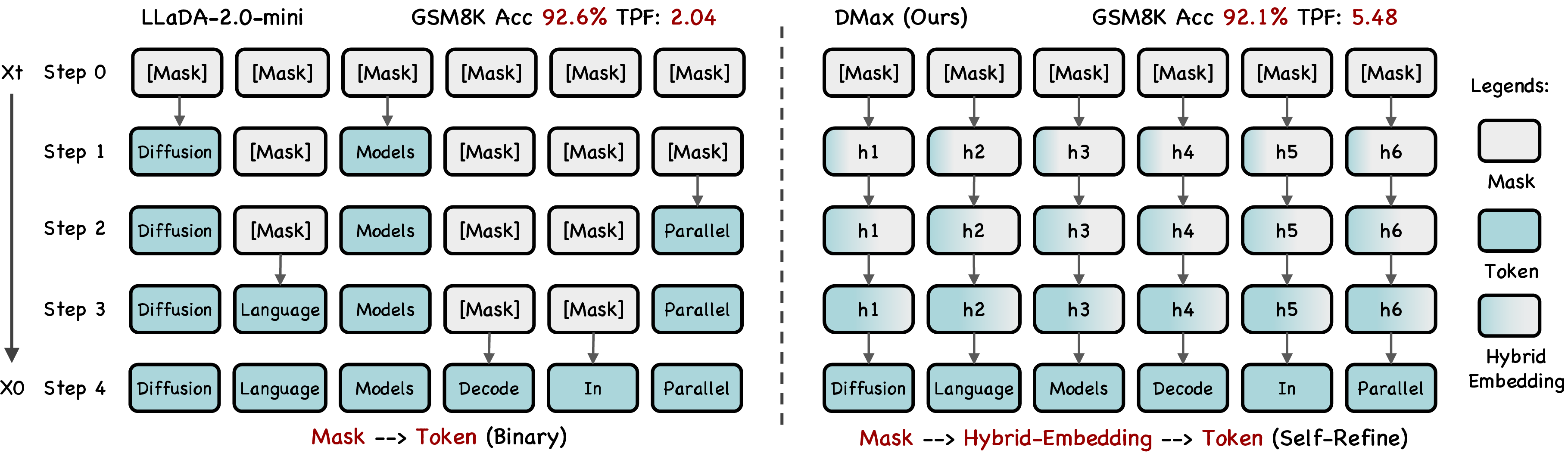
DMax: Aggressive Parallel Decoding for dLLMs
Abstract: We present DMax, a new paradigm for efficient diffusion LLMs (dLLMs). It mitigates error accumulation in parallel decoding, enabling aggressive decoding parallelism while preserving generation quality. Unlike conventional masked dLLMs that decode through a binary mask-to-token transition, DMax reformulates decoding as a progressive self-refinement from mask embeddings to token embeddings. At the core of our approach is On-Policy Uniform Training, a novel training strategy that efficiently unifies masked and uniform dLLMs, equipping the model to recover clean tokens from both masked inputs and its own erroneous predictions. Building on this foundation, we further propose Soft Parallel Decoding. We represent each intermediate decoding state as an interpolation between the predicted token embedding and the mask embedding, enabling iterative self-revising in embedding space. Extensive experiments across a variety of benchmarks demonstrate the effectiveness of DMax. Compared with the original LLaDA-2.0-mini, our method improves TPF on GSM8K from 2.04 to 5.47 while preserving accuracy. On MBPP, it increases TPF from 2.71 to 5.86 while maintaining comparable performance. On two H200 GPUs, our model achieves an average of 1,338 TPS at batch size 1. Code is available at: https://github.com/czg1225/DMax
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “DMax: Aggressive Parallel Decoding for dLLMs”
What is this paper about?
This paper introduces DMax, a new way to make diffusion LLMs (a type of AI that writes text) generate words much faster without messing up their answers. DMax lets the model guess many words at once (parallel decoding) while still being able to fix its own mistakes, so quality stays high.
What questions are the researchers trying to answer?
- How can we make text models write many words at the same time, instead of one-by-one, without errors snowballing out of control?
- Can we train a model to notice and correct its own bad guesses during generation?
- Is there a safe way to “half-commit” to a guess (not fully lock it in) so the model can smoothly revise it later?
How did they try to solve it? (Plain-language methods and analogies)
First, two quick ideas you need:
- Masked diffusion models (MDLMs): Imagine starting a sentence full of blanks [MASK] and filling them in step by step. Today’s models often fill in many blanks at once. The problem: once a blank is filled, it’s locked in. If it’s wrong, later steps build on that mistake—errors pile up.
- Uniform diffusion models (UDLMs): Instead of blanks, start with random gibberish everywhere and repeatedly clean it up. You can revise every position at every step, which is good for fixing errors. But starting from gibberish is unstable and hard.
DMax combines the best of both.
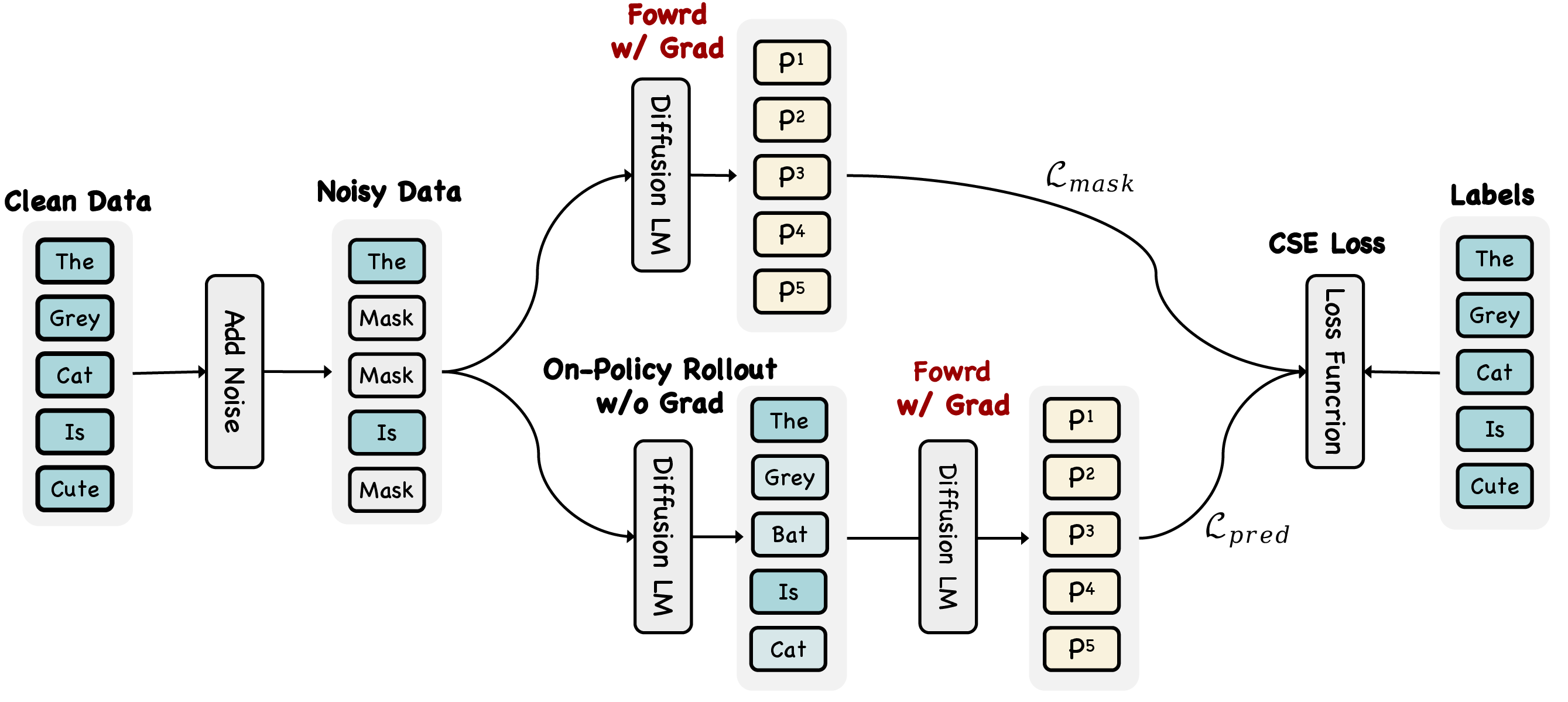
- On-Policy Uniform Training (OPUT): Practice fixing your own guesses Think of training as practice games. Old training replaced blanks with random nonsense and asked the model to recover the true sentence—like practicing against a fake opponent you’ll never see in a real game. OPUT changes that: the model practices on the kinds of errors it actually makes during decoding. It:
- Starts with some blanks,
- Lets the model fill them in,
- Then feeds those model-made guesses back in,
- Trains the model to turn those imperfect guesses into the correct answer.
This shrinks the gap between practice and real use. The model keeps its skill at filling blanks but also learns to fix its own mistakes.
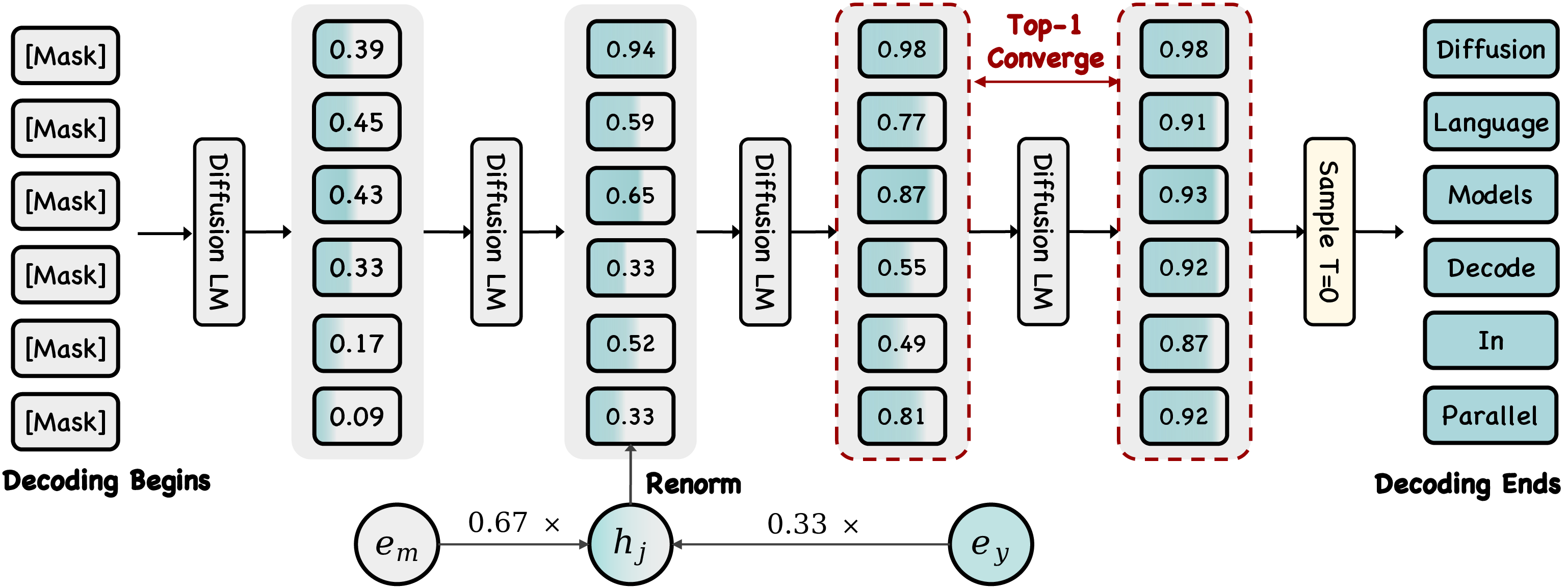
- Soft Parallel Decoding (SPD): Write in pencil first, pen later Instead of treating a guess as fully final (ink), DMax treats each guessed word as a soft mix between:
- the “mask” (meaning “I’m unsure”), and
- the guessed word (meaning “I’m this sure”). In math terms, it blends their “embeddings” (number-based representations of meanings) according to confidence. In plain terms: it writes lightly when unsure and darkens the word as confidence grows. This “soft” idea lets uncertainty carry forward, so the model knows what to focus on revising next.
To keep things stable, DMax also commits only a left-to-right chunk of confident guesses at a time. If it hits a low-confidence spot, it leaves the rest masked for later. That prevents weak future guesses from confusing earlier ones.
Simple glossary:
- Embedding: a numeric “fingerprint” of a word’s meaning.
- Interpolation: mixing two things—here, mixing “mask” and “guess” embeddings based on confidence.
- Confidence threshold: how sure the model must be before a guess counts as “good enough” to tentatively keep.
What did they find, and why does it matter?
Here are the highlights from standard benchmarks:
- Faster parallel decoding without losing accuracy:
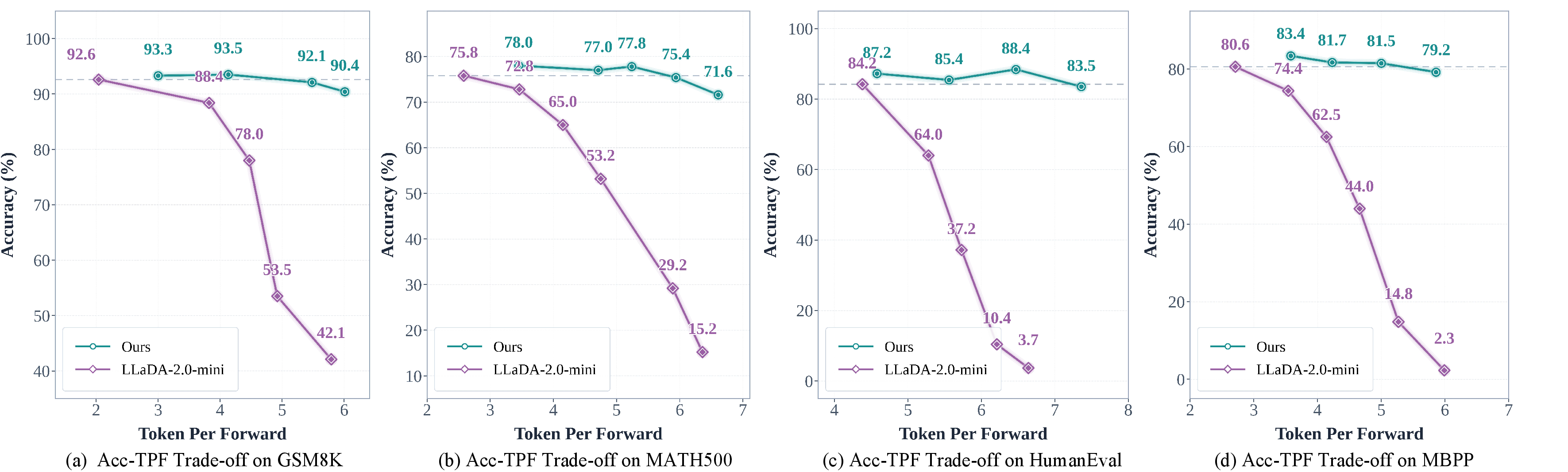
- On a math benchmark (GSM8K), DMax boosts “tokens per forward” (how many new words the model adds per step) from about 2.0 to about 5.5, while accuracy stays around 92%.
- On a coding benchmark (MBPP), it increases tokens per forward from about 2.7 to about 5.9, with similar accuracy to the original model.
- High real-world speed:
- On two powerful GPUs, the system processes over 1,000 tokens per second (they report around 1,300+ TPS in some tests).
- More stable under aggressive parallelism:
- Competing methods speed things up a bit but often lose lots of accuracy when pushing parallel decoding. DMax stays accurate even when decoding very aggressively because it can revise mistakes.
Why this matters: Faster generation means cheaper, quicker AI responses—great for chatbots, coding assistants, and math solvers. Keeping accuracy high means you don’t pay for speed with wrong answers.
So what? What’s the impact?
- For users: Quicker replies without sacrificing correctness.
- For developers: A practical recipe (OPUT + SPD) to speed up diffusion-based LLMs safely.
- For research: A new baseline that shows how to combine “self-correction during decoding” with “parallel decoding,” pointing to future work where models write more in parallel and fix errors on the fly.
In short, DMax teaches models to write fast and smart—guessing many words at once, but with a built-in eraser to fix mistakes before they spread.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems that remain unresolved and could guide future research:
- Generalization beyond the LLaDA‑2.0‑mini base: How well does DMax transfer to larger/smaller dLLMs, MoE variants, multilingual vocabularies, different tokenizers, and non-LLaDA architectures without task-specific tuning?
- Task/domain coverage: Effects on open-ended instruction following, dialogue, summarization, factual QA, and multilingual tasks remain untested; current evidence is limited to math and code.
- Long-form and safety-critical generation: Impact on coherence, factuality, safety, and moderation in long-form outputs is unmeasured.
- Data generation bias in OPUT: Training supervision is entirely self-distilled from the base model (threshold 0.95), risking confirmation bias and error reinforcement; the trade-off between stability and novelty/diversity is not analyzed.
- Contamination checks: Potential overlap between self-distilled data and evaluation sets (e.g., GSM8K, HumanEval/MBPP variants) is not rigorously audited or reported.
- Calibration dependence: SPD relies on predicted probabilities to interpolate embeddings; the method’s sensitivity to miscalibration and the effect of calibration techniques (e.g., temperature scaling) are not studied.
- Confidence thresholds: No principled procedure for choosing or adapting τ_dec and τ_acc across tasks/domains; limited sensitivity analysis beyond a few fixed values.
- Block size and partitioning: Only a block size of 32 is explored; how TPF/accuracy trade-offs evolve with varying block sizes or alternative partition strategies is unknown.
- Left-to-right contiguous-prefix constraint: The chosen promotion rule may limit global consistency where right context informs left tokens; effectiveness of alternative promotion policies (e.g., multi-span, bidirectional, graph-based) is untested.
- Hybrid embedding design: SPD mixes only top‑1 token embedding with the mask embedding; the potential benefits of richer mixtures (e.g., expected embedding over top‑k or full distribution, learned gates/MLPs, non-linear mixing) are unexplored.
- Embedding-space assumptions: Renormalization by L2 norms is ad hoc; the compatibility of SPD with models using strong LayerNorm, learned embedding scales, or different embedding parameterizations is not justified or compared to alternatives.
- Convergence behavior: No theoretical guarantees on SPD convergence, iteration bounds per block, or worst-case oscillation scenarios; empirical iteration counts and stopping behavior are not reported.
- Inference compute accounting: TPS is reported, but the total FLOPs per generated token/sequence and per-block iteration counts (with and without SPD) are not disclosed, complicating fair cost comparisons.
- Memory/latency overheads: The system-level implications of hybrid embeddings and repeated block refinement (e.g., KV cache reuse, memory bandwidth, latency spikes) are not analyzed.
- Hardware generality: All results use H200 GPUs with batch size 1; portability and scaling on other accelerators (A100, consumer GPUs, TPUs), different batch sizes, and distributed setups remain unknown.
- Interaction with KV caching and sparse attention: How SPD and OPUT interact with caching, token dropping, sparse attention, or streaming settings is unreported.
- OPUT design choices: The paper presents t sampling and later fixes mask ratio at 0.75; the effect of different noise schedules, t ranges, corruption policies, and sampling temperatures/top‑k/top‑p during on-policy rollouts is not ablated.
- Training stability and cost: OPUT uses two inputs (masked and predicted) via separate iterations; the extra compute/time, stability across seeds, and convergence diagnostics versus standard MDLM/UDLM training are not quantified.
- Comparison to alternative “soft” decoding: There is no head‑to‑head with concurrent soft-embedding approaches (e.g., SM, EvoToken) under identical settings to isolate SPD’s contribution.
- Compatibility with few-step/traj-distilled dLLMs: How DMax interacts with few-step training (e.g., T3D, D3LLM), consistency methods, or pseudo-trajectory distillation is unclear.
- Hybrid AR–diffusion settings: The applicability of SPD/OPUT in diffusion–autoregressive hybrids or speculative-style verification for dLLMs is not evaluated.
- Robustness to OOD prompts and adversarial inputs: Stability under distribution shift, adversarial perturbations, and noisy user inputs is untested.
- Diversity–quality trade-offs: Effects on output diversity/entropy and mode collapse (given on-policy rollouts) are not measured; decoding may become overly conservative.
- Error taxonomy: No qualitative error analysis (e.g., where residual error accumulation persists, typical failure modes under high parallelism, correlated error patterns within blocks).
- Metrics and reproducibility: AUP is reported without detailed definition or reproducibility protocol; precise TPF/TPS measurement methodology and seeds are not fully specified for replication.
- Theoretical grounding: A formal justification for why OPUT + SPD should reduce train–inference mismatch and mitigate error accumulation (e.g., a bias–variance or fixed-point view) is absent.
- Extensions to multimodal/agent settings: Although cited as promising areas, DMax’s behavior in multimodal dLLMs and agentic pipelines (tool-use, retrieval, planning) is untested.
- Tokenizer and special-token reliance: SPD assumes a dedicated [MASK] embedding; generalization to vocabularies without explicit mask tokens or byte-level tokenizers is not discussed.
- Acceptance thresholds vs. correctness: High τ_acc (0.9) might prematurely accept confidently wrong tokens; strategies for dynamic thresholding or verification are not explored.
Practical Applications
Immediate Applications
The following applications can be deployed now using DMax’s On-Policy Uniform Training (OPUT) and Soft Parallel Decoding (SPD), given an available dLLM (e.g., LLaDA-2.0-mini) and standard GPU inference infrastructure.
- Accelerated dLLM-powered chat and customer support
- Sector: Software, Customer Support, Consumer Tech
- Workflow/Product: Integrate SPD into existing dLLM-serving stacks (e.g., dInFer) to cut latency and cost per response; expose a “parallel decoding mode” in API endpoints for high-concurrency chatbots.
- Assumptions/Dependencies: Production stack uses a diffusion LLM with a mask embedding; confidence calibration for thresholds (τ_dec, τ_acc); H100/H200-class GPUs or profiling on available hardware; task prompts similar to training distribution.
- Low-latency math tutoring and reasoning assistants
- Sector: Education
- Workflow/Product: Use DMax-Math for interactive GSM8K-like tutoring, step-by-step feedback, and automated grading with 2×–3× higher TPF while preserving accuracy; deploy as web/mobile app back-end.
- Assumptions/Dependencies: Benchmarks show strong performance on math tasks; guardrails and solution verification needed for classroom use; domain prompts may require additional OPUT fine-tuning.
- Faster code assistants and developer productivity tools
- Sector: Software
- Workflow/Product: Install SPD-backed dLLM in IDE extensions (LSP servers) to generate code completions, tests, and fixes; apply OPUT fine-tuning on in-domain repositories for improved stability.
- Assumptions/Dependencies: Code-specific dLLM availability (e.g., DMax-Coder); security scanning and license compliance for generated code; calibration of thresholds to balance speed and correctness.
- Throughput-oriented batch generation (synthetic data pipelines)
- Sector: AI/ML Operations, Data Engineering
- Workflow/Product: Use DMax to accelerate large-scale generation of chain-of-thought rationales, programming tasks, or prompts for self-distillation and dataset augmentation.
- Assumptions/Dependencies: Quality control pipeline (filters, validators); self-distillation aligns with use policies; compute scheduling for block-wise decoding (block size ~32 as in the paper).
- Inference cost and energy reduction for on-prem/cloud serving
- Sector: Cloud/Infra, Energy-Conscious Operations
- Workflow/Product: Migrate dLLM inference endpoints to SPD; monitor TPF/TPS and AUP Score in dashboards; reduce GPU-hours per token for internal workloads.
- Assumptions/Dependencies: Actual cost savings depend on hardware utilization and batch sizing; benefits are clearest on H100/H200-class GPUs; careful profiling needed for smaller GPUs.
- Research reproducibility and baselines for dLLM self-correction
- Sector: Academia/Research
- Workflow/Product: Adopt OPUT for training/evaluating self-revision in dLLMs; standardize metrics (TPF/TPS/AUP) in comparative studies; release ablations and scripts to accelerate community benchmarks.
- Assumptions/Dependencies: Access to training compute for on-policy rollouts; availability of a base MDLM; adherence to dataset licensing for self-distillation.
- MLOps: Confidence- and convergence-aware monitoring
- Sector: Software/DevOps
- Workflow/Product: Add telemetry for τ_dec, τ_acc, TPF, block convergence criteria (consistency vs confidence) to inference logs; use alerts for oscillations or collapse.
- Assumptions/Dependencies: Inference framework must expose token-level confidences; internal SRE support for new metrics.
- Domain adaptation via self-distillation
- Sector: Cross-sector (Finance, Legal, E-commerce)
- Workflow/Product: Generate on-policy trajectories on in-domain prompts, then apply OPUT to adapt the dLLM; deploy SPD at inference for robust, fast decoding.
- Assumptions/Dependencies: Sufficient in-domain prompts; privacy/compliance for generating and storing self-distilled data; risk controls for hallucinations in high-stakes domains.
Long-Term Applications
The following applications require further research, scaling, or engineering—e.g., broader domain coverage, model scaling, on-device optimization, or regulatory readiness.
- Broad replacement of autoregressive decoding in production
- Sectors: Software, Consumer Platforms, Enterprise SaaS
- Potential Tools/Products: “DMax-grade” dLLMs as general-purpose back-ends for chat, retrieval-augmented generation, and agentic systems with aggressive parallel decoding.
- Assumptions/Dependencies: Comparable open-domain quality to top AR LLMs; robust calibration across tasks; ecosystem support (tooling, prompts, safety).
- On-device assistants with low-latency reasoning
- Sectors: Mobile, Edge/IoT
- Potential Tools/Products: Quantized dLLMs leveraging SPD to reduce steps and energy; hybrid CPU/NPU/GPU pipelines that exploit contiguous-prefix promotion.
- Assumptions/Dependencies: Compact dLLM architectures with mask embeddings; quantization/pruning friendly diffusion stacks; hardware-accelerated embedding ops.
- Real-time language-driven robotics and planning
- Sectors: Robotics, Industrial Automation
- Potential Tools/Products: Task planners that use SPD for fast revisions of action plans; integration with multimodal dLLMs (text + vision) to correct early-stage errors on the fly.
- Assumptions/Dependencies: Safety-verified outputs; tight coupling with perception and control loops; extension of mask/hybrid embedding constructs to multimodal streams.
- Healthcare documentation and decision support at scale
- Sectors: Healthcare
- Potential Tools/Products: High-throughput clinical summarization, coding (e.g., ICD), and patient communication tools where DMax reduces lag during long-chain reasoning.
- Assumptions/Dependencies: Domain-specific OPUT fine-tuning; rigorous validation, compliance (HIPAA, GDPR), and guardrails; calibrated confidence thresholds for high-stakes texts.
- Financial analysis and compliance copilots
- Sectors: Finance
- Potential Tools/Products: Rapid generation and self-revision of analyses, briefings, and regulatory reports with predictable latency; parallel decoding for bulk document processing.
- Assumptions/Dependencies: Strong retrieval integration; audit trails for self-revisions; conservative thresholds to mitigate error cascades.
- Multimodal dLLMs with uncertainty-aware decoding
- Sectors: Media, Autonomous Systems, Education
- Potential Tools/Products: Extend OPUT/SPD to speech and vision tokens (e.g., blending “mask” embeddings for images/audio); self-revising captioning, instruction-following, or VQA with parallel decoding.
- Assumptions/Dependencies: Definition of mask embeddings for non-text modalities; stable training under on-policy multimodal noise; GPU kernels optimized for hybrid-embedding ops.
- Hardware–software co-design for parallel dLLM decoding
- Sectors: Semiconductors, Cloud Providers
- Potential Tools/Products: Kernels/ASICs that accelerate hybrid embedding interpolation, contiguous-prefix scheduling, and block-wise convergence checks; scheduler plugins in inference runtimes.
- Assumptions/Dependencies: Vendor support; standardization of dLLM interfaces; long hardware design cycles.
- Standardization of efficiency metrics and procurement policy
- Sectors: Public Sector, Large Enterprises
- Potential Tools/Products: Adoption of AUP Score, TPF, and TPS as procurement metrics for LLM services; efficiency-focused benchmarks for public funding and sustainability.
- Assumptions/Dependencies: Community consensus on metrics; independent evaluation bodies; mapping metrics to environmental impact (energy/CO₂).
- Energy-aware edge and grid applications
- Sectors: Energy, Smart Infrastructure
- Potential Tools/Products: Low-latency, low-power textual interfaces for smart meters, grid diagnostics, or maintenance logs using SPD to minimize compute per task.
- Assumptions/Dependencies: Robust on-device dLLMs; strict reliability requirements; domain-specific OPUT fine-tuning for technical jargon.
- Multi-agent and workflow orchestration with self-revising steps
- Sectors: Enterprise Automation, Operations
- Potential Tools/Products: Agent frameworks that exploit SPD to revise intermediate steps in parallel (e.g., plan expansion, critique/repair loops) for faster end-to-end tasks.
- Assumptions/Dependencies: Interfaces for exposing token-level confidence to agents; careful design to avoid oscillations; evaluation beyond math/code to complex enterprise workflows.
Glossary
- Acceptance threshold: A confidence level used to decide when a decoded block is stable enough to commit its tokens. "The acceptance threshold for determining whether a block has converged to a stable state is set to $\tau_{\mathrm{acc}=0.9$."
- AUP Score: An aggregate metric used to evaluate parallel decoding performance across settings by summarizing the efficiency–accuracy trade-off. "we also report the AUP score to provide a more comprehensive evaluation of parallel decoding performance."
- Autoregressive LLMs (AR-LLM): Models that generate text token-by-token, each conditioned on previously generated tokens. "Autoregressive LLMs (AR-LLM) \cite{achiam2023gpt, bai2023qwen,grattafiori2024llama} in text generation."
- Block-diffusion: A decoding/training setup where sequences are processed in fixed-size blocks through diffusion steps. "Training follows the block-diffusion setting with a block size of 32."
- Chain-of-thought: A prompting technique that elicits intermediate reasoning steps to improve reasoning accuracy. "and prompt the model to produce chain-of-thought \cite{wei2022chain} reasoning."
- Confidence priors: Prior information about prediction confidence carried into later steps to guide self-correction. "This simple design provides the model with confidence priors from previous steps, enabling more robust self-correction."
- Confidence threshold: A cutoff on prediction confidence used to decide which positions to promote from mask to token during decoding. "the base model, evaluated with its default confidence-threshold-based parallel decoding strategy using a threshold of 0.95"
- Contiguous prefix: The leftmost continuous segment of positions in a block that satisfies a decoding criterion (e.g., confidence). "promote only its longest contiguous prefix whose confidence exceeds $\tau_{\mathrm{dec}$."
- Cross-entropy loss: A standard classification loss used here to supervise token recovery across positions. "We then supervise both outputs against the original clean sequence using cross-entropy loss over all token positions, regardless of whether a position is masked:"
- Denoising process: The iterative procedure of recovering clean tokens from corrupted inputs in diffusion models. "formulate text generation as a discrete denoising process over token sequences"
- Diffusion LLMs (dLLMs): LLMs that generate text via iterative denoising steps instead of strictly autoregressive token-by-token generation. "Diffusion LLMs (dLLMs) \cite{yi2024diffusion,yu2025discrete,zhang2025survey,li2025survey,ni2025diffusion,zhou2026dllm} have emerged as a compelling alternative"
- Embedding space: The vector space where token and mask embeddings lie, enabling continuous interpolation and refinement. "enabling iterative self-revising in embedding space."
- Error accumulation: The compounding of early prediction errors that propagate and degrade later decoding steps. "do not address the fundamental bottleneck underlying parallel decoding in current dLLM paradigm: error accumulation."
- Hybrid embedding: A soft input representation formed by interpolating between a predicted token embedding and the mask embedding based on confidence. "we construct a hybrid embedding from the top-1 prediction at the previous step as the model input."
- Mask embedding: The learned vector representation corresponding to the special [MASK] symbol, used to encode maximal uncertainty. "every mask position uses the mask embedding as model input:"
- Masked Diffusion LLMs (MDLMs): dLLMs trained to recover original tokens only at masked positions, starting from [MASK]-corrupted inputs. "Masked Diffusion LLMs (MDLMs)."
- On-Policy Uniform Training (OPUT): A training strategy that builds noisy inputs from the model’s own predictions to align training with inference and teach self-correction. "Central to our approach is On-Policy Uniform Training (OPUT)"
- On-policy rollout: Generating training inputs by sampling from the current model’s predictive distribution rather than a fixed or uniform distribution. "making this a strictly on-policy rollout process."
- Remasking: An optional step that reintroduces masks to already decoded positions to allow further refinement. "with an optional remasking step to enable further refinement."
- Renormalize (hybrid embedding): Adjust the norm of the interpolated embedding to prevent magnitude distortion when combining embeddings. "we renormalize the hybrid embedding so that its norm matches the probability-weighted sum of the component norms:"
- Self-distillation: Creating training targets from the model’s own generated outputs instead of external annotations. "We construct all training data through self-distillation."
- Semantic collapse: A failure mode where accumulated errors lead to nonsensical or degenerate outputs. "ultimately leading to semantic collapse."
- Semi-autoregressive: A decoding regime that commits tokens in chunks or blocks while still allowing some parallelism. "It follows a block-wise semi-autoregressive process."
- Soft Parallel Decoding (SPD): The proposed decoding method that propagates uncertainty via hybrid embeddings to enable robust, highly parallel decoding. "Our proposed SPD further improves robustness when many erroneous predictions emerge simultaneously"
- Speculative decoding: A fast decoding approach that proposes tokens in parallel and validates them, used here as a point of contrast. "Unlike speculative decoding \cite{leviathan2023fast,cai2024medusa,li2024eagle},"
- Tensor parallelism: A distributed inference technique that partitions model tensors across multiple GPUs to increase throughput. "All evaluations are conducted with the dInFer \cite{ma2025dinfer} framework on 2 H200 GPUs using tensor parallelism."
- Top-1 prediction: The most likely token according to the model’s probability distribution at a position. "the top-1 predictions at all positions remain unchanged for two consecutive decoding steps,"
- Tokens per forward (TPF): The number of tokens decoded or committed per forward pass, indicating the degree of parallelism. "our method increases tokens per forward (TPF) from 2.04 to 5.48"
- Tokens per second (TPS): A throughput metric indicating how many tokens are produced per second during inference. "On two H200 GPUs, our model achieves an average of 1,338 TPS at batch size 1."
- Train--inference mismatch: A discrepancy where the training corruption or inputs differ from those encountered during inference, harming performance. "This corruption process introduces a severe train--inference mismatch."
- Uniform Diffusion LLMs (UDLMs): dLLMs trained to recover clean tokens from arbitrary noisy tokens sampled from the vocabulary, enabling token-to-token correction. "Uniform Diffusion LLMs (UDLMs)."
- Uniform vocabulary distribution: Sampling tokens uniformly at random from the vocabulary to create noisy inputs. "rather than from a uniform vocabulary distribution,"
- Unnormalized hybrid embedding: The raw (pre-renormalization) linear combination of token and mask embeddings used to represent uncertainty. "The unnormalized hybrid embedding is then"
Collections
Sign up for free to add this paper to one or more collections.

