- The paper introduces a modular pipeline that transforms unlabeled videos into high-quality 3D scene data for tasks like detection, segmentation, spatial VQA, and navigation.
- It presents SceneVerse++, a large-scale dataset of 6,687 indoor scenes featuring diverse, multi-room environments and detailed semantic annotations.
- Empirical results demonstrate strong zero-shot transfer and improved performance across tasks, while highlighting challenges such as domain bias and sensitivity to segmentation granularity.
Lifting Unlabeled Internet-level Data for 3D Scene Understanding
Introduction and Motivation
The paper "Lifting Unlabeled Internet-level Data for 3D Scene Understanding" (2604.01907) addresses the persistent bottleneck in 3D scene understanding: the lack of annotated, large-scale, real-world 3D datasets. While internet-scale 2D collections have been leveraged to great effect for visual pretraining, the logistics of 3D acquisition and dense annotation have caused 3D dataset growth to stagnate, with only incremental advances beyond ScanNet, ARKitScenes, and ScanNet++. The central contribution of this work is the design and analysis of modular, automated data generation pipelines capable of transforming unlabeled, in-the-wild videos into high-quality 3D scene data suitable for end-to-end model supervision in detection, segmentation, spatial VQA, and navigation.
The SceneVerse++ Dataset: Construction and Statistics
The authors curate SceneVerse++, a dataset comprising 6,687 diverse and large-scale real-world indoor scenes drawn from internet-sourced videos. The pipeline leverages robust shot detection, view selection, and filtering to ensure frame quality and indoor focus. Sparse reconstruction and pose estimation use feature-rich, parallax-driven keyframe extraction and dense bundle adjustment. The result is a dataset that not only surpasses competing repositories in the number of unique spaces, but crucially scales to multi-room, multi-floor, and high object-diversity scenarios, reflecting in-the-wild complexity absent from prior collections.
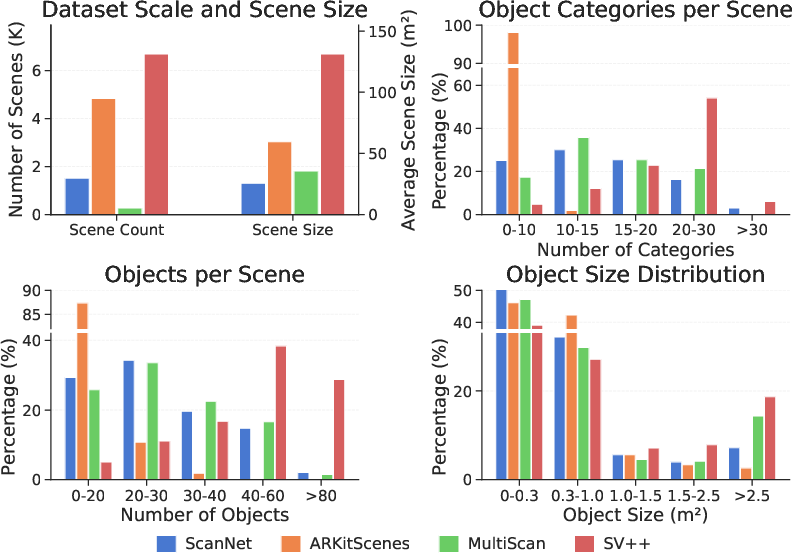
Figure 1: SceneVerse++ encompasses more scenes, larger areas, and greater object diversity compared with existing real-world datasets.
Modular Data Engine for Automatic 3D Groundtruth Generation
The data engine employs a multi-stage modular pipeline for efficient and scalable dense geometry and semantic annotation:
- 3D Reconstruction: Sparse SfM outputs are densified via metric depth prediction using depth priors projected from SfM point clouds, which are fused in a TSDF representation. This enables watertight mesh generation with filtering for consistency and noise rejection, balancing between neural rendering fidelity and tractable compute costs.
- Instance Segmentation: 2D segmentation masks (CropFormer) are aggregated using geometric alignment and view consensus. Instances are semantically grounded with vision-LLMs (Describe Anything, Qwen2-VL), and mapped to common taxonomies (e.g., ScanNet categories).
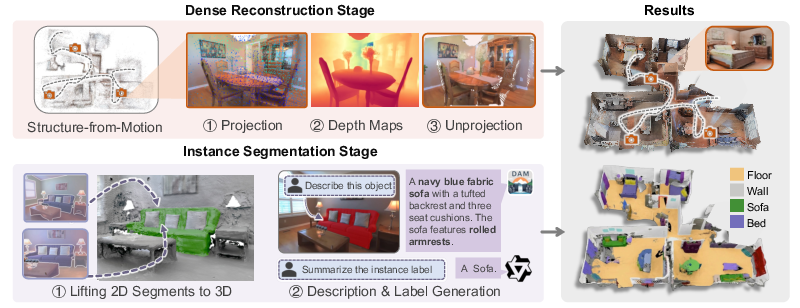
Figure 2: The pipeline leverages a modular design for automatic 3D reconstruction and segmentation.
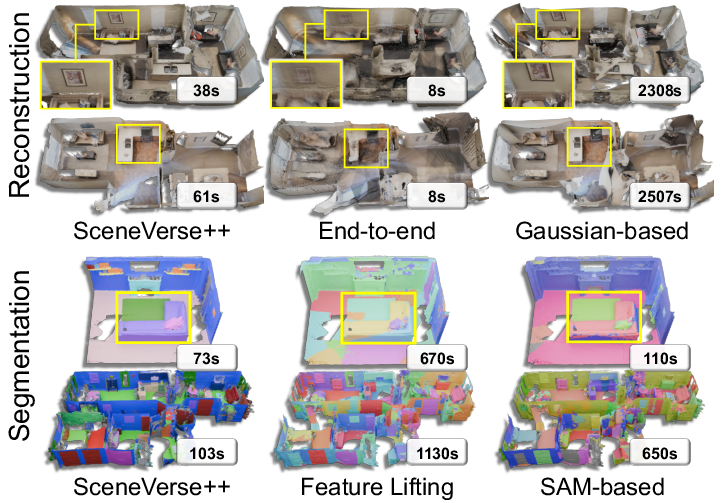
Figure 3: SceneVerse++ features a balance in reconstruction quality and efficiency, as compared to existing approaches.
Empirical results indicate that on average, each SceneVerse++ scene contains 49 objects from 21 categories, outstripping the diversity and scale of prior datasets. The computational overhead is manageable (∼0.6 GPU-CPU hours/scene), enabling feasible massive-scale data transformation.
Benchmark Transfer and Analysis
3D Object Detection and Instance Segmentation
Models trained with SceneVerse++ demonstrate strong zero-shot transfer to real-world benchmarks (ScanNet, ARKitScenes). For instance, SpatialLM, originally tuned on synthetic data, achieves higher [email protected] on ScanNet when pretrained with SceneVerse++ (30.9 vs 29.0, zero-shot), which surges to 58.6 upon consistent finetuning, in contrast to 38.0 for purely synthetic pretraining. However, Mask3D segmentation performance exhibits high sensitivity to input segmentation distribution, with substantial performance drop in domain-shifted regimes, indicating model architectures heavily dependent on precomputed instance-level cues are less scale-robust.
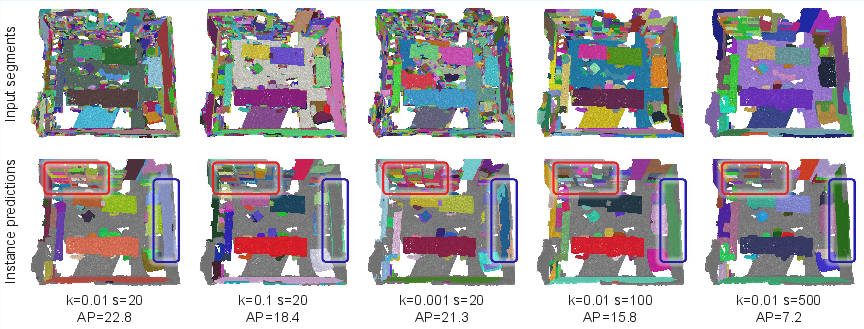
Figure 4: Instance segmentation models exhibit high sensitivity to input segment granularity; over/under-segmentation degrades AP even with robust pretraining.
Spatial VQA and Generalization
Spatial reasoning tasks are addressed by constructing 3D scene graphs and templated VQA data. Leveraging 632K automatically generated QA samples, models such as Qwen2.5-VL-3B/7B show +14.9/+9.8 absolute improvement on the VSI-Bench full set in zero-shot transfer relative to unfine-tuned baselines. Category analysis reveals that gains are more pronounced for general spatial relations (e.g., relative distance, direction), while tasks relying on dataset-specific distributions (object count, room size) can show reduced generalizability—attributing to domain and dataset bias.
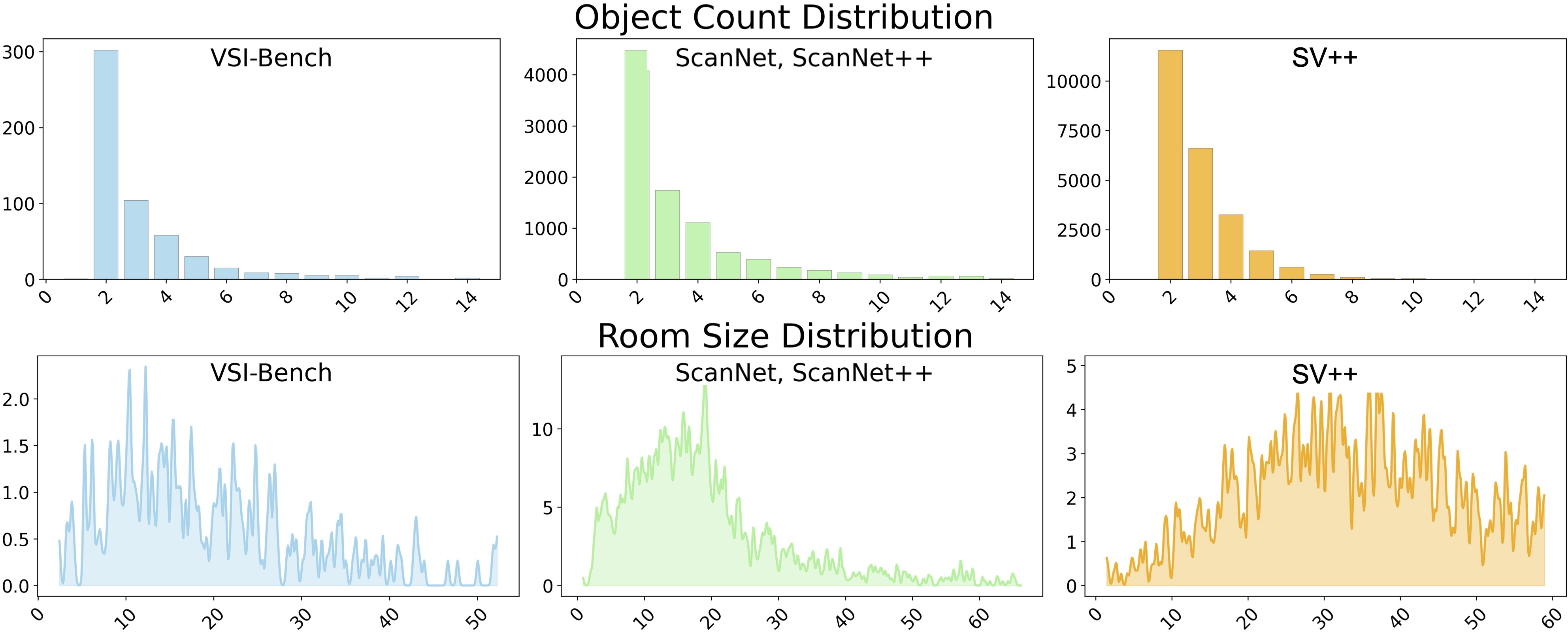
Figure 5: Distribution statistics of 3D spatial VQA answer types generated and used for spatial reasoning model benchmarking.
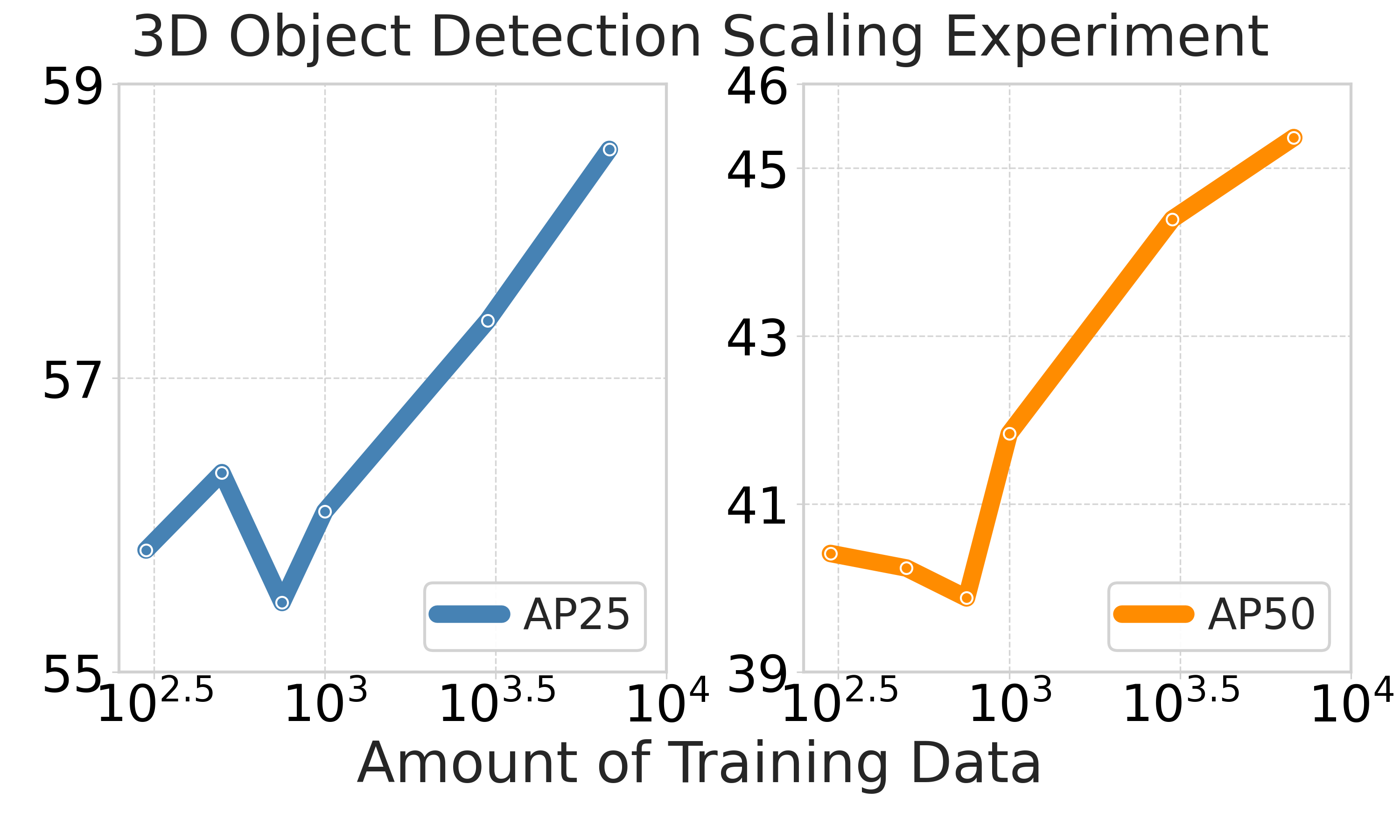
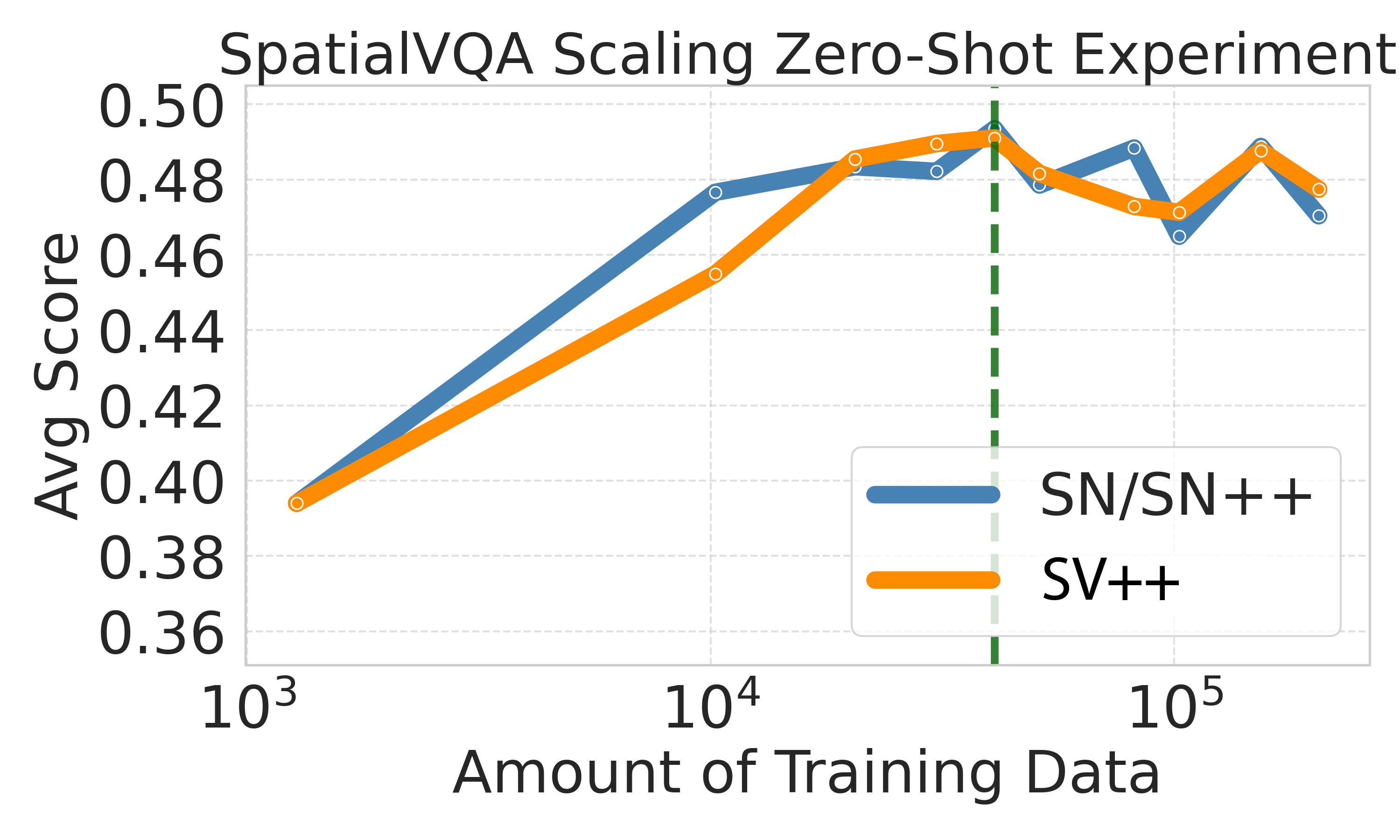
Figure 6: Data scaling curves empirically confirm log-linear trends up to model/data saturation, with effective scaling varying by task alignment and architecture.
Vision-Language Navigation (VLN) from Room-Tour Videos
The VLN pipeline refines raw human-captured room-tour trajectories via postprocessing and action encoding steps to best approximate structured, goal-oriented navigation as in R2R. Three stylistic modes for instruction synthesis ensure linguistic diversity. Empirically, pretraining on SceneVerse++ and subsequent finetuning on R2R yields SR = 0.228, compared to 0.088 with R2R only—a +14% improvement in navigation success, attributable to the richer motion and language patterns harvested from unconstrained internet videos.

Figure 7: Multi-stage VLN data generation—trajectory refinement, action encoding, and language grounding by VLMs—aligns unconstrained egocentric video for navigation tasks.
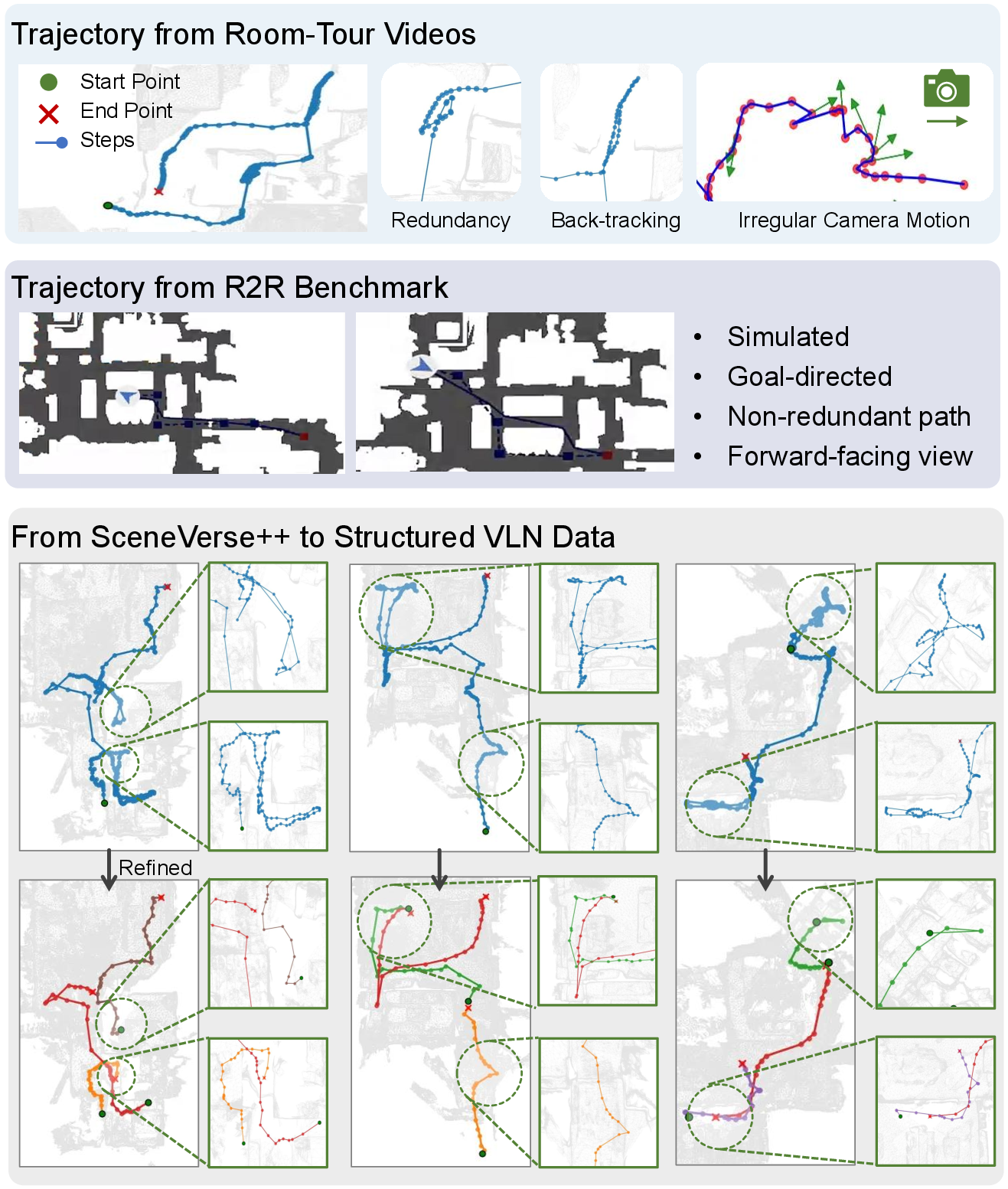
Figure 8: Room-tour videos exhibit irregular, often redundant camera motion. The pipeline yields navigation-structured, goal-consistent R2R-compatible trajectories.
Implications, Biases, and Model Scaling
The work exposes that the ability to effectively scale data and transfer to out-of-domain tasks is highly dependent on model class and architecture. Models ingesting raw geometric features or operating as MLLMs show more robust zero/few-shot generalization. Conversely, approaches highly tuned to specific precomputed modalities (segment-based detectors) incur substantial accuracy penalties under task or dataset shift.
The analysis of spatial reasoning and navigation tasks demonstrates that large-scale, internet-sourced data (when properly curated and processed) can close both the quantity and quality gaps in 3D scene supervision—even when explicit ground truth is absent—provided attention is paid to pipeline modularity, error propagation, and domain biases.
The authors offer a critical position: scaling 3D scene data via automation should not be viewed as a “plug-and-play” system, but rather as a continuous co-design effort between improved sub-module models, fair benchmarks measuring generalizable scene understanding, and models robust to real-world data variety. Moreover, the empirical evidence of domain bias in both representations and benchmarks (as shown in spatial QA and VLN tasks) implies that truly universal 3D scene understanding remains open, requiring not merely data scale but architectural and evaluation innovations as well.
Conclusion
This work demonstrates, through large-scale dataset construction and multi-task supervisory experiments, the practical feasibility and limitations of modular, automated data engines for 3D scene understanding. SceneVerse++ establishes a new state-of-the-art for diversity, scale, and realism in 3D scene datasets derived from unlabeled internet videos. The modular pipeline enables effective zero-shot transfer to detection, segmentation, spatial VQA, and navigation tasks—especially when coupled with robust, end-to-end model architectures. The findings underscore that efficient scaling in 3D demands both hardware-aware pipeline design and theoretical progress in reducing bias and increasing generalization in model architectures and benchmarks. This paradigm is poised to catalyze further research into robust, real-world–capable 3D scene understanding systems, with the potential for direct impact in robotics, embodied AI, and spatially grounded reasoning.