- The paper introduces Terra, a 3D world model that uses point latents to overcome view-dependent limitations and achieve exact multi-view consistency.
- It leverages a point-to-Gaussian VAE and sparse point flow matching to encode colored point clouds into compact representations for efficient 3D scene generation.
- Experimental results on ScanNet v2 demonstrate Terra’s superior performance in reconstruction, unconditional generation, and image-conditioned generation.
Terra: Explorable Native 3D World Model with Point Latents
Introduction and Motivation
The paper introduces Terra, a native 3D world model that leverages point latents for intrinsic scene representation and generation. Unlike conventional world models that rely on pixel-aligned or 2.5D representations, Terra operates directly in a sparse 3D latent space, discarding view-dependent constraints and enabling exact multi-view consistency. This approach addresses the limitations of prior methods, which struggle with multi-view consistency and efficient exploration due to their reliance on 2D or pixel-aligned representations.
Terra's architecture is built upon two core components: a point-to-Gaussian variational autoencoder (P2G-VAE) and a sparse point flow matching model (SPFlow). The P2G-VAE encodes colored point clouds into compact point latents and decodes them into 3D Gaussian primitives, facilitating joint modeling of geometry and appearance. SPFlow enables generative modeling in the latent point space via flow matching, supporting both unconditional and conditional generation, as well as progressive exploration.
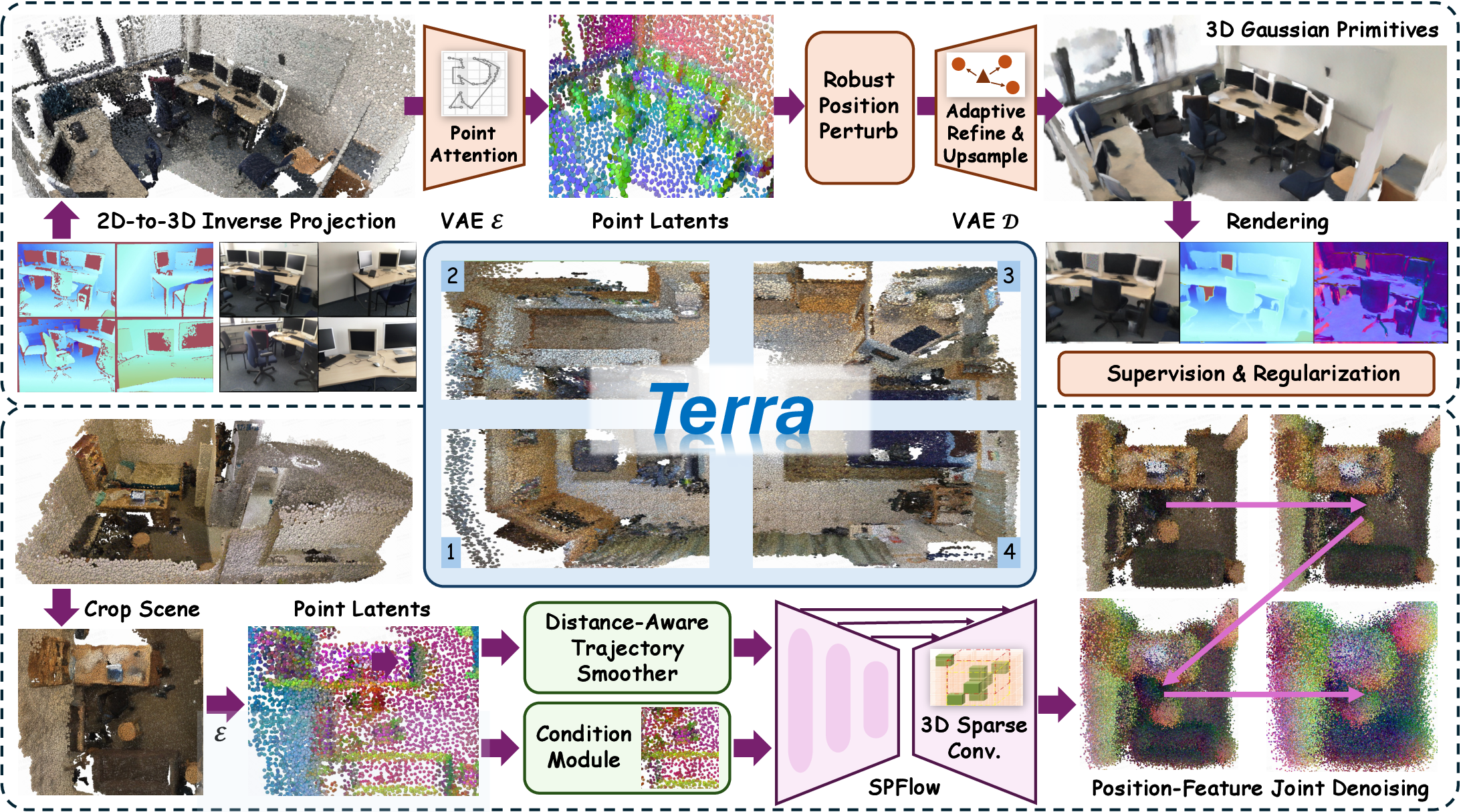
Figure 1: Terra's pipeline comprises a point-to-Gaussian VAE and a sparse point flow matching model, both utilizing native sparse 3D architectures for efficient scene encoding and generation.
Latent Point Representation and Model Architecture
Terra formulates explorable world modeling as a progressive outpainting task in the point latent space. The latent point representation consists of spatially sparse, semantically rich point latents, each encoding 3D coordinates and features. This design allows for adaptive complexity, efficient integration of historical context, and direct modeling of the environment without the need for view-dependent elements or reprojection constraints.
The P2G-VAE is constructed on a modified point transformer backbone, with residual connections removed for improved latent space robustness. Key innovations include:
- Robust Position Perturbation: Gaussian noise is added to point coordinates to regularize the latent space, enhancing decoder robustness to positional noise and improving generative quality.
- Adaptive Upsampling and Refinement: The decoder upsamples and refines point latents via learnable queries and feature-based offsets, restoring dense and meaningful structures without complex mask-guided operations.
- Comprehensive Regularizations: The loss function integrates L2, SSIM, LPIPS, chamfer distance, normal, effective rank, and explicit color supervision, directly aligning Gaussian colors with input point cloud colors for optimization efficiency.
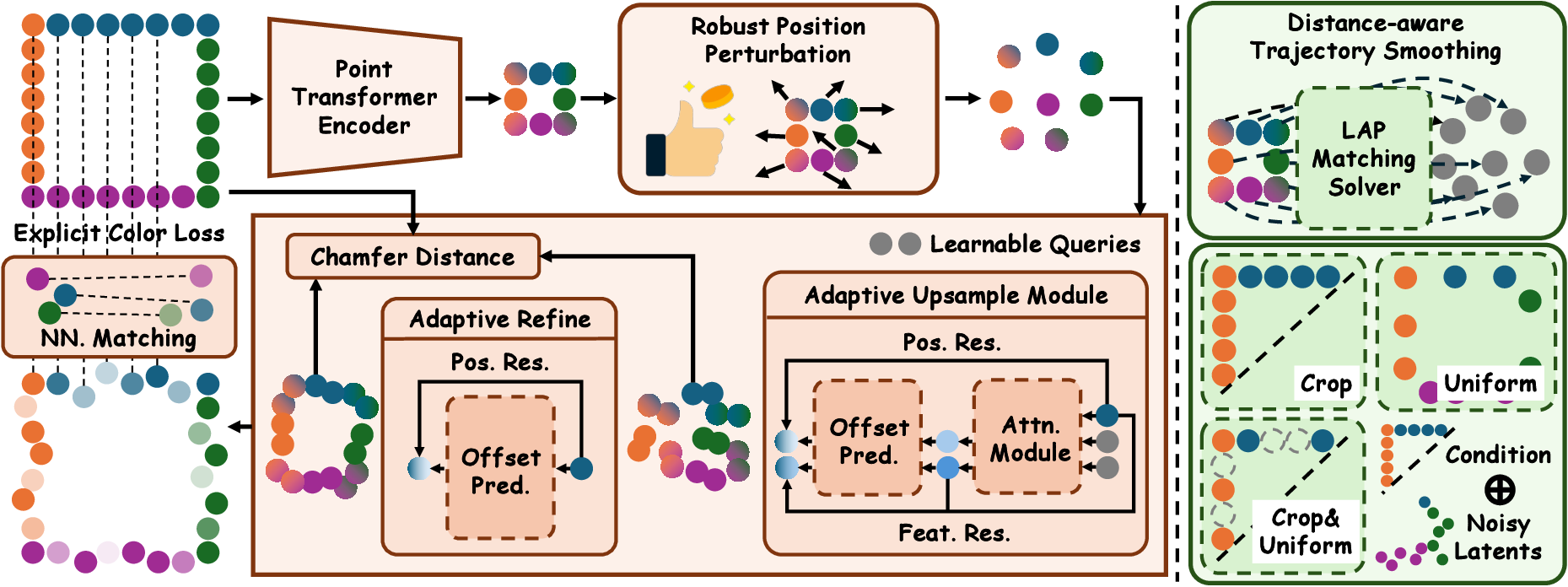
Figure 2: Method details, including linear assignment for trajectory smoothing, position and feature residuals, and nearest neighbor color supervision.
Native 3D Generative Modeling
Generative modeling in Terra is achieved via flow matching, where noise is progressively added to both positions and features of point latents, and a 3D sparse UNet predicts the velocity vector for denoising. The model simultaneously learns the joint distribution of geometry and texture, facilitating mutual enhancement.
A critical contribution is the distance-aware trajectory smoothing technique, which optimizes the matching between noisy samples and point latents using the Jonker-Volgenant algorithm, minimizing transport distances and straightening denoising trajectories for unstructured point clouds.
Conditional generation is supported via multi-stage training (reconstruction, unconditional pretraining, masked conditional generation) and flexible conditioning mechanisms (cropping, uniform sampling, and combinations), enabling diverse exploration styles.
Experimental Results
Terra is evaluated on the ScanNet v2 dataset across reconstruction, unconditional generation, and image-conditioned generation tasks. The model demonstrates state-of-the-art performance in 3D consistency, geometry quality, and efficiency.
Reconstruction
Terra outperforms baselines in PSNR, SSIM, Abs. Rel., RMSE, and δ1 metrics, reconstructing complete scenes in a single forward pass and completing partial objects even in regions with sensor failures.
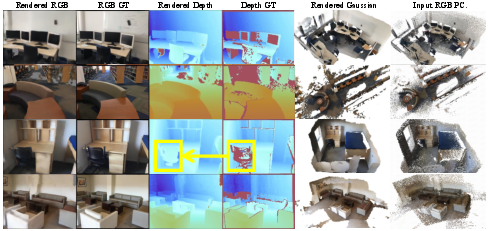
Figure 3: Terra achieves photorealistic rendering for RGB and depth, completing partial objects in challenging regions.
Unconditional Generation
Terra achieves superior point cloud FID (P-FID) and KID (P-KID) compared to Prometheus (2.5D) and Trellis (3D grid), validating the efficacy of point latents for geometry modeling. While Prometheus excels in image quality metrics due to 2D diffusion pretraining, its underlying 3D structures are less consistent.

Figure 4: Terra generates diverse and reasonable scenes, whereas Prometheus and Trellis lack consistent geometry and texture, respectively.
Image Conditioned Generation
Terra demonstrates better geometry quality (chamfer and earth mover's distances) than Prometheus, with improved multi-view consistency, despite Prometheus achieving lower FID and KID.

Figure 5: Terra and Prometheus produce plausible images, but Terra maintains superior geometry consistency.
Explorable World Modeling
Terra supports step-by-step exploration, generating coherent and diverse room layouts with plausible textures, validating its capacity for progressive world simulation.

Figure 6: Terra generates coherent and diverse room layouts from step-by-step exploration, supporting explorable world modeling.
Ablation Study
Ablation experiments confirm the effectiveness of Terra's design choices. Position perturbation, adaptive upsampling and refinement, explicit color supervision, and distance-aware trajectory smoothing each contribute to improved reconstruction and generative performance. Notably, position perturbation is essential for generative robustness, while trajectory smoothing is critical for model convergence.
Implications and Future Directions
Terra's native 3D approach offers significant advantages in multi-view consistency, rendering flexibility, and modeling efficiency. The use of point latents and Gaussian primitives enables scalable, rendering-compatible scene generation, bridging the gap between object-level fine-grained and scene-level coarse geometry models.
Practically, Terra can be applied to embodied perception, simulation, and planning tasks requiring accurate and explorable 3D world models. Theoretically, the work suggests that direct modeling in 3D latent spaces can overcome limitations of pixel-aligned representations, paving the way for more robust and efficient world models.
Future research may explore scaling Terra to larger, more complex environments, integrating semantic understanding, and extending the framework to support interactive and multimodal world modeling. Further investigation into efficient training and inference strategies for sparse 3D architectures will be critical for real-world deployment.
Conclusion
Terra establishes a new paradigm for 3D world modeling by leveraging point latents and native 3D architectures. The model achieves state-of-the-art results in reconstruction and generation tasks, supports flexible and progressive exploration, and demonstrates the practical and theoretical benefits of intrinsic 3D representations. Terra's innovations in latent space design, generative modeling, and trajectory smoothing provide a foundation for future advances in explorable, consistent, and efficient world models.