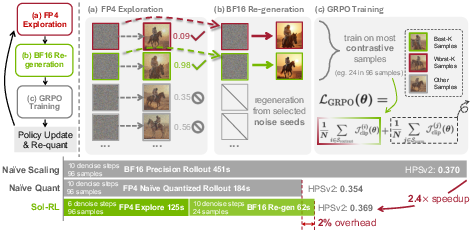
FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
Abstract: Reinforcement-Learning-based post-training has recently emerged as a promising paradigm for aligning text-to-image diffusion models with human preferences. In recent studies, increasing the rollout group size yields pronounced performance improvements, indicating substantial room for further alignment gains. However, scaling rollouts on large-scale foundational diffusion models (e.g., FLUX.1-12B) imposes a heavy computational burden. To alleviate this bottleneck, we explore the integration of FP4 quantization into Diffusion RL rollouts. Yet, we identify that naive quantized pipelines inherently introduce risks of performance degradation. To overcome this dilemma between efficiency and training integrity, we propose Sol-RL (Speed-of-light RL), a novel FP4-empowered Two-stage Reinforcement Learning framework. First, we utilize high-throughput NVFP4 rollouts to generate a massive candidate pool and extract a highly contrastive subset. Second, we regenerate these selected samples in BF16 precision and optimize the policy exclusively on them. By decoupling candidate exploration from policy optimization, Sol-RL integrates the algorithmic mechanisms of rollout scaling with the system-level throughput gains of NVFP4. This synergistic algorithm-hardware design effectively accelerates the rollout phase while reserving high-fidelity samples for optimization. We empirically demonstrate that our framework maintains the training integrity of BF16 precision pipeline while fully exploiting the throughput gains enabled by FP4 arithmetic. Extensive experiments across SANA, FLUX.1, and SD3.5-L substantiate that our approach delivers superior alignment performance across multiple metrics while accelerating training convergence by up to $4.64\times$, unlocking the power of massive rollout scaling at a fraction of the cost.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about teaching AI image generators (like the ones that turn text prompts into pictures) to make images that people like more—faster and cheaper. The authors introduce a method called Sol‑RL that uses two “modes” of computation:
- a super‑fast, low‑precision mode to explore many ideas quickly
- a high‑precision mode to fine‑tune the model only on the best (and worst) examples
Think of it like skimming lots of low‑resolution thumbnails to find the most interesting photos, then re‑creating just those in full HD before using them to teach the AI what to do.
What questions the paper asks
In simple terms, the paper asks:
- How can we check many possible images for each prompt without spending a ton of time and compute?
- Can we use a faster, lower‑precision number format (called FP4) to explore options without hurting training quality?
- If low‑precision images aren’t perfect for learning, can we still use them to pick the best examples, then train on high‑quality versions instead?
How the method works (in everyday language)
To understand the approach, here are a few quick ideas explained simply:
- Diffusion model: A kind of image generator that starts from random “noise” and gradually cleans it up to form a picture.
- Reinforcement learning (RL): A way of teaching a model by giving it rewards for doing well (e.g., making images humans prefer).
- Rollouts: For each prompt (like “a cat surfing”), the model makes many candidate images. We compare them and use the best information to improve the model.
- Precision: Computers represent numbers with a certain number of bits. FP4 is a fast, 4‑bit format (very small, like sketching with a thick marker), while BF16 is a slower, 16‑bit format (more detailed, like drawing with a fine pen).
The problem: If you make lots of images for each prompt (to better judge what’s good), it becomes very expensive. Using low precision everywhere is fast but can hurt learning because the training samples aren’t precise enough—the model might learn from slightly “wrong” images.
The two‑stage Sol‑RL approach
The authors split the process into two stages to get the best of both worlds:
- Stage 1: FP4 Explore (fast “scout mode”)
- Generate a large batch of quick, low‑precision images (for example, 96 per prompt) using FP4 and fewer steps.
- Score them using reward models (automatic judges of image quality and prompt match).
- Use these quick images only to rank which seeds (the starting random noises) look most promising or most problematic.
- Stage 2: BF16 Train (careful “HQ mode”)
- Take just the top and bottom seeds (for example, 24 total) and re‑generate those images in high precision (BF16) with more steps.
- Train the model using only these high‑quality images and their rewards.
Why this works: Even though FP4 images aren’t perfect, they usually keep the overall layout and idea (e.g., “there is a cat on a surfboard”), which is enough to tell which ones are better or worse. So FP4 is great for fast ranking, and BF16 is used where accuracy really matters—during training.
What the researchers found
Here are the main results, and why they matter:
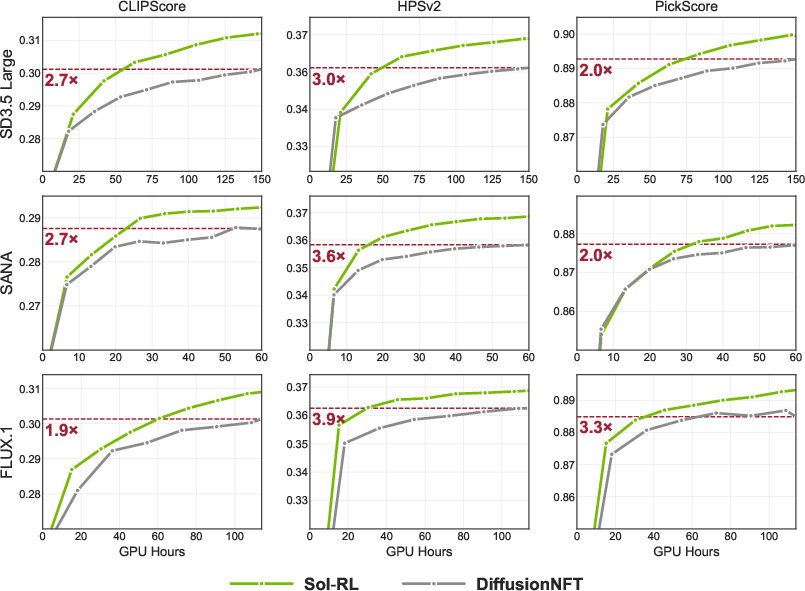
- Much faster training to the same or better quality
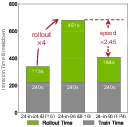
- Sol‑RL reached the same reward level up to about 4.64× faster in wall‑clock time.
- Per training step, the “make images” part sped up by about 2.4×; overall step time improved by about 1.6×.
- This means you can explore many more ideas in the same amount of time.
- Better final image alignment
- Across multiple measures (ImageReward, CLIPScore, PickScore, HPSv2), Sol‑RL achieved higher scores than several leading methods.
- In simple terms: the images matched the prompts better and looked more appealing.
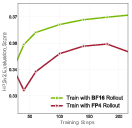
- Training stays stable and high‑quality
- Training only on BF16 re‑generated samples preserved quality: performance matched or was within ~1% of a full high‑precision pipeline, while being much faster.
- Directly training on FP4 images (without the two‑stage approach) caused unstable training and worse results—so the split is important.
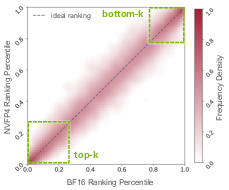
- The FP4 “rank then regenerate” idea is reliable
- The quick FP4 images were good enough to rank candidates correctly most of the time, especially for the best and worst items—the ones most useful for learning.
- Works across different big image models
- The approach improved SANA, FLUX.1, and Stable Diffusion 3.5‑Large, showing it’s broadly useful.
Why this matters
- Cheaper, faster alignment: Teaching giant image models what people like usually takes lots of compute. Sol‑RL cuts the cost and time, which helps researchers and companies train better models more efficiently.
- Better use of new hardware: The method takes advantage of modern GPUs that run FP4 very fast, using them smartly without sacrificing final quality.
- Scales to bigger models and datasets: Because you can explore many more candidates quickly, the model sees more variety and learns better preferences.
- A general idea for other AI tasks: The “fast explore, precise train” pattern could help in other areas where we need to try many options (like text generation or video).
A simple analogy to remember it by
- FP4 Explore = flipping through lots of low‑res thumbnails to pick interesting photos fast.
- BF16 Train = re‑creating just those selected photos in high resolution and using them to teach the model what “good” looks like.
By combining speed and accuracy in the right places, Sol‑RL helps AI image generators learn better preferences in a fraction of the time.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. These points highlight what remains missing, uncertain, or unexplored, and suggest concrete directions for future research.
- Robustness of FP4-based proxy ranking:
- Quantify rank preservation with formal statistics (e.g., Spearman/Kendall correlations, top-k hit rate, pairwise inversion rate) across prompts, seeds, and throughout training as the policy evolves, rather than relying on a qualitative heatmap.
- Analyze failure modes where FP4 exploration misselects top/bottom candidates (e.g., fine-grained text rendering, small objects, faces), and measure the impact on final alignment.
- Generality of the two-stage pipeline:
- Validate ranking robustness with stochastic samplers (e.g., SDE/ancestral) and alternative ODE solvers/schedules; the method currently assumes deterministic ODE sampling and uses fewer steps in Stage 1 than Stage 2 without exploring broader sampler discrepancies.
- Test on broader generative modalities (video, audio, 3D, text-to-video) and other diffusion architectures to assess cross-domain applicability.
- Hardware and format dependence:
- Assess portability beyond NVIDIA Blackwell/NVFP4 (e.g., MXFP4, INT4, FP8, or non-NVIDIA hardware). How does ranking fidelity and speedup change with different low-bit formats, block sizes, scaling schemes, and micro-scaling strategies?
- Provide a detailed analysis of overheads from frequent re-quantization of updated weights and any kernel re-compilation costs on various hardware.
- Scaling behavior and hyperparameterization:
- Explore larger rollout groups and different K/N ratios, and develop adaptive selection policies (e.g., dynamic K based on proxy uncertainty) rather than a fixed top/bottom-K.
- Systematically study sensitivity to the number of FP4 exploration steps and to denoising schedules beyond the tested ranges, including learned or prompt-adaptive schedules.
- Reward-model and metric dependence:
- Evaluate robustness of FP4 ranking and final alignment under different or conflicting reward models, especially when optimizing multiple rewards jointly (e.g., trade-offs among ImageReward, HPSv2, OCR).
- Incorporate human preference evaluations to validate that speedups and metric gains translate to genuine human alignment (mitigate reward hacking).
- Safety, bias, and failure cases:
- Analyze effects on safety-critical prompts (e.g., harmful content, bias, fairness) and whether FP4 exploration introduces selection bias toward images that metrics favor but humans find undesirable.
- Investigate whether quantized exploration skews class/attribute distributions in the selected seeds.
- Theoretical guarantees and assumptions:
- Empirically estimate or upper bound the perturbation term Δ in the theory, and test the Lipschitz and sub-Gaussian assumptions used in the EVT-based argument on real models/data.
- Characterize how Δ and rank preservation evolve as the model is fine-tuned (distribution shift over training) and with different solvers or precision formats.
- On-policy/off-policy considerations:
- Although Stage 2 regenerates BF16 targets, Stage 1 uses a quantized policy to pick seeds; analyze residual off-policy bias rigorously, and compare with methods that unify precision across rollout and training (e.g., FP8-on-policy baselines).
- Integration with broader RL for diffusion:
- Examine compatibility with alternative diffusion RL objectives (e.g., DDPO variants, DPO-like methods, forward-process vs reverse-process objectives) and whether FP4 exploration affects them differently.
- Study interactions with GRPO variants (e.g., branching, tree search) and whether FP4 exploration remains a reliable proxy when trajectories branch or share partial histories.
- Impact of guidance and sampling settings:
- Evaluate how classifier-free guidance strength, negative prompts, and other conditioning strategies affect FP4 ranking reliability and final alignment; current results mix/no-use of CFG and do not ablate guidance systematically.
- Efficiency breakdown and end-to-end system costs:
- Provide a fine-grained runtime/energy breakdown (generation vs reward inference vs optimization vs I/O) to explain why 4× theoretical TFLOPs translate to ~2.4× rollout speedup and to identify remaining bottlenecks (e.g., reward model evaluation).
- Measure energy efficiency and memory footprints under FP4 exploration and BF16 regeneration to report cost-per-aligned-sample and carbon implications.
- Long-horizon stability and convergence:
- Assess training stability across long runs (catastrophic forgetting, oscillations) and under more aggressive scaling (N≫96). Report variance across seeds and runs, not just means.
- Selection strategy and uncertainty:
- Investigate alternative selection criteria that account for ranking uncertainty (e.g., confidence intervals, margin-based selection) and study how misranking near the top-k boundary affects learning.
- Effect of parameterization and adaptation:
- Explore full fine-tuning vs LoRA, higher/lower LoRA ranks, and the impact of frequent parameter updates on FP4 ranking fidelity across iterations.
- Evaluate whether quantization-aware training or mixed-precision training in Stage 2 could further reduce the gap or remove the need for BF16 regeneration.
- Dataset and domain coverage:
- Validate on more diverse prompt sets (e.g., DrawBench, MS-COCO captions, PartiPrompts, synthetic/long-tail prompts) to assess generalization beyond PickScore prompts and ensure broad robustness.
- Reproducibility details:
- Provide complete configuration details for samplers, seeds, temperature/noise settings, and reward-model versions to allow precise replication of ranking reliability and speedup claims.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s two-stage “FP4 Explore, BF16 Train” (Sol-RL) framework today.
- Accelerated alignment/fine-tuning of text-to-image (T2I) models for production content
- Sectors: Media/entertainment, advertising, gaming, e-commerce, design
- Tools/products/workflows: Integrate Sol-RL into existing RLHF/reward-optimization pipelines (e.g., DiffusionNFT + LoRA) to align SANA, FLUX.1, SD3.5-L with image reward models; “rank-then-regenerate” training loop exploiting NVFP4 exploration on NVIDIA Blackwell and BF16 regeneration for updates
- Assumptions/dependencies: Access to NVFP4-capable GPUs (e.g., NVIDIA B200/Blackwell); deterministic ODE sampling with seed reuse; high-quality reward models (ImageReward, CLIPScore, HPSv2, PickScore); base-model licensing for fine-tuning
- Cost and energy reduction in T2I alignment operations
- Sectors: Cloud AI, MLOps, sustainability/operations
- Tools/products/workflows: Replace BF16 brute-force rollouts with FP4 exploration to cut GPU-hours and wall-clock time (up to 4.64× speedups); incorporate energy/CO₂ dashboards to quantify savings
- Assumptions/dependencies: NVFP4 throughput advantage materializes on target hardware; reward-proxy ranking remains reliable at reduced FP4 steps (e.g., ~6 steps)
- Managed “Sol-RL-as-a-Service” in cloud platforms
- Sectors: Cloud providers, model hosting platforms, enterprise AI
- Tools/products/workflows: A hosted API that takes prompts + reward models, performs FP4 exploration at scale, regenerates top/bottom seeds in BF16, and updates LoRA adapters; multi-tenant orchestration of exploration clusters (FP4) and training clusters (BF16)
- Assumptions/dependencies: Efficient multi-precision orchestration, seed caching, and NVIDIA Transformer Engine integration
- Interactive creative tooling with fast variation ranking
- Sectors: Creative software, design tools, marketing platforms
- Tools/products/workflows: Backend runs large FP4 candidate pools per user prompt, returns top-K previews rapidly; regenerate final picks at BF16 for high-fidelity assets; supports “generate many, pick best” UX with low latency
- Assumptions/dependencies: Latency budgets allow FP4 exploration bursts; reward proxies correlate with user preferences; reproducible seeds for deterministic regeneration
- Safety/compliance alignment for T2I models
- Sectors: Trust & safety, platform policy enforcement
- Tools/products/workflows: Add safety-oriented reward models (toxicity, violence, IP compliance) to the Sol-RL loop for rapid updates as policies evolve; nightly FP4 exploration + BF16 updates to maintain compliance
- Assumptions/dependencies: Availability and continuous improvement of safety reward models; governance around reward selection and bias mitigation
- Active data curation and prompt triage
- Sectors: Dataset vendors, MLOps, research labs
- Tools/products/workflows: Use FP4 proxy ranking to select the most contrastive seeds/prompts for labeling, reward modeling, or dataset filtering; prioritize hard cases for human review
- Assumptions/dependencies: Reward models reflect desired properties; deterministic ranking across hardware/software stacks
- MLOps workflow templates for two-stage RL
- Sectors: Software tooling, platform engineering
- Tools/products/workflows: Kubernetes/Ray pipelines that split “explore in FP4, train in BF16,” with seed-preservation and rank-based selection as first-class operations; dashboards for rollout-time vs. iteration-time breakdown
- Assumptions/dependencies: Engineering effort to integrate NVFP4 kernels, deterministic ODE sampling, and LoRA updates with minimal recompilation overhead
- Hardware/accelerator validation for low-precision diffusion RL
- Sectors: Semiconductor/HW acceleration, compiler/runtime stacks
- Tools/products/workflows: Benchmark NVFP4 throughput and ranking fidelity on Sol-RL workloads; optimize kernels and scaling strategies for 4-bit arithmetic
- Assumptions/dependencies: Mature NVFP4 kernels in the NVIDIA Transformer Engine; stable compiler/runtime support
- Academic experiments at larger rollout scales
- Sectors: Academia, open research labs
- Tools/products/workflows: Run large-N ablations and reproducibility studies on GRPO for diffusion without prohibitive compute; evaluate proxy-ranking reliability and quantization-error bounds
- Assumptions/dependencies: Access to Blackwell-class GPUs; open-source Sol-RL implementations and reward models
Long-Term Applications
The following opportunities are promising but may require additional research, scaling, or ecosystem development before wide deployment.
- Extension to video diffusion and multimodal (T2V) RL alignment
- Sectors: Media, social platforms, film/TV, user-generated content
- Tools/products/workflows: Adapt FP4 exploration to long-horizon video diffusion with temporal reward models; regenerate/select sequences in BF16 for training
- Assumptions/dependencies: Robust video reward models; ranking stability over longer sequences; memory/compute scaling for multi-frame ODE solvers
- Two-stage RL for 3D, NeRFs, and CAD asset generation
- Sectors: Gaming, AR/VR, industrial design, robotics simulation
- Tools/products/workflows: FP4 proxy ranking for coarse geometry/structure; BF16 regeneration for high-fidelity meshes/scenes; RL on preference/similarity rewards
- Assumptions/dependencies: Deterministic solvers or reproducible seeds in 3D pipelines; well-calibrated reward functions for geometry/semantic fidelity
- Cross-modal generative alignment (audio, speech, music)
- Sectors: Music tech, voice assistants, media localization
- Tools/products/workflows: Apply rank-then-regenerate to audio diffusion or flow models using perceptual reward metrics; fast exploration in low precision with BF16 updates
- Assumptions/dependencies: Strong audio reward models; quantized kernels for audio architectures; ranking consistency with fewer steps
- Real-time user-in-the-loop personalization loops
- Sectors: Consumer apps, creative marketplaces
- Tools/products/workflows: Continual small-step alignment while users provide feedback; FP4 exploration per session and rapid BF16 micro-updates to LoRA adapters
- Assumptions/dependencies: Very low-latency inference and training; UX design for continual learning; safeguards against drift and preference overfitting
- General RL beyond diffusion (e.g., robotics/control) via decoupled exploration/training
- Sectors: Robotics, autonomous systems, industrial control
- Tools/products/workflows: Low-precision rollout to explore policies cheaply while maintaining high-precision updates for stability
- Assumptions/dependencies: Off-policy gaps and environment stochasticity may reduce ranking reliability; safety and sim-to-real challenges; quantization-sensitive controllers
- Carbon- and cost-aware schedulers for heterogeneous fleets
- Sectors: Cloud/edge operations, sustainability
- Tools/products/workflows: Schedulers that assign FP4 exploration to energy-efficient windows/hardware and BF16 training to HBM-rich nodes; integrate with carbon-intensity signals
- Assumptions/dependencies: Diverse hardware fleet, telemetry APIs, reliable carbon accounting and scheduling policies
- Reward-model development using FP4-enabled hard-example mining
- Sectors: Research, safety, platform policy teams
- Tools/products/workflows: Mine high-contrastive samples cheaply (top/bottom-K) to train better reward models; bootstrap new objectives (style, layout, safety)
- Assumptions/dependencies: Access to human feedback for calibration; pipelines to detect and mitigate bias in reward signals
- Open standards and libraries for rank-then-regenerate pipelines
- Sectors: OSS community, enterprise AI tooling
- Tools/products/workflows: Diffusers-compatible plugin for Sol-RL; standardized APIs for seed preservation, ranking interfaces, and multi-precision orchestration
- Assumptions/dependencies: Community adoption; consistent cross-vendor support for low-precision formats and deterministic solvers
- Edge/on-device exploration with cloud regeneration
- Sectors: Mobile/edge, privacy-preserving ML
- Tools/products/workflows: Perform few-step FP4 ranking on-device (future NPUs), send only seed IDs to cloud for BF16 regeneration; privacy-friendly personalization
- Assumptions/dependencies: Future edge hardware with FP4-like arithmetic; bandwidth-efficient seed handoff; privacy and security compliance
- Policy and governance: compute-efficient alignment guidelines and incentives
- Sectors: Public sector, standards bodies, funding agencies
- Tools/products/workflows: Best-practice recommendations to decouple exploration from high-precision training for reduced energy use; procurement criteria that favor low-precision exploration
- Assumptions/dependencies: Measurement standards for energy efficiency and reproducibility; reward-model transparency and auditability
Glossary
- Adjoint method: A technique for computing gradients through differential equations by solving an auxiliary adjoint system to reduce memory usage. "Adjoint Matching~\citep{domingo2024adjoint} applies the adjoint method~\citep{pontryagin2018mathematical} for memory-efficient gradient computation."
- Advantage (in RL): The relative performance measure of an action compared to a baseline, used to reduce gradient variance. "the advantage of the -th sample is obtained by standardizing its reward against the group statistics:"
- Advantage Weighted Matching (AWM): A forward-process diffusion RL method that weights denoising targets by advantages to align with rewards. "Mainstream ``forward-process'' diffusion RL algorithms—especially Advantage Weighted Matching (AWM)~\citep{xue2025advantage}..."
- BF16 precision: A 16-bit floating-point format (bfloat16) that uses 8 exponent bits and 7 mantissa bits, commonly used for training stability with reduced memory. "we regenerate these selected samples in BF16 precision and optimize the policy exclusively on them."
- Blackwell (NVIDIA Blackwell architecture): NVIDIA’s GPU architecture that introduces native low-precision formats (e.g., FP4) for high-throughput compute. "Driven by recent hardware advancements (e.g., NVIDIA Blackwell), 4-bit floating-point (FP4) arithmetic has emerged as a promising acceleration paradigm."
- Block-level micro-scaling: A quantization technique where contiguous groups of values share a scaling factor to preserve dynamic range in low precision. "To maintain numerical fidelity, it employs block-level micro-scaling, where contiguous elements share a single scaling factor."
- CLIPScore: An image-text alignment metric derived from CLIP embeddings to assess semantic consistency. "We utilize ImageReward~\cite{xu2023imagereward}, CLIPScore~\cite{clipscore}, PickScore~\cite{kirstain2023pick}, and HPSv2~\cite{hpsv2} as our primary alignment objectives..."
- Classifier-free guidance (CFG): A technique that trades off between conditional and unconditional generations to steer outputs; often disabled in RL post-training. "All rollouts use deterministic ODE sampling; classifier-free guidance is disabled for SANA and SD3.5..."
- Conditional probability density map: A visualization showing the probability distribution of one variable conditioned on another, used here to compare rank consistency. "Figure~\ref{fig:correlation_c} presents a conditional probability density map comparing the true BF16 ranks against the NVFP4 proxy ranks."
- Critic (value network): A learned model estimating expected returns to reduce variance in policy gradients; avoided in GRPO. "Most modern algorithms, including PPO~\citep{schulman2017proximal}, implement this baseline using a learned value network (critic)."
- Decoupled two-stage reinforcement learning: A training design separating fast, approximate exploration from high-fidelity optimization to balance speed and stability. "Decoupled two-stage reinforcement learning pipeline of Sol-RL."
- Denoising score matching loss: An objective used to train diffusion models by matching the model’s score (gradient of log-density) to the true data score during denoising. "formulate their objectives based on denoising score matching loss, treating the rollout samples as direct regression targets."
- Deterministic ODE-style diffusion sampling: A diffusion sampling approach using ordinary differential equations to produce deterministic trajectories from noise. "under the deterministic nature of ODE-style diffusion sampling"
- Diffusion Reinforcement Learning: The application of RL techniques to guide diffusion models toward desired behaviors or preferences. "FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling"
- Diffusion-DPO: A diffusion-model adaptation of Direct Preference Optimization that aligns generations using preference data without explicit rollouts. "Diffusion-DPO~\citep{wallace2024diffusion} offers a preference-optimization counterpart to this line..."
- E4M3 (floating-point format): A floating-point encoding with 4 exponent and 3 mantissa bits used for scaling factors in NVFP4. "NVIDIA's NVFP4 groups 16 elements under an E4M3 scale."
- E8M0 (floating-point format): A floating-point encoding with 8 exponent and 0 mantissa bits used for scaling factors in MXFP4. "the OCP MXFP4 standard groups 32 elements under an E8M0 scale"
- ELBO (Evidence Lower Bound): A variational objective that lower-bounds the log-likelihood, used as a proxy for policy likelihood in forward-process optimization. "by using the ELBO as a proxy for policy likelihood."
- Euler–Maruyama discretization: A numerical method for approximating stochastic differential equations, used to formulate multi-step diffusion RL. "formulate diffusion RL as a multi-step decision-making problem based on an Euler-Maruyama discretization of the reverse process"
- Extreme Value Theory (EVT): A statistical framework for modeling the behavior of extreme (max/min) values in samples, used to analyze rollout scaling. "through the lens of Extreme Value Theory (EVT)."
- FP4 quantization: A 4-bit floating-point representation enabling high-throughput inference with shared scaling, used to accelerate rollouts. "we explore the integration of FP4 quantization into Diffusion RL rollouts."
- FP8 precision: An 8-bit floating-point format used to balance performance and accuracy in training/inference pipelines. "FP8-RL~\cite{fp8-rl} utilizes importance ratio between quantized inference and BF16 precision training."
- Forward-process (in diffusion RL): Training approach optimizing the forward denoising process directly, often aligning with rewards or preferences. "Mainstream ``forward-process'' diffusion RL algorithms—especially Advantage Weighted Matching (AWM)..."
- Grönwall's inequality: A bound used in differential equations to control the growth of solution deviations over time. "we can apply standard comparison arguments and Gr\"onwall's inequality to bound the final sample deviation:"
- Group Relative Policy Optimization (GRPO): A policy optimization method using group-wise relative rewards to compute advantages without a critic. "Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath} circumvents this by evaluating a group of candidate responses."
- HPSv2: A learned human-preference scoring metric for images, used to evaluate alignment quality. "We utilize ImageReward~\cite{xu2023imagereward}, CLIPScore~\cite{clipscore}, PickScore~\cite{kirstain2023pick}, and HPSv2~\cite{hpsv2}..."
- ImageReward: A reward model trained from human preferences to score text-to-image outputs. "We utilize ImageReward~\cite{xu2023imagereward}..."
- Inception Score (IS): A generative image quality metric measuring image diversity and object recognizability via a classifier. "achieve on-par Inception Score (IS) and CLIP scores across multiple base T2I models"
- Importance ratio: The ratio of probabilities under different policies/distributions used for off-policy correction. "FP8-RL~\cite{fp8-rl} utilizes importance ratio between quantized inference and BF16 precision training."
- Initial noise (seed): The starting noise vector for diffusion sampling that determines the semantic structure of generated images. "Given the same initial noise seed, the accelerated approximations maintain intra-group ranking consistency..."
- Kullback–Leibler (KL) divergence: A measure of divergence between two probability distributions used as a regularizer in policy optimization. "regularizing the policy toward a reference model $\pi_{\text{ref}$ through a direct KL term in the loss"
- Lipschitz continuity: A smoothness property of functions that bounds how fast outputs can change with inputs. "Assuming the vector field is -Lipschitz continuous with respect to "
- LoRA (Low-Rank Adaptation): A parameter-efficient finetuning method that injects low-rank updates into model weights. "We apply Low-Rank Adaptation (LoRA)~\cite{hu2022lora} with a rank of and a scaling factor of ..."
- Low-bit quantization: Representing weights/activations with very few bits to accelerate inference at the cost of numerical precision. "when corrupted by low-bit quantization (e.g., FP4), the numerical noise forces the high-precision policy to mimic distorted, low-fidelity semantics."
- MXFP4: An OCP 4-bit floating-point format used for scaling blocks of values in quantization. "the OCP MXFP4 standard groups 32 elements under an E8M0 scale"
- NVFP4: NVIDIA’s FP4 implementation with specific block scaling enabling high-throughput inference. "we utilize high-throughput NVFP4 rollouts to generate a massive candidate pool"
- ODE solver: A numerical integrator for ordinary differential equations used in deterministic diffusion sampling. "generating samples through a NVFP4 model ODE solver."
- Off-policy gap: The mismatch that arises when optimizing a policy with data generated by a different (e.g., quantized) policy. "A key concern is the off-policy gap: trajectories sampled by quantized policy exhibit an inherent distribution shift from the high-precision target policy"
- PickScore: A human-preference model providing scalar scores for generated images. "We utilize ImageReward, CLIPScore, PickScore, and HPSv2 as our primary alignment objectives..."
- Policy gradient: A class of RL methods that optimize policies by estimating gradients of expected returns. "In the simplest policy gradient formulation, REINFORCE~\citep{williams1992simple} optimizes"
- PPO (Proximal Policy Optimization): A stable policy gradient method using clipped surrogate objectives to constrain updates. "Most modern algorithms, including PPO~\citep{schulman2017proximal}, implement this baseline..."
- Projection function (FP4): The quantization operator mapping high-precision values to their FP4 representations. "where is the shared scaling factor and $\Pi_{\text{FP4}(\cdot)$ denotes the projection function."
- REINFORCE: A Monte Carlo policy gradient algorithm that estimates gradients using sampled returns. "In the simplest policy gradient formulation, REINFORCE~\citep{williams1992simple} optimizes"
- Reward Feedback Learning (ReFL): A paradigm optimizing models by directly maximizing reward signals derived from preference models. "ImageReward~\citep{xu2023imagereward} introduces Reward Feedback Learning (ReFL)..."
- Rollout: The process of generating candidate trajectories or samples from a policy for evaluation and learning. "utilizing high-throughput NVFP4 rollouts to generate a massive candidate pool"
- Rollout scaling: Increasing the number of generated candidates per prompt to strengthen relative comparisons and learning signals. "Within this Diffusion GRPO framework, scaling the rollout size has been shown to yield consistent and appreciable reward improvements"
- SDE (stochastic differential equation): A differential equation with stochastic components; used for diffusion sampling in SDE-based methods. "mixed ODE/SDE sampling~\citep{li2025mixgrpo}"
- Singular Value Decomposition (SVD): A matrix factorization used here to absorb activation outliers for robust low-bit quantization. "SVDQuant~\cite{svdquant} have successfully bridged the gap to 4-bit inference by absorbing activation outliers through Singular Value Decomposition (SVD)."
- Sub-Gaussian distribution: A class of light-tailed distributions bounded in their tail behavior like a Gaussian; used for theoretical bounds. "we model the true oracle rewards of the generated candidates as identically distributed from a sub-Gaussian distribution, ."
- TFLOPs: Tera floating-point operations per second; a measure of compute throughput. "NVFP4 dense operations deliver up to the TFLOPs of standard BF16 arithmetic."
- Truncated backpropagation: A technique to reduce memory usage by backpropagating through limited steps of a long computation graph. "mitigates the resulting memory overhead through truncated backpropagation and gradient checkpointing."
- Vector field: The function defining the time derivative in a differential equation governing diffusion dynamics. "Let the high-precision trajectory satisfy the exact vector field "
- Wasserstein-2 regularization: A regularizer using the 2-Wasserstein distance to stabilize optimization with respect to distribution shifts. "extend this objective to an online setting with Wasserstein-2 regularization."
Collections
Sign up for free to add this paper to one or more collections.

