Multi-Agent Memory from a Computer Architecture Perspective: Visions and Challenges Ahead
Abstract: As LLM agents evolve into collaborative multi-agent systems, their memory requirements grow rapidly in complexity. This position paper frames multi-agent memory as a computer architecture problem. We distinguish shared and distributed memory paradigms, propose a three-layer memory hierarchy (I/O, cache, and memory), and identify two critical protocol gaps: cache sharing across agents and structured memory access control. We argue that the most pressing open challenge is multi-agent memory consistency. Our architectural framing provides a foundation for building reliable, scalable multi-agent systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Multi-Agent Memory from a Computer Architecture Perspective: Visions and Challenges Ahead”
What is this paper about?
This paper looks at how groups of AI “agents” (think: smart chatbots that can work together) remember and share information. The authors say that as these agents team up and handle more complex tasks—like dealing with long conversations, images, videos, and computer actions—the big bottleneck is memory: what to keep, where to keep it, how to share it, and how to avoid mixing things up. They argue we should design agent memory the way we design computer memory.
What questions are the authors trying to answer?
The authors focus on simple but important questions:
- How should multiple AI agents store and share information without getting confused?
- Should agents use one shared memory or each keep their own, and how do we sync them?
- What “layers” of memory do agents need to be fast and reliable?
- What rules (protocols) do agents need to safely share short-term notes and long-term facts?
- How can we keep all agents’ memories consistent so everyone sees the right, up-to-date information?
How do they approach the problem?
Instead of running big experiments, this is a “position paper” that offers a blueprint. The authors borrow ideas from how computer memory works and translate them for AI agents.
They compare two basic ways to organize memory, using everyday analogies:
- Shared memory: Like a shared Google Doc. All agents write and read the same place. It’s easy to reuse info, but people can overwrite each other, read old versions, or see conflicting edits if there aren’t clear rules.
- Distributed memory: Like each student keeping their own notebook and only sharing pages when needed. It scales better and avoids stepping on each other’s toes, but it’s hard to keep everyone in sync.
Then they describe a three-layer memory “stack” for agents:
- Agent I/O (input/output): How agents take in and send out info (like ears and mouth—text, images, tool calls).
- Agent cache (short-term): A small, fast “scratchpad” for immediate reasoning (like sticky notes or what’s in your head during a test).
- Agent memory (long-term): Bigger, slower storage for history and knowledge (like a binder or bookshelf—databases, document stores).
They say the real challenge is “moving the right information to the right layer at the right time,” just like in computers.
They also point out two missing sets of rules (protocols) agents need:
- Cache sharing rules: How one agent can reuse another’s short-term work without copying entire conversations.
- Memory access rules: Who can read or write what, and at what level of detail (a whole document, a paragraph, a single record)?
Finally, they highlight a major open problem: consistency—making sure all agents see updates in a reasonable order and don’t act on stale or contradictory info.
What did they find or argue, and why does it matter?
Here’s what the authors claim is most important:
- Context is getting complex: Agents now need to handle long histories, images and videos, structured data (like database steps), and changing environments (like editing code on a computer). That means memory isn’t just a “prompt”—it’s a whole system.
- Memory needs a hierarchy: Just like computers have fast caches and larger main memory, agents need fast short-term notes and bigger long-term stores. Performance depends on smart “caching,” not just more compute.
- Two protocol gaps slow us down:
- No standard way to share short-term caches between agents.
- No standard way to control who can access what in long-term memory.
- The biggest challenge is multi-agent consistency: If one agent updates a fact (say, a customer’s phone number), when and how do other agents see the change? What if two agents update the same thing at the same time? The paper says we need clear, explicit rules for versions, visibility, and how to resolve conflicts—similar to how computers manage memory updates.
Why this matters: Without these structures and rules, multi-agent systems can become slow, wasteful, or error-prone—like a group project where everyone writes different answers because they saw different versions of the notes.
What could this change in the future?
If we design agent memory more like computer memory:
- Teams of AI agents could collaborate more reliably and faster, reusing each other’s work instead of repeating it.
- Systems could scale to bigger tasks (longer dialogues, more data, richer media) without falling apart.
- Developers could build safer and clearer apps by setting standard rules for who can read/write what.
- Research can focus on clear targets: cache-sharing protocols, memory access permissions, and consistency models that prevent “he-said, she-said” data problems.
Bottom line
The paper says: to make groups of AI agents truly useful, we must treat their memory like a carefully engineered system—with layers, sharing rules, and consistency guarantees. This architectural perspective gives a roadmap for building smarter, more dependable multi-agent systems.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what the paper leaves missing, uncertain, or unexplored, articulated as concrete, actionable gaps for future work:
- Formal specification and taxonomy of multi-agent memory consistency models (e.g., sequential, causal, eventual) for semantic artifacts, including precise visibility and ordering rules.
- Concrete versioning scheme for heterogeneous artifacts (text, images, graphs, tool traces): unit of versioning, lineage/provenance, causal metadata (e.g., vector clocks), and garbage-collection policies.
- Conflict detection and resolution algorithms tailored to semantic conflicts (contradictory facts, incompatible plans), including handling of speculative updates, retractions, and reconciliation policies.
- Transaction and isolation semantics for agent memory (atomic commits, read/write sets, isolation levels) under message-passing constraints and partial failures.
- A standardized cross-agent cache sharing protocol beyond ad hoc KV reuse: canonical wire formats, compatibility across model families/tokenizers, transformation functions, and validation/verification steps.
- Security and privacy for cache sharing: authentication/authorization, integrity checks, differential access to latent states, and defenses against side-channel leakage through shared KV/hidden states.
- Memory access control protocol: permission granularity (record, chunk, trace segment), scope (session/task/org), auditability, revocation semantics, and multi-tenancy isolation.
- Interoperability standards across agent frameworks (e.g., MCP, LangGraph, AutoGen) for memory APIs, schemas, and transport/wire protocols.
- Unified schema/ontology for multimodal and structured memory items (documents, embeddings, code, graphs, images, videos, execution traces) to enable consistent indexing, addressing, and access.
- Provenance and trust metadata: how to attach, verify, propagate, and use source, confidence, and attestation in read-time selection and conflict resolution.
- Benchmarks and metrics to evaluate multi-agent memory: staleness, visibility latency, conflict rate, consistency violations, memory hit rate, cache reuse efficiency, and task success under consistency stress.
- Representative workloads/simulators for memory stress testing (long-horizon collaborative coding, multi-tool planning, environment-coupled tasks) with controllable concurrency and update contention.
- Performance models and empirical trade-off studies for caching, prefetching, and coherence traffic vs. task accuracy, latency, and cost.
- Scalable designs for shared/distributed memory (sharding, replication, partitioning), including CAP-style trade-offs and placement/routing policies.
- Fault tolerance and recovery semantics: idempotent writes, deduplication, rollback/roll-forward, durable checkpoints, and exactly-once or at-least-once guarantees for memory updates.
- Handling environment-coupled state: linking memory updates to external side effects/tools, ensuring read-after-write correctness across agent-environment boundaries.
- Data lifecycle management: summarization, compaction, retention/forgetting policies that preserve consistency, utility, and privacy across distributed caches/stores.
- Privacy and compliance mechanisms: PII redaction, encryption in transit/at rest, access logging, differential privacy, and right-to-be-forgotten across replicas and ephemeral caches.
- Mitigating error propagation: detection and quarantine of hallucinated or corrupted memory, rollback strategies, and reputation/credit assignment for sources and agents.
- Learning-based memory management: training adaptive policies for caching, routing, and synchronization; safe online learning signals; exploration–exploitation trade-offs.
- Cost and energy analysis of memory movement (KV sharing, synchronization, retrieval), with cost-aware orchestration policies and budgets.
- Formal verification/model checking of memory protocols to ensure safety (e.g., no forbidden reorderings) and liveness under asynchrony and partial failures.
- Practical semantics for eventual consistency in semantic memory: acceptable divergence bounds, reconciliation windows, and user-facing consistency SLAs.
- Identity resolution and deduplication across agents/modalities (entity linking, canonicalization) to avoid incoherent duplication and drift.
- Real-time constraints: scheduling and QoS policies that meet latency budgets for reads/writes in interactive, multimodal tasks.
- Heterogeneous agent compatibility: bridging different LLM architectures, tokenizers, and modalities for shared artifacts (e.g., KV alignment, latent-space adapters).
- Observability and debugging: end-to-end tracing, memory state inspection, reproducibility under concurrency, and developer tooling for diagnosing consistency bugs.
- Economic and incentive mechanisms for open ecosystems: rate limiting, cost attribution, quality incentives, and anti-spam/abuse protections for shared memory.
- Ethical governance for shared memory: consent, data ownership, bias amplification risks, and cross-agent influence guardrails.
- Reference implementations and empirical validation: working prototypes of the proposed hierarchy and protocols on real tasks, with ablations and comparative baselines.
Practical Applications
Immediate Applications
The following applications can be deployed with current frameworks and infrastructure, leveraging the paper’s memory hierarchy framing (I/O–cache–memory), shared vs. distributed designs, and the identified protocol gaps (cache sharing and memory access control).
- Bold memory-hierarchy engineering for current multi-agent stacks
- Sectors: software, enterprise IT, platforms
- What it looks like: Refactoring LangGraph/AutoGen/LangChain agents to explicitly separate I/O, cache (KV caches, recent tool outputs), and long-term memory (vector/graph/document stores). Introduce cache eviction, prefetching, and pinning policies; ensure data is loaded in the right layer when needed.
- Derived from: Three-layer hierarchy; “agent performance is a data movement problem.”
- Tools/workflows: Middleware that tracks “context misses,” cache-hit dashboards, policy-driven context construction.
- Assumptions/dependencies: Access to agent code; observability hooks into vector DBs and model KV caches; stable retrieval pipelines.
- Cross-agent artifact reuse (lightweight cache sharing)
- Sectors: customer support, software dev-assistance, research co-pilots
- What it looks like: Agents share reusable artifacts—tool outputs, embeddings, structured plans, partial parses—via a shared “artifact bus” to avoid redundant work and reduce token costs.
- Derived from: Missing piece 1—cache sharing beyond raw KV; shared vs. distributed memory trade-offs.
- Tools/workflows: Shared artifact registry with TTL/version tags; adapters to transform artifacts across agents.
- Assumptions/dependencies: Co-location or fast network; compatible schemas for artifact formats; privacy filters.
- Memory access control for agent teams (RBAC/ABAC over memory)
- Sectors: healthcare, finance, legal, HR, government
- What it looks like: Enforce read/write scopes, permissions, and granularity (document vs. chunk vs. record vs. trace segment) for shared memory. Add audit logs and PII guards.
- Derived from: Missing piece 2—structured memory access protocol (permissions, scope, unit of access).
- Tools/workflows: Memory gateway with policy engine; mapping to data catalogs and DLP tools.
- Assumptions/dependencies: Clear data classification; integration with IAM; regulatory alignment (HIPAA, GDPR).
- Versioned artifact stores with simple conflict rules
- Sectors: software engineering (coding agents), MLOps, analytics
- What it looks like: Store plans, tool traces, and evidence as versioned records; enforce “last-writer-wins” or reviewer-in-the-loop merges; tag speculative vs. committed updates.
- Derived from: Read-time conflict handling and update-time visibility; call for explicit versioning/visibility.
- Tools/workflows: Git-like artifact repos; plan “transactions” that commit atomically; human approvals for merges.
- Assumptions/dependencies: Discipline in tagging artifacts; lightweight consistency acceptable; reviewer capacity.
- Memory observability and SRE for agents
- Sectors: platform engineering, AIOps
- What it looks like: Instrument memory pipelines with metrics (cache hit rate, context miss penalties, bandwidth, staleness). Alert on incoherent context or excessive memory thrashing.
- Derived from: End-to-end data movement emphasis; hierarchy design.
- Tools/workflows: Prometheus/Grafana dashboards, tracing of memory accesses, synthetic probes for recall latency.
- Assumptions/dependencies: Unified logging; consistent IDs for artifacts; performance budgets.
- RAG data-movement optimization (prefetching and caching)
- Sectors: search, CRM, knowledge management, support
- What it looks like: Prefetch likely-needed documents into fast caches; pin high-utility facts in short-term memory; demote stale items; batch memory reads to reduce I/O.
- Derived from: Cache layer design; analogy to hardware caching.
- Tools/workflows: Relevance forecasting; LRU/LFU policies; heuristic or learned prefetchers.
- Assumptions/dependencies: Quality signals for relevance; retriever stability; predictable task patterns.
- Team-of-agents collaboration patterns with scoped sharing
- Sectors: education (tutoring teams), enterprise KM, marketing/content ops
- What it looks like: Each agent keeps local working memory, and selectively publishes shareable artifacts to a common store with clear scope (read-only snippets, approved templates).
- Derived from: Shared vs. distributed memory; “between extremes” hybrid design.
- Tools/workflows: Publish/subscribe channels for artifacts; moderation queues.
- Assumptions/dependencies: Defined roles; socialization of sharing norms; minimal consistency requirements.
- Benchmarking harnesses for memory behavior
- Sectors: academia, model vendors, enterprise eval teams
- What it looks like: Create tests for cache-hit effectiveness, stale-read rates, revision handling, and memory bandwidth under long-context tasks.
- Derived from: Positioning memory as the bottleneck; need to evaluate coherence and data movement.
- Tools/workflows: Synthetic long-horizon tasks; multimodal memory stress tests; reproducible traces.
- Assumptions/dependencies: Access to model internals/telemetry; dataset licenses; community adoption.
- Edge/robot teams with simple distributed memory sync
- Sectors: robotics (warehousing, inspection), IoT
- What it looks like: Each robot maintains on-device memory and periodically synchronizes summaries to a hub; use version tags to prevent outdated plans/actions.
- Derived from: Distributed memory paradigm and selective synchronization.
- Tools/workflows: Periodic snapshotting; diff-based sync; conflict logs.
- Assumptions/dependencies: Intermittent connectivity; tolerance for eventual consistency; safety overrides.
- Personal multi-device assistants with access-scoped long-term memory
- Sectors: consumer, productivity
- What it looks like: Phone, laptop, and home hub agents share long-term notes/tasks with device-scoped permissions (e.g., voice transcripts read-only on laptop).
- Derived from: Hierarchy and access control protocol needs.
- Tools/workflows: Encrypted memory store; per-device RBAC; user consent UI.
- Assumptions/dependencies: Cross-device identity; end-to-end encryption; latency-tolerant UX.
Long-Term Applications
These require advances in formal models, protocols, or infrastructure (as the paper calls for explicit cache-sharing protocols, memory access standards, and multi-agent consistency models).
- Formal multi-agent memory consistency models and engines
- Sectors: cross-sector foundational infrastructure
- What it looks like: “Agent consistency levels” (e.g., causal semantic consistency) specifying visibility/ordering for reads and writes; runtime enforcing versioning and conflict resolution for heterogeneous artifacts.
- Derived from: The paper’s central challenge—multi-agent consistency (read-time conflicts, update-time visibility and ordering).
- Assumptions/dependencies: Agreement on semantics for artifacts; standardized metadata; performance-efficient enforcement.
- Standardized cache-sharing protocol across models/vendors
- Sectors: platforms, cloud AI, ISVs
- What it looks like: Open protocol for exchanging cached artifacts (beyond raw KV), with transforms, provenance, and security. Think “cache-to-cache” for agents.
- Derived from: Missing piece 1—cache sharing protocol.
- Assumptions/dependencies: Vendor cooperation; IP/licensing clarity; privacy-preserving transformations.
- Cross-agent memory access protocol with governance and auditing
- Sectors: healthcare, finance, public sector
- What it looks like: An open, auditable API spec defining permissions, granularity units, scopes, and consent for shared memories; integrates with compliance tooling.
- Derived from: Missing piece 2—structured access control (permissions, scope, granularity).
- Assumptions/dependencies: Standards bodies/consortia; certification pathways; regulator buy-in.
- Agent OS/runtime with first-class memory hierarchy
- Sectors: software platforms, device ecosystems
- What it looks like: An “Agent OS” that natively manages I/O–cache–memory layers, prefetching, eviction, and consistency; apps register memory policies and SLAs.
- Derived from: Architecture-inspired hierarchy; end-to-end data movement.
- Assumptions/dependencies: Ecosystem consolidation; developer tooling; backward compatibility with current frameworks.
- Hardware–software co-design: KV/cache fabrics for agents
- Sectors: semiconductors, cloud providers, edge devices
- What it looks like: Accelerators and interconnects optimized for cross-agent cache exchange and memory bandwidth; near-memory compute for embedding ops.
- Derived from: Architectural analogy; cache sharing importance and bandwidth limits.
- Assumptions/dependencies: Silicon roadmaps; open interfaces; clear ROI from latency/cost savings.
- Semantic CRDTs/merge frameworks for agent artifacts
- Sectors: collaborative software, analytics, documentation
- What it looks like: Conflict-free replicated data types extended to plans, tool traces, and evidence graphs; semantics-aware merges (e.g., deduping contradictory claims).
- Derived from: Need for explicit conflict-resolution rules and versioning.
- Assumptions/dependencies: Formalization of artifact semantics; evaluation corpora; performance constraints.
- Compliance-grade sector stacks (EHR-/trading-ready agent memory)
- Sectors: healthcare, finance
- What it looks like: Memory layers with fine-grained consent, immutable audit trails, redaction on read, and transactional visibility guarantees; automated SOC2/HIPAA/GDPR evidence.
- Derived from: Access control and consistency models adapted to regulated data.
- Assumptions/dependencies: Legal standards mapping; certifiable runtimes; robust de-identification.
- Multi-modal, structured memory with versioned consistency
- Sectors: media, education, engineering
- What it looks like: Unified stores for text, images, videos, and executable traces with consistent version histories and cross-modal references; agents reason over synchronized views.
- Derived from: Context shift to multimodal/structured traces; consistency requirement.
- Assumptions/dependencies: Storage formats and schemas; efficient cross-modal indexing; high-bandwidth I/O.
- Knowledge and artifact marketplaces
- Sectors: enterprise ecosystems, research
- What it looks like: Marketplaces that trade validated artifacts (summaries, plans, embeddings) with provenance and expiry policies; agents purchase/share caches under license.
- Derived from: Cache sharing and shared memory reuse at scale.
- Assumptions/dependencies: IP frameworks; trust and verification; standard artifact schemas.
- Zero-trust memory planes and privacy-preserving exchange
- Sectors: security, public sector, defense
- What it looks like: Memory exchange over encrypted channels with hardware-backed attestation; differential privacy or secure computation for sensitive artifacts.
- Derived from: Access protocol needs and risks of shared caches.
- Assumptions/dependencies: Practical privacy tech (DP/HE/MPC) with acceptable latency; attestation infrastructure.
- Fleet-level autonomy with consistent shared memory
- Sectors: energy (smart grids), mobility (traffic control), logistics
- What it looks like: Many agents coordinating via shared, consistent state (plans, telemetry), with clear visibility/ordering guarantees to prevent contradictions in control.
- Derived from: Multi-agent consistency; distributed memory with synchronization.
- Assumptions/dependencies: High availability networks; safety cases; real-time constraints and formal verification.
- Research benchmarks and certification for agent consistency
- Sectors: academia, standards bodies, vendors
- What it looks like: Community suites testing visibility/ordering semantics across agent systems; certifications for “consistency levels” akin to database isolation levels.
- Derived from: Call for principled consistency models and protocols.
- Assumptions/dependencies: Shared taxonomies; neutral hosts; long-term maintenance.
Notes on Assumptions and Dependencies Across Applications
- Model and framework compatibility: Effective cache/artifact sharing may require similar tokenizers, architectures, or adapters.
- Trust, safety, and governance: Shared memory creates privacy and misuse risks; policies and audits are essential.
- Network and co-location: Benefits of cache sharing and bandwidth-sensitive designs depend on deployment topology and latency budgets.
- Human-in-the-loop: Many conflict-resolution and access-control workflows initially rely on human approval before automation is safe.
- Standardization: Broad interoperability hinges on open protocols (extensions to MCP or new standards) and vendor participation.
- Evaluation and monitoring: Without observability, hierarchy and consistency gains are hard to quantify and maintain.
Glossary
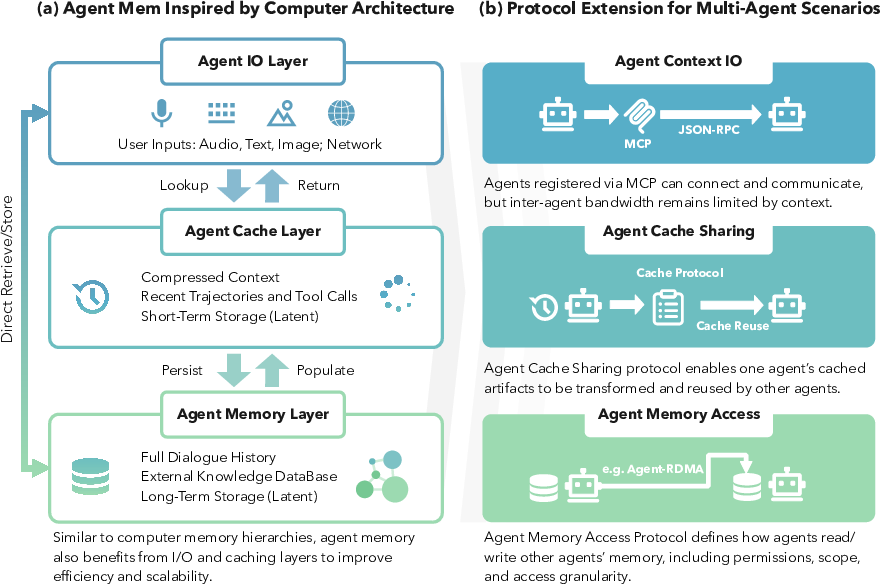
- Agent cache layer: A fast, short-term memory tier for immediate reasoning artifacts. "Agent cache layer: fast, limited-capacity memory for immediate reasoning (compressed context, recent tool calls, short-term latent storage such as KV caches and embeddings)."
- Agent context I/O: The communication layer for exchanging context between agents and tools. "This layer is best viewed as agent context I/O, e.g. MCP~\cite{anthropic_mcp_intro}."
- Agent I/O layer: Interfaces for ingesting and emitting multimodal information. "Agent I/O layer: Interfaces that ingest and emit information (audio, text documents, images, network calls)."
- Agent memory access protocol: Rules governing how agents read and write shared or private memory. "Missing piece 2: Agent memory access protocol."
- Agent memory layer: Large, persistent storage optimized for retrieval and long-term state. "Agent memory layer: large-capacity, slower memory optimized for retrieval and persistence (full dialogue history, vector DBs, graph DBs, and document stores)."
- Bandwidth: The rate at which data can be transferred between components or agents. "In computer systems, performance and scalability are often limited not by compute but by memory hierarchy, bandwidth, and consistency."
- Cache sharing: Mechanisms that let agents reuse each other’s cached computations or representations. "Missing piece 1: Agent cache sharing protocol."
- Cache transfers: Direct movement of cached data between processing entities (by analogy to multiprocessors). "The goal is to enable one agent's cached results to be transformed and reused by another, analogous to cache transfers in multiprocessors."
- Coherence constraints: Requirements ensuring data seen by agents is not stale or conflicting. "As such, context is no longer a static prompt; it is a dynamic memory system with bandwidth, caching, and coherence constraints."
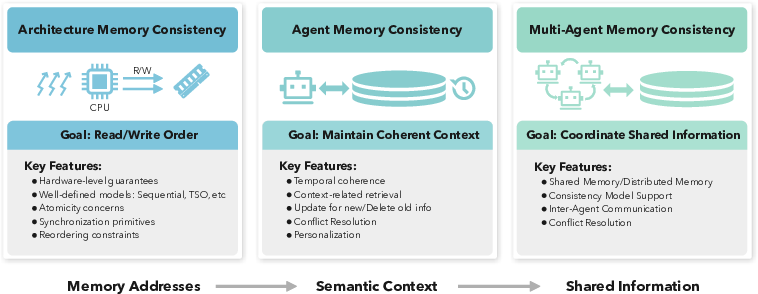
- Consistency models: Formal rules determining visibility and ordering of reads/writes in shared memory. "In computer architecture, consistency models~\cite{sorin2011primer} specify which updates are visible to a read and in what order concurrent updates may be observed."
- Context windows: The maximum span of input tokens a model can attend to at once. "Longer context windows: Suites like RULER \cite{hsieh2024ruler} emphasize reasoning over long histories, not just retrieval."
- Distributed memory: A paradigm where each agent maintains its own local memory and synchronizes selectively. "In \emph{distributed memory}, each agent owns local memory and synchronizes selectively."
- End-to-end data movement: A performance perspective focusing on moving relevant data through all system layers. "This framing emphasizes a key principle: \textbf{agent performance is an end-to-end data movement problem}."
- Graph DBs: Databases that store and query data as nodes and edges for relationship-centric retrieval. "Agent memory layer: large-capacity, slower memory optimized for retrieval and persistence (full dialogue history, vector DBs, graph DBs, and document stores)."
- KV cache: Key–value attention cache storing previous token states to speed up transformer decoding. "Agent cache layer: fast, limited-capacity memory for immediate reasoning (compressed context, recent tool calls, short-term latent storage such as KV caches and embeddings)."
- KV cache sharing: Exchanging key–value attention caches across agents or models for efficiency. "Recent work explores KV cache sharing~\cite{liu2024droidspeak, fu2025cache, ye2025kvcomm}, but we lack a principled protocol for sharing cached artifacts across agents."
- Memory hierarchy: A layered organization of memory with different latency, bandwidth, and capacity characteristics. "We distinguish shared and distributed memory paradigms, propose a three-layer memory hierarchy (I/O, cache, and memory), and identify two critical protocol gaps..."
- Message passing: Communication method where agents exchange information via discrete messages. "Many systems rely on connectivity protocols, but inter-agent bandwidth remains limited by message passing."
- Multi-agent memory consistency: Guarantees about how updates from multiple agents become visible and ordered. "For agent memory systems, multi-agent memory consistency decomposes into two requirements:"
- Multi-hop tracing: Reasoning over sequences of linked pieces of information across multiple steps. "LLM evaluations show that 'real' context ability involves more than simple retrieval; it requires multi-hop tracing, aggregation, and sustained reasoning as context length scales."
- Multimodal: Involving multiple data modalities (e.g., text, images, video) in reasoning. "Multimodal benchmarks add images, diagrams, and videos."
- Planner--orchestrator stacks: Agent architectures separating task planning from execution coordination. "LLM agents... to multi-agent systems: tool-using agents, planner--orchestrator stacks~\cite{langgraph_overview}, debate teams..."
- Read-time conflict handling: Policies for resolving inconsistencies when reading evolving records with multiple versions. "For agent memory systems, multi-agent memory consistency decomposes into two requirements: read-time conflict handling under iterative revisions, where records evolve across versions and stale artifacts may remain visible,"
- Shared memory: A paradigm where multiple agents read and write to a common memory pool. "In shared memory, all agents access a shared pool (e.g., a shared vector store or document database)."
- Structured memory access control: Fine-grained, rule-based governance of who can access which memory units and how. "We distinguish shared and distributed memory paradigms, propose a three-layer memory hierarchy (I/O, cache, and memory), and identify two critical protocol gaps: cache sharing across agents and structured memory access control."
- Synchronization: Coordination mechanisms ensuring agents’ states remain consistent when operating concurrently. "\textbf{Distributed memory} improves isolation and scalability but requires explicit synchronization; state divergence becomes common unless carefully managed."
- Vector DBs: Databases optimized for indexing and retrieving vector embeddings (e.g., for similarity search). "Agent memory layer: large-capacity, slower memory optimized for retrieval and persistence (full dialogue history, vector DBs, graph DBs, and document stores)."
- Vector store: A repository for vector embeddings to enable nearest-neighbor retrieval. "In shared memory, all agents access a shared pool (e.g., a shared vector store or document database)."
- Versioning: Managing multiple versions of memory artifacts over time for consistency and rollback. "A practical direction is to make versioning, visibility, and conflict-resolution rules explicit, so agents agree on what to read and when updates take effect."
- Visibility and ordering: Rules determining when writes become observable and in what sequence across agents. "and update-time visibility and ordering that determines when an agent's writes become observable to others and how concurrent writes may be observed in a permissible order."
Collections
Sign up for free to add this paper to one or more collections.