- The paper presents a virtual scanning framework that simulates real scanner behavior to generate paired partial and complete scene data.
- It employs configurable parameters, ray-casting, and panoramic colorization to accurately model occlusions, range limitations, and noise.
- The dataset, produced via procedural scene generation, provides robust supervision for training 3D object completion and occlusion reasoning models.
Synthetic Dataset Generation for Partially Observed Indoor Objects
Motivation and Context
3D scene completion and object-level geometric reconstruction remain challenging, especially because most real-world scan datasets lack complete ground-truth geometry for occluded or hidden regions. Although large-scale RGB-D datasets now exist for indoor scenes, they typically only offer observations of visible surfaces, creating a bottleneck for the development and supervised training of completion networks. This gap is acute for both digital twin applications and embodied AI, where prediction of unobserved structure is necessary for downstream tasks.
Recent advances in deep learning for point cloud completion, such as the integration of material segmentation with geometry and texture inference approaches [vermandere_geometry_2025], have accentuated the importance of high-fidelity partial-to-complete pairs. However, acquiring such data through real-world multi-position terrestrial scanning is costly and limited. Synthetic dataset creation offers a scalable alternative, but prior work focused on mesh surface sampling fails to capture important physical constraints such as occlusion, range, and noise.
Virtual Scanning Framework
To address these challenges, the work presents a robust virtual scanning framework implemented within Unity, designed specifically to simulate real-world scanner behavior (Figure 1). Key features include support for configurable parameters that mimic commercial hardware, such as measurement range, scanner resolution, angular coverage, and both systematic and distance-dependent noise. Instead of naïvely sampling mesh vertices, the system explicitly casts rays from scanner viewpoints, enabling physically accurate modeling of occlusions, missed regions, and range limitations.
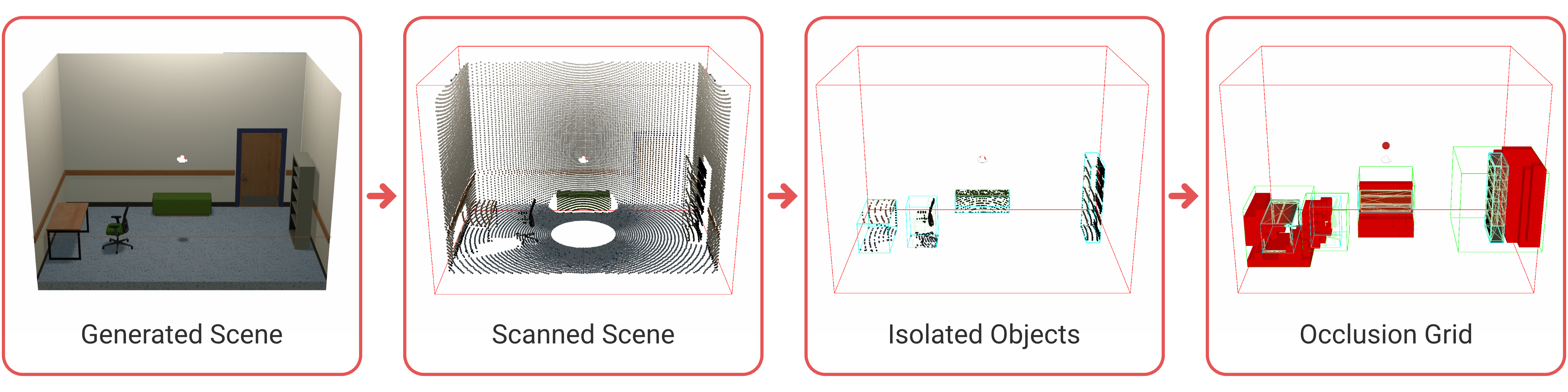
Figure 1: Virtual scanner overview highlighting input configuration and the high-level flow from scene asset ingestion to scan acquisition and data export.
Unity's extensibility enables modular integration with arbitrary 3D environments. The system generates a field of scan vectors through a stratified spherical arrangement (Figure 2), achieving uniform directional coverage with computational efficiency.
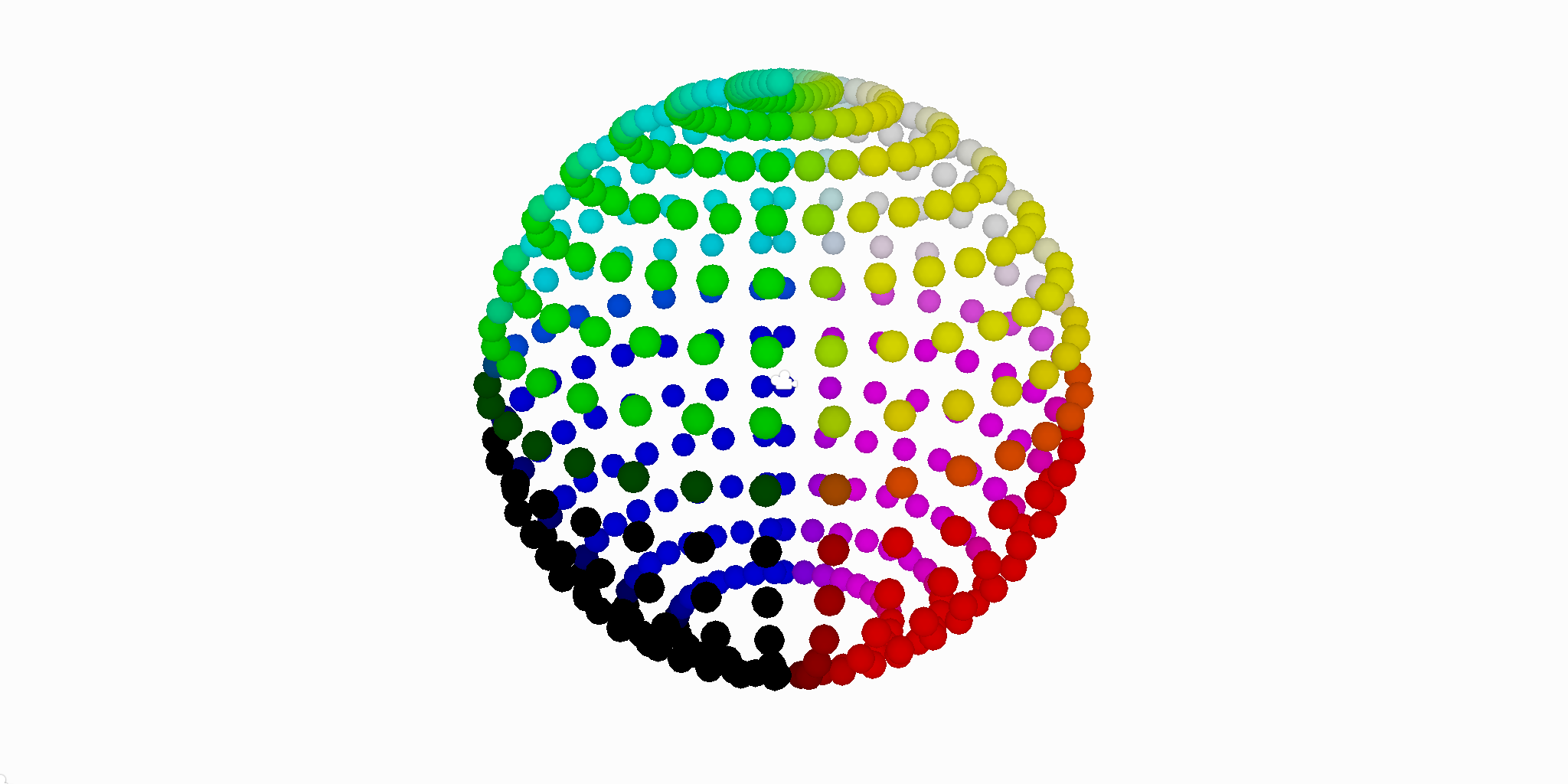
Figure 2: Spherical array of scan vectors at the scan initialization stage, color-coded by their direction.
Once vectors are defined, ray-casting determines intersection points, forming partial noisy point clouds. Points out of range are discarded, aligning the acquisition characteristics with real hardware, including time-of-flight LiDAR or structured light devices. State-of-the-art simulators, especially those focused on mobile robotics or topographic LiDAR, typically lack either object isolation capabilities or explicit occlusion labeling—capabilities this framework directly addresses.
Point Cloud Colourization and Object Isolation
To increase the realism of the synthetic scans, the framework captures a 360∘ panoramic cubemap from the scanner's location. Each ray intersection is colorized by projecting the 3D intersection back into panoramic UV coordinates, replicating lighting and appearance characteristics of its virtual context (Figure 3).

Figure 3: Equirectangular projection of the panoramic RGB image used for point color assignment.
Object isolation is enabled via the association of unique scripts (ScannedObject) to non-structural mesh instances, supporting the extraction of per-object oriented bounding boxes, partial clouds, and visibility grids. Each object, or the scene as a whole, can have a corresponding voxelized occlusion grid, where each voxel is classified as occupied, observed, or occluded based on line-of-sight analysis from the scanner (Figure 4).
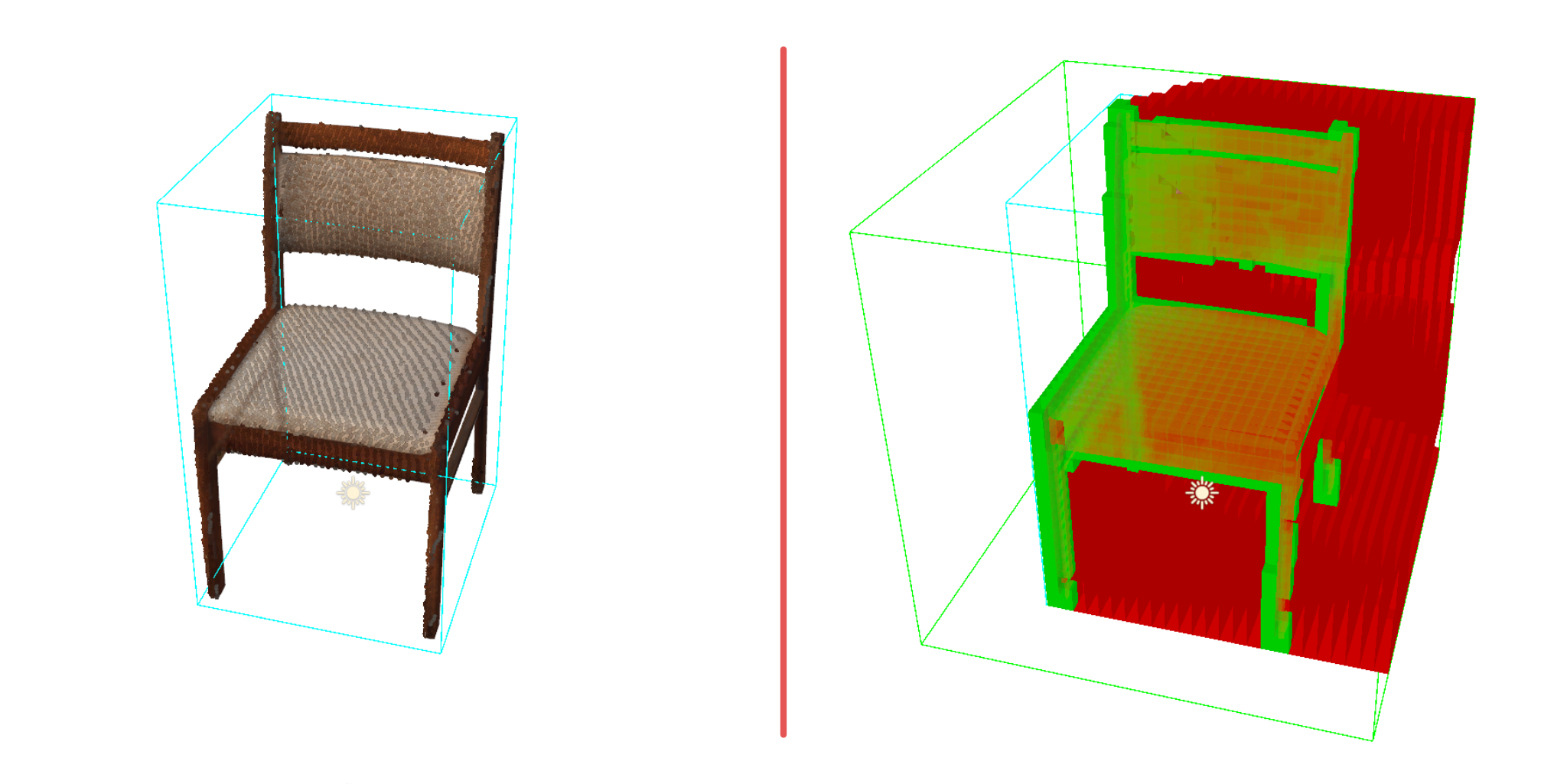
Figure 4: Partially scanned object (left) and its corresponding voxel occlusion grid, with green for occupied and red for occluded voxels.
This explicit occlusion modeling provides dense supervision for occlusion reasoning—a feature typically absent from both real datasets [scannet_2017, song_sun_2015] and competing simulation frameworks [blume_simulating_2006, winiwarter_virtual_2022].
Procedural Scene Generation
Scalability is achieved by integrating the scanner with a fully procedural indoor scene generation pipeline in Unity. Each scene is instantiated using stochastic sampling for room dimensions, followed by tile-based wall, ceiling, and floor placement. Architectural elements such as windows and doors are procedurally assigned, and both wall-mounted and freestanding furniture are populated with physically consistent collision-aware positioning (Figure 5).

Figure 5: Overview of generated scene layouts, including both top-down and perspective views for two environment styles.
Asset styles and furniture collections are modular, permitting control over architectural themes. This enables broad coverage in data-driven model training and evaluation, similar in spirit to recent advances in controllable 3D scene generation [chen_roompilot_2025, raistick_infinigen_nodate, tang_diffuscene_2024]. Scene generation is fully deterministic via seeded PRNG, supporting reproducible experiments.
Dataset Composition and Export
The resulting V-Scan dataset comprises approximately 100 diverse, furnished indoor scenes. Each sample includes:
- Furnished scan: Colorized partial point cloud and panorama extracted from the full environment.
- Empty scan: Scene-only geometry (without furniture), forming complete ground truth.
- Object-level data: Per-object partial point clouds, OBBs, full ground-truth meshes, and sparse voxel occlusion grids.
- Scene-level voxel grids: Explicit labeling of total observable, occupied, and occluded spatial regions.
Automated scanner placement ensures uniform conditions and annotation completeness. This structure enables benchmarking of both occlusion reasoning and object completion, bridging the gap between simple mesh-based synthetic datasets (e.g., ShapeNet [chang_shapenet_2015], ModelNet [wu_3d_2015]) and real-world scanned datasets (e.g., SUN RGB-D [song_sun_2015], Matterport3D [chang_matterport3d_2017], ScanNet++ [yeshwanth_scannet_2023]) that lack ground-truth for unobserved regions.
Implications and Future Directions
The introduction of realistic synthetic scan data with paired ground-truth occlusion and object completeness significantly advances the methodological toolkit for geometric completion, scene reconstruction, and occlusion reasoning. This approach enables systematic ablation studies on the impact of occlusion, range, and noise characteristics on supervised learning.
On a practical level, the approach supports the development of deep networks that can more effectively generalize to real scan degradation patterns, such as incomplete visibility and out-of-range areas. The dataset provides extensive supervision for approaches leveraging voxel occupancy, material-predictive features, and partial observation priors, opening avenues for end-to-end differentiable scene synthesis and robust completion in data-starved application domains.
Potential future extensions identified by the authors include simulation of mobile scanning trajectories, extension to multi-room layouts, and incorporation of time-varying dynamic objects. Advances in procedural scene realism, e.g., through learned generative scene generators [tang_diffuscene_2024], could further increase domain fidelity and transferability.
Conclusion
This work introduces a unified pipeline for producing high-fidelity partially observed scan data paired with fully annotated ground truth for both scenes and individual objects. By leveraging physically realistic virtual scanner simulation and procedural Unity-based scene generation, the resulting V-Scan dataset is well-positioned to catalyze progress in supervised 3D object completion, scene reconstruction, and occlusion reasoning. The framework effectively balances physical accuracy with efficient, scalable data generation, providing a reproducible standard for evaluating learning-based 3D perception systems.
References: (2604.07010), [vermandere_geometry_2025], [chang_shapenet_2015], [wu_3d_2015], [chang_matterport3d_2017], [scannet_2017], [yeshwanth_scannet_2023], [tang_diffuscene_2024], [chen_roompilot_2025], [raistick_infinigen_nodate], [blume_simulating_2006], [winiwarter_virtual_2022]