- The paper introduces a hybrid Socratic framework that integrates deterministic code analysis with generative dialogue to enhance code understanding assessment.
- It categorizes assessment architectures into rule-based, LLM-based, and hybrid systems, highlighting trade-offs between consistency and adaptability.
- Empirical results, including a 43% improvement in programming knowledge, demonstrate the framework's potential despite challenges like LLM hallucinations.
Chatbot-Based Assessment of Code Understanding in Automated Programming Assessment Systems
Systematic Review Methodology and Search Strategy
The paper conducts a saturation-based scoping review focused on conversational agents within programming assessment systems. Five search string variants, based on the PICOC framework, were constructed to target literature across multiple technical platforms and educational contexts (Figure 1).
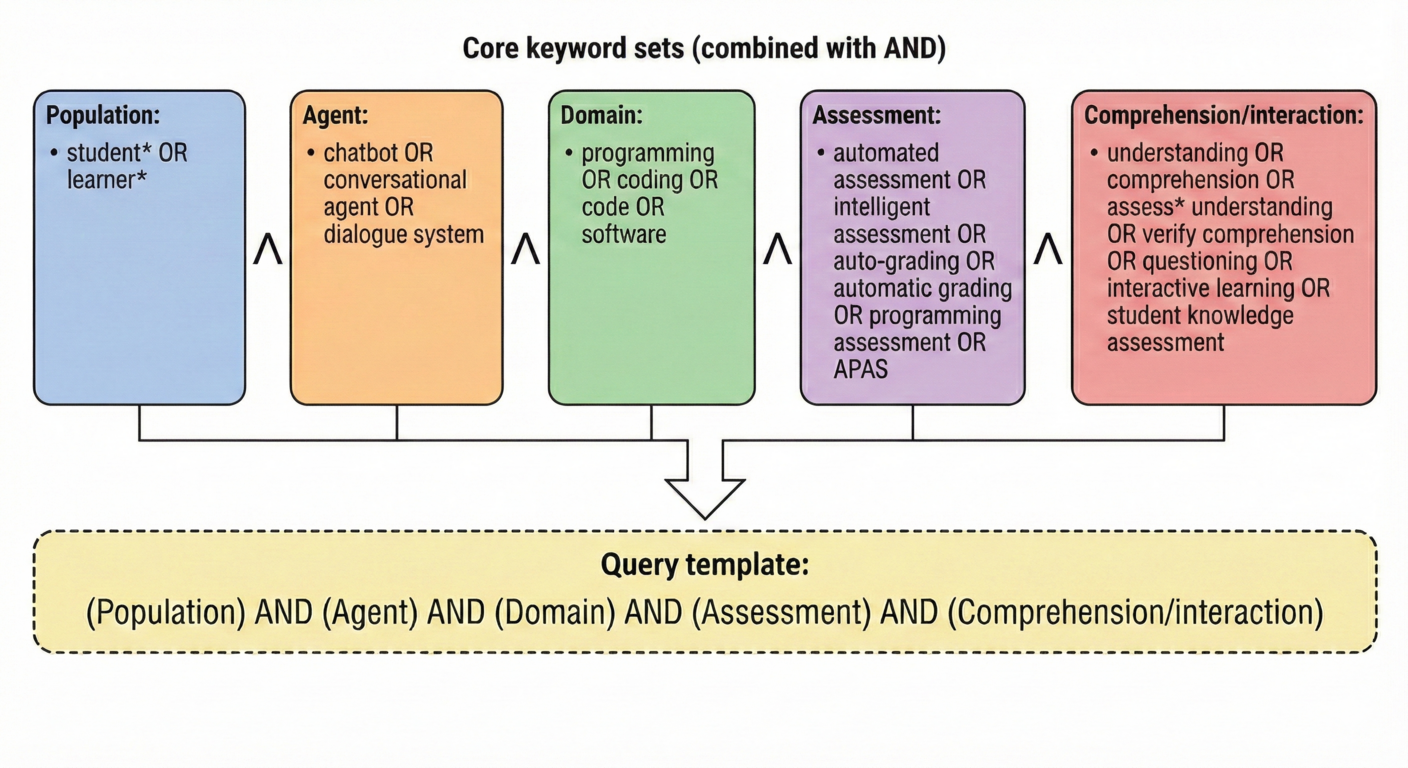
Figure 1: Keyword groups and query template used to derive the five search string variants.
A PRISMA-guided workflow, adapted for the rapid evolution and small volume of the domain, was used to systematically identify, screen, and include relevant studies. The review combined multi-source searches, iterative screening, and snowballing to maximize coverage, yielding a final corpus categorized by architecture and pedagogical method (Figure 2).
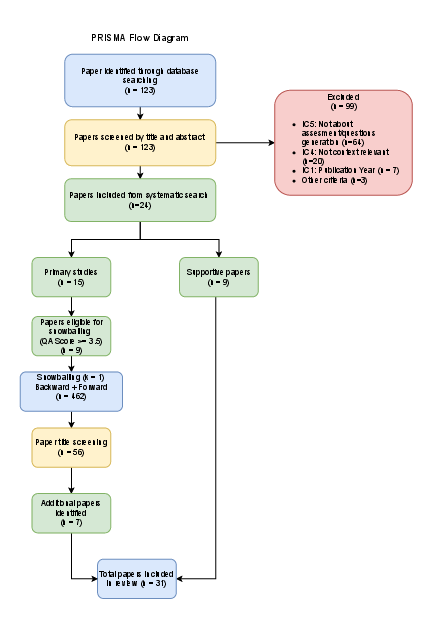
Figure 2: PRISMA-style flow diagram of identification, screening, eligibility, and inclusion.
Categorization of Conversational Assessment Architectures
Three principal architectures emerged—rule-based/template-driven, LLM-based, and hybrid systems:
- Rule-Based/Template-Driven: Utilize deterministic algorithms and handcrafted templates, leveraging static and dynamic code analysis. These methods show strong consistency and auditability but lack adaptability and suffer from limited coverage for novel code patterns.
- LLM-Based: Employ generative models (e.g., GPT, Llama, Mistral) to generate contextually appropriate, multi-turn Socratic dialogues. While these enable broader code comprehension and adaptive questioning, they are prone to hallucinations, inconsistent grading, and solution-leakage.
- Hybrid Systems: Integrate deterministic program analysis with generative conversational layers, balancing reliability and adaptability. Hybrid systems combine code-grounded evidence with responsive dialogue and guardrails, appearing most suitable for scalable and transparent assessment scenarios.
Benefits, Limitations, and Pedagogical Implications
Empirical evidence demonstrates notable gains: Socratic Author achieved a 43% improvement in programming knowledge, ChatDAC increased post-test scores, and tiered hint engagement correlated positively with exam performance. These agents scale personalized feedback and reduce instructor workload in large cohorts. However, technical limitations such as LLM hallucinations and behavioral risks—student over-reliance, gaming, and superficial engagement—impose constraints on assessment reliability.
A key pedagogical insight is the persistent gap between code-writing and code-understanding competence; students frequently excel on structural questions (>80%) but underperform (<50%) on dynamic execution and tracing tasks. Effective conversational assessment thus requires probing deeper conceptual understanding aligned with explicit reasoning targets.
Hybrid Socratic Framework: Design and Implementation
Deriving from the review, the Hybrid Socratic Framework combines static/dynamic code analysis with a dual-agent conversational layer (Instructor and Verifier), knowledge-tracking, scaffolded questioning, and Socratic guardrails (Figure 3).
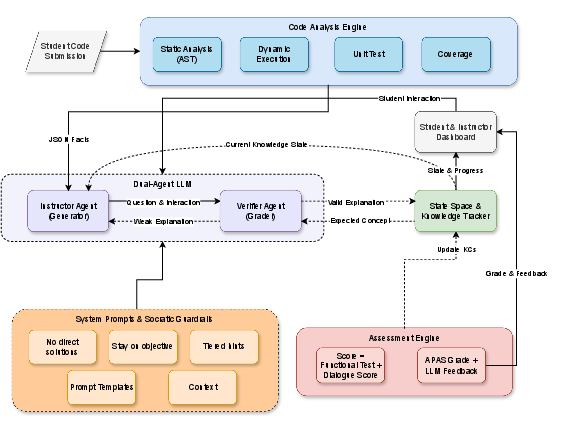
Figure 3: Hybrid Socratic Framework for chatbot-based assessment in APASs.
Essential Components
- Code Analysis Engine: Extracts deterministic program facts for prompt grounding.
- State Space and Knowledge Tracker: Monitors student misconceptions and knowledge gaps across dialogue turns.
- Dual-Agent Core: Instructor generates Socratic, program-specific questions; Verifier evaluates explanations against reference states.
- Assessment Engine: Integrates evidence from code correctness and explanation quality.
- Socratic Guardrails: Constrains agent behavior to prevent solution-giving and off-topic responses.
Integrity Safeguards
To mitigate risks arising from LLM-generated explanations, the framework integrates proctored deployment options, randomized runtime trace questions, stepwise reasoning tied to execution states, and adaptive follow-ups. This shifts assessment from generic explanation to code- and execution-grounded reasoning.
Agent Prompting and Assessment Strategy
Agents operate under strict role-specific prompts adapted from established templates, separating question-generation from explanation evaluation. A two-tier assessment strategy is used: Tier 1 (selection via scenario-based MCQs) ensures initial conceptual engagement, and Tier 2 (open-ended explanation) measures depth of understanding, with scoring weighted toward explanation quality.
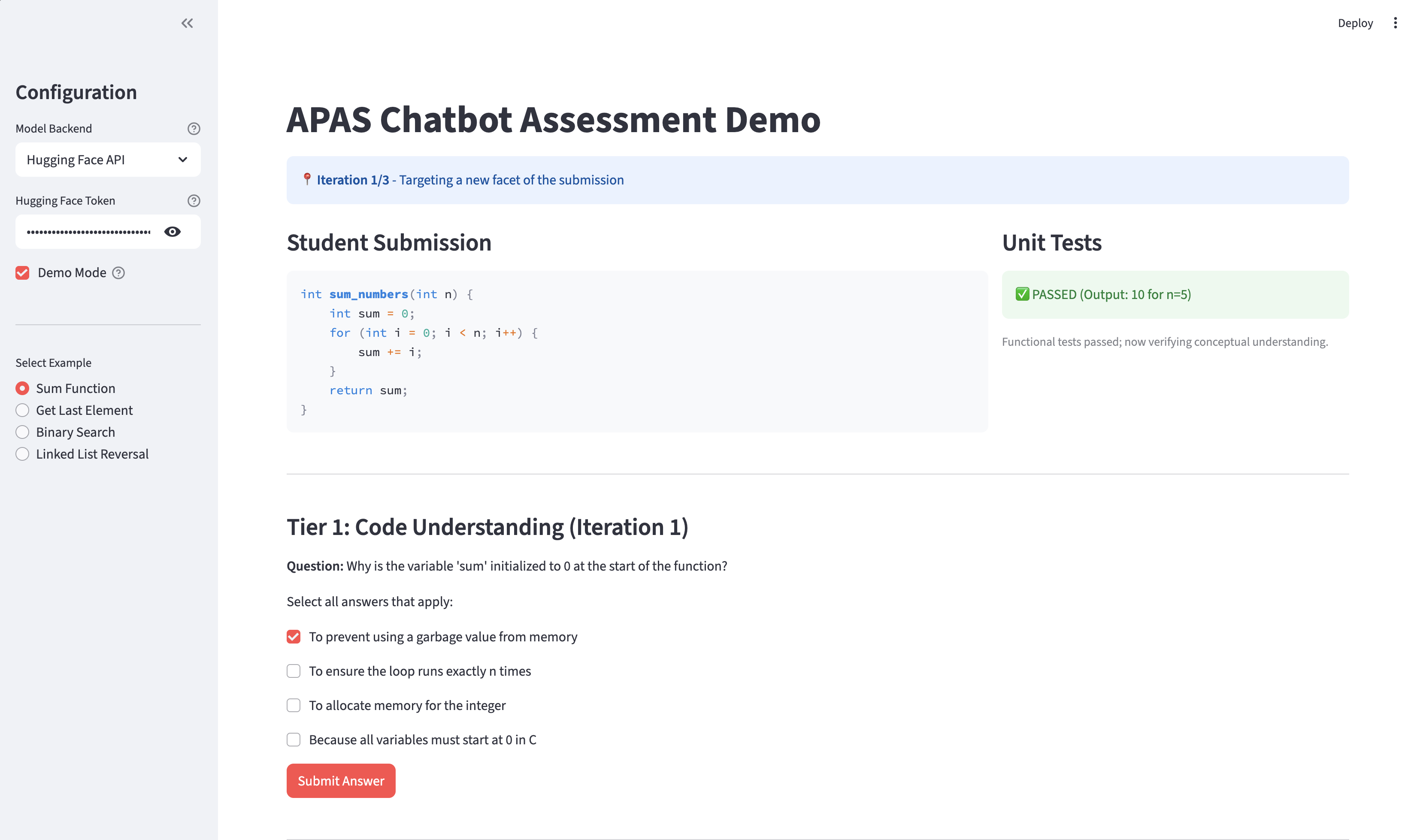
Figure 4: Proof of concept, Tier 1: scenario-based multiple-choice question generated by the Instructor Agent.
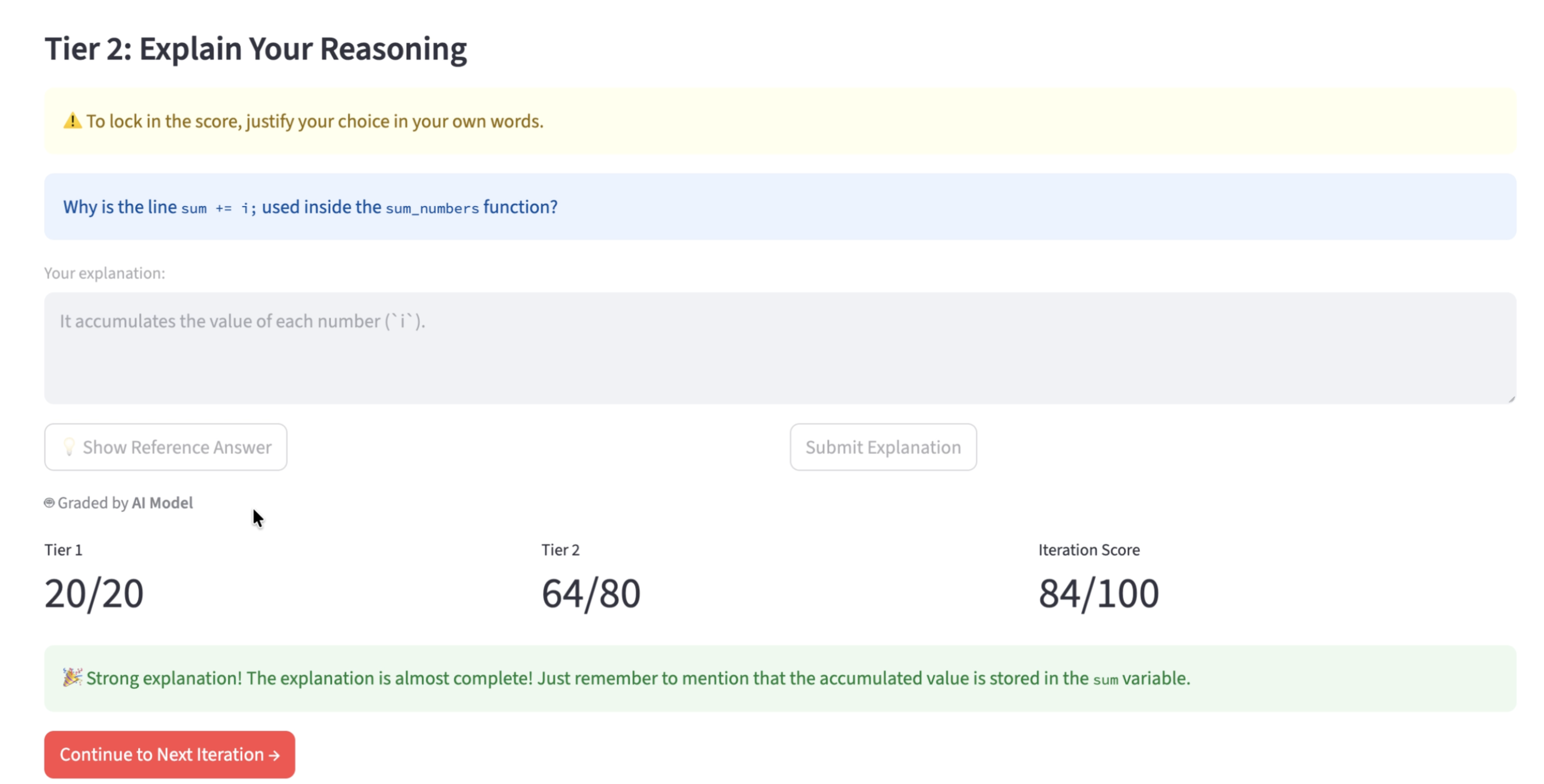
Figure 5: Proof of concept, Tier 2: open-ended explanation graded by the Verifier Agent.
Discussion and Practical/Theoretical Implications
The results imply a necessary evolution in APASs—from functional artifact assessment to verification of reasoning and explanation. Effective adoption will depend on transparent role definition, prompt policies, scoring thresholds, and clear formative/summative separation. Ethical considerations require auditability, appeal mechanisms, and ongoing validation for fairness and consistency—especially in high-stakes grading. Digital sustainability needs vendor-independent model hosting and reproducible prompt/version management.
Hybrid architectures both address and create new complexities, balancing coverage, adaptability, and operational auditability while introducing infrastructural burden. The applicability of conversational assessment extends to program comprehension, algorithmic reasoning, and authorship verification, anchoring assessment in observable code behavior rather than unconstrained model interpretation.
Threats to Validity
The rapid evolution of LLMs and conversational tools presents ongoing threats to methodological validity. Unvalidated framework parameters and reliance on untested prototype deployments limit generalizability. The synthesis should be interpreted as provisional guidance pending empirical classroom validation.
Conclusion
Conversational assessment, grounded in deterministic program analysis and scaffolded Socratic dialogue, constitutes a promising complementary layer for verifying code understanding in the era of ubiquitous LLMs. The Hybrid Socratic Framework offers a balanced approach, combining the strengths of deterministic evidence and adaptive dialogue. Sustained adoption requires empirical validation, robust knowledge-tracking, multimodal extensions, and careful integration of formative/summative practices to support privacy, reliability, and fairness.
Future Perspectives
Empirical classroom deployments and human-machine comparison studies will be critical in validating framework reliability and acceptance. Development of advanced knowledge-tracing and multimodal assessment modalities will enhance robustness. Systematic investigation into deployment modes, privacy/fairness impacts, and their behavioral consequences is essential for principled integration of conversational agents in programming assessment.