- The paper introduces a novel feedforward framework that jointly reconstructs 3D appearance and estimates physical parameters from monocular video.
- It leverages a differentiable simulation–rendering loop to optimize both geometry and physical attributes without requiring scene-specific tuning.
- The method achieves significant gains in PSNR and Chamfer Distance while reducing inference latency to under one second per asset.
Joint Appearance and Physics Estimation for Non-Rigid Objects from Monocular Video
Motivation and Problem Setting
Accurate reconstruction of non-rigid objects with physical plausibility is a key challenge for computer vision, graphics, and robotics. While recent neural rendering frameworks, notably NeRF-based and 3D Gaussian Splatting (3DGS) techniques, have facilitated high-fidelity 3D reconstructions, these methods are largely geometry- and appearance-centric and do not infer object-specific physical attributes required for downstream simulation and manipulation tasks. Prior approaches to physics-aware reconstruction often rely on per-scene optimization, extensive multi-view data, pre-defined material classes, or explicit ground-truth physical annotations. These constraints significantly limit their practicality and scalability, particularly for rapid asset acquisition from monocular video.
The ReconPhys framework addresses these deficiencies with a feedforward, dual-branch architecture that jointly reconstructs appearance and infers underlying physical properties (e.g., mass, stiffness, damping, and friction) of non-rigid objects from a single, monocular video. ReconPhys bridges explicit 3DGS geometric modeling with a differentiable spring-mass physical simulation whose parameters are estimated directly from visual dynamics observed in the input sequence.
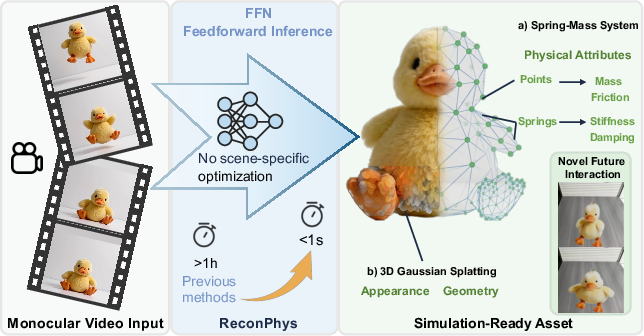
Figure 1: ReconPhys efficiently generates simulation-ready 3DGS assets with physics binding from monocular video within one second.
Framework Overview and Architecture
ReconPhys is architected as a pipeline comprising two principal modules:
- 3DGS Predictor: Infers a high-fidelity, canonical 3D Gaussian representation encoding the spatial and appearance properties of the object from monocular input.
- Physics Predictor: Employs a vision backbone to regress compact sets of physical parameters. These parameterize a spring-mass system, constructed by sampling anchor points linked to the 3DGS asset. This system simulates the physically plausible motion and deformation of the object in response to external forces.
A key aspect is the binding procedure: 3DGS kernels are tied to the simulated anchor points, enabling the renderer to synthesize temporally coherent, physics-consistent object motion. All physics inference and subsequent simulation occur in a fully feedforward manner, eschewing expensive scene-specific optimization at test time.
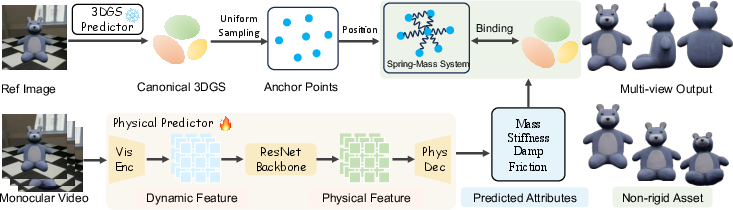
Figure 2: The framework leverages (left) geometry and anchor sampling for 3DGS construction and (right) a physics predictor to generate physical attributes, together yielding simulatable non-rigid assets.
Differentiable Simulation–Rendering Loop and Learning Paradigm
ReconPhys is trained via a self-supervised, end-to-end differentiable loop connecting pixel-level reconstruction loss to the physical attribute inference subtree. Specifically, the predicted physical parameters are fed to a differentiable spring-mass simulation that drives object deformation over the input video frames. The simulation's outputs are bound to the 3DGS kernels and rendered into RGB images. Discrepancy between the rendered outputs and the ground-truth video provides supervision for both geometry and physical attribute estimation. The graphical connection allows direct back-propagation of reconstruction loss gradients to physical variables, enabling their optimization in the absence of explicit labels.
To mitigate train–test distributional gap and promote robust, stable rollout, the method employs self-forcing: anchor state evolution is autoregressive based on the model's own previous predictions, not on imputed ground-truth states, substantially enhancing future state prediction accuracy and simulation stability.
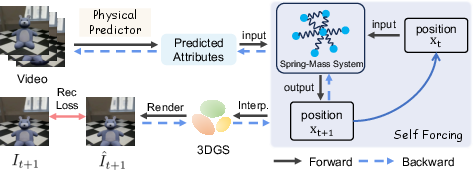
Figure 3: The self-forcing training pipeline supervises simulated motion from estimated physical parameters using reconstruction loss, ensuring temporal consistency over long horizons.
Experimental Evaluation
Synthetic Dataset and Protocol
A procedural pipeline synthesizes a large-scale dataset, selecting 500 semantically non-rigid objects from Objaverse-XL and parameterizing each with continuous-valued physical attributes. For each asset, several dynamic trajectories (free-fall, collision, deformation) are simulated, rendered as monocular videos, and paired with ground-truth geometry and physical attribute sets.
The standard protocol allocates 450 objects for training and 46 for cross-object generalization tests, with the critical regime being generalization to unseen geometry-attribute pairings. Baselines include Spring-Gaus and 4DGS, which perform per-scene optimization and require multi-view inputs.
Numerical Results and Visual Fidelity
ReconPhys delivers substantial improvements over appearance-only or per-object optimization baselines. For future-state prediction, it achieves 21.64 PSNR, a +7.6 dB gain over Spring-Gaus (13.27 PSNR), and reduces Chamfer Distance from 0.349 (Spring-Gaus) to 0.004, evidencing high-fidelity trajectory prediction and geometric consistency. Notably, inference latency is reduced from over 1 hour to less than 1 second per asset without explicit physical labels or scene-specific optimization.

Figure 4: Qualitative comparison illustrating ReconPhys's stable and realistic prediction of future deformation states compared to baselines prone to instability or inability to extrapolate.
Evaluation on real-world video sequences validates consistent qualitative performance for non-rigid objects, even in scenarios with uncontrolled physics, confirming robust generalization beyond synthetic data.

Figure 5: Real-world asset sequence (top) and simulation prediction (bottom), highlighting faithful non-rigid deformation over time.
Physical Disentanglement
A targeted evaluation assigns each of 46 objects in the test set two distinct sets of physical attributes, maintaining fixed geometry. ReconPhys preserves geometric fidelity while capturing divergent dynamic behavior corresponding to physical parameter changes, both visually and quantitatively. Physical parameter estimation error is significantly reduced relative to Spring-Gaus, especially for stiffness and damping coefficients.
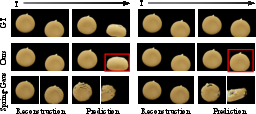
Figure 6: Given different physical attributes for the same geometry, ReconPhys predicts more accurate and differentiated deformation trajectories versus Spring-Gaus.
Application to Robotic Manipulation
By reconstructing simulation-ready, physically-authenticated 3DGS assets from brief, monocular video, this method enables rapid acquisition of objects for non-rigid manipulation tasks. The reconstructed digital twin can be inserted into physics simulators and manipulated via trajectory controllers, as demonstrated in multiple manipulation scenarios (stretching, squeezing, squashing), evidencing direct applicability for scalable robotics pipelines.

Figure 7: Demonstration of four non-rigid manipulation scenarios simulated with ReconPhys-reconstructed assets, showcasing deployment flexibility.
Implications and Future Directions
ReconPhys constitutes a scalable mechanism for physics-aware digital asset creation from uncalibrated, monocular observations—eliminating manual tuning, expensive optimization, and ground-truth labeling requirements. The feedforward generalization across unseen object geometries and material parameters underpins practical simulation-ready asset pipelines for robotic learning, graphics, and digital content creation.
From a theoretical perspective, the framework demonstrates that physical attribute inference can be grounded in pixel-level loss without explicit supervision by tightly binding differentiable simulation and rendering. The demonstrated ability for attribute disentanglement and reliable future-state prediction sets the stage for investigating finer material property estimation, more complex force interactions, and integration with differentiable continuum mechanics.
Extensions may target richer constitutive models (beyond mass–spring systems), exploit active manipulation trajectories for richer supervision, or fuse additional sensory modalities (e.g., tactile, audio) for enhanced physical understanding. The runtime efficiency and self-supervised learning paradigm also offer potential for closed-loop adaptation and continual learning in real-world embodied simulation environments.
Conclusion
ReconPhys establishes a new benchmark for feedforward, physics-aware non-rigid object reconstruction from monocular video. By unifying geometry and physics attribute inference within a differentiable, self-supervised simulation–rendering loop, it achieves state-of-the-art performance in both geometric fidelity and physically plausible future dynamic prediction. The framework's efficiency, generalization, and disentanglement capabilities position it as an effective foundation for scalable, physically grounded digital asset pipelines in robotics and interactive simulation.