APRIL: Active Partial Rollouts in Reinforcement Learning to tame long-tail generation
Abstract: Reinforcement learning (RL) has become a cornerstone in advancing large-scale pre-trained LLMs. Successive generations, including GPT-o series, DeepSeek-R1, Kimi-K1.5, Grok 4, and GLM-4.5, have relied on large-scale RL training to enhance reasoning and coding capabilities. To meet the community's growing RL needs, numerous RL frameworks have been proposed. Most of these frameworks primarily rely on inference engines for rollout generation and training engines for policy updates. However, RL training remains computationally expensive, with rollout generation accounting for more than 90% of total runtime. In addition, its efficiency is often constrained by the long-tail distribution of rollout response lengths, where a few lengthy responses stall entire batches, leaving GPUs idle and underutilized. As model and rollout sizes continue to grow, this bottleneck increasingly limits scalability. To address this challenge, we propose Active Partial Rollouts in Reinforcement Learning (APRIL), which mitigates long-tail inefficiency. In the rollout phase, APRIL over-provisions rollout requests, terminates once the target number of responses is reached, and recycles incomplete responses for continuation in future steps. This strategy ensures that no rollouts are discarded while substantially reducing GPU idle time. Experiments show that APRIL improves rollout throughput by at most 44% across commonly used RL algorithms (GRPO, DAPO, GSPO), accelerates convergence, and achieves at most 8% higher final accuracy across tasks. Moreover, APRIL is both framework and hardware agnostic, already integrated into the slime RL framework, and deployable on NVIDIA and AMD GPUs alike. Taken together, this work unifies system-level and algorithmic considerations in proposing APRIL, with the aim of advancing RL training efficiency and inspiring further optimizations in RL systems.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making reinforcement learning (RL) for LLMs faster and more efficient. The authors noticed that training these models with RL wastes a lot of time because some generated answers are much longer than others. Their new method, called APRIL (Active Partial Rollouts in Reinforcement Learning), speeds things up by not waiting for the very longest answers to finish before moving on.
The big questions they asked
- Why is RL training for LLMs so slow, and what’s causing most of the waiting?
- Can we keep training accuracy high while making the rollout (answer generation) part faster?
- Can we design a method that works with different RL algorithms and on different kinds of GPUs (computer chips)?
- Will this method still train models stably and maybe even improve final performance?
How they tried to solve it
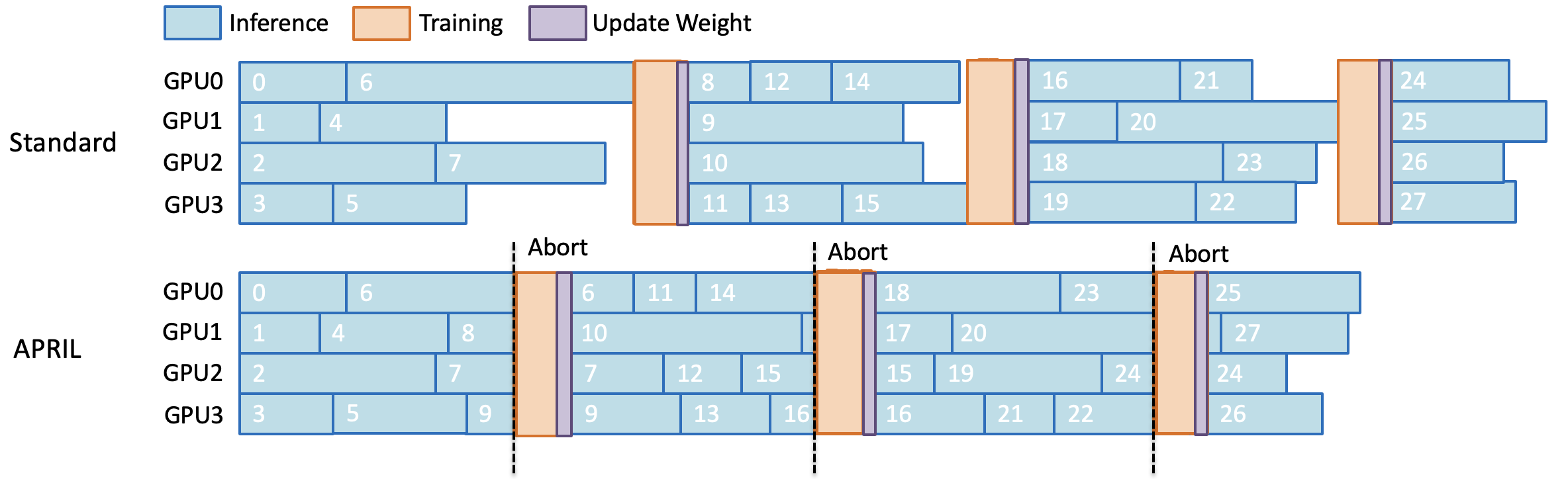
First: what’s the slowdown?
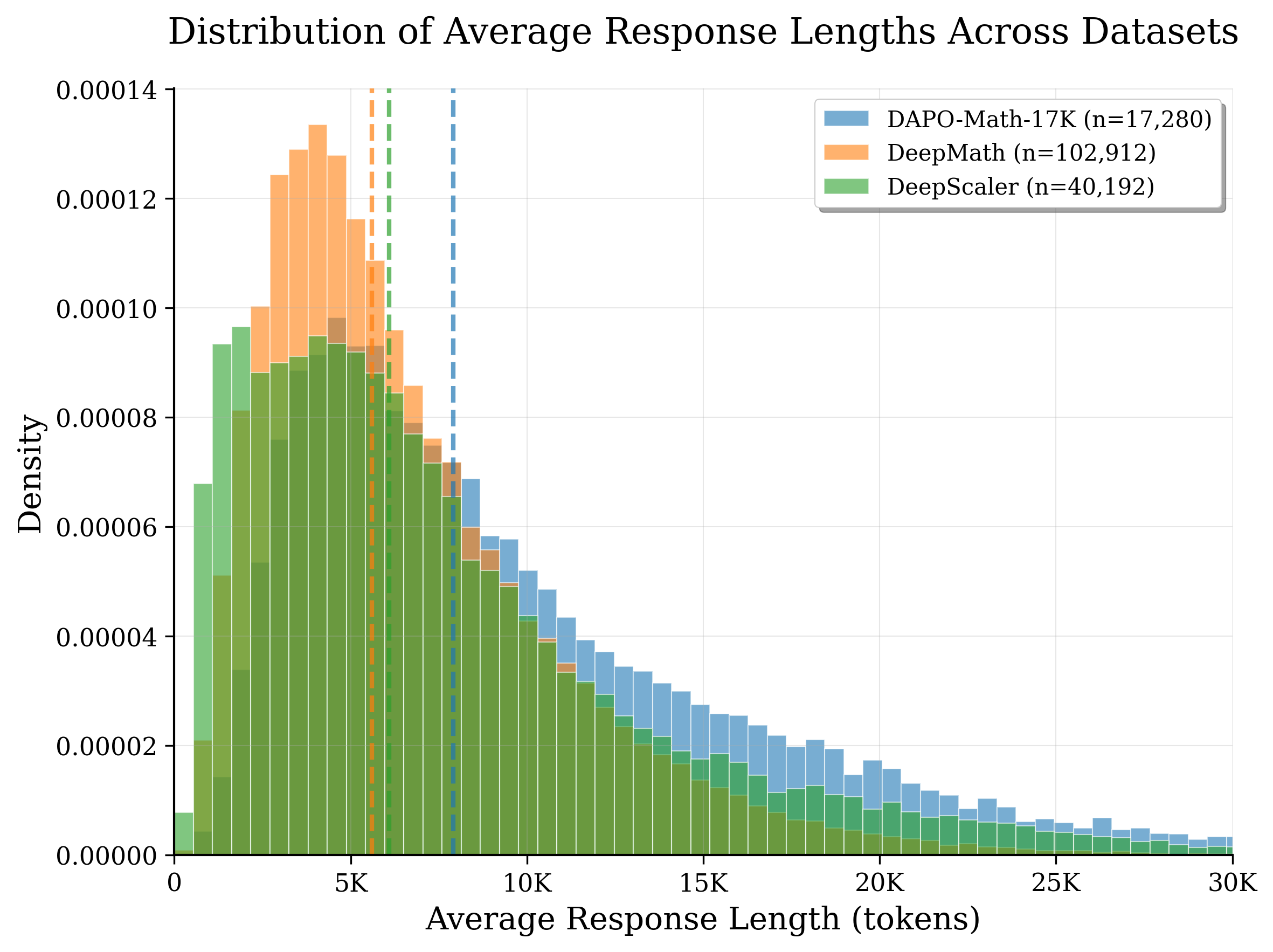
In RL training, the model generates several trial answers (called “rollouts”) for each question or prompt. Imagine a class where students write essays: most finish quickly, but a few write very long essays. If the teacher waits for everyone to finish before grading, the whole class is held up by the slowest few. That’s the “long-tail” problem: a small number of very long responses delay the entire batch, leaving powerful GPUs sitting idle.
What is APRIL?
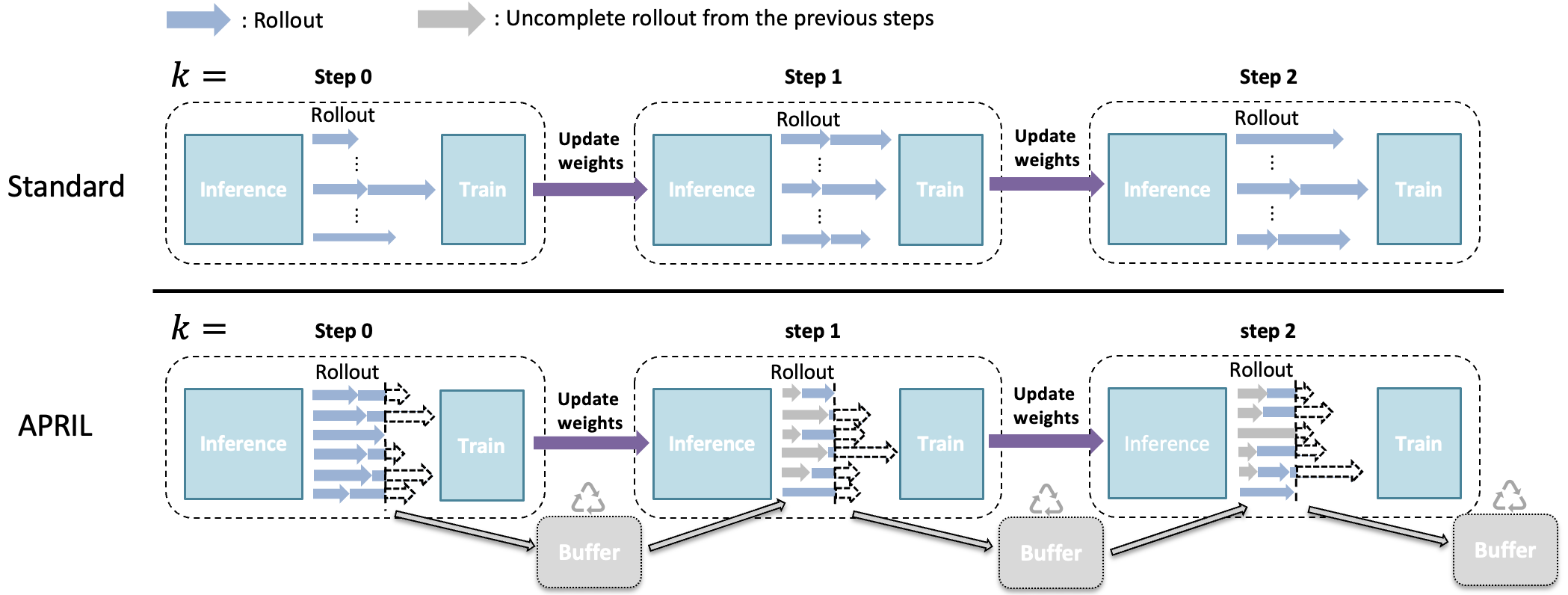
APRIL is like smarter classroom management. Instead of waiting for every single long essay:
- The system starts more rollouts than it actually needs for the current step.
- As soon as it gets enough finished rollouts, it stops the rest (pauses them, not discards).
- The finished rollouts are used immediately to train the model.
- The paused, unfinished rollouts are saved and continued in the next step.
This way, nothing is wasted, and the GPUs spend less time waiting.
Key steps in APRIL
Here’s what APRIL does during each training step:
- Start extra rollouts (more than the usual batch).
- When enough rollouts finish, immediately stop the remaining ones.
- Store the unfinished ones in a buffer (like a “to-be-continued” list).
- In the next step, resume those unfinished rollouts first, before starting new ones.
What about “on-policy” vs “off-policy”?
- “On-policy” means training on data created by the model’s current version.
- By pausing and resuming, a few rollouts may be partly created by slightly older versions of the model (that’s “off-policy”).
- The authors checked whether this would cause problems. They found it didn’t hurt training; in fact, it sometimes helped accuracy and stability.
How did they test it?
They tried APRIL with popular RL methods (GRPO, DAPO, and GSPO) and on different LLMs (like Qwen3-4B and Qwen3-8B). They used math reasoning datasets and measured:
- Throughput: how many tokens per second the system generates (higher is better).
- Accuracy on a tough math benchmark (AIME-2024).
- Training stability and speed of convergence.
- Compatibility across NVIDIA and AMD GPUs.
What did they find?
Here are the main results the authors report:
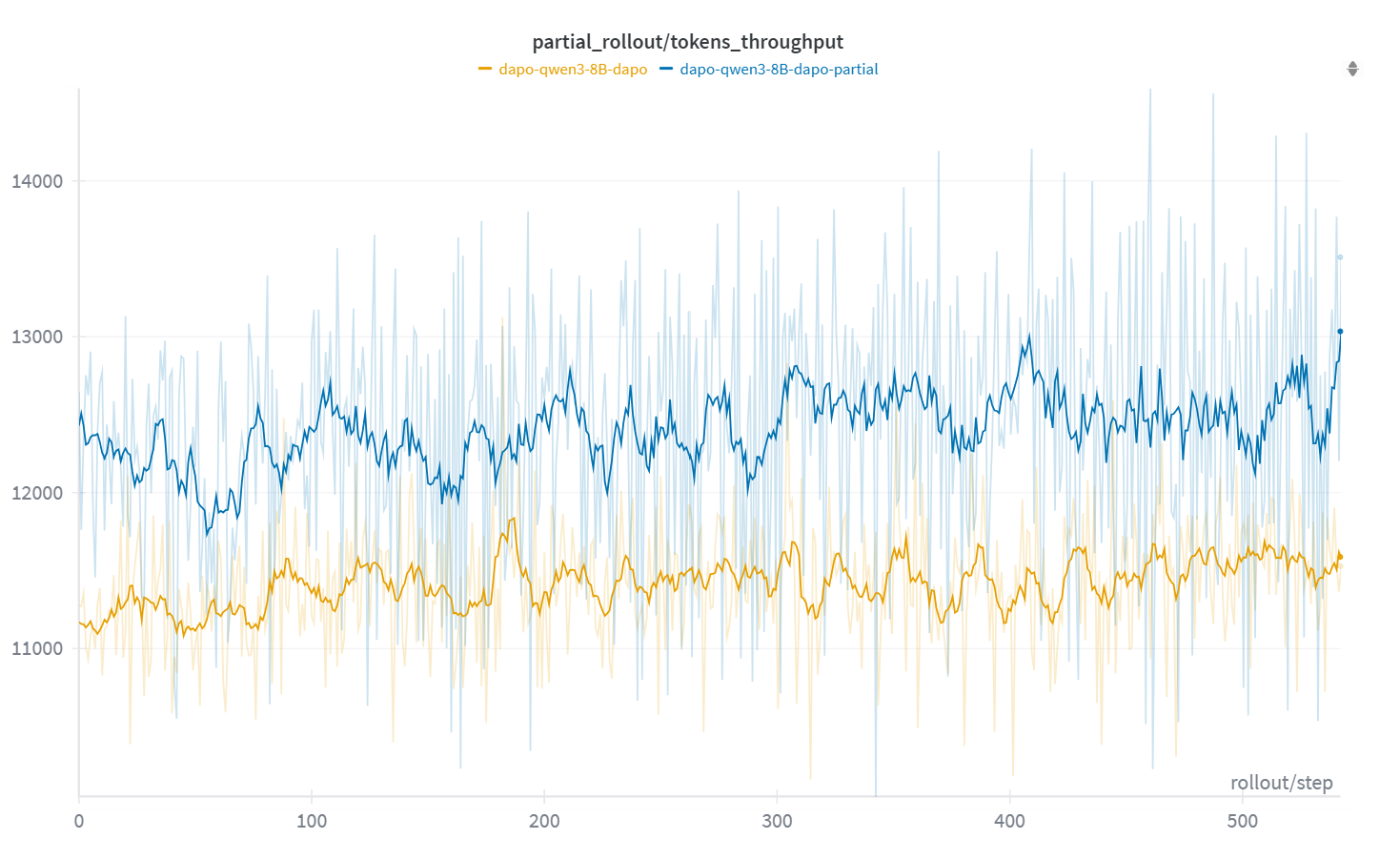
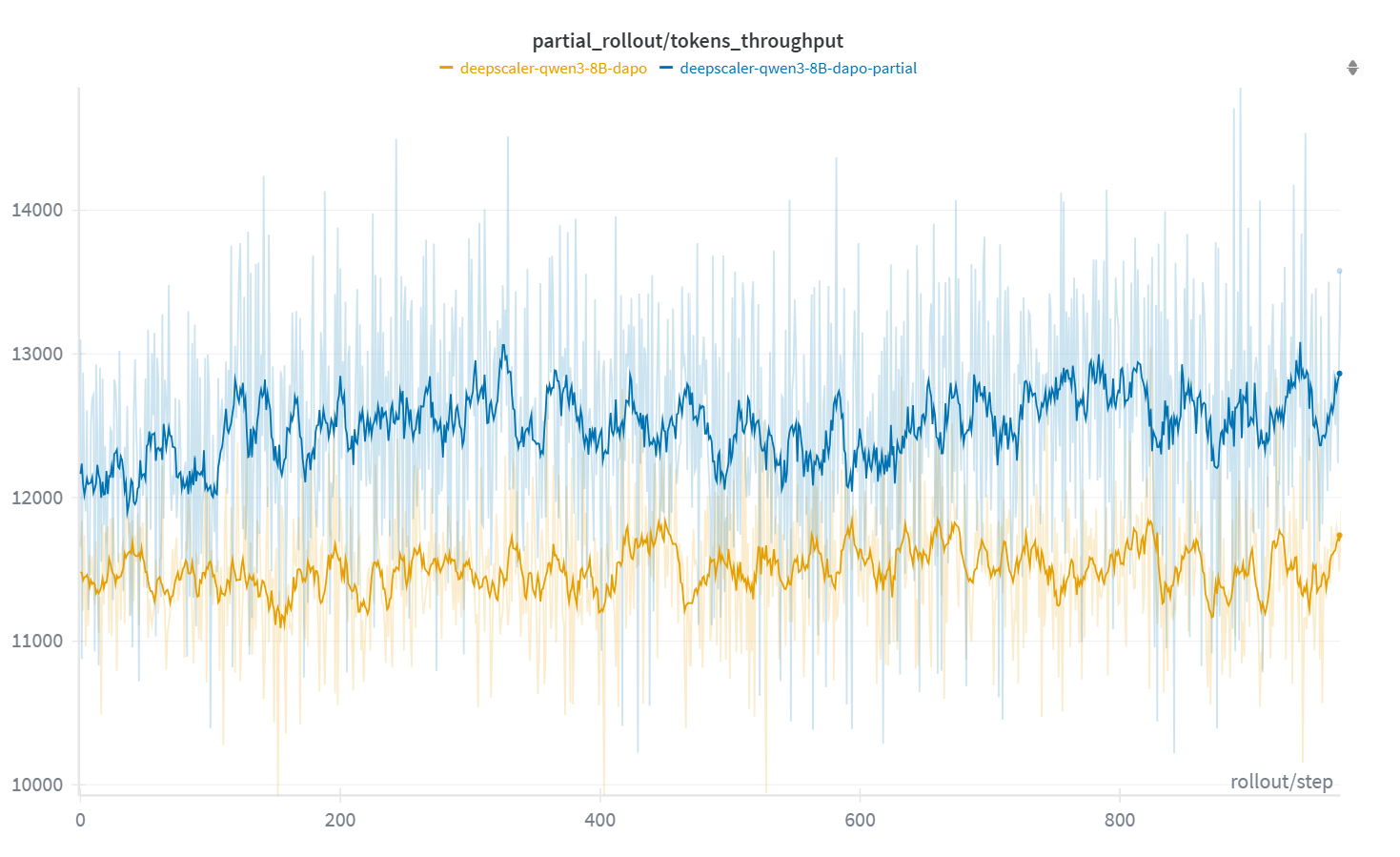
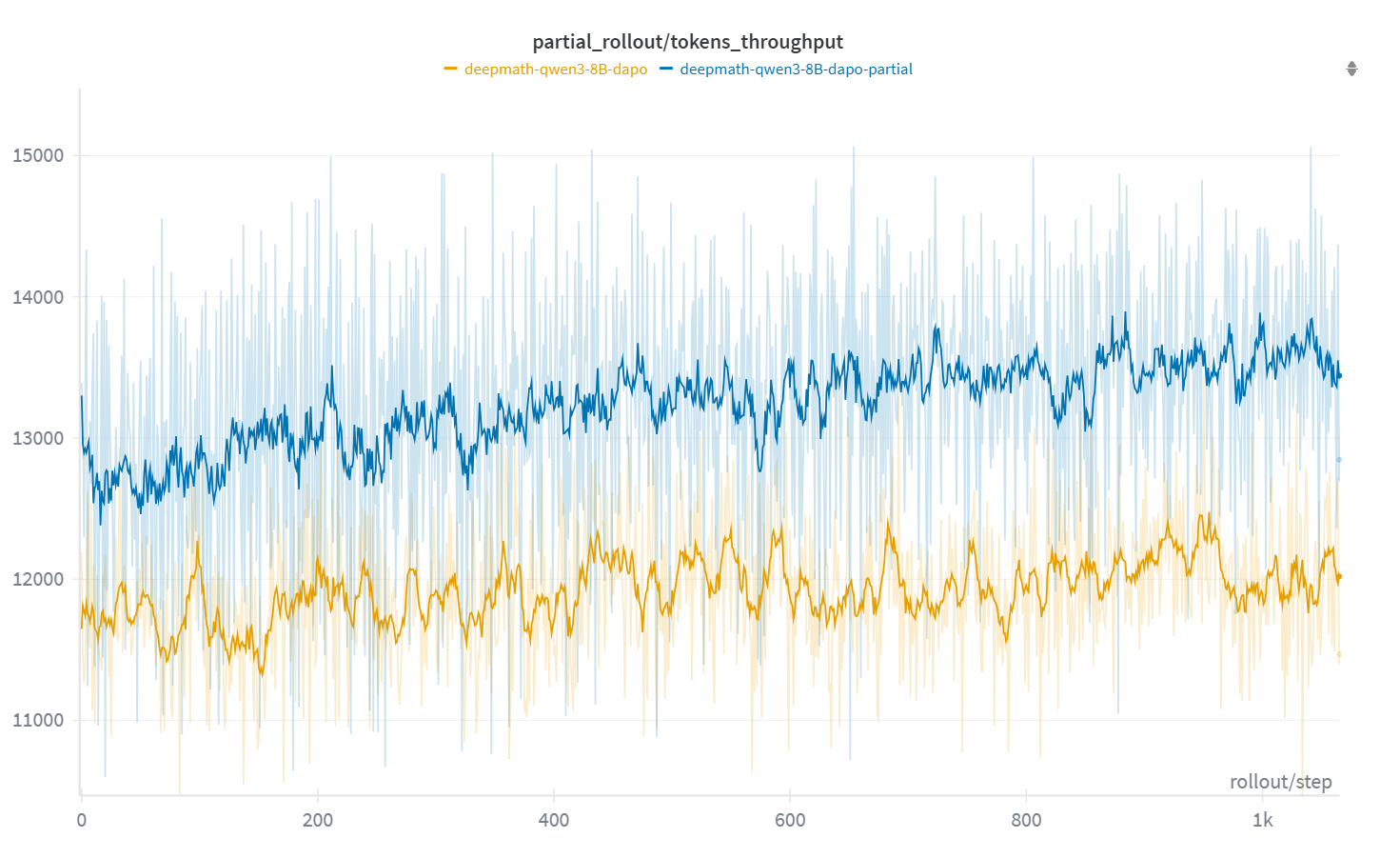
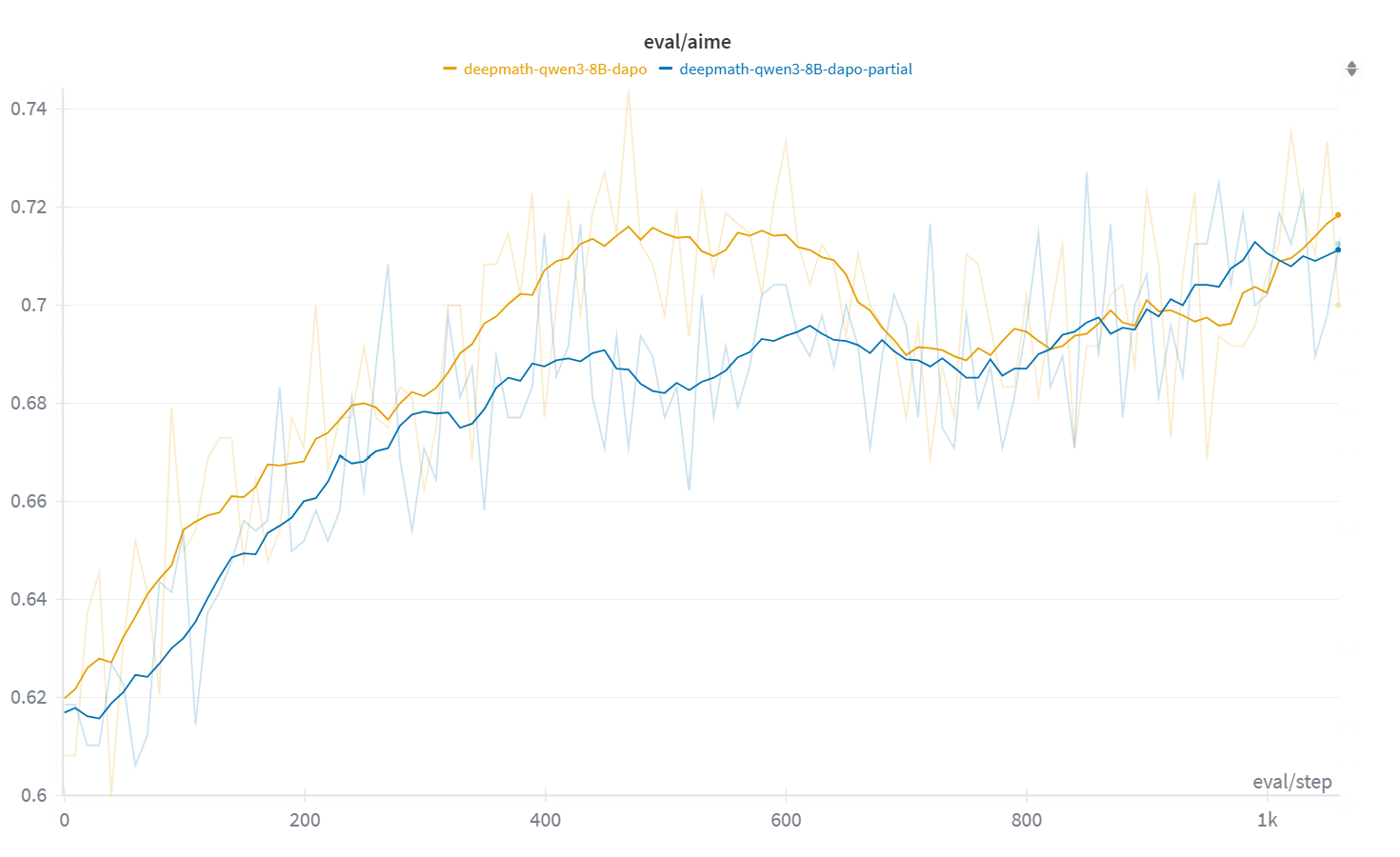
- Faster rollouts: APRIL improved rollout throughput by up to 44% (often 20–35% depending on model and algorithm).
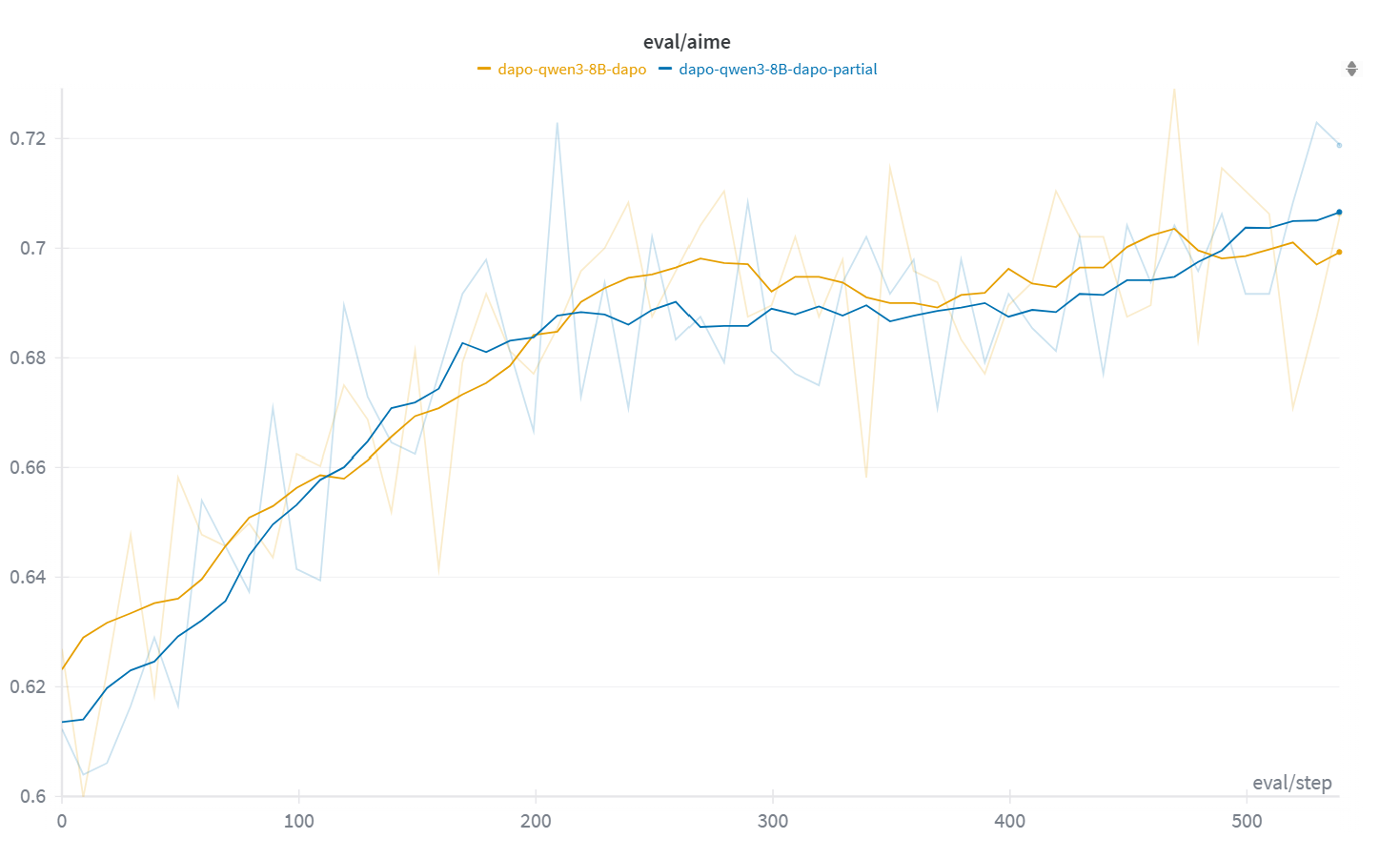
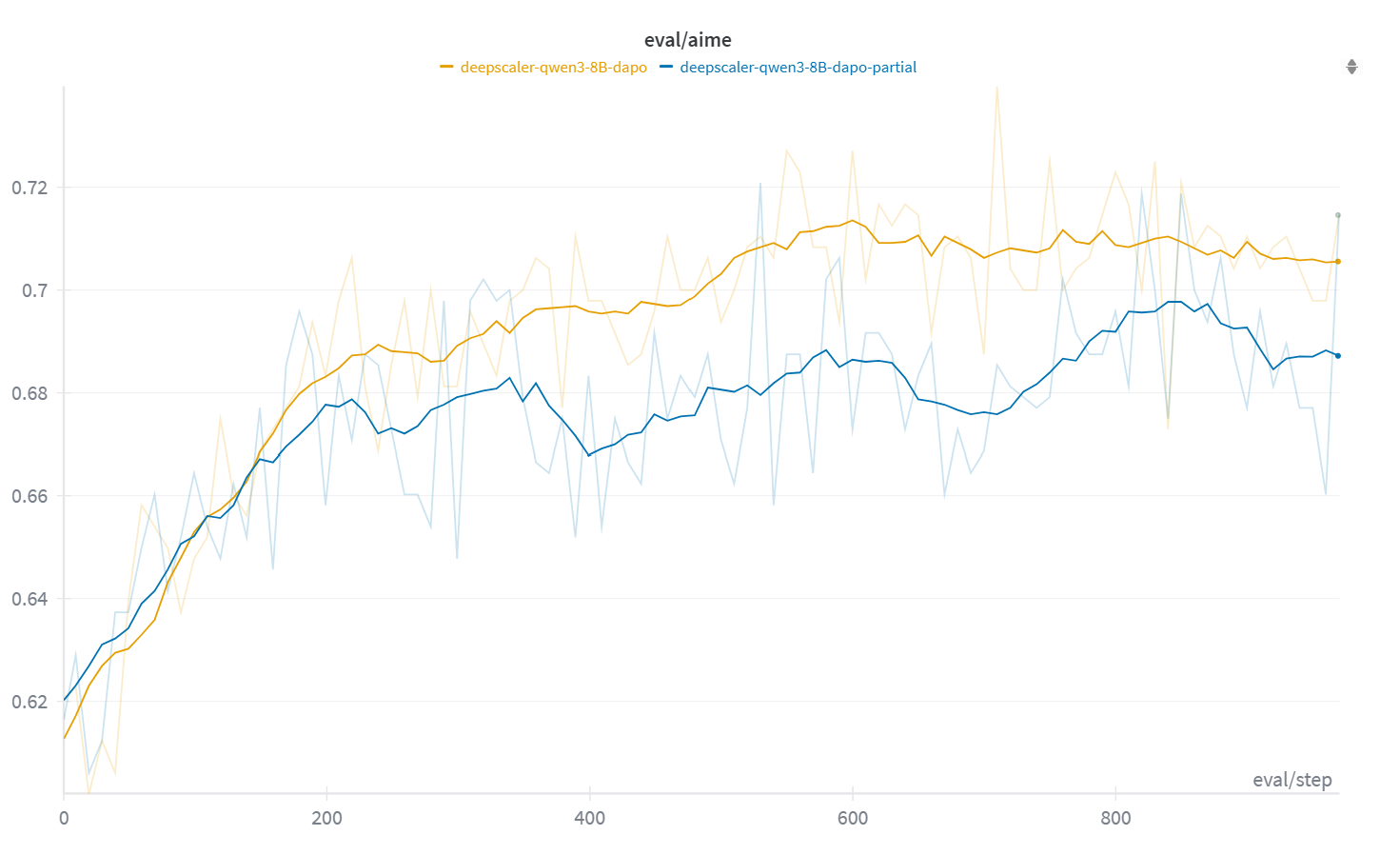
- Equal or better accuracy: Final accuracy often improved by about 2–8%.
- Faster convergence: Models learned faster with APRIL.
- More stable training: APRIL avoided cases where the model suddenly produced super-long answers that break training later on.
- Plug-and-play: APRIL worked across different RL algorithms (GRPO, DAPO, GSPO), different models, and both NVIDIA and AMD GPUs. It’s already integrated into an open-source RL framework called slime.
Why this matters: Since the rollout phase can take over 90% of RL training time, making it faster saves a lot of compute and money while keeping or improving quality.
Why it matters and what it could change
APRIL shows that a simple scheduling idea—start extra, stop when enough finish, and resume the rest later—can make RL training for LLMs much more efficient. This matters because:
- It reduces wasted GPU time during generation.
- It scales better as models and answer lengths grow.
- It keeps training stable and can even improve accuracy.
- It’s easy to adopt across frameworks and hardware.
In short, APRIL helps train smarter models faster and more affordably. That could accelerate progress in areas like reasoning, coding, and other tasks where LLMs need RL to improve.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions that remain unresolved and could guide future work:
- Lack of theoretical analysis of APRIL’s mixed-policy updates: no formal characterization of bias/variance in advantage estimates when trajectories are generated under multiple policy versions, nor conditions under which stability and convergence are guaranteed.
- No off-policy correction mechanisms: APRIL does not employ importance sampling, trust-region bounds, or staleness-aware reweighting; the impact of such corrections on stability and accuracy remains unexplored.
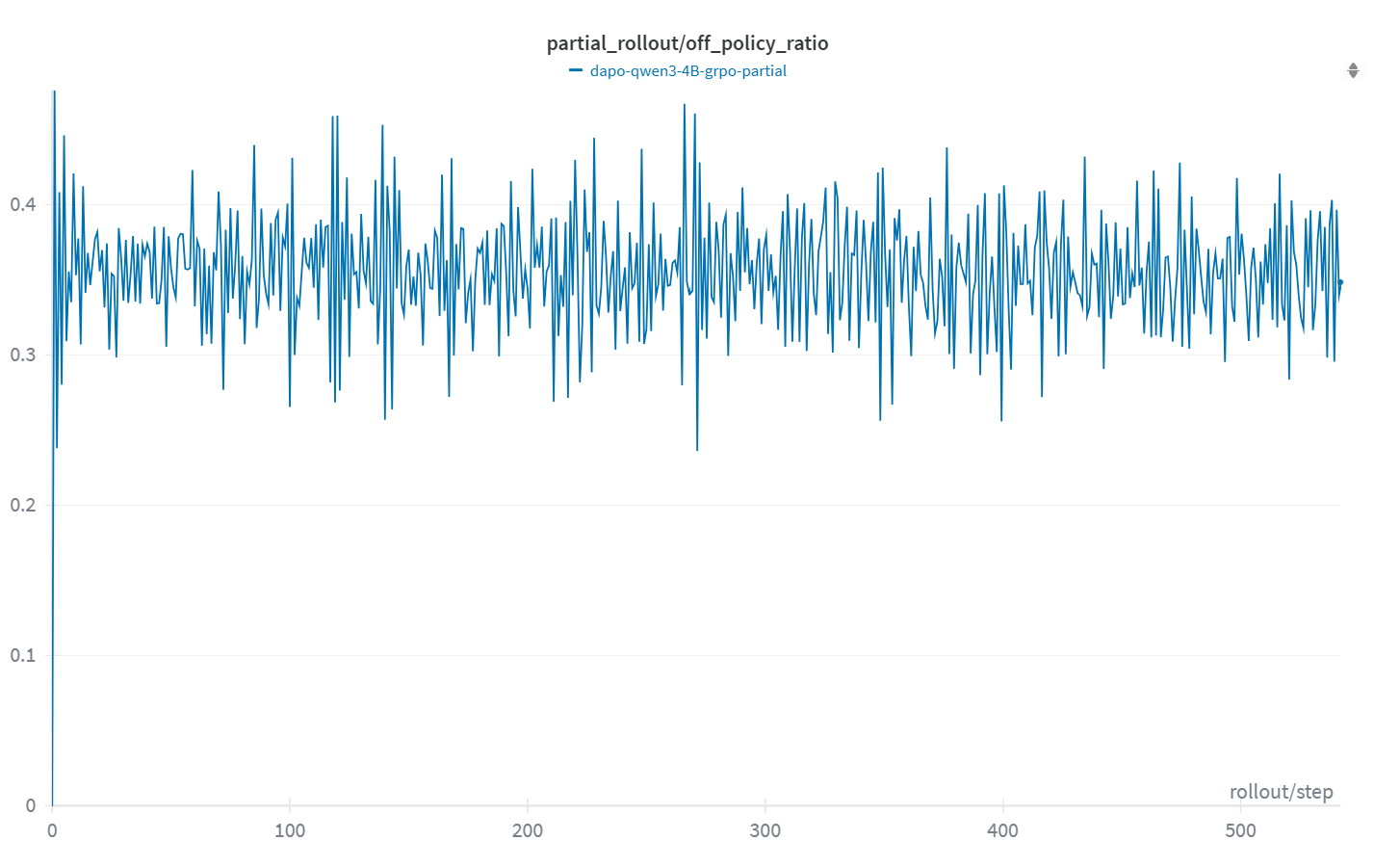
- Unbounded rollout staleness: the proportion of resumed (off-policy) tokens is reported at ~40% but is not controlled; methods to cap, schedule, or adaptively regulate staleness are absent.
- Hyperparameter sensitivity is unstudied: the choice of over_sampling_batch_size (e.g., 2× batch size) lacks ablations and guidance; adaptive policies for selecting N′ across models/datasets are not provided.
- Scheduler design is fixed and simplistic: stopping when N instances finish may waste compute on aborted long sequences; alternative stopping criteria (e.g., token budgets, predicted length-aware scheduling, SortedRL-style policies) are not evaluated.
- Wasted compute from aborted rollouts is unquantified: the paper does not measure how many tokens are discarded per iteration, nor the net efficiency trade-off between gains in throughput and compute waste.
- Buffering/resumption semantics are under-specified: details on RNG state, sampling temperature/top-p consistency, and reproducibility when resuming with a newer policy are not provided.
- Credit assignment for mixed-policy trajectories is unclear: whether log-probs are recomputed under the current policy for the entire sequence or only for resumed segments is not detailed; implications for gradient correctness are unknown.
- No bounds on policy-lag per trajectory: while they “did not encounter” >5 successive policy versions, the distribution of policy versions per trajectory and worst-case behavior under long contexts are unmeasured.
- Interaction with inference-level optimizations is untested: synergy or interference with continuous batching, speculative decoding, KV-cache reuse, and batching kernels in vLLM/SGLang is not empirically evaluated.
- End-to-end training speed and cost are not reported: improvements are shown for rollout throughput, but wall-clock time-to-target accuracy, energy consumption, and cost-per-accuracy are not measured.
- Limited algorithmic coverage: experiments cover GRPO and DAPO; applicability to standard PPO with reward/value networks, KL regularization regimes, and other RLHF variants (e.g., GSPO beyond mention) is unverified.
- Narrow task/domain scope: results are limited to mathematical reasoning datasets; generalization to coding, dialogue/alignment, tool-use, agentic tasks, and long-context generation remains open.
- Limited model scale and hardware topology: evaluations use 4B/8B models on a single node; scaling to >70B models, multi-node clusters, heterogeneous interconnects, and distributed inference/training paradigms is unexplored.
- Lack of comparison to asynchronous RL baselines: the claimed middle ground is not benchmarked against AReaL/AsyncFlow/StreamRL-style systems; trade-offs in stability vs. utilization vs. accuracy remain unquantified.
- Instance-level group completion trade-offs are not measured: waiting for all n_samples per prompt to finish may introduce per-instance delays; the impact of group size on throughput, stability, and accuracy is not analyzed.
- Robustness across seeds and statistical significance are missing: accuracy gains (2–8%) are reported without multiple-seed runs, confidence intervals, or hypothesis tests; potential regression risks are unassessed.
- Evaluation breadth is limited: reliance on AIME-2024 only; broader benchmarks (e.g., GSM8K, MATH, HumanEval, Codeforces, BIG-bench) would clarify generalizability.
- Fairness and starvation in scheduling are unaddressed: repeatedly long sequences may be aborted multiple times; aging or prioritization policies to prevent starvation and ensure fairness are not discussed.
- Memory/KV-cache implications of abort/resume are not measured: potential fragmentation, cache invalidation costs, and memory pressure under different inference backends (vLLM/SGLang) and GPU stacks (CUDA/ROCm) are unknown.
- Safety and alignment effects are unstudied: how mixed-policy rollouts affect reward hacking, harmful content, or alignment metrics is not evaluated.
- Practical guidance is missing: no recipes for selecting N′, capping staleness, combining APRIL with inference accelerators, or adapting to specific task length distributions are provided.
Practical Applications
Immediate Applications
The following applications can be deployed now using the APRIL method and its open-source implementation, with clear ties to sectors, tools, and workflows.
- RLHF and reasoning LLM training efficiency upgrades (Software/AI)
- Use case: Drop-in acceleration of rollout generation in synchronous RL training pipelines (GRPO, DAPO, GSPO) for instruction-following, math reasoning, and coding models.
- Tools/products/workflows: Integrate APRIL in slime; connect to vLLM or SGLang for inference; orchestrate with Ray; use FSDP or Megatron-LM for training; enable oversampling + early termination + buffered continuation at the rollout stage.
- Impact: 20–44% throughput improvement, faster convergence, up to ~8% higher final accuracy, reduced GPU idle time.
- Assumptions/dependencies: Long-tail response length is present; inference backend supports preemption/abort and continuation; reward function and policy update tolerate mildly mixed-policy rollouts; adequate memory/KV-cache handling.
- Cloud cost and energy reduction for RL training (Cloud/AI Infrastructure/Energy)
- Use case: Lower total training runtime and energy consumption for RL phases in large LLM training on NVIDIA or AMD clusters.
- Tools/products/workflows: APRIL-enabled rollout schedulers; GPU/cluster utilization dashboards; tokens-per-second SLAs; energy/carbon monitoring attached to RL steps.
- Impact: Reduced compute-hours per experiment; improved utilization; lower carbon footprint per training run.
- Assumptions/dependencies: Stable cluster networking; inference engines accept abort/resume; accurate utilization and energy telemetry.
- Hardware diversification without performance penalty (Semiconductor/HPC)
- Use case: Port RL pipelines to AMD MI300, maintain comparable speedups to NVIDIA H100/H200; hedge vendor risk and expand capacity.
- Tools/products/workflows: APRIL in slime with ROCm/HIP support; adapted memory management (e.g., torch_memory_saver patches) for synchronous RL.
- Impact: Broader hardware coverage; competitive throughput gains across vendors.
- Assumptions/dependencies: ROCm-compatible inference/training stacks; validated abort/resume semantics on target hardware.
- Length-aware scheduling within synchronous RL frameworks (Software/AI)
- Use case: Enable “APRIL mode” in OpenRLHF, verl, and similar frameworks to mitigate batch stalls from long-tail rollouts.
- Tools/products/workflows: Framework plugin/module exposing oversampling ratio, abort threshold, continuation buffer, and instance-level group completion.
- Impact: Higher throughput with minimal code changes; improved training stability by avoiding pathological long generations late in training.
- Assumptions/dependencies: Compatibility with framework’s batching and reward computation; instance grouping supported (n_samples_per_prompt).
- Budget-friendly RL for academic labs and small startups (Academia/Startups)
- Use case: Run more RL experiments under limited budgets; reproduce results faster; expand hyperparameter sweeps and ablations.
- Tools/products/workflows: APRIL-enabled slime on single-node clusters; preconfigured recipes for GRPO/DAPO/GSPO with Qwen-family models; standardized throughput and accuracy tracking.
- Impact: Shorter wall-clock times per experiment; more robust training curves; accessible large-scale RL for non-hyperscalers.
- Assumptions/dependencies: Availability of open datasets and reward functions; moderate engineering effort to enable preemption and buffering.
- MLOps observability and autoscaling for RL rollouts (Software/DevOps)
- Use case: Monitor rollout length distributions; dynamically tune oversampling ratios; autoscale inference workers to minimize idle bubbles.
- Tools/products/workflows: Telemetry for batch-level/instance-level length variance; controllers that adjust APRIL parameters during training; alerting on tail explosions.
- Impact: Stable throughput over time; mitigation of late-stage training instability; proactive resource management.
- Assumptions/dependencies: Reliable metrics capture; safe runtime parameter tuning; minimal disruption to PPO-derived algorithms.
- Faster model iteration cycles for product teams (Software/Enterprise AI)
- Use case: Shorten release cadence for RL-enhanced features (e.g., reasoning or coding assistants) by cutting RL training time.
- Tools/products/workflows: APRIL-enabled RLHF pipelines in CI/CD; gated evaluation (AIME-like benchmarks) tied to tokens/sec targets.
- Impact: Quicker experimentation-to-deployment; potential cost savings passed to customers.
- Assumptions/dependencies: CI/CD integration for RL stages; consistent evaluation suites; model governance compliance.
Long-Term Applications
The following applications require further research, scaling, or ecosystem development before broad deployment.
- Hybrid synchronous–asynchronous RL with APRIL-style preemptive continuation (Software/AI Systems)
- Use case: Build streaming RL frameworks that combine APRIL’s partial rollouts with decoupled inference/training to maximize utilization while managing staleness.
- Tools/products/workflows: Shared rollout buffers with prioritized resumption; staleness-aware sampling; cross-cluster orchestration.
- Dependencies/assumptions: Robust off-policy corrections (importance sampling, KL regularizers); stability under higher staleness; advanced buffer management.
- Formal mixed-policy advantage estimation and off-policy corrections (Academia/Algorithms)
- Use case: Theorize and empirically validate advantage estimators for trajectories spanning multiple policy versions; quantify stability/accuracy trade-offs.
- Tools/products/workflows: New PPO variants with principled weighting; staleness metrics; benchmark suites across tasks with heavy long-tail behavior.
- Dependencies/assumptions: Access to diverse datasets; reproducible training pipelines; agreement on evaluation standards.
- RL-aware inference backends combining APRIL with speculative decoding/continuous batching (Software/Systems)
- Use case: End-to-end rollout engines that unify fast token generation (speculative/continuous batching) with preemptive scheduling and continuation buffers.
- Tools/products/workflows: vLLM/SGLang extensions exposing abort/resume APIs; KV-cache persistence and partial sequence integrity guarantees.
- Dependencies/assumptions: Engine support for fine-grained preemption; correctness guarantees for resumed sequences; careful latency/throughput trade-offs.
- Carbon-aware APRIL scheduling and compute governance (Policy/Energy/Cloud)
- Use case: Introduce guidelines and tools for energy-efficient RL training (e.g., tail mitigation as a best practice), with carbon accounting tied to rollout inefficiency.
- Tools/products/workflows: Policy templates for AI sustainability; procurement standards that favor efficiency-optimized RL systems; carbon reporting integrated into MLOps.
- Dependencies/assumptions: Standardized metrics (tokens/kWh, idle ratio); data center telemetry; regulator acceptance and industry buy-in.
- Extension beyond LLMs to other sequence-generating RL domains (Robotics/Autonomous Systems/Multimodal AI)
- Use case: Apply partial-rollout preemption to long-horizon robotics policies, speech/text-to-action sequences, and multi-agent systems with variable episode lengths.
- Tools/products/workflows: Domain-specific continuation buffers; episode resumption semantics; reward shaping aligned with partial trajectories.
- Dependencies/assumptions: Safe resumption in simulation/real-world control; task-appropriate off-policy handling; measurable tail distributions.
- Cloud “APRIL-as-a-Service” and marketplace integrations (Cloud/Platforms)
- Use case: Managed rollout schedulers offered by cloud providers to accelerate RL training; “preemptible rollout” SKUs with SLAs.
- Tools/products/workflows: Platform APIs for abort/resume; configurable oversampling; billing tied to token-throughput improvements.
- Dependencies/assumptions: Provider support across GPU types; clear pricing and performance guarantees; security/isolation for buffered states.
- Tail-aware curriculum and policy regularization (Academia/Software)
- Use case: Curriculum that adapts max lengths and sampling strategies to tame tails; regularizers to prevent pathological long generations late in training.
- Tools/products/workflows: Length-aware sampling; per-instance group control; automated detection and mitigation of tail explosions.
- Dependencies/assumptions: Reliable detection of tail events; alignment with reward functions; minimal penalty to exploration/diversity.
- Standardization of RL efficiency metrics for benchmarking and governance (Policy/Community)
- Use case: Community benchmarks reporting tokens/sec, idle ratios, staleness %, and energy per step; used for funding, procurement, and publication standards.
- Tools/products/workflows: Open dashboards; shared telemetry schemas; leaderboards that weigh efficiency alongside accuracy.
- Dependencies/assumptions: Broad community participation; comparability across frameworks/hardware; trustworthy measurement practices.
- Enterprise-grade reliability and security for preemptible rollouts (Enterprise/Compliance)
- Use case: Hardened implementations with memory safety, isolation, and compliance controls for partial rollouts and buffered continuations.
- Tools/products/workflows: Secure buffer stores; deterministic resumption; audit logging of abort/resume events.
- Dependencies/assumptions: Robust engineering; adherence to data governance; formal verification/testing in regulated environments.
Glossary
- A3C (Asynchronous Advantage Actor-Critic): A distributed RL algorithm where multiple asynchronous actor-learners update a shared policy to improve sample efficiency and speed. Example: "Asynchronous Advantage Actor-Critic (A3C) \citep{mnih2016asynchronousmethodsdeepreinforcement} and IMPALA \citep{espeholt2018impalascalabledistributeddeeprl}, which pioneered similar disaggregated designs."
- AIME-2024 benchmark: A math reasoning evaluation set used to assess LLM performance on challenging problems. Example: "To evaluate the final performance, we use the AIME-2024 benchmark\footnote{\url{http://huggingface.co/datasets/HuggingFaceH4/aime_2024}, a collection of recent challenging math reasoning problems."
- Active Partial Rollouts (APRIL): A rollout scheduling mechanism that over-provisions, preemptively stops long generations, and resumes them later to reduce idle time without discarding data. Example: "we propose Active Partial Rollouts in Reinforcement Learning (APRIL), which mitigates long-tail inefficiency."
- Advantage function: In policy-gradient RL, the relative value of an action compared to a baseline, guiding gradient updates. Example: "Implications for the Advantage Function."
- Asynchronous RL: An RL paradigm that decouples rollout generation and training across resources to improve utilization, often using off-policy data. Example: "Asynchronous RL"
- Auto-regressive: A token-by-token generation process where each output depends on previously generated tokens. Example: "in an auto-regressive manner"
- Continuous batching: An inference scheduling technique that dynamically adds/removes requests within a batch to minimize idling and maximize GPU utilization. Example: "proposed continuous batching to address the inefficiency of the traditional static batching"
- DAPO: An on-policy RL algorithm variant for LLMs that optimizes policies using a direct advantage objective. Example: "APRIL improves rollout throughput by at most 44\% across commonly used RL algorithms (GRPO, DAPO, GSPO)"
- FSDP: Fully Sharded Data Parallel; a distributed training method that shards model states across devices to reduce memory and scale training. Example: "FSDP~\citep{zhao2023pytorchfsdp} or Megatron-LM~\citep{shoeybi2019megatron} as training backends"
- GRPO (Group Relative Policy Optimization): An on-policy RL method that replaces value networks with group-based baselines from multiple responses. Example: "Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmathpushinglimitsmathematical, mroueh2025grpo} was introduced"
- GSPO (Group Sequence Policy Optimization): An on-policy RL variant optimizing policies over groups of sequences to improve learning efficiency. Example: "APRIL improves rollout throughput by at most 44\% across commonly used RL algorithms (GRPO, DAPO, GSPO)"
- Hybrid-policy rollouts: Trajectories generated by a mixture of policy versions due to partial continuation across steps. Example: "Proportion of hybrid-policy rollouts in each RL training step."
- IMPALA: A scalable distributed off-policy RL algorithm using V-trace corrections to stabilize learning from asynchronous actors. Example: "Asynchronous Advantage Actor-Critic (A3C) \citep{mnih2016asynchronousmethodsdeepreinforcement} and IMPALA \citep{espeholt2018impalascalabledistributeddeeprl}, which pioneered similar disaggregated designs."
- Importance sampling: A correction technique for off-policy learning that reweights samples from a behavior policy to the target policy. Example: "policy shaping via regularized importance sampling to prevent superficial imitation and encourage sustained exploration throughout training."
- Long-tail distribution: A skewed distribution where a small fraction of very long generations dominates runtime and stalls batches. Example: "its efficiency is often constrained by the long-tail distribution of rollout response lengths"
- Megatron-LM: A large-scale model parallel training framework for transformer LLMs. Example: "FSDP~\citep{zhao2023pytorchfsdp} or Megatron-LM~\citep{shoeybi2019megatron} as training backends"
- Off-policy: Learning from data generated by an older or different policy than the one being updated. Example: "Do the slightly partial off-policy rollouts in APRIL affect convergence and accuracy?"
- On-policy: Learning exclusively from data generated by the current policy being optimized. Example: "fundamental performance bottleneck in scaling on-policy RL training"
- Proximal Policy Optimization (PPO): A stable on-policy policy-gradient algorithm using clipped objectives or KL penalties to limit policy updates. Example: "Proximal Policy Optimization (PPO) stands as a cornerstone in RL training for LLMs"
- Ray: A distributed computing framework used to orchestrate parallel inference and training workloads. Example: "Ray~\citep{moritz2018raydistributedframeworkemerging} for orchestrating parallel training and inference"
- REINFORCE: A foundational Monte Carlo policy-gradient method that updates parameters by weighting log-probability gradients with returns. Example: "we adopt the REINFORCE algorithm~\citep{williams1992simple} as a general formulation"
- Reward model: A learned function that scores generated responses to guide RL training when explicit rewards are unavailable. Example: "It's worth noting that could be a learned reward model, as in PPO~\citep{schulman2017ppo}"
- Rollout: A generated trajectory (e.g., model response) sampled from a policy to estimate rewards and gradients in RL. Example: "rollout generation accounting for more than 90\% of total runtime."
- Score function: The gradient of the log-likelihood of an action under the policy, used in policy-gradient estimators. Example: "The gradient term is the score function"
- SGLang: An inference backend optimized for efficient structured generation and serving of LLMs. Example: "employing vLLM~\citep{10.1145/360(0006.36131)65} or SGLang~\citep{zheng2024sglangefficientexecutionstructured} as inference backends"
- Speculative decoding: An inference acceleration method using a fast draft model to propose tokens that the large model verifies, reducing latency. Example: "speculative decoding \citep{leviathan2023fastinferencetransformersspeculative, chen2023acceleratinglargelanguagemodel, 10.5555/3737916.3738438, chen2025spinacceleratinglargelanguage} has emerged as a powerful optimization."
- Synchronous RL: A training paradigm where all rollouts for a batch complete before a single synchronized policy update, emphasizing on-policy data. Example: "The mainstream paradigm in reinforcement learning (RL) systems is synchronous RL,"
- vLLM: A high-throughput LLM serving engine providing efficient inference for generation workloads. Example: "employing vLLM~\citep{10.1145/360(0006.36131)65} or SGLang~\citep{zheng2024sglangefficientexecutionstructured} as inference backends"
- Value network: A model estimating expected returns to reduce variance in policy-gradient methods; sometimes removed via group baselines. Example: "eliminates the need for an explicit value network"
Collections
Sign up for free to add this paper to one or more collections.

