- The paper proposes expert-reward informed tuning that refines translation quality by using granular data filtering and quality estimation techniques.
- It utilizes a multi-component pipeline—including SFT-LTP and GRPO—to address data scarcity and optimize low-resource Chinese-centric MT performance.
- Experimental results show significant BLEU improvements over larger models, validating the benefits of targeted reward curation and data distillation.
MERIT: Expert-Reward Guided Multilingual Tuning for Chinese-Centric Low-Resource MT
Motivation and Benchmark Construction
The persistent translation quality gap for Chinese↔low-resource Southeast Asian languages is attributable to a dearth of high-quality parallel corpora, severe data noise, and the absence of standardized direct evaluation protocols. The paper proposes a decisive shift from the traditional English-pivoted evaluation methodologies that conflate semantic drift with translation performance, introducing CALT—the first Chinese-centric benchmark supporting direct LRL→Chinese assessment for five languages: Vietnamese, Indonesian, Burmese, Tagalog, and Lao. The re-indexing of the ALT corpus enables the extraction of genuine LRL↔Chinese pairs, eliminating pivot-induced artifacts, and offers a scalable, reproducible, and pivot-free testbed. The focus on these target LRLs reflects both the feasibility of high-fidelity re-alignment and genuine parallel data scarcity, situating the evaluation at the low-resource frontier most relevant to the region's digital divide.
MERIT Framework: Data Filtering, Specialization, Reward Optimization
The proposed Multilingual Expert-Reward Informed Tuning (MERIT) architecture addresses corpus noise, model capacity, and adaptation via a multi-component pipeline:
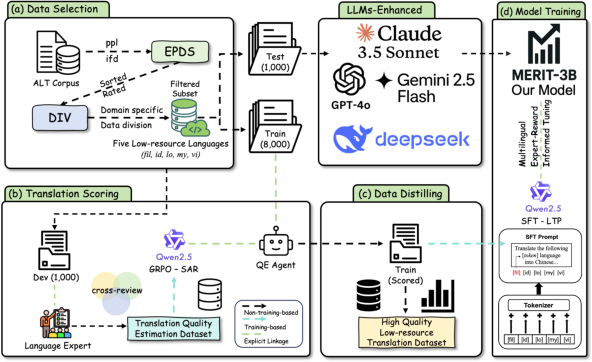
Figure 1: Overview of the MERIT framework encompassing data filtering, reward-based scoring, and specialized model tuning.
Data Curation and Sampling: Noisy parallel corpora are filtered in three stages. Heuristic candidates are sampled from the mined pool using statistical alignment features (length, token ratios, punctuation/digit divergence, lexical diversity). Additional semantic scores are added via LLM-based perplexity and instruction-following metrics, and a final quality estimation (QE) agent—trained on cross-reviewed human gold annotation—distills high-value instances through a reference-free scoring regime.
Supervised Fine-Tuning with Language-Token Prefixing (SFT-LTP): Open-source encoder-decoder LLMs (e.g., Qwen-2.5 0.5B/3B) are subject to supervised fine-tuning, employing explicit language-identifier tokens in both tokenizer and prompt to resolve language demarcation and maximize transfer. Training is performed independently for each LRL→Chinese direction, with cross-entropy optimization and label smoothing to regularize limited data scenarios.
Reward-Guided Optimization via Group Relative Policy Optimization (GRPO): The QE agent is further refined with a reinforcement learning loop, maximizing Semantic Alignment Reward (SAR). SAR is a step-wise, high-granularity reward function that promotes consistency with human judgment for semantic adequacy, but allows margin for subjectivity (2.0 for exact, 1.0 for ≤10pt error, otherwise 0.0). GRPO operates on candidate batches, using relative intra-batch comparisons to stabilize training dynamics and selection.
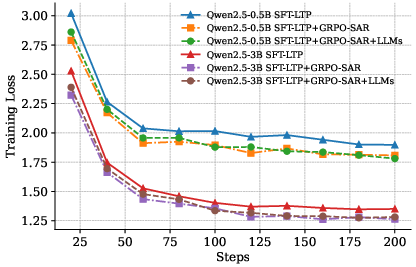
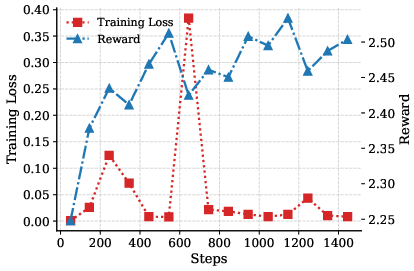
Figure 2: Loss and reward curves demonstrate SFT pretraining followed by GRPO reward maximization yielding monotonic performance improvements.
The MERIT-3B model, trained on only 22.8% of the original candidate data post-filtering, exceeds the largest open-source competitor (NLLB-200 3.3B) and even approaches or surpasses much larger instruction-tuned LLMs on key LRL→Chinese test directions. Specifically, substantial absolute BLEU-4 improvements are reported for Filipino (+4.7), Indonesian (+9.5), and Vietnamese (+5.9) over NLLB-200, with similarly significant margins on METEOR and BERTScore. These gains are statistically significant (p < 0.01 for major metrics) and robust across both strict overlap and semantic-friendly evaluation protocols.
The BLEU-chrF composite, defined as the arithmetic mean of BLEU-4 and chrF, better captures both lexical and semantic gains, validating the effect of data distillation and reward modeling. Ablation over SFT-LTP, SFT-LTP+GRPO-SAR, and the full LLME-enhanced pipeline reveals pronounced synergistic effects: for Qwen-2.5 3B, transitioning from zero-shot to full LLME raises overall BLEU-chrF from 9.1 to 19.9—a 119% relative improvement—despite a >60% reduction in training data volume.
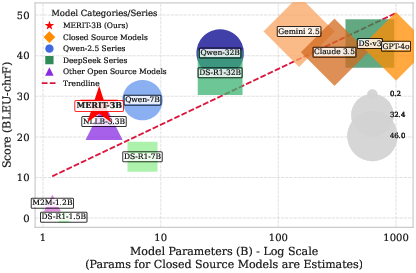
Figure 3: BLEU-chrF/model size trade-off plot highlights MERIT-3B's performance parity with or outperformance of much larger models, betraying the inefficacy of naïve upscaling for LRLs.
For extremely low-resource languages (Lao, Burmese), models below 3B parameters fail to generalize, often defaulting to source copying or hallucinations, affirming the necessity of expert-reward curation. By leveraging semantic rewards, MERIT-3B remains operational in script-divergent, corpus-deficient conditions where even scaling alone does not suffice.
Practical Implications and Theoretical Impact
The work concretely demonstrates that reward-informed expert distillation and granular filtering can surpass raw parameter count as the principal axis for improvement in LRL scenarios. This directly challenges the prevailing trend of brute-force scaling in multilingual MT, calling instead for sophisticated data-model interface optimization. The open-source, reproducible pipeline—by re-architecting both the benchmark and the training methodology—enables systematic progress monitoring on Chinese-centric LRL translation.
Practically, the framework is adaptable to other dense-to-sparse language settings beyond Southeast Asia. The modular design (data selection, reward-based QE, RL-fine-tuning) facilitates integration with advanced prompting, transfer learning, and hybrid commercial–open translation pipelines. The full ablation suite also offers a blueprint for optimizing inexpensive (sub-7B) LLMs in strategies that emphasize data pragmatics and human-aligned reward modeling over costly large-scale pretraining.
Theoretically, the SAR-driven GRPO strategy points toward the broader utility of local, expert-calibrated, non-exact scalar rewards for sequence generation tasks. The framework’s modular reward objective may generalize to balancing multi-aspect generation metrics (e.g., adequacy, fluency, style) and to broader problems in semi- and self-supervised RLHF settings.
Limitations and Perspectives for Future Research
Constraints remain regarding (1) coverage—the present benchmark spans only five LRLs and is ultimately limited by the original ALT's domain and script diversity, (2) reward model scope—SAR is adequacy-dominant, and (3) scalability—the approach is validated only up to 3B scale with no explicit latency/efficiency benchmarking. There is also potential for subtle English-centric bias retention given the ALT’s genesis. Addressing these would entail incorporating additional script normalization, developing multi-objective or style-aware reward functions, and extending the recipe to billion-scale models and other linguistic clusters (e.g., Tibeto-Burman, Uralic).
Future lines of work include ensemble strategies combining MERIT’s high-recall filtering with advanced LLM prompting in few/zero-shot, expanding cross-script robustness, and integrating adversarial or contrastive reward specialists to jointly optimize adequacy, fluency, and semantic informativeness.
Conclusion
The MERIT framework establishes a rigorous, data- and reward-efficient approach for advancing Chinese-centric low-resource machine translation. By emphasizing expert-aligned curation and SAR-based optimization, it achieves strong, statistically validated quality gains in LRL translation—often with a fraction of the data and computational budget of standard approaches. This paradigm prioritizes targeted quality filtering and human-calibrated reward shaping, offering both a practical toolkit for low-resource MT and a template for future expert-guided sequence generation in multilingual and multimodal AI.

