dInfer: An Efficient Inference Framework for Diffusion Language Models
Abstract: Diffusion-based LLMs (dLLMs) have emerged as a promising alternative to autoregressive (AR) LLMs, leveraging denoising-based generation to enable inherent parallelism. Even more and more open-sourced dLLM models emerge, yet their widespread adoption remains constrained by the lack of a standardized and efficient inference framework. We present dInfer, an efficient and extensible framework for dLLM inference. dInfer decomposes the inference pipeline into four modular components--model, diffusion iteration manager, decoding strategy, and KV-cache manager--and integrates novel algorithms for each component alongside system-level optimizations. Through this combination of algorithmic innovations and system enhancements, dInfer achieves substantial efficiency gains without compromising output quality on LLaDA-MoE. At batch size 1, it surpasses 1,100 tokens per second on HumanEval and averages over 800 tokens per second across six benchmarks on $8\times$ H800 GPUs. Compared to prior systems, dInfer delivers a $10\times$ speedup over Fast-dLLM while maintaining similar model performance. Even compared to the AR model (with a comparable number of activation parameters and performance) QWen2.5-3B, which is highly optimized with the latest vLLM inference engine, dInfer still delivers a $2$-$3\times$ speedup. The implementation of dInfer is open-sourced at https://github.com/inclusionAI/dInfer.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces dInfer, a fast and flexible system for running a new kind of LLM called a diffusion LLM (dLLM). Unlike normal LLMs that write one token (piece of a word) at a time, diffusion models “clean up” a whole sentence in several rounds, like sharpening a blurry photo step by step. dInfer makes this process much faster and more reliable, so these models are practical to use.
What questions does it try to answer?
The paper focuses on three simple questions:
- How can we make diffusion LLMs run faster without hurting the quality of their answers?
- How can we safely decode many tokens at once (in parallel) without the results getting worse?
- Can we build a standard, open-source framework so different diffusion models can be tested fairly and improved consistently?
How did the researchers approach it?
The authors built dInfer as a modular framework, like a set of Lego blocks you can snap together. Each block handles a key part of the model’s inference (generation) process.
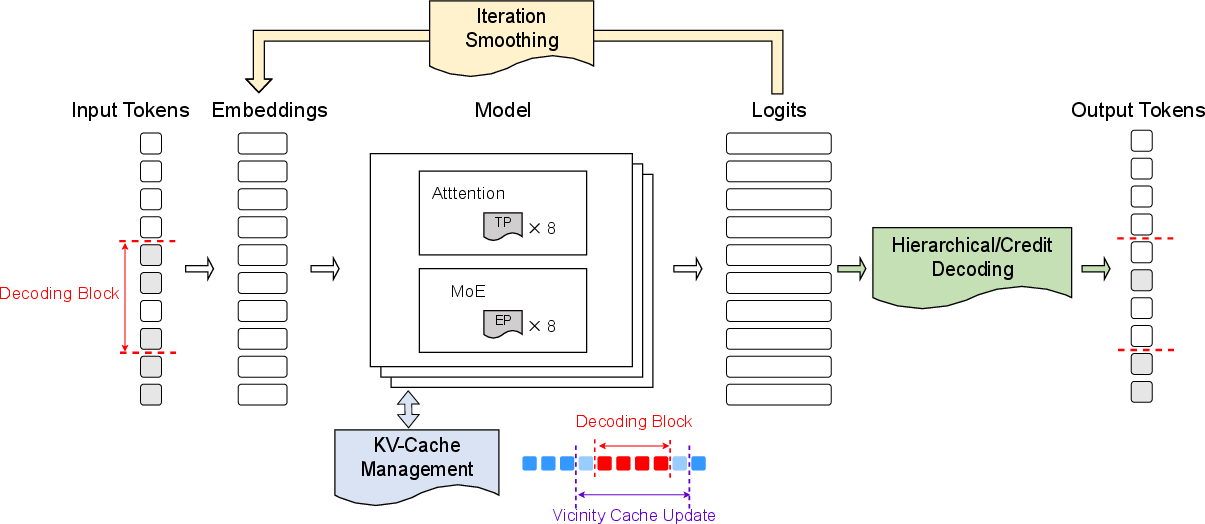
The four building blocks in dInfer
- Model: The actual LLM (like LLaDA-MoE), which predicts the next tokens.
- Diffusion iteration manager: The “round controller” that decides which parts of the sentence to improve in each step and passes information between steps.
- Decoding strategy: The rules for choosing which tokens to “lock in” (commit) during each round.
- KV-cache manager: A smart memory system that reuses past calculations where possible, so the model doesn’t redo expensive work every time.
Smart decoding strategies (how dInfer chooses tokens to commit)
To safely decode many tokens at once, dInfer uses:
- Threshold decoding: Commit tokens only when the model is very confident (above a preset threshold).
- Hierarchical decoding (new): Break masked spans into smaller chunks and make sure at least one token per chunk is committed. This reduces local confusion and speeds things up.
- Credit decoding (new): Give “credit points” to tokens that keep showing up as likely across multiple rounds. Tokens with strong, consistent scores get committed sooner.
Smarter memory and iteration tricks
- Iteration smoothing (new): Instead of ignoring uncertain positions, dInfer reuses their probability distributions to create better embeddings (representations) for the next round. Think of it like carrying forward a “soft hint” so later steps start with a smarter guess.
- Vicinity KV-cache refresh (new): KV-cache is a kind of “sticky note” that remembers attention calculations. In diffusion models, the whole sentence can change each round, so you can’t reuse everything. dInfer refreshes only the cache around the current decoding block (nearby tokens), and updates the whole cache when a block is fully decoded. This balances speed and accuracy.
- Blockwise decoding: Split the sequence into fixed-size blocks and improve them step by step.
- System-level speedups:
- Tensor parallelism: Split heavy math across multiple GPUs.
- Expert parallelism: For MoE models (mixture of experts), send work to different “specialist” networks and still run fast even with one request at a time.
- PyTorch compile + CUDA Graphs: Fuse many small GPU operations into bigger ones to reduce overhead.
- Loop unrolling: Keep GPU work flowing smoothly across iterations (fewer idle gaps).
- Early stopping: If the end-of-sequence token appears, stop immediately to avoid wasting time.
Training tweak to speed up decoding further
- Trajectory Distillation (TD): Teach the model to “jump” ahead by learning from its best past generation paths. This helps the model decode more tokens per step, increasing speed without changing the base architecture. The result is LLaDA-MoE-TD, a faster version of LLaDA-MoE.
What did they find?
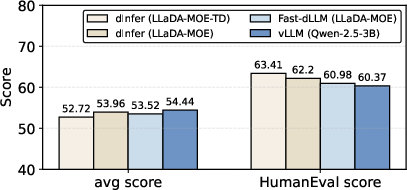
On strong hardware (8× NVIDIA H800 GPUs) and real benchmarks (code, math, and instruction-following), dInfer achieved:
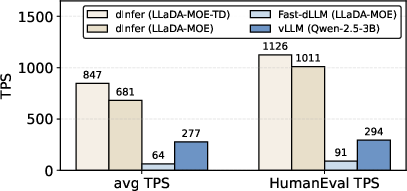
- Over 1,100 tokens per second (TPS) on HumanEval (a code test).
- Over 800 TPS on average across six benchmarks at batch size 1 (one question at a time).
Compared to other systems:
- About 10× faster than Fast-dLLM, with similar accuracy.
- About 2–3× faster than a well-optimized autoregressive model (Qwen2.5-3B running on vLLM), while keeping quality comparable.
With Trajectory Distillation (LLaDA-MoE-TD):
- Average TPS increased to about 847, beating the autoregressive baseline by more than 3×.
- The model committed more tokens per iteration (higher TPF), meaning each round did more useful work.
These results show diffusion LLMs can be extremely fast in practice—sometimes even faster than traditional models—if you design the inference carefully.
Why does this matter?
- Faster apps: High-speed inference means quicker responses in coding assistants, math tutors, and chatbots.
- Lower costs: Doing more work per GPU second reduces energy and cloud bills.
- New possibilities: Reliable parallel decoding opens the door to new features that are hard with one-token-at-a-time models.
- Fair comparisons: A standard framework helps researchers measure and improve diffusion models consistently.
Key takeaways
- Diffusion LLMs don’t have to be slow. With smart decoding, memory reuse, and GPU tricks, they can be very fast—sometimes faster than traditional models—even when handling one request at a time.
- dInfer’s four-part design (model, iteration manager, decoder, cache manager) makes it easy to plug in new ideas and test them fairly.
- New algorithms like hierarchical decoding, credit decoding, iteration smoothing, and vicinity KV-cache refresh make parallel decoding both safe and efficient.
- Trajectory Distillation trains diffusion models to “take bigger jumps,” increasing tokens-per-step and overall speed.
- The framework is open-source, so others can build on it: https://github.com/inclusionAI/dInfer
In short, dInfer shows that diffusion-based LLMs are not just a cool idea—they can be practical, fast, and ready for real-world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper—each item is stated concretely to guide future work.
- Generality across dLLM architectures: dInfer is evaluated only on LLaDA variants; test portability and performance on other diffusion LMs (e.g., different attention schemes, non-MoE models, larger/smaller sizes).
- Batch-size scalability: results are limited to batch size 1; measure throughput, latency, and GPU utilization under larger batch sizes and multi-tenant workloads.
- Long-context behavior: generation length is fixed (1024) with block size 64; study performance, stability, and accuracy for longer contexts (e.g., 4k–32k), including scaling laws and block-size sensitivity.
- Hyperparameter sensitivity: thresholds, smoothing weights, and cache windows are hand-picked; provide systematic sensitivity analyses and practical tuning guidelines across tasks.
- Iteration smoothing validity: no formal analysis of distribution shift or convergence; quantify when logits-to-embedding fusion harms or helps, and derive principled schedules for α and decode-threshold decay.
- Early-commit risks in hierarchical/credit decoding: investigate failure modes where premature commitments introduce irreversible errors; design rollback/error-correction mechanisms and measure semantic consistency impacts.
- KV-cache vicinity refresh policy: window sizes are fixed; develop adaptive or confidence-based refresh strategies, and characterize accuracy–speed trade-offs with theoretical or empirical bounds on staleness error.
- EOS early termination reliability: assess false-EOS detection and its effect on incomplete outputs (multi-part code, long reasoning, multi-section instructions); propose safeguards and validation checks.
- System-level ablations: isolate and quantify the contribution of torch.compile, CUDA Graphs, loop unrolling, TP, and EP individually across benchmarks and hardware.
- Memory and energy efficiency: report peak VRAM, memory fragmentation, and energy/cost per token; evaluate feasibility on consumer GPUs and under constrained memory budgets.
- Broader task coverage: expand beyond code/math/instruction to general NLG (summarization, translation, open-ended chat), multilingual settings, and safety/bias/toxicity benchmarks.
- Latency metrics and streaming: provide time-to-first-token, time-to-last-token, tail-latency distributions, and streaming behavior analyses for interactive applications.
- Fair comparison protocols: comparisons use different architectures (MoE vs dense) and dev toolchains; establish matched-parameter baselines, cross-hardware replication, and uniform software stacks.
- Trajectory Distillation/Compression scope: quantify domain generalization beyond math-heavy datasets, training cost, data requirements, and potential overfitting or degradation on non-math tasks.
- Compatibility with quantization/sparsity: evaluate FP8/INT8/INT4 quantization, structured sparsity, and memory-saving techniques; determine their interplay with bidirectional attention and caching.
- Robustness to noisy/adversarial inputs: test stability of parallel decoding under perturbations, ambiguous prompts, and long multi-step reasoning; define robustness metrics and mitigation strategies.
- Multi-turn dialogue and tool use: specify mechanisms for maintaining conversation state, tool outputs, and external memory under bidirectional attention and cache refreshes; evaluate in agentic workflows.
- Standardizing TPS/TPF reporting: propose a reproducible benchmark suite (fixed seeds, prompts, lengths, hardware, software versions) with public logs to avoid apples-to-oranges comparisons.
- Adaptive iteration scheduling: explore dynamic block sizing and step scheduling driven by confidence or uncertainty to optimize quality–speed trade-offs per input.
- Cross-node and multi-node scaling: evaluate performance on multi-node clusters, interconnect bottlenecks, and commodity hardware; characterize scaling efficiency and communication overheads.
- Theoretical grounding: develop formal criteria for decoding thresholds, smoothing schedules, and convergence guarantees in diffusion-based language generation.
- Cache-error detection and recovery: design mechanisms to detect staleness-induced errors (e.g., confidence drift) and trigger selective re-computation or targeted refreshes.
- Expert parallelism effects: analyze how EP impacts token quality and routing stability at batch size 1, including potential expert collapse or oscillations under rapid iterations.
- Safety and alignment: measure how aggressive parallel decoding affects jailbreak susceptibility and harmful outputs; integrate safety filters or alignment-aware decoding rules.
- Framework extensibility: document API stability and integration paths with RLHF/preference optimization pipelines and common inference servers (e.g., Triton, Ray Serve, Kubernetes autoscaling).
- Detailed ablations for decoding algorithms: beyond average metrics, report per-task breakdowns of error types, commit rates, and confidence dynamics to diagnose where each method helps or harms.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, organized by sector and supported by the paper’s concrete methods (hierarchical/credit decoding, iteration smoothing, vicinity KV-cache refresh, tensor/expert parallelism, CUDA Graphs, loop unrolling, EOS early-termination) and the open-source dInfer framework.
- Software/AI Infrastructure
- Low-latency dLLM serving at batch size 1
- Use case: Replace or complement AR LLM endpoints (e.g., chat, agents) with dLLM endpoints powered by dInfer to cut single-user latency and GPU costs.
- Tools/workflows: Integrate dInfer into existing serving stacks (vLLM backend, TorchServe/Triton, Ray); turn on TP+EP, torch.compile, CUDA Graphs; enable loop-unrolling and EOS early termination.
- Assumptions/Dependencies: NVIDIA GPUs (e.g., H800/A100/H100) with recent CUDA; PyTorch 2.9+; dLLM availability (e.g., LLaDA-MoE/-Instruct); quality parity validated for target tasks.
- Parallel-decoding A/B testing without retraining
- Use case: Swap threshold, hierarchical, and credit decoding per route to maximize tokens per forward on different workloads.
- Tools/workflows: dInfer’s modular APIs; CI pipelines that test TPS/TPF and task accuracy; telemetry dashboards for “TPS per sequence” reporting.
- Assumptions/Dependencies: Task-specific hyperparameter tuning for decode thresholds and IterSmooth weights; monitoring to detect quality regressions at large parallel spans.
- Developer Tools (Code Assistants, IDE Plugins)
- Faster code generation and live debugging
- Use case: Interactive code completion and test generation with reduced waiting time, especially for long outputs or multi-step solutions.
- Tools/products: dLLM-backed code assistant services; IDE plugins that call dInfer endpoints; EOS early-termination to stop once a solution is produced.
- Assumptions/Dependencies: dLLM trained or adapted for code; stable accuracy on datasets like HumanEval/MBPP; GPU inference for real-time use.
- Education
- Real-time math and reasoning tutors
- Use case: Deploy dLLM tutors for step-by-step math reasoning and long-form explanations with lower latency.
- Tools/workflows: dInfer with iteration smoothing to stabilize intermediate steps; hierarchical decoding to commit tokens reliably per span.
- Assumptions/Dependencies: Domain tuning and evaluation on GSM8K-like data; safeguards for correctness and pedagogical quality.
- Enterprise AI (General)
- Cost-efficient agent loops and tool-use orchestrations
- Use case: Internal copilots, RAG pipelines, and workflow agents that issue many short, sequential calls benefit from dInfer’s speed at batch size 1.
- Tools/workflows: Endpoint migration for dLLM-powered routes; KV vicinity refresh to balance speed and quality on bidirectional attention.
- Assumptions/Dependencies: Task fits dLLM strengths; observability for latency/accuracy trade-offs; GPU scheduling tuned for TP/EP.
- Academia
- Standardized dLLM inference benchmarking
- Use case: Adopt “TPS per sequence” and “TPF” metrics to fairly compare algorithms and systems; use dInfer as a reproducible baseline.
- Tools/workflows: Public benchmarks (HumanEval, GSM8K, etc.); ablation-ready configurations; shared scripts for caching/decoding variants.
- Assumptions/Dependencies: Community agreement on reporting conventions (hardware, batch size, lengths); dataset licensing.
- Policy and Governance
- Procurement and transparency standards for AI inference
- Use case: Require vendors to report TPS per sequence at batch size 1, energy-per-token, and accuracy on standardized suites when bidding for AI services.
- Tools/workflows: Internal policy templates referencing dInfer-style metrics and configurations; reproducibility checks.
- Assumptions/Dependencies: Access to comparable hardware; independent verification procedures; alignment with sustainability targets.
- Daily Life (Power Users, Local AI)
- Faster local assistants for long-form tasks
- Use case: Users with high-end GPUs run dLLM assistants (writing, math, coding) with less lag using dInfer.
- Tools/workflows: dInfer docker/conda setups; pre-configured profiles for “single-user, low-latency.”
- Assumptions/Dependencies: Local NVIDIA GPU; familiarity with dLLM models; quality expectations aligned with open-source dLLMs.
Long-Term Applications
These applications require further research, scaling, productization, or broader ecosystem adoption (models, hardware, standards).
- General-Purpose dLLM Inference Engines
- Mainstream integration into production inference stacks
- Use case: First-class support for dLLMs in major engines (Triton, vLLM, Ray Serve) with native TP+EP and CUDA Graph orchestration.
- Potential products: “dLLM-ready” serving runtimes; autoscaling schedulers optimized for iterative denoising loops.
- Assumptions/Dependencies: Widespread dLLM adoption; robust APIs across vendors; mature ops/tooling for cache refresh policies.
- Training Pipelines Using Trajectory Distillation (Trajectory Compression)
- Systematic reduction of diffusion steps across domains
- Use case: Fine-tune domain-specific dLLMs (math, code, legal) to “jump” multiple steps via golden trajectory distillation, improving TPF/TPS.
- Tools/workflows: Data collection harnesses with external verifiers (e.g., math_verify); curriculum for compressed transitions; offline evaluation loops.
- Assumptions/Dependencies: High-quality verifier availability; scalable data generation; guardrails to prevent overfitting or shortcut reasoning.
- Edge and Embedded Deployment
- Real-time language reasoning at the edge
- Use case: On-device assistants in robotics, AR/VR, and mobile with reduced latency leveraging parallel decoding and early termination.
- Tools/products: Lightweight dLLM variants; hardware-aware decoding schedules; memory-aware KV vicinity refresh implementations.
- Assumptions/Dependencies: Smaller, efficient dLLMs; hardware accelerators beyond high-end GPUs; careful power/thermal management.
- Sector-Specific Solutions
- Healthcare
- Use case: Low-latency clinical summarization and decision support where responsiveness matters during consultations.
- Tools/workflows: dLLM endpoints with confidence tracking (credit decoding) and audit logs of intermediate states (iteration smoothing artifacts).
- Assumptions/Dependencies: Regulatory clearance; rigorous validation; bias/safety monitoring; domain-verified trajectories.
- Finance
- Use case: Real-time compliance assistants and report drafting under strict SLAs.
- Tools/workflows: Parallel decoding tuned for long documents; EOS early termination to cut compute once policy criteria are met.
- Assumptions/Dependencies: Model robustness to domain-specific jargon; auditability; privacy and compliance constraints.
- Robotics
- Use case: Faster language-to-action planning in multi-step tasks via parallel refinements, reducing control-loop delays.
- Tools/workflows: Agent frameworks that exploit dLLM denoising iterations; integration with perception/action modules.
- Assumptions/Dependencies: Safety guarantees; deterministic control; on-device inference viability.
- Education
- Use case: Adaptive tutoring systems that generate multi-step solutions quickly while retaining accuracy via trajectory-tuned models.
- Tools/workflows: Distilled trajectories aligned with curricula; per-learner latency/quality knobs (decode thresholds, IterSmooth).
- Assumptions/Dependencies: Content quality assurance; avoidance of shortcut learning; fairness across learners.
- Hardware–Software Co-Design
- Accelerators tailored to iterative denoising and bidirectional attention
- Use case: New kernels and scheduling primitives that eliminate stream bubbles and maximize EP/TP utilization at small batch sizes.
- Tools/products: Vendor-optimized libraries for dLLMs; firmware/runtime features to support loop unrolling and cache refresh semantics.
- Assumptions/Dependencies: Industry interest; standardized dLLM primitives; cross-vendor portability.
- Benchmarking and Governance Standards
- Industry-wide adoption of fair, reproducible inference metrics
- Use case: TPS per sequence at standardized lengths/hardware; disclosure of caching/decoding configs; energy-per-token reporting.
- Tools/workflows: Public leaderboards; certification processes; audit trails with dInfer-like config manifests.
- Assumptions/Dependencies: Community consensus; third-party auditing; versioning of models and toolchains.
Cross-Cutting Assumptions and Dependencies
- Model availability and fitness: dLLMs (e.g., LLaDA-MoE/-Instruct/-TD) must match task accuracy requirements; large parallel spans may require careful tuning to avoid quality drops.
- Hardware and toolchains: Benefits rely on modern NVIDIA GPUs, CUDA Graphs, PyTorch compile, and expert/tensor parallelism; portability to other hardware stacks may need additional engineering.
- Task profiles: Gains are highest for long outputs and multi-step reasoning; short or highly constrained tasks may see smaller relative improvements.
- Operational readiness: Observability (TPS/TPF, accuracy, energy), guardrails, and fallback routes (AR models) are prudent for production deployments.
Glossary
- Autoregressive (AR) LLMs: LLMs that generate output sequentially, one token at a time, conditioning each token on all previous ones. "Diffusion-based LLMs (dLLMs) have emerged as a promising alternative to autoregressive (AR) LLMs, leveraging denoising-based generation to enable inherent parallelism."
- Bidirectional attention: An attention mechanism where each token can attend to all others (both past and future positions), allowing mutual influence across the sequence. "dLLMs employ bidirectional attention, meaning that decoding a single token can affect the representations of all tokens in the sequence."
- Blockwise caching: A training-free KV-cache strategy that reuses attention key/value states for blocks of tokens to reduce recomputation. "Earlier approaches introduced training-free strategies such as blockwise caching and Dual Cache \citep{wu2025fast}, which reuse KV states for decoded tokens or suffixes of masked tokens."
- Blockwise decoding: A decoding procedure that processes the sequence in fixed-size blocks, potentially enabling early stopping once completion conditions are met. "We also introduce an early termination mechanism for blockwise decoding."
- Blockwise diffusion iteration: A diffusion-based decoding approach that denoises fixed-size spans in each iteration. "The blockwise diffusion iteration algorithm performs decoding in fixed-size spans and serves as a baseline (Algorithm~\ref{alg:blockwise})."
- Causal attention: An attention pattern where each token can only attend to previous tokens, enabling KV reuse in autoregressive models. "In AR models, causal attention allows KV states to be computed once and reused; in dLLMs, however, token representations evolve across denoising steps, making static reuse infeasible."
- Credit decoding: A parallel decoding algorithm that accumulates historical confidence as “credits” to commit consistently stable tokens earlier. "Credit decoding (ours): accumulates historical confidence scores as credits and preferentially commits tokens with consistently stable predictions, improving reliability across iterations."
- CUDA Graphs: A CUDA feature that captures and replays sequences of GPU operations to reduce launch overhead and improve performance. "dInfer uses PyTorch's just-in-time (JIT) compiler torch.compile to fuse CUDA kernels and execute them within NVIDIA CUDA Graphs, thereby eliminating PyTorch execution overhead."
- CUDA stream bubbles: Idle gaps between consecutive GPU kernel launches on CUDA streams that cause underutilization and throughput loss. "Diffusion iterations can suffer from CUDA stream bubbles--idle gaps of consecutive kernel launches between diffusion iterations--which waste GPU cycles and reduce throughput."
- Denoising-based generation: A generative process that iteratively refines noisy sequences toward clean outputs, enabling parallel token updates. "Diffusion-based LLMs (dLLMs) have emerged as a promising alternative to autoregressive (AR) LLMs, leveraging denoising-based generation to enable inherent parallelism."
- Diffusion-based LLMs (dLLMs): LLMs that generate text by iteratively denoising entire sequences rather than producing tokens sequentially. "Diffusion-based LLMs (dLLMs) have emerged as a promising alternative to autoregressive (AR) LLMs, leveraging denoising-based generation to enable inherent parallelism."
- Diffusion iteration manager: The controller of iterative denoising that selects regions to decode, runs model passes, and tracks history for context. "The diffusion iteration manager acts as the controller of the iterative denoising process, with three main responsibilities: 1) determining the next region of tokens to decode, 2) interacting with the model to obtain outputs such as logits and hidden states, 3) maintaining historical predictions to provide a richer context for future decoding."
- Dual Cache: A KV-cache reuse method that caches two sets of key/value states (e.g., for decoded and masked segments) to reduce computation. "Earlier approaches introduced training-free strategies such as blockwise caching and Dual Cache \citep{wu2025fast}, which reuse KV states for decoded tokens or suffixes of masked tokens."
- End-of-sequence (EOS) token: A special token indicating sequence termination, enabling early stopping in generation. "Once an end-of-sequence (EOS) token is generated within a block, subsequent decoding steps on the remaining blocks become redundant."
- Expert parallelism (EP): A distributed inference/training scheme that parallelizes computation across experts in Mixture-of-Experts models. "Expert parallelism is applied to the LLaDA-MoE model and is effective even at a batch size of 1--unlike in AR models, where expert parallelism typically requires large batch sizes."
- Hierarchical decoding: A divide-and-conquer parallel decoding method that recursively splits masked spans to reduce local dependencies and ensure progress. "Hierarchical decoding (ours): recursively partitions masked spans, ensuring at least one token is decoded per region, thereby reducing local dependencies and improving efficiency."
- Iteration smoothing: A technique that carries information across denoising steps by fusing previous iteration representations into current embeddings. "The iteration smoothing algorithm improves upon this by retaining token representations from the previous iteration and fusing them with the next iteration’s embeddings."
- K and V states: The keys (K) and values (V) computed in attention layers, often cached to avoid recomputation. "During denoising, K and V states are recomputed for both masked tokens and their immediate neighbors; once a block is fully decoded, a full cache update ensures global consistency."
- KV-cache: A cache of attention keys and values used to speed up Transformer inference by reusing intermediate states. "A central challenge in dLLM inference is KV-cache incompatibility."
- Logits: The unnormalized model outputs (pre-softmax) representing token scores before conversion to probabilities. "interacting with the model to obtain outputs such as logits and hidden states"
- Loop unrolling: An execution optimization that restructures loops to minimize overhead and keep GPU pipelines busy. "To address this, dInfer applies a loop unrolling strategy that allows Python to launch CUDA kernels continuously without being blocked by stream synchronization."
- Tensor parallelism (TP): Model-parallel technique that splits tensor computations across GPUs to accelerate large models. "Tensor parallelism is applied to the linear layers preceding attention modules, distributing dense computations efficiently across multiple GPUs."
- Threshold decoding: A parallel decoding heuristic that commits tokens whose confidence exceeds a preset threshold. "Threshold decoding (from Fast-dLLM \citep{wu2025fast}): commits tokens whose confidence exceeds a preset threshold."
- Tokens per forward (TPF): A throughput metric measuring how many tokens are committed per diffusion iteration per sequence. "To evaluate the efficiency of the dInfer framework, we use tokens per forward (TPF) per sequence to measure the parallel decoding capability within a single diffusion iteration, and tokens per second (TPS) per sequence to assess overall inference efficiency."
- Tokens per second (TPS): A throughput metric measuring the number of generated tokens per second per sequence. "To evaluate the efficiency of the dInfer framework, we use tokens per forward (TPF) per sequence to measure the parallel decoding capability within a single diffusion iteration, and tokens per second (TPS) per sequence to assess overall inference efficiency."
- torch.compile: PyTorch’s JIT compilation API that fuses and optimizes kernels for faster execution. "dInfer uses PyTorch's just-in-time (JIT) compiler torch.compile to fuse CUDA kernels and execute them within NVIDIA CUDA Graphs, thereby eliminating PyTorch execution overhead."
- Trajectory Compression: A fine-tuning method that trains the model to “jump” multiple denoising steps by learning compressed transitions along high-quality trajectories. "we propose a novel second-stage fine-tuning method, termed Trajectory Compression, to explicitly reduce the number of required sampling steps."
- Trajectory Distillation: A post-training technique that uses effective generation trajectories to improve parallel decoding efficiency. "Specifically, we introduce Trajectory Distillation, applied to LLaDA-MoE, yielding the enhanced LLaDA-MoE-TD variant (see Section~\ref{sec:TD})."
- vLLM: A high-performance LLM inference engine used as the backend for execution and parallelism. "dInfer builds on vLLM’s backend to exploit two complementary forms of parallelism."
- Vicinity KV-cache refresh: A cache update strategy that selectively recomputes K/V states for a local window near the current decoding block to reduce staleness. "To balance cost and performance, dInfer introduces vicinity KV-cache refresh."
Collections
Sign up for free to add this paper to one or more collections.

