- The paper introduces a unified test-time adaptation framework that leverages batch-frequency pseudo-rewards and reinforcement learning to enhance video reasoning without ground-truth labels.
- It employs a contextual multi-armed bandit for adaptive frame selection, significantly improving answer consistency and reducing dependence on large-scale annotated datasets.
- Experimental results demonstrate notable accuracy gains across multiple video QA benchmarks, establishing TTA-Vid as an effective approach for long-duration, label-scarce video analysis.
TTA-Vid: Generalized Test-Time Adaptation for Video Reasoning
Introduction
The paper "TTA-Vid: Generalized Test-Time Adaptation for Video Reasoning" (2604.00696) addresses critical challenges in adapting vision-LLMs (VLMs) for advanced video reasoning, focusing on long, informationally structured videos such as instructional or lecture content. Contemporary video reasoning systems, though powerful, are hindered by their dependence on large-scale supervised datasets and costly, multi-stage training pipelines (SFT + RL or reward optimization). Moreover, such systems lack flexibility for rapid adaptation to new domains, particularly in settings with scarce labeled data or where test-time adaptation is essential.
TTA-Vid introduces a unified framework for test-time adaptation (TTA) that operates without ground-truth labels. The approach performs reinforcement learning (RL)-based optimization on unlabeled, incoming video question-answer (QA) pairs, enabling sample-efficient adaptation and improved generalization. This is critical for temporal reasoning tasks where relevant cues are sparsely and heterogeneously distributed across many frames. The core technical contribution is the combination of adaptive frame selection, implemented via a multi-armed bandit (MAB) formulation, and a batch-level, frequency-based RL reward that enforces answer consistency across diverse frame subsets.
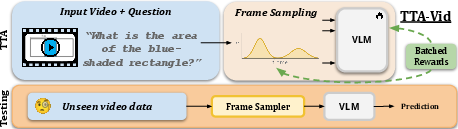
Figure 1: TTA-Vid adapts vision-LLMs at test-time by sampling multiple frame subsets, enforcing majority-consistency among generated answers, and updating a frame-importance distribution via a multi-armed bandit. This allows a test-time adaptation without labels while selecting frames most relevant for reasoning.
Methodology
TTA-Vid's architecture is composed of two synergistic components: (1) Test-Time Adaptation using batch-wide frequency rewards, and (2) Adaptive Frame Selection via a contextual multi-armed bandit.
1. Test-Time Adaptation with Batch-Wide Frequency Rewards
For each unlabeled input video, TTA-Vid repeatedly samples multiple frame subsets and, conditioned on a question, generates multiple candidate answer predictions for each subset using a vision-language policy. The batch-level answer space across all subsets and rollouts forms a soft pseudo-labeling mechanism: answers that recurrently appear are treated as high-confidence pseudo-references.
Reward values are computed as the empirical frequency of each answer (across all K frame subsets and N rollouts per subset), penalized by the normalized entropy of the answer distribution to reduce the propagation of high-uncertainty outputs. The RL objective (optimized by Group Relative Policy Optimization, GRPO) drives the model parameters toward answer-consistency across diverse frame views, while implicitly encouraging sharper, lower-entropy distributions.
2. Adaptive Frame Selection via Multi-Armed Bandit
Given the prohibitive input dimensionality (videos have many more frames than a few-shot context window can handle), TTA-Vid models frame selection as a multi-armed bandit. Each frame in the video is treated as an arm, with importance weights initialized either uniformly or via CLIP-based semantic similarity to the question.
At each adaptation iteration, the method samples subsets of frames for rollouts stochastically according to the current learned distribution. Frames that belong to subsets yielding superior rewards (i.e., rollouts with high-consistency answers) receive increased weights; those in poorly performing subsets are down-weighted using a multiplicative update rule. This learning pipeline produces a global frame sampling distribution that generalizes to held-out/unseen videos at inference.
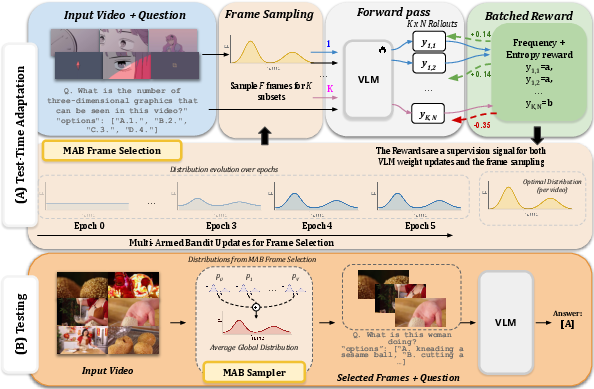
Figure 2: Overview of TTA-Vid: TTA-Vid performs test-time adaptation with batch-aware RL and identifies informative frames using a MAB-based selection policy; rewards are shared between both model and frame selector.
In aggregate, this framework adapts both model parameters and perceptual focus in an unsupervised fashion, allowing TTA-Vid to continually update its reasoning capabilities for new domains without requiring manual annotation.
Experimental Results
Benchmarks and Experimental Setup
TTA-Vid is validated on five QA-driven video understanding datasets: VideoMMMU, MMVU, SciVideoBench, VideoMME, and LongVideoBench, covering both instructional and general domains. Two state-of-the-art VLM backbones are evaluated: InternVL-3 and Qwen2.5-VL, representing the latest open-source architectures.
Frame selection, reward design, and adaptation parameters are all ablated for empirical rigor. The core adaptation is performed on a single batch (32 video QA pairs) with four sampled subsets (F=4 frames each) and up to eight rollouts per subset.
Main Results
TTA-Vid demonstrates consistent, significant improvement over base VLMs and outperforms prior SOTA video reasoning models even when these baselines are trained with full-scale supervised data and RL.
- On InternVL-3 (8B), average accuracy increases from 51.37% to 55.13% (+3.76 points).
- On Qwen2.5-VL (7B), average accuracy rises from 48.82% to 51.84% (+3.02 points).
- Gains are evident across all evaluated datasets, with the largest improvements in long-duration and STEM-oriented videos.
Importantly, the adaptation trained on only 32 unlabeled test-time samples not only generalizes across the entire test set, but also transfers across datasets—e.g., a model adapted on MMVU data generalizes to VideoMMMU or SciVideoBench.
TTA-Vid also shows robust performance even with minimal samples; training on a single sample still yields considerable gains.
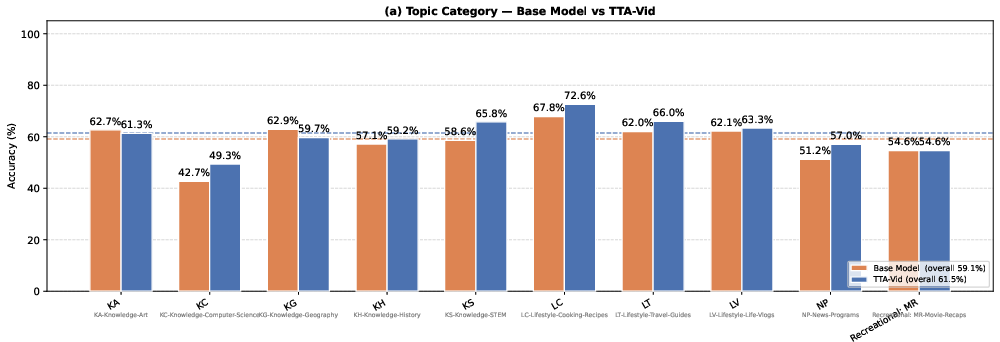
Figure 3: Per-category performance (LongVideoBench): TTA-Vid yields the strongest improvement in Computer Science, STEM, and New Programs topics.
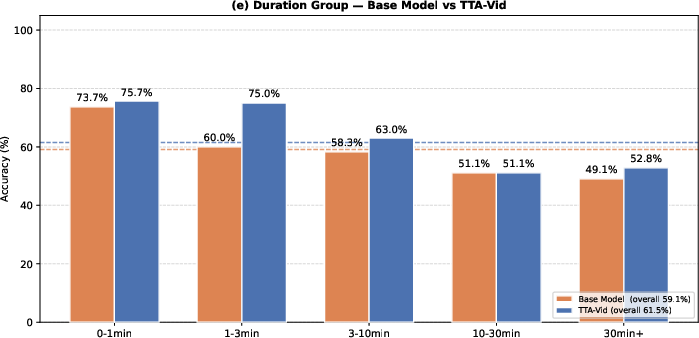
Figure 4: TTA-Vid exhibits largest gains on 1–3 minute videos, but maintains improvements even for >30 minute content, indicating efficacy on long-range temporal reasoning.
Ablation: Frame Selection and Reward Structure
The MAB-based learned frame distribution outperforms both random and CLIP-similarity-based frame sampling strategies. When comparing reward computation based on majority answer, ground truth (when available), or self-consistency, the majority-vote pseudo-labeling proves more generalizable (e.g., achieving 65.11% vs 60.96% accuracy on MMVU with Qwen2.5VL-7B).
Qualitative analysis (see Figure 5) indicates the learned frame selector routinely localizes frames providing decisive context or cues for reasoning questions, while random or heuristic selection often misses these frames.
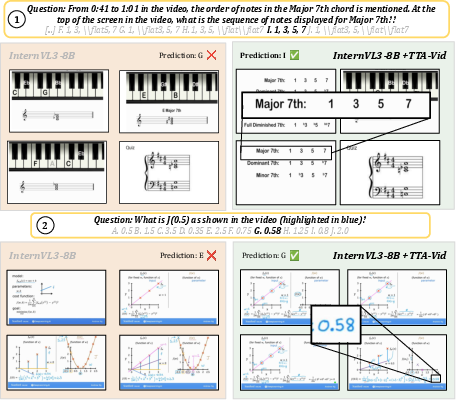
Figure 5: TTA-Vid's learned frame selection vs random sampling: the model selects critical frames supporting correct answers in musical and accounting reasoning tasks, outperforming random baselines.
Theoretical and Practical Implications
TTA-Vid challenges the prevailing orthodoxy in multimodal RL which emphasizes the need for scale, annotation, and end-to-end training. Its results indicate that reinforcement signals derived from consistency across diverse visual evidence can bootstrap powerful adaptation—even in the absence of explicit ground-truth. This points to test-time RL as an efficient, annotation-free strategy for model adaptation and domain generalization, particularly in video understanding where labeled data and context length are fundamental bottlenecks.
The multi-armed bandit formulation of frame selection addresses a long-standing challenge in video QA—how to efficiently focus on the relevant moments in long, information-dense videos. It provides model interpretability by mapping which frames are prioritized as reasoning-critical, potentially informing downstream applications such as educational AI, video summarization, and digital tutors.
Future work can extend TTA-Vid to fully continual learning, dynamic adaptation in streaming scenarios, and joint multimodal memory architectures. There is also fertile ground for integrating more sophisticated pseudo-reward mechanisms (e.g., self-critical learning, teacher-student distillation at test-time), or aligning bandit-based frame selection with attention bottlenecks in scalable transformers.
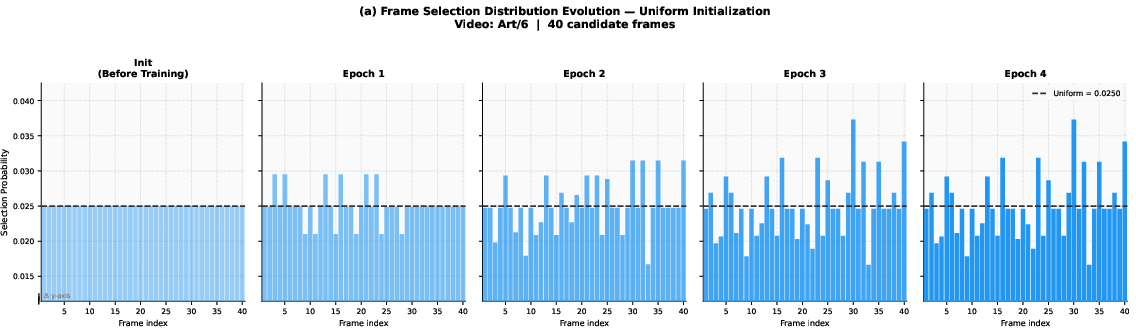
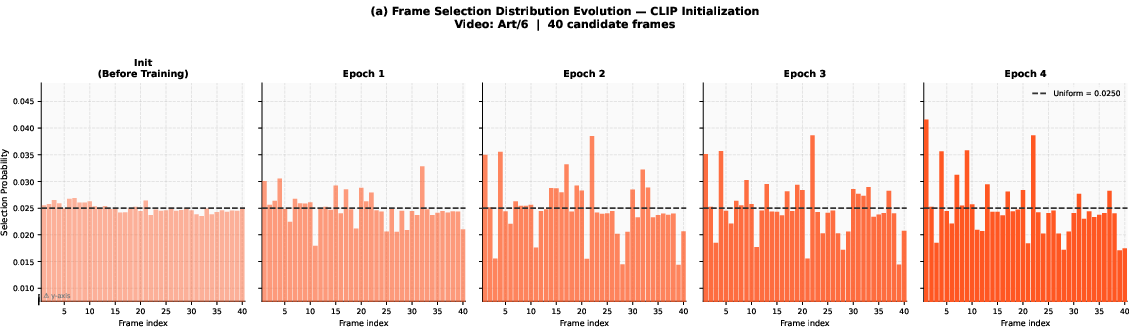
Figure 6: Progression of the learned uniform initialization distribution over epochs demonstrates convergence to informative frame selection.
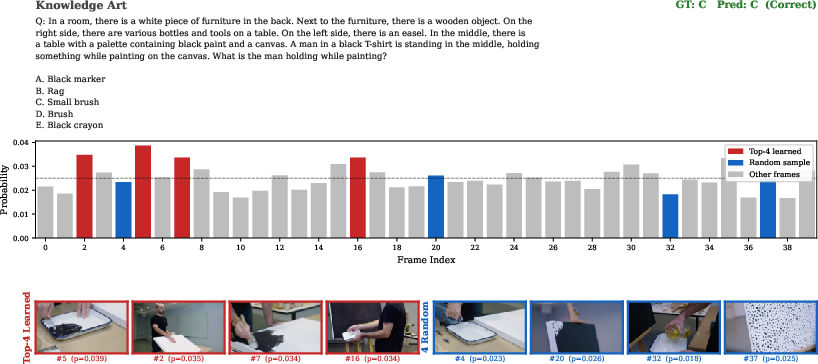
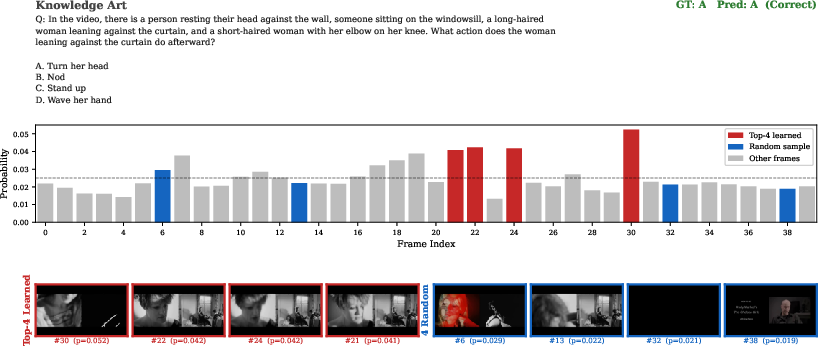
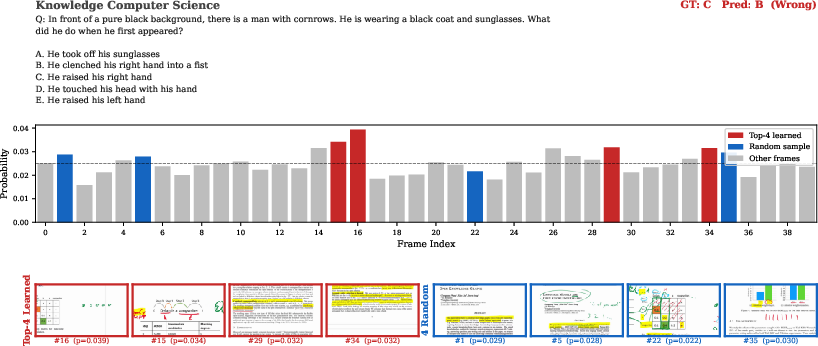
Figure 7: Qualitative example: the third frame sampled from the learned distribution contains the essential visual evidence, supporting correct model predictions.
Conclusion
TTA-Vid establishes a technically rigorous, resource-efficient protocol for test-time adaptation in video reasoning, achieving improvements over heavily supervised SoTA models without access to labels or extensive retraining. Through batch-frequency pseudo-reward RL and learned attention to temporal cues, TTA-Vid exemplifies self-supervised generalization in long-video QA. Its contributions signal a paradigm shift for VLM adaptation, endorsing reinforcement at deployment as a credible means for continual, annotation-free improvement in complex multimodal tasks.