LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
Abstract: Consumer research costs companies billions annually yet suffers from panel biases and limited scale. LLMs offer an alternative by simulating synthetic consumers, but produce unrealistic response distributions when asked directly for numerical ratings. We present semantic similarity rating (SSR), a method that elicits textual responses from LLMs and maps these to Likert distributions using embedding similarity to reference statements. Testing on an extensive dataset comprising 57 personal care product surveys conducted by a leading corporation in that market (9,300 human responses), SSR achieves 90% of human test-retest reliability while maintaining realistic response distributions (KS similarity > 0.85). Additionally, these synthetic respondents provide rich qualitative feedback explaining their ratings. This framework enables scalable consumer research simulations while preserving traditional survey metrics and interpretability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to use LLMs to act like “synthetic consumers” in product surveys. Instead of asking the AI to pick a number on a 1–5 scale (like humans do), the authors ask it to explain its opinion in words, then convert that text into a 1–5 score using a smart matching trick. This method makes the AI’s answers look and behave much more like real human survey results.
What questions did the researchers ask?
They focused on a few simple, big questions:
- Can AI “pretend” to be groups of consumers and rate products in a way that matches real people?
- Why do AIs do badly when we force them to choose numbers (1–5) directly?
- If we let AIs write short answers first, then translate those answers into 1–5 ratings, do we get more human-like results?
- Can this approach keep the good parts of surveys (like rankings of best products) and also give helpful written comments?
- Do AI “personas” (like age or income) change ratings in ways that mirror real human differences?
How did they do the study?
First, here’s the real-world setup:
- The team used data from 57 real product surveys about personal care items (like toothpaste or shampoo).
- About 9,300 people took these surveys in total.
- Everyone rated “purchase intent” (how likely they were to buy) on a 1–5 scale (1 = “definitely not,” 5 = “definitely yes”).
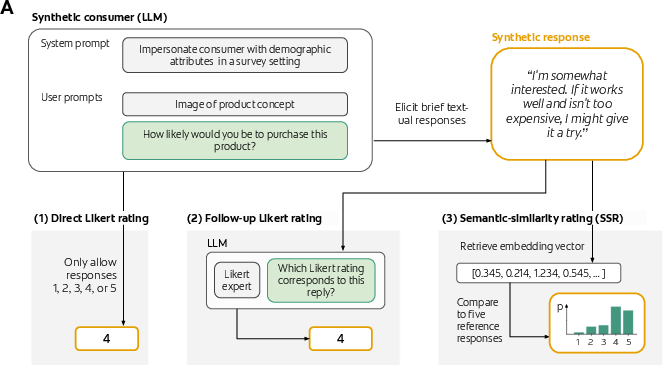
Then they created “synthetic consumers” using LLMs (two well-known models). Each synthetic consumer got a short persona (like age or income), saw the same product description (often with an image), and answered the same question: “How likely are you to purchase this?”
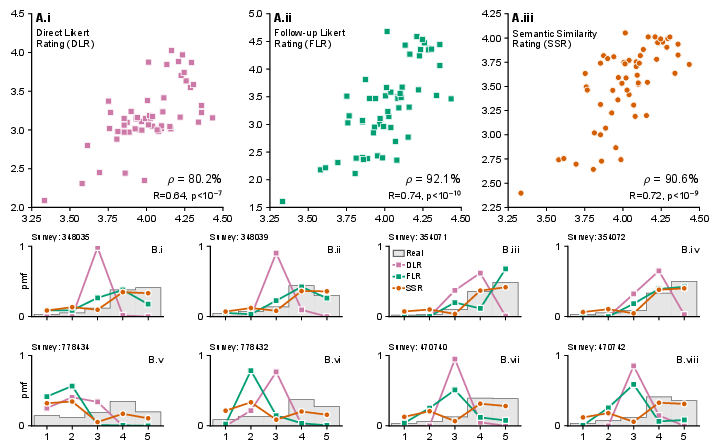
They tested three ways to get ratings from the AI:
- Direct Likert Rating (DLR): Ask for a single number (1–5).
- Follow-up Likert Rating (FLR): First the AI writes a short opinion, then another prompt asks it to convert that text to 1–5.
- Semantic Similarity Rating (SSR): The AI writes a short opinion. That text is then converted to a 1–5 score using “semantic similarity.”
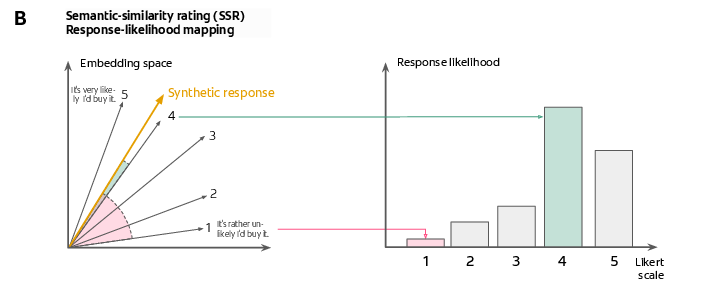
What is “semantic similarity”? Think of it as measuring how close two sentences are in meaning. The method works like this:
- The researchers prepared five short “anchor” sentences, one for each rating (1–5). Example: “I will definitely buy this” (5), “I probably won’t buy this” (2), etc.
- They turned both the AI’s text and the anchor sentences into “embeddings,” which you can imagine as meaning fingerprints: numbers that capture the meaning of a sentence.
- They then measured how similar the AI’s text fingerprint was to each anchor fingerprint (using a standard measure called cosine similarity).
- The closer it was to, say, the “definitely buy” anchor, the higher the odds of a 5. This gives a full probability distribution across 1–5, not just a single number.
How did they check if it worked?
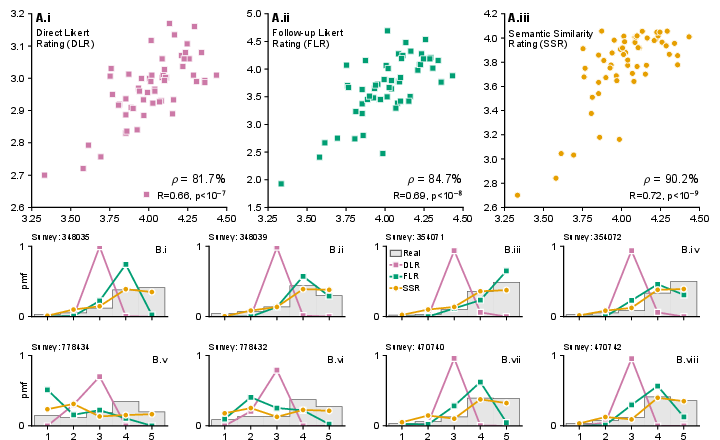
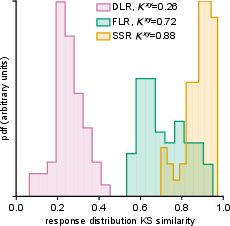
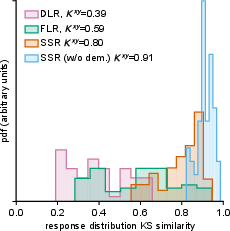
- Distribution similarity: Do the shapes of the AI’s rating distributions match humans’? (They used a statistic called KS similarity; higher means more similar.)
- Product rankings: Do the AI’s average ratings put the products in about the same order as humans do? They used “correlation attainment,” which is like asking: “How close are we to the best possible match, given that even two human groups won’t agree perfectly?” Hitting 100% would mean as good as human–human agreement.
What did they find?
- Direct numbers don’t work well. When forced to pick 1–5 directly, AIs usually choose the safe middle (3) too often. That makes the distribution unrealistic, even if the average product ranking is okay.
- Letting the AI talk first helps a lot. Both FLR and SSR improved results, but SSR was best overall.
- SSR produced human-like distributions and strong rankings. It matched 90% of the “best possible” human-level agreement (correlation attainment ≈ 90%) and had high distribution similarity (KS similarity > 0.85). In plain terms: the AI’s answers looked like real survey data and ranked products much like humans do.
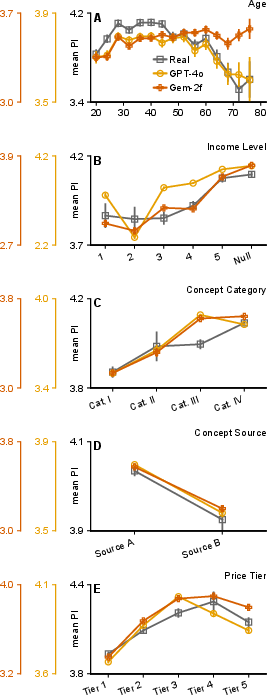
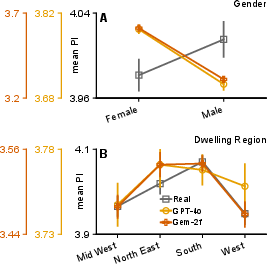
- Personas matter. When the AI was asked to “be” certain types of people (like different ages or income levels), its ratings shifted in ways similar to how real humans differ. Age and income patterns were especially well-captured.
- But don’t remove personas entirely. If the AI wasn’t given any demographic persona, its ratings looked superficially similar to human distributions but did a worse job ranking which products were better—so the results were less useful.
- Extra bonus: rich comments. Because SSR starts with a short written answer, companies also get clear reasons: what people liked, what worried them, and what could be improved.
- It generalizes to other questions. The same method worked reasonably well for a different survey question (“How relevant was the concept?”).
- It beat a trained machine learning baseline. SSR (and even FLR) outperformed a traditional model trained on the survey data for ranking products—despite the LLMs using no special training on this dataset.
Why does it matter?
This approach could make product testing faster, cheaper, and more detailed:
- Companies can screen many early ideas with synthetic surveys, then spend money on human studies for the most promising ones.
- The method keeps familiar metrics (1–5 ratings and averages) but adds richer written feedback.
- It’s “plug-and-play”: no costly fine-tuning needed.
At the same time, there are important cautions:
- The quality depends on good “anchor” sentences and the text embedding model used.
- Not all demographic patterns are perfectly captured (some, like gender or region, were less consistent).
- LLMs work best in domains they “know” from training (like consumer products). In niche areas, results may be weaker.
- Synthetic consumers should complement, not fully replace, real people—especially for final decisions or sensitive subgroups.
In short: By asking AIs to explain themselves first and then translating those explanations into 1–5 scores using semantic similarity, this study gets AI survey results that look and behave a lot more like the real thing—bringing speed, scale, and useful insights to early-stage consumer research.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, articulated so future researchers can act on each item:
- External validity to market behavior: Assess whether SSR-based rankings predict real-world outcomes (e.g., in-market sales, simulated test markets) rather than only reproducing human survey panels.
- Domain generalization: Replicate SSR across product categories (e.g., food, durables, services), brands, and decision contexts (e.g., risk, credence goods) to test robustness beyond personal care.
- Cross-cultural and multilingual validity: Evaluate performance in non-U.S. populations and other languages; test whether anchors and embeddings transfer across cultures and linguistic contexts.
- Anchor sensitivity and optimization: Quantify how results vary with different anchor statements (content, wording, number, polarity), and develop systematic anchor search/optimization (e.g., automated anchor generation, data-driven calibration on held-out surveys).
- Risk of overfitting anchors to the studied corpus: The anchor sets were manually optimized on the 57 surveys; test out-of-corpus performance and establish protocols to prevent anchor overfitting.
- Mapping function design: Compare cosine-similarity normalization to alternative mappings (e.g., softmax with temperature, ordinal regression, IRT-based mappings, kernel methods) and assess calibration, monotonicity, and uncertainty properties.
- Embedding model dependence: Benchmark different embedding models (general vs domain-specific, multilingual, open-source vs closed) and similarity metrics (cosine vs alternatives), including sensitivity to embedding drift over time.
- Model and version drift reproducibility: Track performance stability across LLM/embedding model updates, document versioning effects, and propose procedures for periodic re-calibration.
- Persona construction and ablations: Systematically ablate and test which demographic or psychographic attributes drive alignment (age, income, gender, region, values); explore the utility of attitudinal/behavioral personas beyond demographics.
- Subgroup fidelity and fairness: Rigorously evaluate subgroup validity (e.g., gender, region, ethnicity) where replication was weaker; test for bias propagation, stereotype amplification, and disparate error rates.
- Causal responsiveness to controlled manipulations: Validate that SSR responds correctly (direction and magnitude) to experimental changes in concept attributes (e.g., price, claims, format) consistent with known human causal effects.
- Panel composition and weighting: Study how to synthesize respondents without mapping 1:1 to human participants; evaluate stratified sampling and post-stratification weighting to match target populations.
- Sample size and stability: Determine the number of LLM samples per persona needed for stable distributions and rankings; quantify variance reduction vs cost trade-offs.
- Metric choice for ordinal distributions: Replace or complement KS similarity with ordinal-aware distances (e.g., Earth Mover’s/Wasserstein, Cramér–von Mises for ordinal data) and report sensitivity to metric choice.
- Multi-item scales and latent constructs: Extend beyond single-item PI to multi-item scales (e.g., satisfaction, trust) and test internal consistency, factor structure, and convergent/discriminant validity.
- Generalization to other question types: Systematically evaluate SSR on binary, multiple-choice, continuous, and open-ended coding tasks beyond PI and “relevance.”
- Vision vs text-only stimuli: More deeply quantify the added value and failure modes of multimodal stimuli (vision models’ comprehension limits, artifacts) relative to text-only descriptions.
- Data contamination and brand familiarity: Test whether performance depends on LLM pretraining exposure to specific brands/categories; construct contamination-controlled benchmarks with synthetic or obfuscated brands.
- Stronger baselines: Compare SSR to advanced supervised baselines (e.g., ordinal regression with textual features, SBERT/LLM-encoder + calibrated classifiers, fine-tuned small LMs) under strict out-of-sample protocols.
- Calibration of dynamic range: LLMs produced more dispersed mean PIs than humans for low-appeal products; develop post-hoc calibration methods (e.g., monotonic transformations) to match human scale use without degrading rankings.
- Temporal stability of SSR panels: Assess test–retest reliability of synthetic respondents across days/weeks and under different random seeds/temperatures; quantify within-persona stability.
- Qualitative feedback validation: Develop methods to score the informativeness, specificity, and actionability of synthetic rationales versus human feedback (e.g., human-coded benchmarks, content validity, redundancy measures).
- Privacy and ethics of persona impersonation: Analyze risks of replicating sensitive subgroup traits and biases, and propose governance for responsible use in decision-making.
- Open-data and reproducibility: Results rely on proprietary surveys and closed models; provide public benchmarks, share anchors/protocols, and replicate with open-source models to enable independent verification.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, leveraging the paper’s SSR pipeline (free-text elicitation + embedding-based mapping to Likert distributions), the demographic persona conditioning, and the qualitative rationales produced by LLMs.
- Sector: Consumer Packaged Goods (CPG) and Market Research — Synthetic concept pre-screening
- Use case: Screen early-stage product concepts with SSR to rank ideas and approximate Likert distributions before commissioning large human panels; reserve human studies for finalists.
- Tools/workflow: Persona-conditioned prompts → short free-text PI rationales → embeddings → cosine similarity to anchor statements → per-respondent Likert pmf → survey-level distribution and concept ranking dashboard.
- Assumptions/dependencies: Anchor statements must be curated; embedding model quality matters; best performance when personas include age/income; domain should be well represented in LLM training data.
- Sector: Advertising and Creative Testing — Rapid copy and claim iteration
- Use case: Test alternative headlines, claims, packaging copy, and imagery; select creatives that maximize SSR-derived PI or “relevance” (demonstrated generalization) by persona and price tier.
- Tools/workflow: Batch runs across variations; heatmaps of Likert pmfs; rationale mining to surface objections and value drivers.
- Assumptions/dependencies: Image/text stimuli fidelity; ensure anchors are tuned to construct (PI vs relevance vs trust).
- Sector: Product Management / UX — Feature prioritization with Likert-compatible outputs
- Use case: Map free-text user comments on features (from interviews or forums) to Likert-like “importance” or “satisfaction” using SSR anchors; prioritize roadmap items.
- Tools/workflow: Qual → SSR quantization → weighted prioritization by target personas.
- Assumptions/dependencies: Requires construct-specific anchors (e.g., “importance,” “ease of use”); may need light calibration.
- Sector: E-commerce and Performance Marketing — Persona-targeted messaging optimization
- Use case: Estimate PI/relevance by demographic persona (e.g., age, income) to tailor messaging and channel mix.
- Tools/workflow: Persona grid testing with SSR; uplift charts comparing segments; rationale-based messaging guidelines.
- Assumptions/dependencies: Demographic conditioning improves ranking fidelity; be cautious on attributes the paper found weaker (gender/region).
- Sector: Academia and Survey Methods — Pilot study replacement and instrument design
- Use case: Use SSR to approximate Likert distributions for pilot surveys; test question wording, anchoring vignettes, and scale labels prior to fielding.
- Tools/workflow: Multi-wording A/Bs → SSR outcomes; select forms with best distributional properties; power analysis using synthetic variance.
- Assumptions/dependencies: Validity depends on domain alignment; finalize with small human validation.
- Sector: Public Health Communication and Policy — Message pre-testing
- Use case: Pre-test public-facing messages (e.g., on hygiene, OTC products) to gauge intent/relevance among personas before running field surveys.
- Tools/workflow: SSR over message variants; rationale clustering to identify misunderstandings and barriers.
- Assumptions/dependencies: LLMs mirror known topics better; do not substitute for population-representative polling.
- Sector: Finance / Corporate Strategy — Early-stage demand sensing
- Use case: Use SSR-based rankings as a leading indicator for concept appeal in due diligence or product portfolio reviews.
- Tools/workflow: “Synthetic concept OS” dashboard aggregating PI distributions, rank order, and rationales by consumer segment.
- Assumptions/dependencies: Treat as directional signal; pair with small human panels for critical go/no-go decisions.
- Sector: Customer Insights Operations — Mixed-methods synthesis at scale
- Use case: Combine SSR distributions with qualitatively rich rationales to produce “synthetic focus group” summaries for each concept.
- Tools/workflow: Topic modeling/salience detection over rationales; issue/benefit heatmaps aligned to Likert pmfs; auto-generated insight decks.
- Assumptions/dependencies: Maintain anchor libraries and versioning; ensure prompt hygiene.
- Sector: Survey Platforms / Software — Plug-in SSR module
- Use case: Add SSR as a service to Qualtrics/SurveyMonkey-type tools: upload stimuli, define personas, get Likert distributions and rationales.
- Tools/workflow: API microservice (LLM + embeddings + anchor sets), UI for anchor selection, persona templates, drift monitoring.
- Assumptions/dependencies: API access to robust LLM and embedding models; governance for data privacy and audit logs.
- Sector: Small Businesses / Indie Creators — Quick concept gut-checks
- Use case: Evaluate product ideas, price tiers, and packaging options without panel budgets.
- Tools/workflow: Lightweight web app with prebuilt anchors, common persona presets, and ranked recommendations.
- Assumptions/dependencies: Results are indicative, not substitutes for market tests; ensure domain is within LLM familiarity.
Long-Term Applications
These require further validation, scaling, domain adaptation, or methodological development beyond the paper’s current scope.
- Sector: Cross-Domain Surveying — Generalization to other Likert constructs
- Use case: Extend SSR to satisfaction, trust, safety, usability, perceived risk, fairness, etc., across healthcare, education, public services.
- Enablers: Construct-specific anchor libraries; domain-tuned embeddings; multilingual/cross-cultural anchors.
- Dependencies: Calibration against human benchmarks in each construct/domain.
- Sector: Policy and Governance — Rapid policy prototyping and barometers
- Use case: Maintain “synthetic panels” to pre-test public policies, health advisories, or climate programs; identify segments with low acceptance.
- Enablers: Persona populations representing geographies and socioeconomics; drift detection and periodic human recalibration.
- Dependencies: Ethical oversight; transparency of limitations; non-substitution for official polling.
- Sector: Energy / Automotive / IoT Hardware — Adoption and feature acceptance modeling
- Use case: Test willingness to adopt EV features, smart home devices, or dynamic tariffs; identify barriers via rationales.
- Enablers: Multimodal stimuli (video, 3D renders); price-sensitivity scripts; domain-specific anchors.
- Dependencies: Model exposure to domain knowledge; integration with discrete choice/pivot to conjoint for pricing realism.
- Sector: Healthcare and Biopharma — Patient adherence and education materials
- Use case: Simulate message acceptance for adherence programs or OTC innovations; refine language for diverse literacy levels.
- Enablers: Health literacy-aware anchors; co-design with clinicians; multilingual personas.
- Dependencies: Clinical validation; stringent bias monitoring; regulatory compliance.
- Sector: Education and EdTech — Curriculum and product adoption intent
- Use case: Predict educator/parent/student receptivity to new curricula or tools; tailor rollout communications by segment.
- Enablers: Role-specific persona conditioning; anchors for “relevance,” “appropriateness,” “ease of integration.”
- Dependencies: Cultural/region-specific anchors; validation with pilot districts.
- Sector: Platforms and Tooling — Auto-optimized SSR and adaptive anchoring
- Use case: Learn anchor statements and similarity thresholds that maximize alignment with human data; adapt anchors per domain.
- Enablers: Bayesian calibration with small human holdouts; meta-learning over anchor sets; ensemble of embedding models.
- Dependencies: Continuous evaluation pipelines; versioned anchors and embeddings; governance.
- Sector: ML Ops and Research Methods — Human-in-the-loop calibration and fairness controls
- Use case: Combine SSR with small validation panels to correct drift and enforce fairness (e.g., align subgroup behavior to real data).
- Enablers: Hierarchical models to reweight subgroup outputs; bias audits across gender/region; uncertainty quantification.
- Dependencies: Access to periodic ground-truth data; documented thresholds for acceptability.
- Sector: Creative/Design Automation — Closed-loop generative optimization
- Use case: LLM generates concept variants; SSR evaluates; evolutionary search iterates toward high-PI variants under constraints (cost, sustainability).
- Enablers: Generative design + SSR evaluator + constraint solvers; multi-objective optimization.
- Dependencies: Guardrails to prevent mode collapse; ensure design diversity and compliance.
- Sector: Standards and Regulation — Validation protocols and acceptance criteria
- Use case: Develop industry standards for synthetic survey validity (distributional similarity thresholds, correlation attainment targets) and audit trails.
- Enablers: Cross-industry consortia; benchmark datasets; reproducibility kits.
- Dependencies: Consensus on metrics; periodic re-validation as models change.
- Sector: Privacy-Preserving Analytics — On-device or private-cloud SSR
- Use case: Run SSR pipelines where proprietary concepts cannot leave secure environments.
- Enablers: Private embeddings; local LLMs; confidential computing.
- Dependencies: Performance parity with public models; cost of secure infrastructure.
Notes on Feasibility and Risk
- Domain dependence: SSR is strongest where LLMs have rich prior exposure (e.g., personal care). Expect weaker fidelity in niche domains; calibrate with small human samples.
- Anchor sensitivity: Results depend on anchor design; maintain libraries, run A/Bs, and consider averaging across sets as in the paper.
- Demographic conditioning: Improves ranking fidelity (age/income worked best); treat subgroup outputs cautiously where alignment was weaker (gender/region).
- Embeddings and similarity metrics: Cosine similarity with general-purpose embeddings worked; domain-specific encoders may improve performance but require validation.
- Ethical and legal constraints: Do not replace human research for high-stakes decisions; disclose synthetic nature; comply with claims substantiation and data privacy.
- Not a direct proxy for conversion: SSR yields Likert-like intent distributions and relative rankings, not realized purchasing behavior; triangulate with experiments/market tests.
Glossary
- Acquiescence: A survey response bias where participants tend to agree with statements regardless of content. "responses may be distorted by satisficing, acquiescence, and positivity biases"
- Anchor statements: Predefined reference texts used as scale anchors to map semantic similarities to Likert points. "predefined anchor statements"
- Anchoring vignettes: A survey methodology technique using standardized scenarios to adjust for differences in how respondents use rating scales. "(anchoring vignettes)"
- Angular distance: The angle between embedding vectors, indicating how similar two texts are in an embedding space. "In an embedding space, the synthetic response will have a certain angular distance to any other statement."
- Conjoint-style willingness-to-pay estimation: A discrete-choice approach to infer how much respondents are willing to pay by varying product attributes. "conjoint-style willingness-to-pay estimation"
- Correlation attainment: A metric comparing the correlation between synthetic and real outcomes to the maximum correlation achievable given human test–retest limits. "Correlation attainment is then quantified as "
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "computing the cosine similarity of embeddings with those of predefined anchor statements"
- Cumulative distribution function (CDF): A function giving the probability that a variable is less than or equal to a value; used in KS distance. "as the maximum distance between two CDFs"
- Demographic conditioning: Prompting LLMs with socio-demographic attributes or backstories to influence their responses. "Another focus of some studies is demographic conditioning, where prompts embed socio-demographic backstories."
- Distributional cosine similarity: Cosine similarity applied to probability distribution vectors, which does not account for ordinal scales. "distributional cosine similarity defined as"
- Distributional similarity: The degree to which two response distributions match, here assessed via KS similarity. "distributional similarity was poor"
- Embedding space: A vector space where texts are represented as numerical embeddings for similarity computations. "In an embedding space, the synthetic response will have a certain angular distance to any other statement."
- Feeling thermometer: A survey measure where respondents rate their feelings on a temperature-like scale. "provide \"feeling thermometer\" scores"
- Kolmogorov--Smirnov (KS) similarity: A statistic based on the KS distance used to compare two distributions; here defined as 1 minus the KS distance. "We measure per-survey similarity between synthetic and real purchase intent distributions via Kolmogorov--Smirnov (KS) similarity"
- Kronecker delta function: An indicator function equal to 1 when indices match and 0 otherwise. "where is the Kronecker delta function."
- LightGBM: A gradient boosting decision tree framework optimized for efficiency and speed. "we trained 300 LightGBM classifiers"
- Likert scale: An ordinal survey scale (often 1–5) used to measure attitudes or intentions. "Standard practice is to elicit purchase intent on a Likert scale"
- Ordinality: The property of ordered categories where relative order matters but not exact distances. "because it respects the ordinality of the scale."
- Pearson correlation: A measure of linear association between two variables. "We compute Pearson correlations between mean purchase intents of real and synthetic surveys"
- Personas: Demographic or attitudinal profiles used to condition LLM responses to mimic specific subgroups. "demographic or attitudinal personas"
- Probability mass function (pmf): A function mapping discrete outcomes to their probabilities. "yielding a response probability mass function (pmf)"
- Prompt engineering: Designing and refining prompts to elicit desired behaviors from LLMs. "stays with zero-shot elicitation or prompt engineering."
- Regression-to-the-mean: The tendency of extreme values to move toward the average upon repeated measurement. "such as skewed distributions, over-positivity, or regression-to-the-mean"
- Semantic similarity mapping: An NLP method that aligns texts by comparing their embeddings for semantic similarity. "(semantic similarity mapping)"
- Semantic similarity rating (SSR): A method that maps free-text LLM responses to Likert distributions using embedding-based similarity to anchors. "We present semantic similarity rating (SSR), a method that elicits textual responses from LLMs and maps these to Likert distributions"
- Test--retest reliability: The consistency of measurements across repeated survey administrations. "SSR achieves 90\% of human test--retest reliability"
- Zero-shot elicitation: Obtaining model outputs for a task without task-specific training or fine-tuning. "stays with zero-shot elicitation or prompt engineering."
Collections
Sign up for free to add this paper to one or more collections.