- The paper introduces a Parallel Hybrid Hierarchical 3D Representation (PH²-3D) that organizes scenes into multi-level voxels, eliminating the need for post-hoc merging.
- It implements batch-level multi-task rendering to concurrently produce RGB, depth, and normal maps, ensuring high-resolution and consistent scene synthesis.
- Experiments demonstrate state-of-the-art performance with improvements in PSNR, SSIM, and reduced memory consumption, validated on multiple urban datasets.
CityGS-X: Scalable Parallel Hybrid Hierarchical 3D Gaussian Splatting for Large-Scale Scene Reconstruction
Introduction and Motivation
CityGS-X addresses the persistent challenges in large-scale 3D scene reconstruction, specifically the inefficiencies and geometric inaccuracies inherent in prior 3D Gaussian Splatting (3DGS) approaches. Existing methods typically rely on partition-and-merge strategies for multi-GPU training, which introduce block boundary inconsistencies, redundant representations, and severe scalability bottlenecks due to single-GPU memory constraints. CityGS-X proposes a fundamentally different architecture: Parallel Hybrid Hierarchical 3D Representation (PH2-3D) with batch-level multi-task rendering and progressive RGB-Depth-Normal training. This enables efficient, scalable, and geometrically accurate reconstruction of urban-scale scenes.
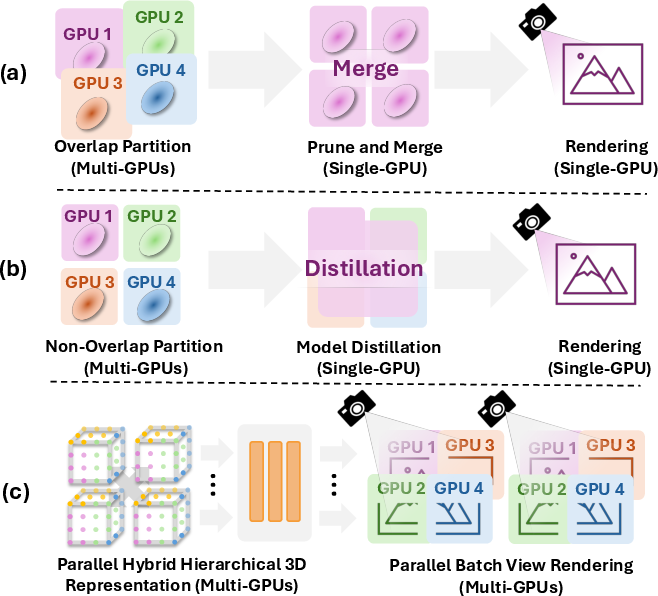
Figure 1: Comparison of CityGS-X's parallel architecture with previous partition-after-merge and distillation-based methods, highlighting improved scalability and efficiency.
Parallel Hybrid Hierarchical 3D Representation (PH2-3D)
The core innovation is the PH2-3D representation, which organizes the scene into K levels of detail (LoDs), each comprising spatially distributed voxels. These voxels are allocated across multiple GPUs using a spatial average sampling strategy to ensure load balancing. Each voxel is parameterized by a learnable embedding, scaling factor, position, and offsets, and is decoded into Gaussian primitives via a shared Gaussian decoder with synchronized gradients. This design eliminates the need for post-hoc merging, reduces memory overhead, and aligns the representation with true scene geometry.
Key implementation details:
- Voxel Distribution: Voxels Xk are assigned to GPUs such that each device processes an equal number of active voxels per view, maximizing parallel efficiency.
- Gaussian Decoding: The shared decoder Fde(⋅) predicts Gaussian attributes in parallel, minimizing inter-GPU communication to gradient synchronization only.
- Scalability: The architecture supports training and rendering of scenes with 5,000+ images on 4×4090 GPUs without OOM errors, far exceeding the capacity of previous methods.
Batch-Level Multi-Task Rendering
CityGS-X leverages its parallel representation for distributed batch-level rendering. Images are patchified (e.g., 16×16 pixels) and assigned to GPUs for concurrent RGB, depth, and normal rendering. The View-Dependent Gaussian Transfer strategy ensures that intersected voxels across all LoDs are efficiently transferred and rendered on the appropriate GPU. This enables:
- Tile-Based Rasterization: Classical rasterization is performed in parallel, supporting high-resolution (up to 4K) rendering.
- Multi-Task Outputs: RGB, depth, and normal maps are rendered simultaneously, facilitating multi-view consistency and geometric supervision.
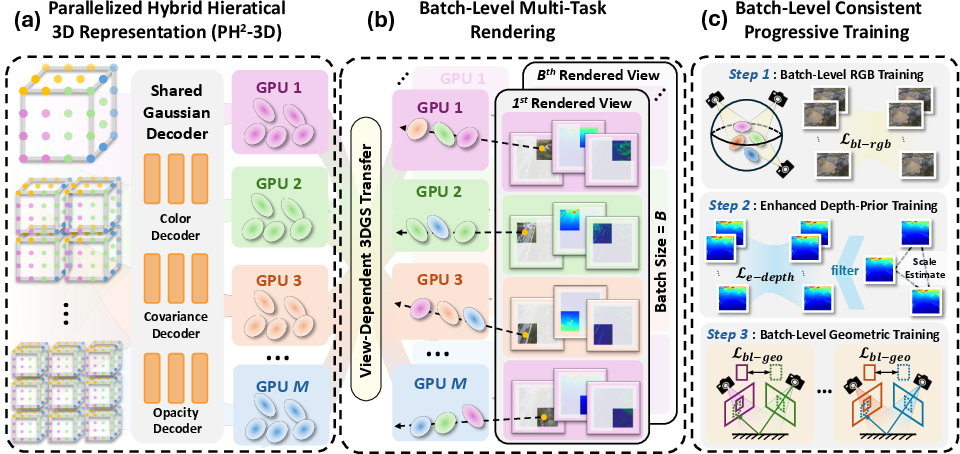
Figure 2: CityGS-X framework overview, illustrating parallel LoD voxel allocation, distributed multi-task rendering, and progressive training.
Batch-Level Consistent Progressive Training
To further enhance geometric fidelity and appearance quality, CityGS-X introduces a three-stage progressive training pipeline:
- Batch-Level RGB Training: Multi-view images are rendered in batches, updating the shared decoder and mitigating viewpoint overfitting.
- Enhanced Depth-Prior Training: Off-the-shelf monocular depth estimators provide pseudo-depth supervision. A confidence-aware filtering strategy masks regions with high reprojection error, regularizing depth only in consistent areas.
- Batch-Level Geometric Training: Multi-view photometric constraints are enforced via normalized cross-correlation between randomly paired image patches, refining fine geometric details.
This progressive approach ensures smooth surface reconstruction, robust geometric alignment, and high-fidelity appearance.
Experimental Results
CityGS-X is evaluated on Mill-19, UrbanScene3D, and MatrixCity datasets, demonstrating superior performance in both quantitative and qualitative metrics.
- Novel View Synthesis: Achieves state-of-the-art PSNR, SSIM, and LPIPS across all scenes, with a notable 0.2dB PSNR improvement on Rubble and 0.026 LPIPS reduction on Sci-Art compared to prior methods.
- Surface Reconstruction: Outperforms CityGS-V2 by 0.35dB PSNR and achieves higher precision, recall, and F1 scores on MatrixCity. Meshes exhibit fewer floaters and holes, and preserve fine structural details.
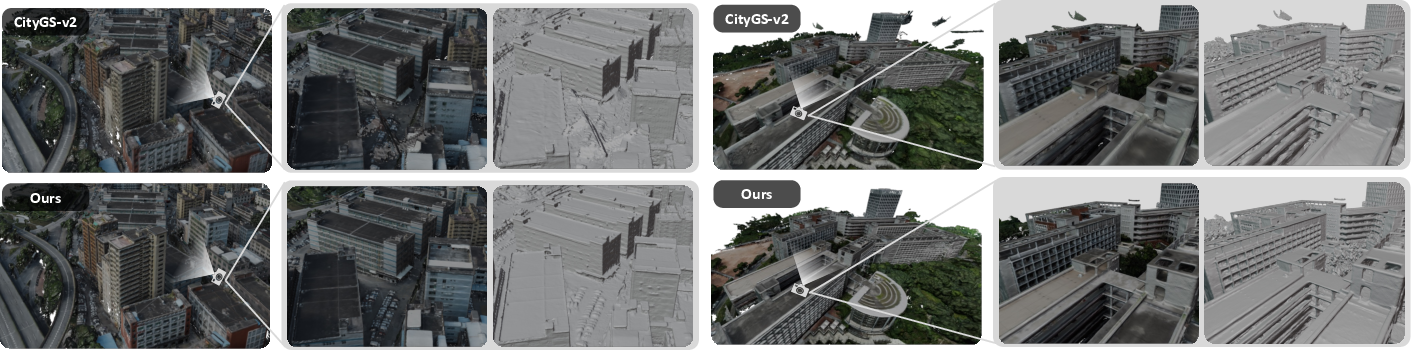
Figure 3: Qualitative mesh and texture comparison between CityGS-V2 and CityGS-X, showing improved geometric detail and surface accuracy.

Figure 4: Qualitative RGB and depth rendering results on Mill-19, demonstrating fine-grained geometric detail and absence of floating artifacts.

Figure 5: Normal map and RGB rendering comparison on UrbanScene3D, highlighting sharper details and smoother reconstructions.
- Training Efficiency: CityGS-X completes training in 5 hours for 5,000+ images on 4×4090 GPUs, while other methods fail due to OOM or require significantly longer times. Memory consumption is reduced by 30–50% compared to alternatives.

Figure 6: Visual comparison of 1080P and 4K training, showing consistent high-quality reconstruction at increased resolution.
- Ablation Studies: Larger batch sizes and more GPUs consistently improve performance due to enhanced multi-view gradient aggregation. Progressive training ablations confirm the necessity of both depth-prior and geometric constraints for optimal results.

Figure 7: Training ablations for MatrixCity, illustrating the impact of progressive training stages on geometric convergence.
Implementation Considerations
- Hardware Requirements: Multi-GPU systems (e.g., 4×4090) are recommended for optimal scalability. The architecture is robust to lower-end GPUs due to efficient memory management.
- Batch Size: Larger batch sizes (up to 32) are supported, improving generalization and multi-view consistency.
- Depth Priors: Integration of monocular depth estimators requires confidence-aware filtering to avoid multi-view inconsistency artifacts.
- Mesh Extraction: TSDF fusion of rendered depth maps enables high-quality mesh generation for downstream applications.
Implications and Future Directions
CityGS-X establishes a new paradigm for scalable, efficient, and geometrically accurate large-scale scene reconstruction. Its parallel hybrid hierarchical representation and batch-level training pipeline overcome the limitations of partition-and-merge strategies, enabling real-time, high-resolution urban modeling. The approach is directly applicable to urban planning, autonomous driving, and aerial surveying, where large-scale, photorealistic, and metrically accurate 3D models are essential.
Potential future developments include:
- Federated and Distributed Training: Extending PH2-3D to heterogeneous multi-node clusters for even larger scenes.
- Dynamic Scene Reconstruction: Adapting the architecture for 4D (spatiotemporal) modeling.
- Semantic Integration: Incorporating semantic priors for context-aware reconstruction and editing.
Conclusion
CityGS-X introduces a scalable, parallel architecture for large-scale 3D scene reconstruction, leveraging hybrid hierarchical representations and batch-level multi-task rendering. Extensive experiments demonstrate significant improvements in efficiency, scalability, and geometric accuracy over previous methods. The framework sets a strong foundation for future research in distributed, high-fidelity urban scene modeling.