- The paper introduces Meta-TTRL, a metacognitive framework that uses intrinsic rewards and introspection for persistent self-improvement in unified multimodal models.
- It deploys a dual-level architecture where an object-level generator and a meta-level introspector work in tandem to enhance compositional and spatial reasoning in text-to-image tasks.
- Empirical results reveal up to 106% improvement in spatial reasoning and robust gains across varied benchmarks, demonstrating lasting test-time adaptation.
Overview
The paper "Meta-TTRL: A Metacognitive Framework for Self-Improving Test-Time Reinforcement Learning in Unified Multimodal Models" (2603.15724) introduces Meta-TTRL, a reinforcement learning (RL) framework designed for Unified Multimodal Models (UMMs) in text-to-image (T2I) generation. In contrast to previous test-time scaling (TTS) methods that focus solely on instance-level improvements via search or sampling with fixed model parameters, Meta-TTRL enables test-time parameter adaptation, leveraging introspective, model-intrinsic signals for persistent, capability-level enhancement. This essay presents a rigorous technical summary, comparative experimental findings, and a discussion of the implications and future directions for Meta-TTRL in the context of UMM research.
Existing TTS strategies for T2I generation rely on post-hoc selection or iterative refinement, yielding improvements only for the current inference instance. Knowledge accumulation across related prompts is absent, resulting in repeated failures for similar prompts and limited scalability due to prohibitively high computational cost for larger models. Meta-TTRL addresses the critical question: Can experience from TTS be utilized as a learning signal to drive test-time reinforcement learning, enabling genuine self-improvement of UMMs without relying on external reward models?
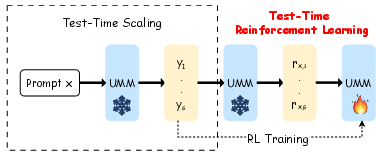
Figure 1: Test-time RL in UMMs shifts performance gains from ephemeral, instance-level to persistent, model-level improvements by updating parameters with model-intrinsic signals.
Meta-TTRL employs a two-level metacognitive architecture:
- Object-Level Generator: Parameterized by policy πϕ, produces candidate images for a given prompt.
- Meta-Level Introspector: Parameterized by θ, constructs structured semantic rubrics and provides intrinsic monitoring signals (rewards) derived from the model's own meta-knowledge.
This architecture embodies a closed monitoring–control loop, in which the introspector's rewards guide gradient-based updates of the generator, achieving persistent, task-specialized improvement at test time.
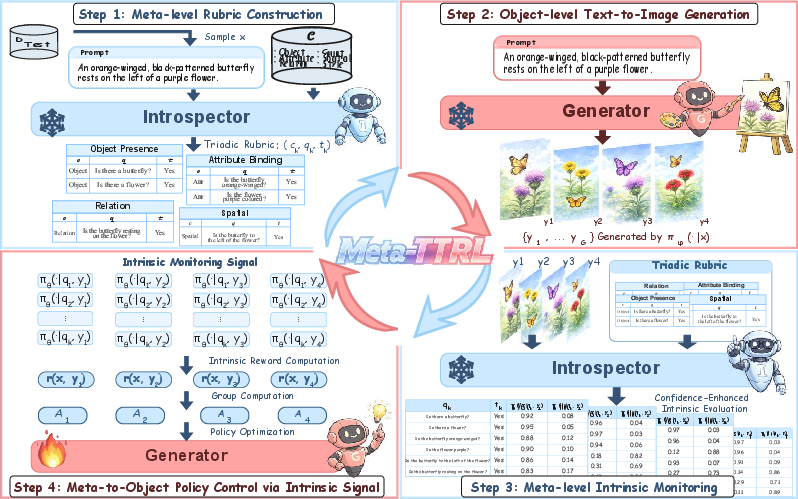
Figure 2: The Meta-TTRL framework comprises a meta-level introspector for constructing rubrics and aggregating intrinsic monitoring signals, and an object-level generator producing candidate T2I images, with feedback driving policy optimization.
The introspector decomposes each prompt into a structured set of evaluation dimensions (Object, Attribute, Count, Spatial, Relation, Style). Each dimension is operationalized into binary verification questions, and the resulting rubric serves as a semantic scaffold for introspective evaluation.
Intrinsic Monitoring and Policy Control
Candidate generations are evaluated by the introspector, which computes confidence-enhanced scores for each rubric criterion. Intrinsic rewards are aggregated and used as the policy optimization signal. Meta-TTRL employs Group Relative Policy Optimization (GRPO), focusing on relative intra-batch improvements and regularizing with KL divergence against a reference policy for stability.
Experimental Results
Meta-TTRL is evaluated across three leading UMMs—Janus-Pro-7B, BAGEL, Qwen-Image—on the TIIF-Bench, T2I-CompBench++, and DPG-Bench datasets. Performance metrics target compositionality and instruction-following fidelity.

Figure 3: Qualitative case studies demonstrate that Meta-TTRL-driven UMMs generate images with improved compositional and spatial reasoning fidelity.
Quantitative Improvements
- All models exhibit consistent gains on all benchmarks, with relative improvement most pronounced for weaker models (e.g., up to 106% for spatial reasoning in Janus-Pro-7B).
- Meta-TTRL excels particularly in subdimensions requiring compositional analysis (shape, texture, numeracy, spatial relations), highlighting the efficacy of meta-knowledge-derived signals for complex reasoning.

Figure 4: Meta-TTRL outperforms both baseline and RL-leakage methods with UnifiedReward across T2I-CompBench++, TIIF-Bench, and DPG-Bench, demonstrating robust test-time optimization.
- Gains generalize to out-of-distribution benchmarks, with persistent improvements across varied prompt distributions and evaluation protocols, indicating minimal overfitting and robust adaptability.
External Introspector and Alternative Monitoring Signals
Replacement of the introspector with an external evaluator (E-TTRL using Qwen3-VL-235B-A22B-Instruct) reveals a capacity-matching phenomenon—Meta-TTRL with intrinsic, capacity-matched signals consistently outperforms external introspection for most compositional subdimensions. Similarly, use of external VQA models for rubric evaluation (e.g., GIT) provides some improvement but does not match the performance of fully intrinsic Meta-TTRL, underscoring the importance of signal alignment with the model's optimization regime.
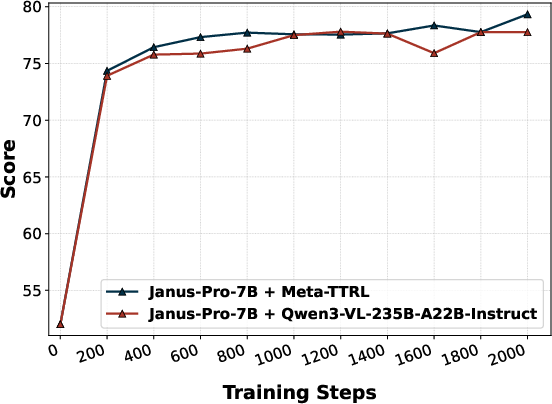
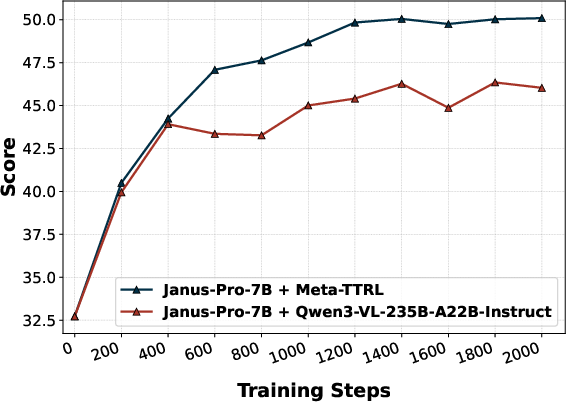
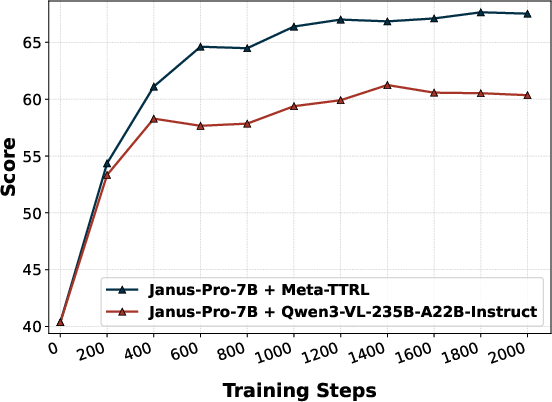
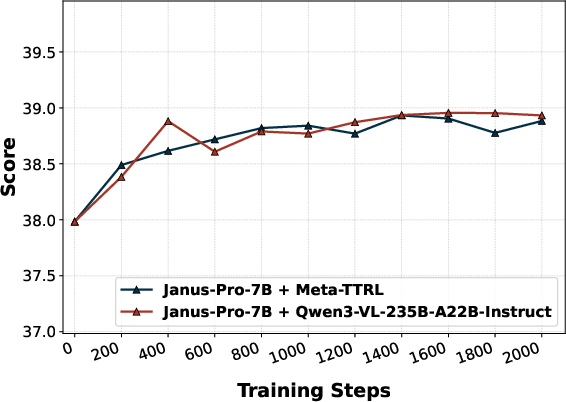
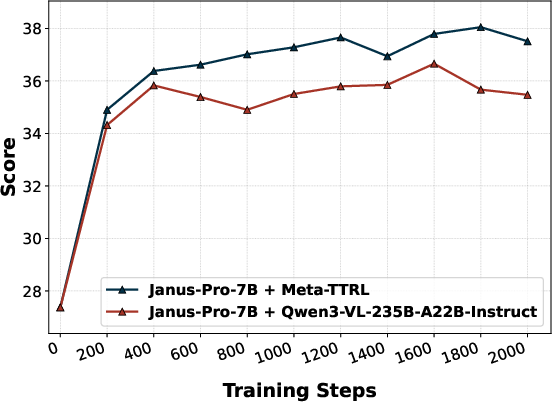
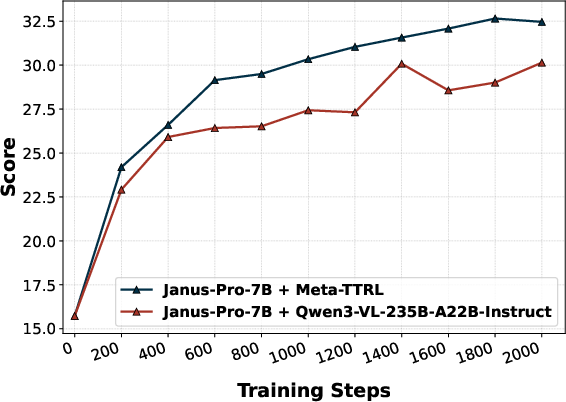
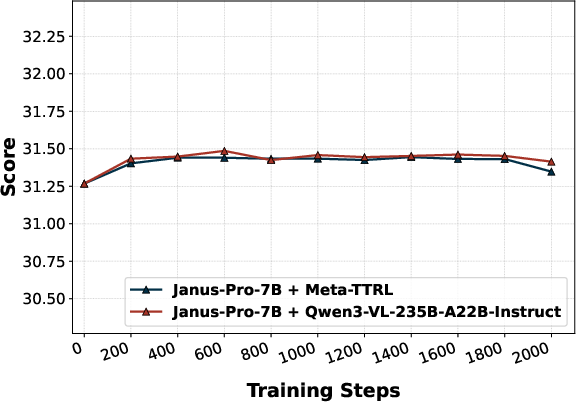
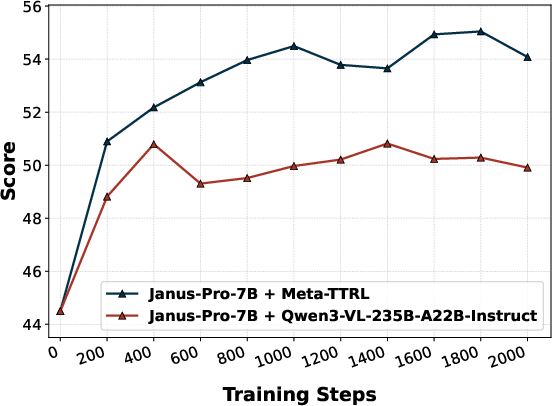
Figure 5: Performance comparison highlights Meta-TTRL’s dominant improvements in challenging compositional T2I subdimensions such as color, shape, texture, and numeracy.
Training Dynamics
Analysis of optimization traces shows steady, synchronized improvements in both the intrinsic reward and external benchmark scores across test-time RL steps, demonstrating the robustness of the metacognitive feedback for test-time self-improvement and ruling out reward hacking artifacts.
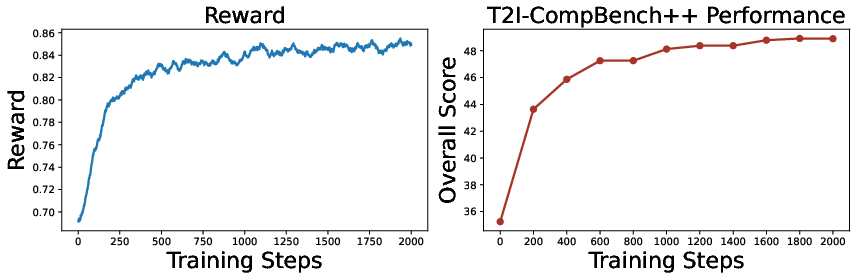
Figure 6: Both GRPO reward and T2I-CompBench++ score increase monotonically during test-time optimization, tracking effective model self-improvement.
Theoretical Insights and Implications
The central insight is the emergence of metacognitive synergy: the success of TTRL in T2I tasks is contingent not on the raw strength of the introspector but on the alignment of the monitoring signals with the capacity and optimization geometry of the base model. External evaluators with higher capacity but misaligned inductive biases provide less actionable feedback for test-time adaptation, highlighting the limits of black-box reward distillation.
Theoretical implications:
- Meta-TTRL operationalizes Nelson–Narens-style metacognition in large foundation models, suggesting promising directions for more sample-efficient and robust test-time adaptation regimes.
- The closed monitoring–control cycle, with test-time parameter updates driven by capacity-matched, introspective signals, offers a new paradigm for UMM self-improvement without dependence on external evaluator models.
Practical implications:
- Meta-TTRL removes the costly dependence on hand-crafted or externally supervised reward models, greatly simplifying deployment for new instruction or compositional T2I tasks.
- Gains persist across prompt distributions and model scales without extensive retraining or additional post-training compute.
Limitations and Future Directions
A primary limitation is the requirement for parameter access within the target UMM, precluding immediate application to closed-source or commercially restricted models. There is also a need to further explore scalability and stability in scenarios involving more complex, multi-turn interactions.
Future directions:
- Investigation of multi-stage or hierarchical metacognitive architectures for open-ended generation tasks.
- Extending self-improving TTRL approaches to other modalities (e.g., video generation) or multi-agent collaborative settings.
- Studying theoretical properties of convergence and generalization in metacognitive test-time RL regimes.
Conclusion
Meta-TTRL is the first test-time RL framework for UMM-based T2I, leveraging model-intrinsic, metacognitive rewards for persistent test-time self-improvement (2603.15724). The empirical evidence reveals strong, generalizable gains in compositional reasoning, particularly for weaker base models, while theoretical analysis underlines the critical role of capacity-matched, introspective signals—the metacognitive synergy effect—in successful test-time learning. The framework sets a new benchmark for evolving UMMs beyond static deployment, enabling continuous, in-situ enhancement post-training.