- The paper demonstrates that injecting oracle information signals significantly boosts SWE agent performance, with Reproduction Test offering the largest gain.
- The methodology uses a systematic extraction pipeline and controlled ablation studies across multiple benchmarks to isolate and quantify each signal’s contribution.
- Results reveal non-additive, synergistic effects among signals, guiding improvements in model training and benchmark design for autonomous software engineering.
Introduction
The paper "ORACLE-SWE: Quantifying the Contribution of Oracle Information Signals on SWE Agents" (2604.07789) provides a systematic analysis of information signals that underlie the success of LLM (LM) agents in repository-level software engineering (SWE) automation. The authors address a gap in prior work: while agentic workflows and signal types have been extensively investigated, the quantitative impact of each pre-identified signal—when made perfect (oracle)—remains poorly understood. To resolve this, ORACLE-SWE introduces a data-driven pipeline to isolate, extract, and inject five information signals into SWE agents, empirically measuring their upper-bound contribution, both individually and in combination, across multiple SWE benchmarks and model architectures.
A comprehensive literature review synthesizes five critical information signals—Reproduction Test, Regression Test, Edit Location, Execution Context, API Usage—as recurrent factors across agent workflows, model training, and failure analyses. The extraction framework systematically generates the oracle version of each signal from repository data, ensuring signal purity and precise alignment with ground truth.
The extraction pipeline for Code Search-related signals—Edit Location, Execution Context, API Usage—is visualized below.
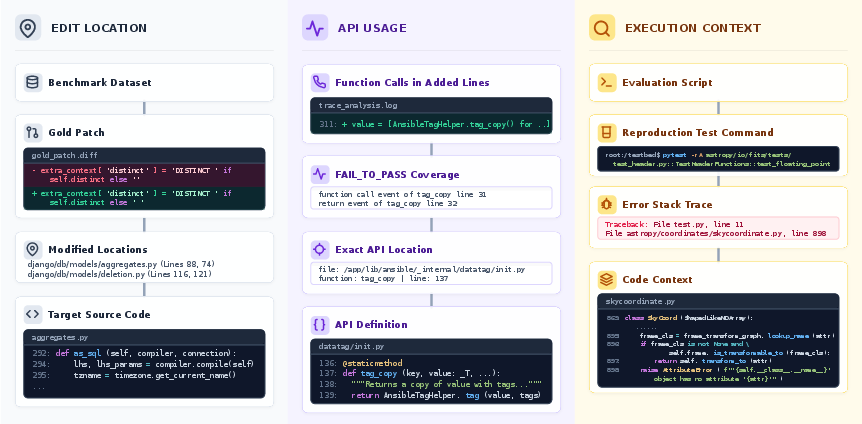
Figure 1: Extraction pipeline of oracle information signals for Code Search, including Edit Location, Execution Context, and API Usage.
Test Verification signals—Reproduction Test and Regression Test—follow an analogous extraction pipeline, leveraging benchmark patch and test metadata.

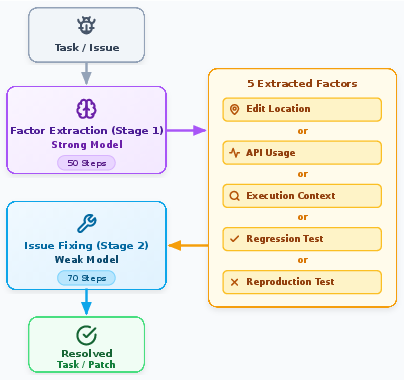
Figure 2: Extraction pipeline of Oracle Tests, including Reproduction Test and Regression Test.
Experimental Setup
Experiments are conducted using a minimalistic SWE-agent, which interacts with repositories using only bash commands and string-replace editing. Detailed ground-truth injection prompts permit controlled ablation studies, isolating the impact of each signal. Multiple model and dataset pairings—including GPT-5-Thinking-Medium, GPT-4o, Claude-4.5/4.6—are evaluated on SWE-bench-Verified, SWE-bench-Live, SWE-bench-Pro (Python/Golang), with extensive filtering for feasibility and reproducibility.
Ablation and Validation Studies
Single Factor Oracle Ablation
Controlled studies demonstrate that providing any oracle signal to the SWE-agent consistently increases task resolution rates. The ordering of signal contribution remains stable across datasets and models. Notably, Reproduction Test consistently yields the largest gain, followed by Execution Context (especially when native error stack traces are available), Edit Location, API Usage, and Regression Test. Native error traces substantially outperform custom context collectors, emphasizing the utility of explicit runtime failure paths.
The ablation results are summarized as follows:
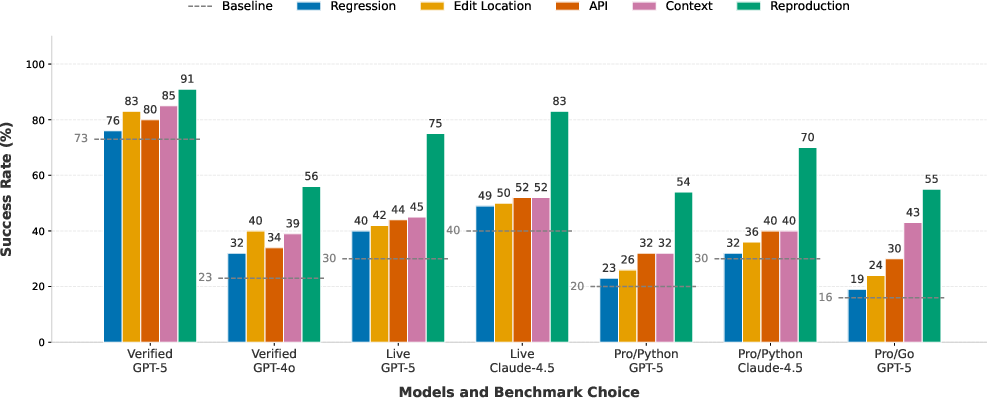
Figure 3: Ablation study measuring the upper-bound contribution of each information factor.
Accumulation and Combination of Signals
Success rates grow monotonically as oracle information signals are aggregated. Edit Location synergizes strongly with test signals, while Regression Test remains low-contributing. Sequential accumulation shows that with all five signals combined, nearly all agent-model-benchmark combinations saturate at ≥97% success, validating the completeness of the selected factor set.
Rollout efficiency increases with signal availability up to a point; step counts reduce as exploration shrinks, but rise again when agents must integrate multiple signals.
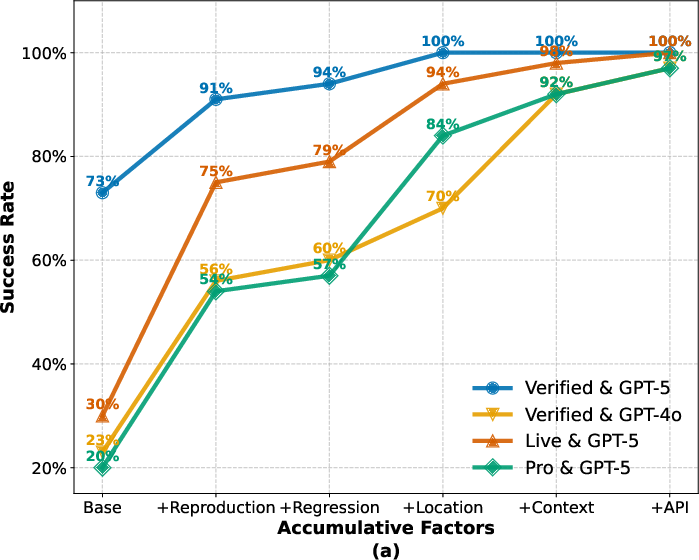
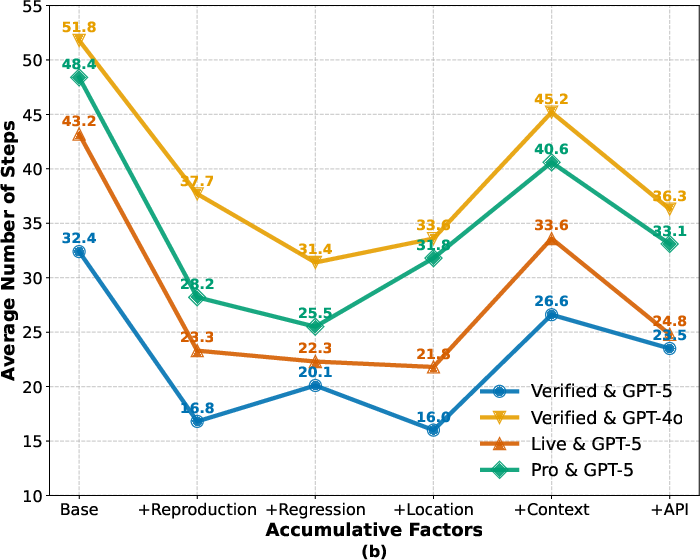
Figure 4: Accumulative contribution and average number of rollout steps when factors accumulate. Each factor on the x-axis incorporates all factors to its left.
Pairwise combinations further reveal that joint provision of Reproduction Test, Edit Location, and API Usage delivers super-additive improvements, indicating that optimizing these signals in tandem outperforms isolated enhancement.
Cost and Rollout Efficiency Analysis
The average cost (measured in LM API usage) and step count per instance vary substantially by signal. Regression Test incurs high cost with low marginal benefit; Execution Context is only cost-effective if stack traces are available. The agent's step count generally declines as signal richness increases, but integration complexity can limit further reductions.
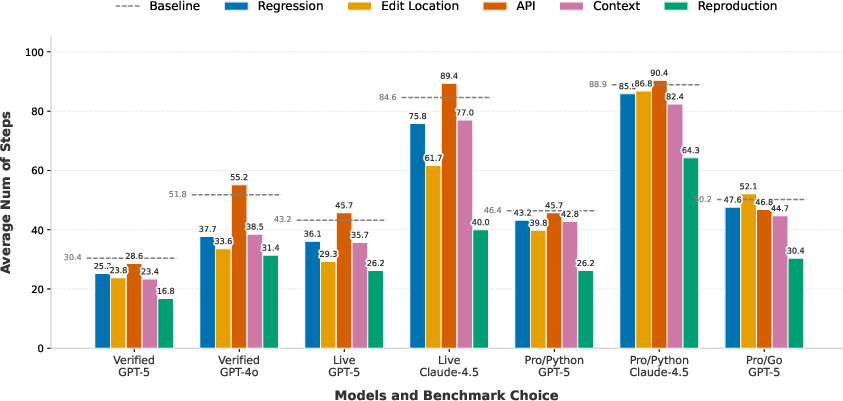
Figure 5: Average number of steps for single factors.
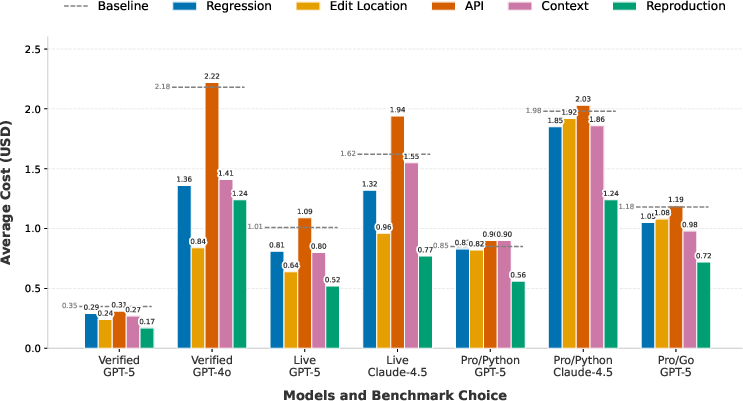
Figure 6: Average cost of rollout for single factors.
Recognizing practical limitations, the paper implements a two-stage validation: a strong model extracts signals; a weak model consumes them for issue resolution. The two-stage pipeline improves task resolution beyond both weak and strong single-agent baselines, especially for Reproduction Test, confirming the robustness of oracle upper-bound estimates. Signal extraction cost and resolution efficiency show signal-dependent trends; combining agent-generated Reproduction Tests with downstream models can resolve tasks previously missed by either agent alone.
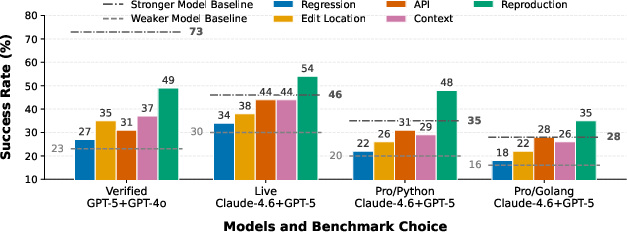
Figure 7: Visualized result of the two-stage validation compared with the single-agent baseline. Labels are formatted as (strong model) + (weak model).
Discussion and Implications
Contradictory and Bold Claims
The paper contradicts the implicit assumptions of prior work where signal contribution was regarded as roughly additive or uniform. Regression Test, despite its historical role, is shown to minimally impact agentic task resolution under oracle conditions, challenging its perceived importance in SWE workflows. Conversely, the dominant impact of Reproduction Test—both numerically and across benchmarks—suggests that thorough, explicit benchmarks of failure conditions are necessary, and that current natural-language issue descriptions are insufficient.
Edit Location and API Usage signals become highly synergistic when paired, especially with test signals; their isolated effect is comparatively muted. Execution Context is only substantially valuable when explicit error stack traces exist, which is not the case for a majority of real-world tasks.
Practical and Theoretical Implications
Practically, these findings direct research and benchmark design toward investing in richer reproduction test generation, enhanced stack trace extraction, and careful curation of edit location and API usage guidance. For model development, direct training for reproduction test synthesis and stack trace-based context integration should be prioritized.
Theoretically, the non-additive nature of factor contributions, the supremacy of Reproduction Test, and the nuanced role of Execution Context reveal complex interdependencies in signal utilization. Future agentic SWE frameworks should focus on dynamic signal integration and adaptive context exploitation rather than uniform stagewise pipelines.
Future Directions
Potential developments include:
- Automated extraction and synthesis of oracle-like signals from novel benchmarks;
- Training LMs to better infer ambiguous signal types (especially where native stack traces are unavailable);
- Dataset augmentation to bolster reproduction test diversity and coverage;
- Investigating cross-language generalization to extend findings beyond Python and Golang.
Integration of signal synergy mechanisms and advanced context-sensitive planning can improve agent robustness and efficiency in complex SWE environments.
Conclusion
ORACLE-SWE rigorously quantifies the upper and practical bounds of five prevalent information signals for LLM-driven SWE agents. The empirical results establish Reproduction Test as the dominant signal and demonstrate that Edit Location, API Usage, and Execution Context provide synergistic uplift, contingent upon their accurate extraction and contextual relevance. Regression Test is confirmed as marginal in direct issue resolution efficacy. These insights shape future research priorities, model training strategies, and benchmark design, offering a detailed, evidence-based roadmap for advancing autonomous, agentic software engineering solutions.