QeRL: Beyond Efficiency -- Quantization-enhanced Reinforcement Learning for LLMs
Abstract: We propose QeRL, a Quantization-enhanced Reinforcement Learning framework for LLMs. While RL is essential for LLMs' reasoning capabilities, it is resource-intensive, requiring substantial GPU memory and long rollout durations. QeRL addresses these issues by combining NVFP4 quantization with Low-Rank Adaptation (LoRA), accelerating rollout phase of RL while reducing memory overhead. Beyond efficiency, our findings show that quantization noise increases policy entropy, enhancing exploration, and enabling the discovery of better strategies during RL. To further optimize exploration, QeRL introduces an Adaptive Quantization Noise (AQN) mechanism, which dynamically adjusts noise during training. Experiments demonstrate that QeRL delivers over 1.5 times speedup in the rollout phase. Moreover, this is the first framework to enable RL training of a 32B LLM on a single H100 80GB GPU, while delivering overall speedups for RL training. It also achieves faster reward growth and higher final accuracy than 16-bit LoRA and QLoRA, while matching the performance of full-parameter fine-tuning on mathematical benchmarks such as GSM8K (90.8%) and MATH 500 (77.4%) in the 7B model. These results establish QeRL as an efficient and effective framework for RL training in LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “QeRL: Beyond Efficiency — Quantization‑enhanced Reinforcement Learning for LLMs”
1. What is this paper about?
This paper introduces QeRL, a way to train LLMs to reason better using reinforcement learning (RL) while using less memory and running faster. It also makes a surprising point: a careful kind of “noise” created when you compress a model can actually help the model explore more options and learn better strategies during RL.
2. What questions did the researchers ask?
They wanted to solve two problems:
- How can we make RL training for big LLMs faster and use less memory, especially during the rollout phase (when the model generates many possible answers to score)?
- Can the “noise” from compressing model weights be turned into a helpful tool that encourages the model to explore more and discover better solutions?
3. How did they do it?
Think of training an LLM like teaching a student to solve math problems by trying ideas, checking answers, and improving over time (that’s RL). This is powerful but slow and memory-hungry. QeRL speeds it up with three main building blocks:
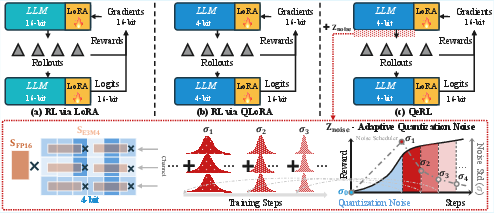
- Quantization (NVFP4): This is like compressing a high-resolution photo into a smaller file so it loads faster. The authors use a 4-bit format called NVFP4, which NVIDIA’s GPUs are designed to run quickly. It shrinks the model’s memory and speeds up generating long reasoning steps (the rollout).
- LoRA: Instead of changing all the model’s parameters, LoRA adds small “adapters” that are cheaper to train. Picture adding a small dial to adjust behavior rather than rebuilding the whole engine.
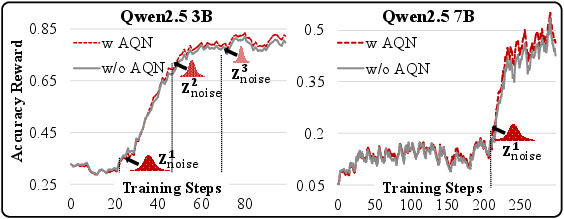
- Adaptive Quantization Noise (AQN): Compression adds tiny fuzz (noise) to the model’s numbers. Surprisingly, in RL this fuzz can be helpful: it increases “entropy,” which means the model is less certain and tries more different words or actions. AQN carefully controls how much noise is added over time—more at the start to explore, less later to focus and improve. They implement this without adding extra parameters by merging the noise into the model’s normalization layers (a standard part called LayerNorm/RMSNorm).
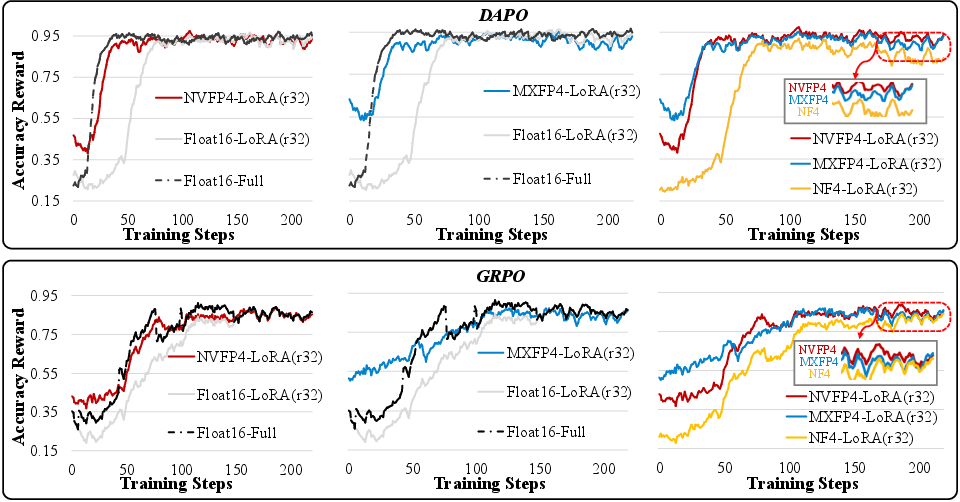
They train with RL methods like GRPO and DAPO. In simple terms, these methods:
- Generate multiple answers to a question.
- Score them with rules (like whether the math result is correct).
- Update the model to prefer better answers, while keeping it from changing too wildly.
4. What did they find?
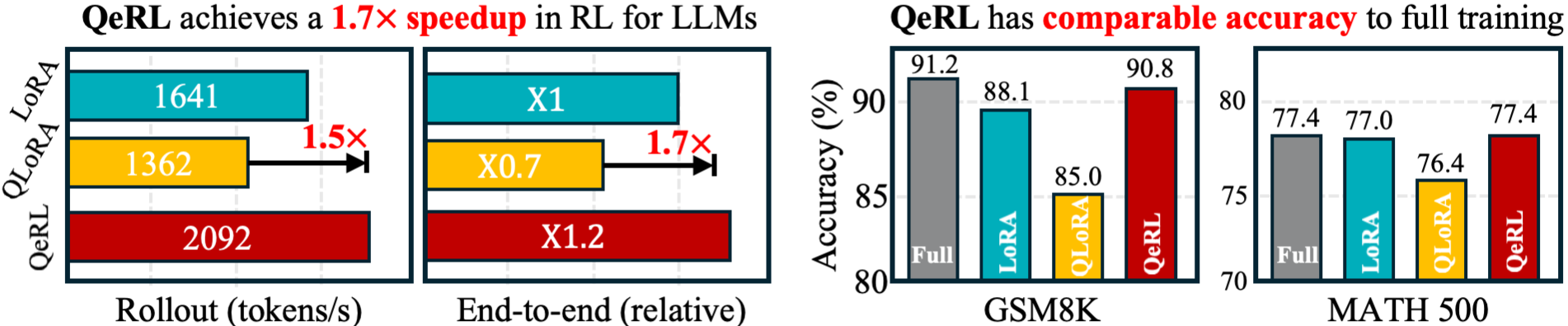
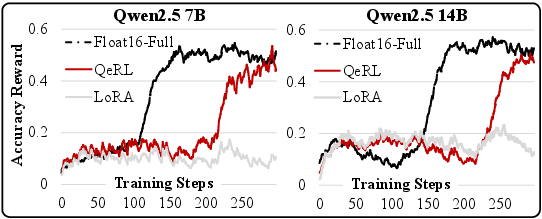
- Faster training: QeRL cut the time of the rollout phase by over 1.5× and sped up overall RL training by about 1.2–1.5× compared to standard methods, especially when generating long answers.
- Lower memory: By using 4-bit weights, big models used only about 25–30% of the memory of their 16-bit versions.
- Better or equal accuracy: On math benchmarks:
- A 7B model reached 90.8% on GSM8K and 77.4% on MATH 500—matching full fine-tuning and beating common efficient methods like 16-bit LoRA and QLoRA.
- Across other tests (AIME, AMC, BigMath), QeRL consistently matched or surpassed 16-bit LoRA.
- Trains very large models: They showed the first RL training of a 32B LLM on a single H100 80GB GPU.
- Why the noise helps: The quantization noise made the model’s choice distribution “flatter” (higher entropy), so it explored more possibilities and avoided getting stuck on one option too early. With AQN’s gradual “noise decay,” exploration is strong at the start and becomes more focused later, which improved reward curves and final accuracy.
5. Why does it matter?
- Practical impact: RL is one of the best ways to teach models to reason, but it’s expensive. QeRL makes RL cheaper and faster, which means more teams can train better reasoning models without huge compute budgets.
- Better learning through controlled exploration: The paper flips a common belief. While noise usually hurts supervised training (where models copy examples), in RL a right amount of controlled noise helps models try smarter options and find better strategies.
- Scaling reasoning: Training very large models (like 32B) with RL on a single high-end GPU is a big step toward more accessible and scalable reasoning systems.
- Broad use: Although tested on math, the approach can be applied to other complex reasoning tasks that need multi-step thinking, like planning, coding, or data analysis.
In short: QeRL shows that compressing models in the right way not only saves memory and time but also makes them learn better strategies during RL, leading to faster training and strong performance on challenging reasoning tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed concretely so future researchers can act on it.
- Lack of theoretical guarantees: the claim that quantization noise increases policy entropy and improves exploration is supported empirically but not derived or bounded; provide a formal analysis of how FP4 weight perturbations propagate to logits, alter softmax entropy, and affect policy gradients under GRPO/DAPO.
- Entropy measurement robustness: policy entropy increases are shown for one model/task; quantify robustness across temperatures, top-p settings, seeds, and sampling strategies, and disentangle quantization-induced entropy from sampling hyperparameters.
- Bias/variance of gradients: quantify how quantization changes the bias and variance of policy gradient estimates (e.g., via controlled experiments measuring gradient noise scale, KL divergence stability, and update magnitudes).
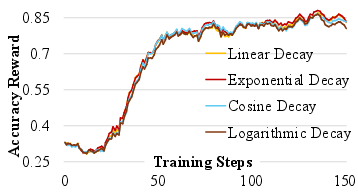
- AQN scheduler design: explore adaptive (data- or signal-driven) schedules that adjust noise based on online signals (e.g., entropy plateau, reward slopes, KL to reference), rather than a fixed exponential decay; compare against learned or per-layer schedules.
- Per-layer noise sensitivity: systemically ablate where AQN is injected (attention vs MLP, Q/K/V vs gate/up/down, early vs late layers) and whether per-layer noise scales outperform shared RMSNorm noise; quantify effects on stability and performance.
- Equivalence of noise merging: rigorously validate the claimed equivalence between additive pre-matmul noise and multiplicative RMSNorm scaling across diverse inputs and architectures, including backward pass effects; measure any discrepancies and their impact on training.
- Backward pass behavior: analyze how merged multiplicative noise interacts with gradient computation (e.g., gradient variance, potential explosion/vanishing in LN scales), and propose safeguards (clipping, normalization, or noise-shaping).
- Generalization beyond math: evaluate QeRL on non-mathematical domains (code generation, reasoning-heavy QA, tool-use, multilingual tasks, dialogue) to assess whether quantization-enhanced exploration remains beneficial or becomes harmful.
- RL algorithm coverage: test compatibility with PPO (with learned reward models), actor-critic (A2C/A3C), off-policy variants, and KL-regularized algorithms; quantify interactions between quantization-induced entropy and explicit entropy/KL penalties.
- Reward model settings: for RLHF-like pipelines, measure whether quantization/AQN impacts preference modeling, reward hacking, or calibration; compare rule-based rewards vs learned reward models under quantized training.
- Seed and run-to-run variance: report statistical significance, error bars, and variance across multiple seeds/runs for reward curves and final accuracies; characterize stability under quantization and AQN.
- LoRA rank interactions: beyond reward curves, evaluate final accuracy and sample efficiency across ranks and targeted layers; determine optimal rank-layer configurations under NVFP4 and AQN.
- Reference model precision: GRPO requires a reference model; clarify whether the reference is also quantized, and measure accuracy/speed/memory trade-offs and KL penalty reliability when both policy and reference are FP4.
- KV-cache precision: quantify memory and speed effects of KV-cache quantization during long rollouts, and its impact on reward, entropy, and training stability; provide kernels/techniques for KV-cache compression compatible with AQN.
- Activation quantization: investigate activation quantization (not just weight-only) in RL training; assess whether FP4 weights + lower-precision activations can further reduce memory while maintaining training quality.
- Format-level analysis: characterize why NVFP4 ultimately outperforms MXFP4/NF4 (e.g., block size, scaler precision, dynamic range), with controlled experiments and metrics (per-layer error, sensitivity to AWQ calibration).
- Calibration dataset sensitivity: analyze how AWQ calibration size/domain affects RL outcomes; test larger/diverse calibration corpora and domain-specific calibration for math vs other tasks.
- Hardware portability: evaluate QeRL on non-NVIDIA hardware (AMD, TPUs) and older NVIDIA architectures lacking FP4 kernel support; measure speed/accuracy/memory trade-offs with INT8/FP8 alternatives to establish portability.
- Fair comparison to QLoRA/others: include head-to-head benchmarks with optimized kernels for competing methods (e.g., GPTQ, bitsandbytes INT8, FlashRL with IS corrections) across identical settings (batch sizes, sequence lengths, sampling configs).
- End-to-end speed beyond the first 30 steps: report throughput and latency over full training (including later long outputs), not only early steps; include breakdowns for rollout, reward computation, logit evaluation, and backward pass.
- Memory accounting: provide complete training memory profiles (model weights, optimizer states, KV cache, activations, ref/policy duplication) for BF16 LoRA, QLoRA, and QeRL at varying batch sizes/sequence lengths.
- Safety/robustness: assess whether increased exploration from quantization/AQN increases unsafe or off-spec generations during RL; include safety metrics and mitigation strategies (e.g., reward shaping or constrained decoding).
- Failure modes: identify tasks where quantization-induced entropy harms learning (e.g., deterministic classification, short-form outputs); propose detection and automatic suppression of AQN when detrimental.
- Online adaptation triggers: study automatic detection of reward plateaus/entropy collapse and trigger noise injections or annealing adjustments accordingly; compare to static interval-based injections.
- Interaction with KL penalties: map out how AQN interacts with KL penalties in GRPO, including whether AQN inflates KL, and propose adaptive KL weighting/hard constraints when using quantization noise.
- Impact on calibration/precision of logits: measure whether quantization/AQN distort logit scales or temperature calibration, and whether temperature re-tuning is needed during training and evaluation.
- Inference-time behavior: evaluate whether models trained with AQN retain performance when AQN is disabled at inference; analyze if AQN creates a train–test mismatch and how to mitigate it (e.g., small residual noise at inference).
- Data efficiency: quantify sample efficiency improvements (steps/episodes to reach target pass@1) attributable to quantization/AQN, separate from speedups due to kernels; include compute-normalized metrics (tokens or FLOPs to target).
- Multi-agent/group size effects: ablate GRPO/DAPO group size (G) under QeRL to understand how quantization-induced exploration interacts with multi-sample aggregation and advantage normalization.
- Integration with advanced PEFT: compare QeRL with other PEFT methods (adapters, prefix-tuning, ReLoRA) and hybrid schemes; determine if combining them with NVFP4/AQN yields further gains.
- Reproducibility details: release code, kernels, and training recipes (exact hyperparameters, schedules, seeds), plus detailed environment specs; include scripts to replicate 32B-on-single-H100 claims and benchmarks across hardware.
Practical Applications
Below are practical, real-world applications that follow from the paper’s findings, methods, and innovations. Each item notes sector(s), potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Cost-reduced RL post-training for domain assistants (software, finance, healthcare, legal)
- What: Use QeRL (NVFP4 + LoRA + AQN) to train reasoning-heavy assistants where rewards are verifiable (e.g., math correctness, code unit tests, SQL execution results, tool-call success).
- Why now: 1.2–1.5× end-to-end speedups and 25–30% of the memory footprint of BF16 LoRA; matches or exceeds 16-bit LoRA and approaches full-FT on GSM8K/MATH.
- Tools/workflows: TRL/DeepSpeed/HF Transformers integration, Marlin NVFP4 kernels, AWQ weight-only calibration, GRPO/DAPO loops with rule-based rewards.
- Assumptions/dependencies: Access to NVFP4-capable GPUs (e.g., H100/B100), reward functions that are programmatically checkable, RMSNorm-based architectures (for AQN noise-merging), stable AQN schedule tuning.
- Single-GPU RL training for larger models in labs/startups (academia, startups, SMEs)
- What: Train 32B policy with GRPO on a single H100 80GB GPU for prototyping, ablations, and classroom demos.
- Why now: Demonstrated feasibility in paper; reduces barrier to entry.
- Tools/workflows: Ready-to-run QeRL configs for Qwen2.5 7B/14B/32B; containerized images with NVFP4 kernels.
- Assumptions/dependencies: H100 80GB or equivalent; curated training data with verifiable rewards; appropriate LoRA ranks (e.g., 16–32) to balance speed/quality.
- Faster RLHF and post-training alignment stages (AI labs)
- What: Replace 16-bit LoRA or NF4 QLoRA with NVFP4+LoRA for rollouts and prefilling to accelerate RLHF steps such as GRPO/DAPO without reward models.
- Why now: Paper shows 1.5× rollout speedup; QLoRA suffers 0.7–0.8× slowdowns due to NF4 unpacking.
- Tools/workflows: Swap precision path to NVFP4; monitor KL/entropy; AQN scheduler to avoid entropy collapse late in training.
- Assumptions/dependencies: Marlin kernel availability; framework hooks for precision control; stability of AQN hyperparameters.
- Synthetic data generation for reasoning traces (academia, data vendors)
- What: Use QeRL-accelerated rollouts to generate diverse high-entropy chain-of-thought/self-play trajectories for supervised distillation.
- Why now: Quantization noise increases policy entropy, improving exploration and diversity of traces with lower cost per token.
- Tools/workflows: Self-instruct pipelines; filtering by programmatic correctness; distillation into smaller student models.
- Assumptions/dependencies: Strong verifier/reward functions; guardrails for safety filtering; compute for iterative generate–filter cycles.
- RL for code copilots with unit-test rewards (software engineering)
- What: Train code models via RL using pass@k unit tests as rewards; exploit QeRL speedups for long-sequence rollouts during code synthesis.
- Why now: Rollouts dominate cost; QeRL accelerates generation and reduces memory, enabling larger batch sizes or longer contexts.
- Tools/workflows: Harness-based reward evaluators (pytest, sandboxing), GRPO without reward model, NVFP4 inference kernels.
- Assumptions/dependencies: Robust sandboxing and deterministic tests; secure execution for untrusted code; reward shaping for partial credit.
- Domain-specific math/science tutors in schools and small labs (education)
- What: Fine-tune 3B–7B instructors on GSM8K/BigMath-style curricula with verifiable answers; deploy as campus-hosted tutors.
- Why now: Paper shows 83.7–90.8% GSM8K with quantized PEFT RL; single-GPU feasibility reduces cost.
- Tools/workflows: QeRL recipe for small models; curricular reward design; evaluation harnesses (MATH500, AMC/AIME).
- Assumptions/dependencies: Access to at least one NVFP4 GPU; appropriate academic datasets; responsible use policies.
- Tool-use and multi-step agent orchestration (software automation, productivity)
- What: Use success/failure of tool calls (e.g., retrieval hits, API return codes) as rewards; leverage AQN-driven exploration to discover better tool sequences.
- Why now: Increased sampling entropy prevents early mode collapse in action selection (tool calling), improving exploration of tool chains.
- Tools/workflows: Agentic RL environments with deterministic tool success metrics; logging and replay buffers for rollouts.
- Assumptions/dependencies: Reliable tool instrumentation and telemetry; safe sandboxing for external calls; failure-mode analysis.
- Cloud provider SKU for low-cost RL training (cloud platforms)
- What: Offer “NVFP4-RL” training instances with pre-optimized kernels for rollouts/prefill, marketed with cost/time SLAs for reasoning RL.
- Why now: Immediate business case from 1.2–1.5× E2E speedups and memory reductions.
- Tools/workflows: Managed MLOps (metrics for entropy, reward growth, rollout throughput), curated images with QeRL stack.
- Assumptions/dependencies: Customer workloads with verifiable rewards; support contracts for kernel/driver updates.
Long-Term Applications
- Cross-domain RL exploration via adaptive quantization noise (robotics, recommender systems, operations research)
- What: Extend AQN to transformer policies beyond language (e.g., decision transformers) to induce structured, multiplicative exploration noise.
- Potential products/workflows: AQN plugins for robotics/control frameworks; auto-tuned noise schedules per task.
- Assumptions/dependencies: Demonstrated transfer to continuous-action spaces and safety-critical settings; additional theory to bound regret/safety.
- Hardware–software co-design for “programmable exploration” (semiconductors, systems)
- What: Architect GPU/NPU features that expose controllable quantization noise primitives (per-channel, per-block) for RL workloads.
- Potential products/workflows: Driver-level APIs to modulate FP4 scaling noise; exploration-aware compilers/kernels.
- Assumptions/dependencies: Vendor support (NVIDIA/AMD/Google); standards for MX/NVFP4-like formats across ecosystems.
- On-device or edge RL fine-tuning for compact models (mobile/edge, IoT)
- What: Future NPUs with FP4-like support could allow small-scale RL post-training on-device (e.g., code fixers, personal tutors).
- Potential products/workflows: Federated RL with verifiable local rewards (privacy-preserving unit tests, local database queries).
- Assumptions/dependencies: FP4-capable edge hardware, memory-efficient KV-cache strategies, robust battery/thermal management.
- RL-as-a-Service for reasoning with verifiable rewards (platforms/SaaS)
- What: Managed service offering RL post-training pipelines for math, code, SQL, and tool-use with cost advantages from QeRL-style stacks.
- Potential products/workflows: Self-serve consoles to define rewards, schedule AQN, monitor entropy and reward curves with governance hooks.
- Assumptions/dependencies: Standardized reward interfaces; liability and safety frameworks for customer-provided tasks.
- Learned or adaptive exploration schedules (AutoML for RL)
- What: Replace hand-tuned exponential AQN schedules with learned controllers (bandits/meta-RL) that optimize noise over training.
- Potential products/workflows: “Auto-AQN” tuner integrated with hyperparameter search services; entropy and reward slope as signals.
- Assumptions/dependencies: Reliable online metrics; safeguards against unstable exploration bursts.
- Safety alignment and robustness using controlled noise (safety, governance)
- What: Use AQN to prevent entropy collapse and explore diverse, safer policies; stress-test models under controlled multiplicative noise.
- Potential products/workflows: Safety evaluation suites that vary noise schedules; red-teaming frameworks for RL policies.
- Assumptions/dependencies: Well-specified safe reward functions; systematic analysis of how noise affects harmful behaviors.
- Multimodal reasoning RL with FP4 kernels (healthcare imaging, robotics, geospatial)
- What: Extend NVFP4+LoRA+AQN to vision–language and speech–LLMs where rollouts are long and rewards are verifiable (e.g., tool-use in medical report generation with rule checks).
- Potential products/workflows: FP4-enabled attention/backbone kernels for multimodal encoders; verifiable reward harnesses (e.g., ICD code matches, structured template conformance).
- Assumptions/dependencies: Kernel support for multimodal blocks; strong, domain-specific verifiers; regulatory compliance.
- Curriculum and data selection co-optimized with exploration (academia, EdTech)
- What: Co-design curricula and AQN schedules to pace exploration across problem difficulty (e.g., BigMath level 3→5).
- Potential products/workflows: Curriculum RL orchestrators that adapt noise based on reward acceleration and error types.
- Assumptions/dependencies: Rich metadata about task difficulty; online diagnostics linking errors to exploration deficits.
- Sustainable AI policy and reporting (policy, ESG)
- What: Recommend quantized RL training as a compute- and energy-efficient practice in grant programs and ESG disclosures.
- Potential products/workflows: Carbon accounting templates that recognize FP4-based training efficiencies; procurement checklists for FP4-capable hardware.
- Assumptions/dependencies: Credible life-cycle assessments; cross-institutional adoption and auditing standards.
- Teacher–student pipelines at scale (education, consumer AI)
- What: Train stronger teachers via QeRL (faster, cheaper), then distill to smaller students for deployment in consumer apps.
- Potential products/workflows: Pipeline templates for RL teacher training → synthetic data → supervised distillation → evaluation.
- Assumptions/dependencies: High-quality verifiers; distillation preserving reasoning fidelity; licensing of base models and datasets.
Notes on common dependencies and constraints
- Hardware: NVFP4/MXFP4 support (Hopper/Blackwell); Marlin or equivalent FP4 kernels; drivers and CUDA compatibility.
- Model architecture: RMSNorm availability to merge AQN noise without parameter overhead; LoRA rank selection (16–32 works well in paper).
- Task fit: Works best for verifiable-reward tasks (math, code, SQL, tool-use). Non-verifiable or preference-only rewards may require additional reward modeling.
- Stability and safety: AQN schedules must be tuned; excessive exploration can destabilize training or degrade safety without proper rewards/guardrails.
- Software ecosystem: Integration with RL frameworks (GRPO/DAPO/TRL), quantization toolchains (AWQ), and MLOps for monitoring reward/entropy/throughput.
Glossary
- Adaptive Quantization Noise (AQN): A training-time mechanism that dynamically modulates quantization-induced perturbations to boost exploration and stabilize RL. "QeRL introduces an Adaptive Quantization Noise (AQN) mechanism, which dynamically adjusts noise during training."
- AWQ: Activation-aware Weight Quantization; a weight-only post-training quantization method used to calibrate model weights for efficient inference. "For weight-only quantization, we applied AWQ to MXFP4 and NVFP4 formats."
- BF16: Bfloat16; a 16-bit floating-point format with an 8-bit exponent designed to preserve dynamic range while reducing memory and compute costs. "original bfloat-16 (BF16) models."
- Blackwell GPU architecture: NVIDIA’s GPU architecture that introduces hardware support for FP4 formats, enabling faster low-bit inference/training. "the latest Blackwell GPU architecture introduces hardware support for the advanced FP4 format, MXFP4 and NVFP4."
- DAPO (Dynamic Sampling Policy Optimization): A reinforcement learning algorithm for LLMs that adjusts sampling and clipping to prevent entropy collapse and improve exploration. "Dynamic Sampling Policy Optimization suggests higher clipping upper-bond can help avoid entropy collapse."
- Dequantization: The process of reconstructing high-precision values from quantized representations using stored scaling information. "The dequantization of a 4-bit $\tilde{\mathbf{W}$ to the high-precision $\hat{\mathbf{W}$ follows:"
- E4M3: An FP8 format with 4 exponent bits and 3 mantissa bits used for block-wise scaling in NVFP4. "NVFP4 employs an FP8 (E4M3) scaling factor with smaller parameter blocks of 16 elements"
- E8M0: An FP8 format with 8 exponent bits and 0 mantissa bits used for block-wise scaling in MXFP4. "MXFP4 adopts a shared FP8 (E8M0) scaling factor across parameter blocks of 32 elements"
- Entropy collapse: A phenomenon where the policy’s entropy diminishes, reducing exploration and potentially harming RL performance. "suggests higher clipping upper-bond can help avoid entropy collapse."
- FP4: Four-bit floating-point format enabling compact weight representation with associated FP8 scaling. "for the floating-point quantization, such as FP4 format"
- GAE (Generalized Advantage Estimation): A method for estimating advantages using exponentially-weighted returns to reduce variance in policy gradients. "Group Relative Policy Optimization is designed based on the Generalized Advantage Estimation (GAE)"
- GRPO (Group Relative Policy Optimization): A policy optimization method that uses grouped samples, rule-based rewards, and KL penalties without a separate reward model. "Group Relative Policy Optimization is designed based on the Generalized Advantage Estimation (GAE)"
- GSM8K: A grade-school math word problem benchmark commonly used to evaluate reasoning in LLMs. "GSM8K comprises 7,500 samples with a generation number of 8"
- Importance sampling: A correction technique that reweights samples to account for distribution or precision mismatches between models. "require importance sampling to correct discrepancies"
- KL penalty: A regularizer based on KL divergence that constrains the policy update to remain close to a reference model. "KL penalty is used in GRPO to avoid the unexpected large change in updating"
- Layer normalization: A normalization technique applied to neural activations across channels to stabilize training and integrate noise modulation. "integrates this noise vector directly into the layer normalization parameters of LLM architectures."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects trainable low-rank matrices to adapt large models without updating full weights. "LoRA introduces a low-rank decomposition to model these updates efficiently:"
- Marlin kernel: An optimized NVIDIA kernel that accelerates inference for weight-only quantized formats on Hopper/Blackwell GPUs. "Weight-only formats also support inference acceleration on NVIDIA-H100 GPUs with the Marlin kernel."
- MXFP4: A micro-scaling FP4 format using shared FP8 (E8M0) scaling per 32-element block for efficient quantized inference. "MXFP4 adopts a shared FP8 (E8M0) scaling factor across parameter blocks of 32 elements"
- NF4 (NormalFloat 4-bit): A 4-bit data type tailored to normally distributed weights, used in QLoRA for quantized training. "4-bit NormalFloat (NF4) is a new data type, designed for normally distributed weights."
- NVFP4: An NVIDIA FP4 format with FP8 (E4M3) scaling per 16-element block, enabling fine-grained scaling and faster generation. "NVFP4 employs an FP8 (E4M3) scaling factor with smaller parameter blocks of 16 elements"
- Pass@1: An evaluation metric measuring the accuracy of the model’s first (single) sampled solution. "we report primarily the average accuracy of one sample (Pass@1)."
- PEFT (Parameter-Efficient Fine-Tuning): Techniques that fine-tune a small subset of parameters (e.g., adapters, low-rank matrices) to reduce memory/compute. "Applying parameter-efficient fine-tuning (PEFT) to quantized models not only reduces training resource consumption"
- Policy entropy: The entropy of the action/token distribution; higher entropy generally promotes exploration in RL. "quantization noise increases policy entropy, enhancing exploration"
- Prefilling: The initial stage of generation/follow-up where caches are filled before autoregressive decoding, optimized here alongside rollout. "integrates a Marlin-based approach in both rollout and prefilling stages."
- PPO (Proximal Policy Optimization): A widely used RL algorithm that constrains updates via clipping; often requires a separate reward model for LLM training. "as required in Proximal Policy Optimization (PPO)"
- QLoRA: A quantized LoRA approach that uses NF4 for weights and optimizes with low-bit precision, trading off speed in RL rollouts. "Using QLoRA in RL slows rollouts by 1.5–2×, further reducing efficiency."
- Quantization: Mapping full-precision weights to low-bit representations (integer or floating-point) using scaling factors to reduce memory/compute. "Integer quantization requires mapping float-point weights"
- Quantization noise: The approximation error introduced by quantization; here leveraged to increase entropy and improve exploration in RL. "quantization noise, with precise control, can benefit RL by increasing policy entropy"
- Rollouts: The process of sampling trajectories/completions from the policy to compute rewards and gradients in RL. "Rollouts are particularly costly"
- RMSNorm: Root Mean Square Layer Normalization; a variant of LayerNorm used in modern LLMs and for noise merging. "LayerNorm (e.g., RMSNorm) of each block in LLMs."
- Top-p sampling: Nucleus sampling that chooses tokens from the smallest set whose cumulative probability exceeds p. "top-p sampling with ."
- Weight-only quantization: Quantizing only the weights (not activations), enabling memory savings and kernel-level speedups. "For weight-only quantization, we applied AWQ to MXFP4 and NVFP4 formats."
- W_q/W_k/W_v projection matrices: The query, key, and value linear projections in self-attention, common targets for LoRA adaptation. "Within self-attention modules, LoRA is generally applied to the attention and feed-forward projection matrices ()"
Collections
Sign up for free to add this paper to one or more collections.