- The paper demonstrates that users misinterpret LLM capabilities, notably mistaking web access and code execution as inherent features.
- It utilizes a two-phase method combining brainstorming and qualitative analysis of 500 Python-related conversations to uncover these misconceptions.
- The findings underscore the need for clearer interface affordance indicators to mitigate persistent user misunderstandings in LLM-assisted programming.
User Misconceptions of LLM-Based Conversational Programming Assistants
Introduction
The proliferation of LLM-based programming assistants has introduced new paradigms in software development, particularly through conversational interfaces such as ChatGPT. While these tools have demonstrated utility in code generation, debugging, and documentation, their diverse capabilities and rapidly evolving feature sets have led to widespread user misconceptions. This paper systematically investigates the nature and prevalence of such misconceptions, focusing on both tool-specific and model-level misunderstandings, and analyzes their manifestation in real-world programming interactions.
Methodology
The study employs a two-phase approach: (1) a collaborative brainstorming activity to catalog potential misconceptions, and (2) a qualitative analysis of 500 Python-related conversations from the WildChat dataset, an open corpus of LLM-chatbot interactions. The pre-processing pipeline for identifying coding-related conversations is depicted below.
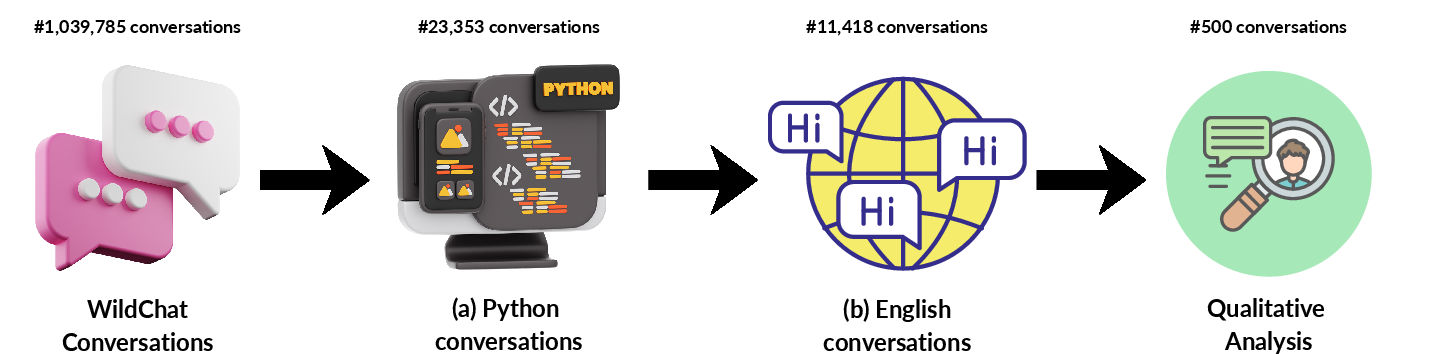
Figure 1: Pre-processing pipeline for identifying coding-related conversations.
Conversations were filtered using regular expressions for code block formatting and language detection, resulting in a subset of English-language Python interactions. Annotation was performed using a custom tool that enabled multi-label coding of both user intentions and inferred misconceptions.
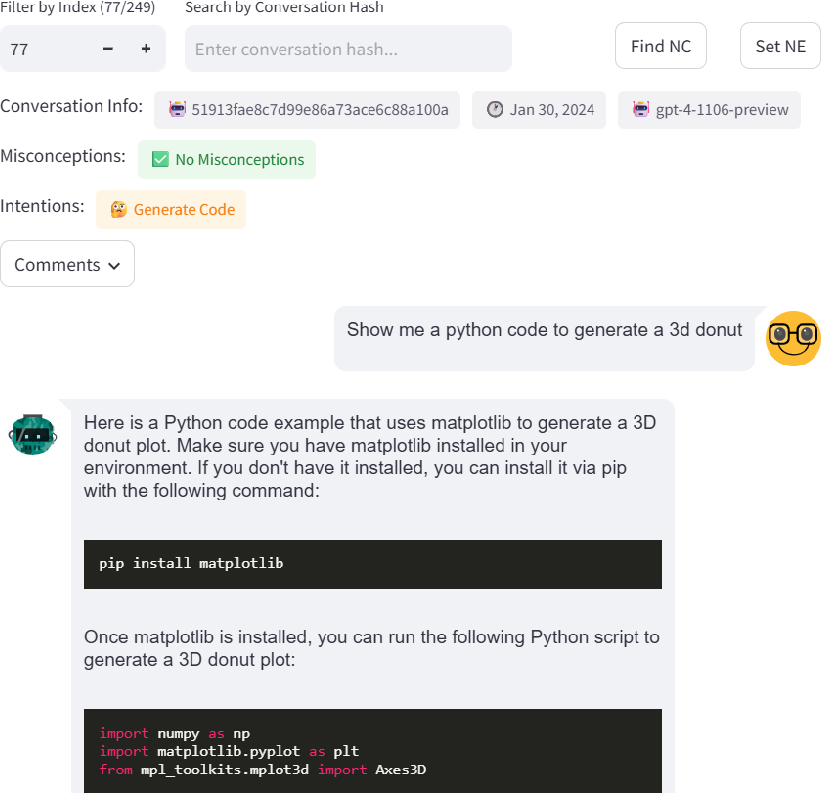
Figure 2: Annotation tool for labeling conversations.
Taxonomy of Misconceptions
The brainstorming phase identified several recurring themes:
- Web Access: Users frequently assume LLMs can access external URLs or perform web scraping, despite the absence of such capabilities in many deployments.
- Code Execution: Prompts often request the model to execute code or return runtime outputs, conflating static analysis with dynamic execution.
- Session Memory: There is confusion regarding cross-session persistence, with users referencing previous conversations as if the model maintains global state.
- Non-Text Output: Requests for graphical or multimedia outputs are common, even when the interface is strictly text-based.
- Local Machine Access: Some users expect the assistant to interact with their local environment, such as running terminal commands or accessing files.
- Continuous Training: Misconceptions about real-time model updates and knowledge cutoffs persist, leading to erroneous expectations about the currency of information.
- Deterministic Behavior: Users may expect consistent outputs for identical prompts, overlooking inherent stochasticity in LLM responses.
Model-Level Misconceptions
- Stability of Results: There is limited awareness of prompt sensitivity and context window effects.
- Groundedness: Users may believe hallucinations are impossible in certain contexts, such as when uploading data.
- Native Explainability: The assumption that LLMs can reliably explain their own generated code is prevalent, despite evidence to the contrary.
- Symbolic Logic: LLMs are often mistaken for symbolic engines, especially in algebraic or logical queries.
- Context Window: The "monotonicity belief" that more context always improves performance is widespread, despite non-linear recall dynamics.
Qualitative Analysis of WildChat Logs
The analysis of 500 Python-related conversations revealed the following:
- Intention Distribution: The majority of prompts were for code generation (243), debugging (126), and code modification (86). Other intentions included brainstorming, documentation lookup, validation, refactoring, and optimization.
- Misconception Prevalence: The most frequent misconceptions involved web access (20), dynamic analysis (14), algebraic computation (7), code execution (4), session memory (4), non-text output (3), local machine access (3), and others.
Inter-rater reliability for intention coding was high (κ=0.87), but moderate for misconception coding (κ=0.80 on the Gold dataset, 0.45≤κ≤0.51 in validation), reflecting the inherent ambiguity in inferring user beliefs from prompt language.
High-Agreement Misconceptions
Web Access
Prompts such as "write a code to interact with <GitHub URL>" or "use a genetic algorithm to optimize features from the Titanic dataset at <Kaggle URL>" exemplify the misconception that the LLM can directly access external resources. Even when datasets are likely present in training data, the explicit inclusion of URLs indicates a misunderstanding of the model's retrieval mechanisms.
Non-Text Output
Requests for figures, graphs, or meteograms (e.g., "give me a meteogram in port of genoa on June 7, 2020") were flagged as misconceptions, given the text-only nature of the interface.
Session Memory
Instances where users referenced previous sessions (e.g., "please redo the previous programming problem") demonstrate confusion about session persistence.
Code Execution
Prompts such as "make the code run and check for input 5" or "did you call the function to make it run?" reflect the expectation that the assistant can execute code and return outputs, which is not supported in the WildChat deployment.
Local Machine Access
Requests for information about file download locations or running code in the user's terminal suggest an overestimation of the assistant's integration with the local environment.
Continuous Training
Prompts requesting the "latest" version of libraries or APIs (e.g., "use latest telethon") indicate a lack of awareness of the model's knowledge cutoff.
Algebra
Direct evaluation of algebraic expressions (e.g., "what does 75% exponential equate to") conflates LLMs with symbolic computation engines.
Clear Chat
Prompts such as "clear this page" reveal assumptions about system commands and context management.
Ambiguous Misconceptions and Contextual Factors
Several prompt patterns, particularly in debugging and optimization contexts, were difficult to conclusively label as misconceptions. For example, requests to "remove all errors" or "make the function error proof" may reflect either a misunderstanding of static analysis limitations or simply prompt engineering strategies. Similarly, optimization requests (e.g., "speed up this function as much as possible") may be based on either informed expectations or misconceptions about profiling capabilities.
The analysis also highlighted the challenge of inferring misconceptions from prompt language alone, especially in cases involving ambiguous or underspecified requests.
The findings underscore the necessity for LLM-based programming assistants to clearly communicate their capabilities and limitations. Standardized affordance indicators (e.g., icons or specs sheets) could mitigate common misconceptions, particularly regarding web access, code execution, and session memory. Reliance on LLM-mediated chat for system information is unreliable, as models may fabricate responses or misreport their own version and capabilities.
Limitations
The study's scope is constrained by the authors' backgrounds, the non-representative nature of the WildChat dataset, and the inherent difficulty of inferring user beliefs from interaction logs. The rapid evolution of LLM tool affordances may also limit the generalizability of specific findings.
Future Directions
Further research should employ targeted surveys and behavioral experiments to directly measure user misconceptions, tailored to specific tool configurations. Automated log analysis using LLM-based classifiers could scale the detection of misconception-related language. Longitudinal studies are needed to track the evolution of user mental models as LLM capabilities and interfaces continue to change.
Conclusion
This work provides a systematic characterization of user misconceptions in LLM-based conversational programming assistants, distinguishing between tool-specific and model-level misunderstandings. The analysis of real-world interaction logs reveals persistent confusions about web access, code execution, session memory, and other affordances, with significant implications for tool design and user education. Addressing these misconceptions is critical for improving the reliability, usability, and safety of LLM-assisted programming workflows.

