- The paper introduces MAPO, a framework that aligns textual reasoning with visual actions using CLIP-based semantic verification.
- The method employs dense, process-level supervision and group-based advantage estimation to reduce policy gradient variance.
- Empirical results on benchmarks like HR-Bench demonstrate improved accuracy and training stability over standard RL approaches.
Bridging the Reasoning-Action Gap in Multimodal Agents: An Analysis of MAPO
Introduction
Contemporary Multimodal LLMs (MLLMs) are increasingly agentic, capable of interleaving text-based reasoning with visually-grounded actions such as tool invocations in multi-turn dialogues. However, a persistent challenge in this paradigm is the reasoning-action gap: models often produce plausible text justifying their intent, but fail to execute corresponding visual actions with process-level fidelity, leading to degraded multimodal reasoning. Outcome-centric reinforcement learning (RL) fails to address this gap, as it rewards only the final correctness, ignoring process-level discrepancies.
The paper "Walk the Talk: Bridging the Reasoning-Action Gap for Thinking with Images via Multimodal Agentic Policy Optimization" (MAPO) (2604.06777) proposes a new RL framework—Multimodal Agentic Policy Optimization—that introduces dense, process-consistent supervision by enforcing semantic consistency between textual reasoning and visual actions. Utilizing self-generated descriptive labels and a CLIP-based semantic verifier, MAPO explicitly aligns the agent's actions with its textual thought process within the Multimodal Chain-of-Thought (MCoT), resulting in not only improved task performance but also greater training stability and scalability.
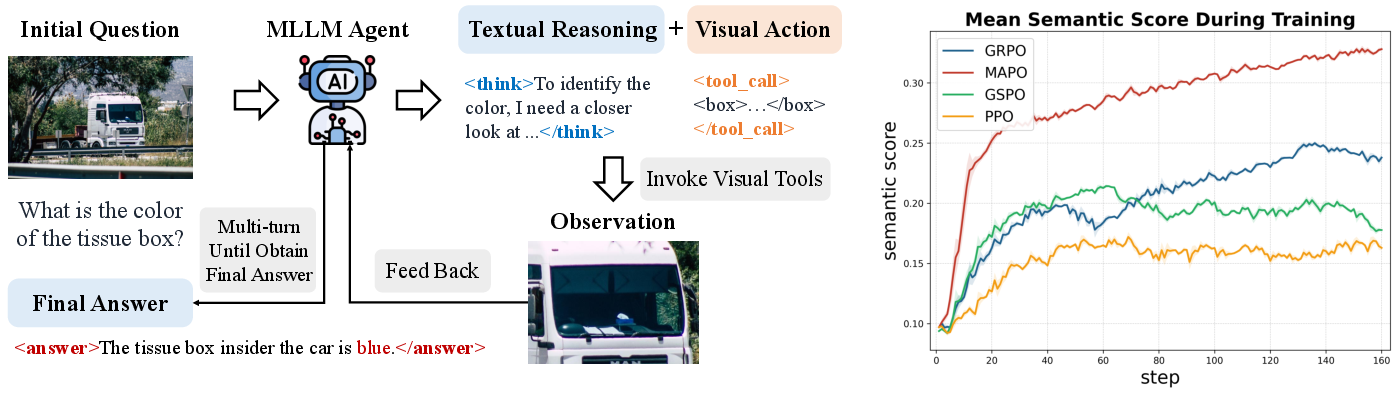
Figure 1: The agentic "thinking with images" setup (left), and MAPO's semantic score training curves showing clear improvements over standard RL (right).
MAPO Framework and Methodology
MAPO transforms each step of agentic reasoning in MLLMs into an explicit "talk and walk" loop. The model must produce a textual rationale, a tool action, and a fine-grained descriptive label of its intended visual target. After executing the tool action—such as cropping or zooming—the resulting image is verified against the self-generated text using a lightweight CLIP model, creating a dense, computationally cheap supervision signal for every step.
To avoid reward hacking and encourage efficient trajectories, MAPO employs a trajectory-aware discount factor on the semantic score, penalizing unnecessarily long sequences while tolerating exploration in initial turns. The semantic consistency signals, along with the outcome reward, are seamlessly incorporated during RL optimization through group-based advantage estimation.
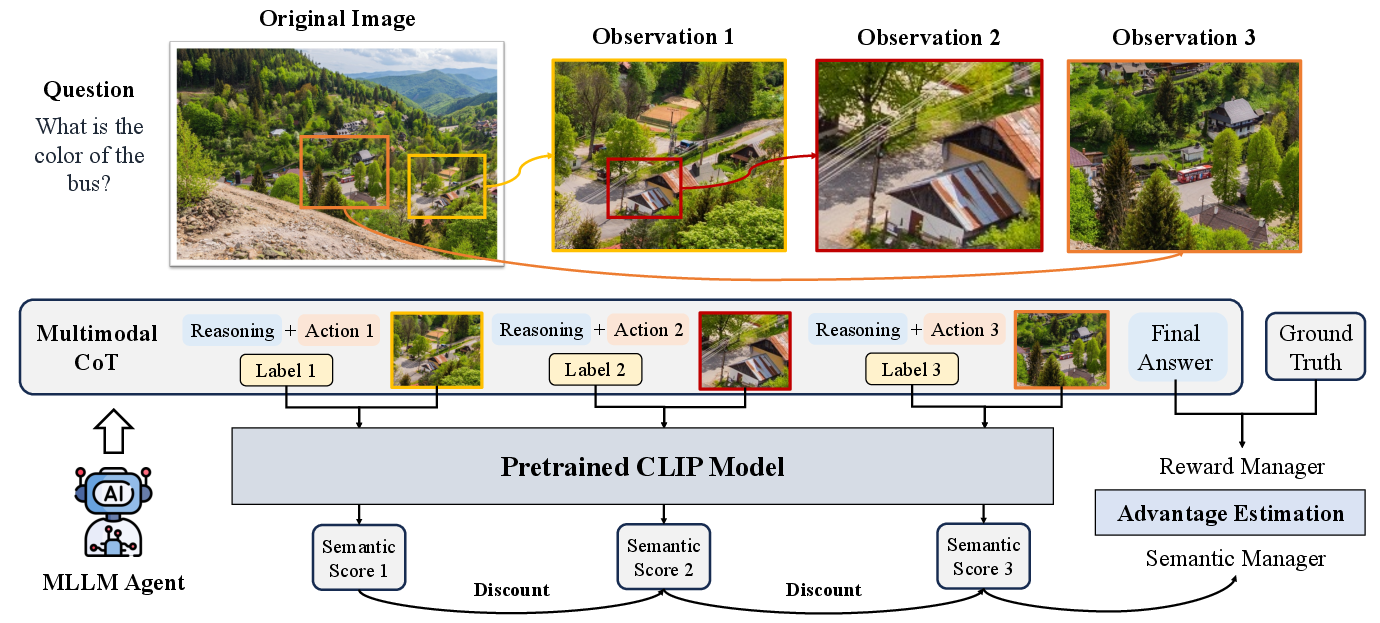
Figure 2: MAPO bridges the reasoning-action gap by integrating CLIP-based semantic alignment with textual reasoning and visual actions at each agentic step.
This design both (1) enforces structured process-aligned exploration during RL, and (2) grounds the abstract reasoning of MLLMs in observable reality without requiring costly manual annotation.
Theoretical Insights: Dual Variance Reduction
MAPO's core contribution is substantiated by a theoretical reduction of policy gradient variance on two axes:
- Spatial Variance Reduction: Group-based advantage estimation (as in GRPO) leverages the high intra-group correlation when sampling multiple candidate responses on the same prompt, acting as an effective spatial control variate. The group-mean reward acts to filter out prompt-intrinsic difficulty, stabilizing updates over diverse multimodal inputs.
- Signal Variance Reduction: Incorporating continuous, CLIP-derived semantic scores provides dense, process-aware feedback, mitigating the sparsity and high-variance of binary outcome signals. The semantic score offers a lower-variance, trajectory-aligned proxy for progression towards the task objective.
The dual effect is a dramatic improvement in optimization smoothness and empirical convergence guarantees for complex, high-dimensional MLLM policies.
Empirical Results
MAPO delivers robust state-of-the-art results on several fine-grained high-resolution visual reasoning benchmarks, including V*, HR-Bench, and MME-Real-Lite. When directly compared to strong open-source and closed-source MLLMs, as well as leading RL optimization strategies (PPO, DAPO, GRPO, GSPO), MAPO demonstrates clear quantitative gains. For instance, on HR-Bench, MAPO surpasses the previous best GRPO baseline by +2% in overall accuracy, and leads in the most challenging 8K subset (78.6% vs. 77.0%).
Process-level qualitative analysis further reveals that MAPO-trained agents exhibit strong semantic alignment in reasoning-action trajectories, consistently "walking the talk" rather than hallucinating unattested visual actions.

Figure 3: MAPO trajectories (left) overtly align executed visual actions with generated textual rationales, unlike GRPO (right) which frequently misaligns execution and reasoning.
Scalability analysis underscores MAPO's advantage: standard RL approaches such as GRPO experience collapse and catastrophic forgetting in long-horizon training, while MAPO maintains stable, monotonically increasing learning curves without mode collapse.
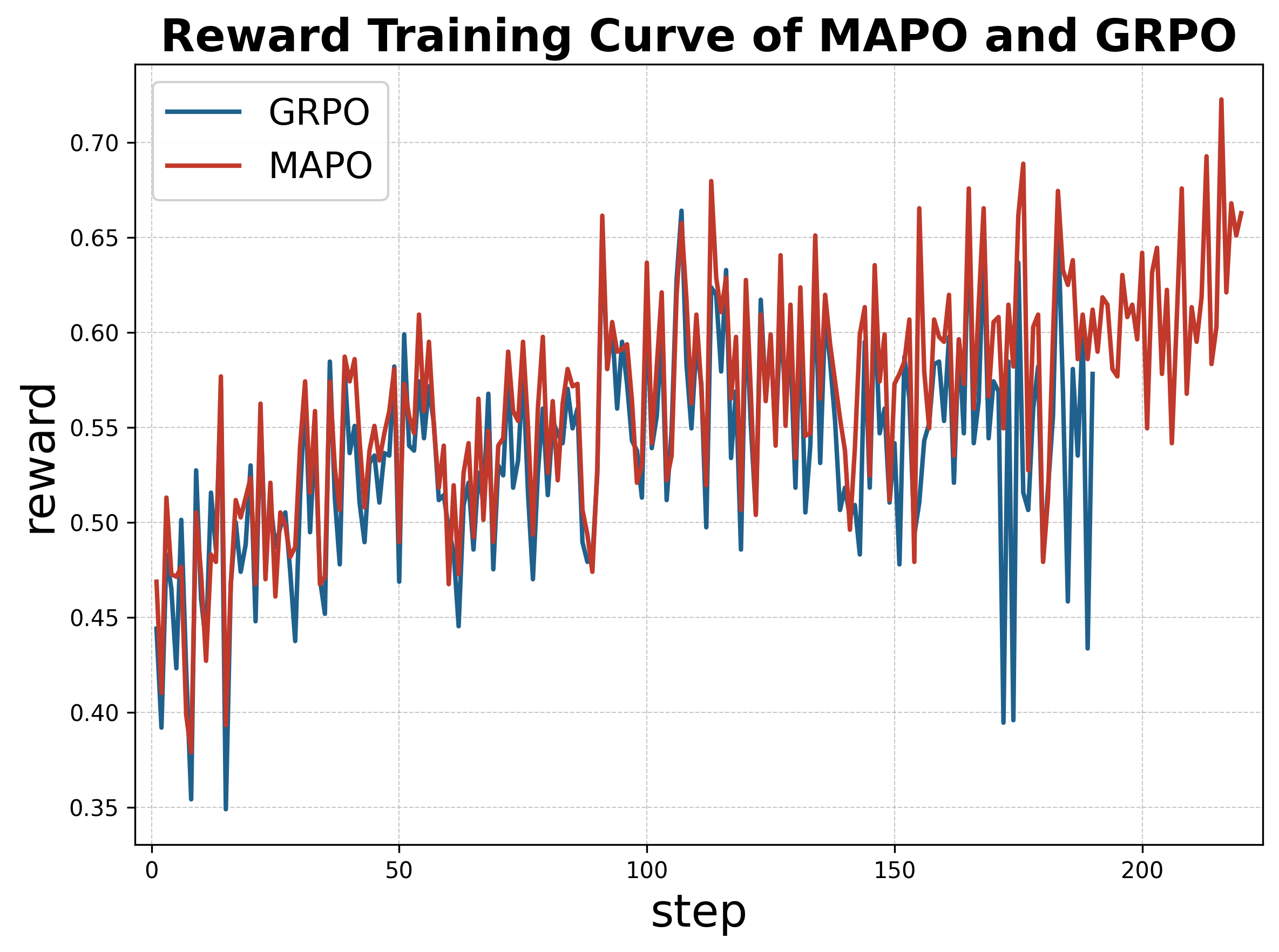
Figure 4: Reward dynamics show MAPO's resilience to degradation during extended training, unlike GRPO which suffers instability and collapse.
Implications and Future Directions
MAPO generalizes to a broad range of tool-integrated agentic environments beyond visual exploration—any setting permitting the agent to express explicit intent labels (e.g., web navigation, API invocation, code execution) and employ a modality-appropriate semantic alignment model is a candidate for this process-grounded RL strategy.
Practically, MAPO opens the door to constructing more reliable, interpretable, and robust MLLM-based agents. Theoretically, it provides a solid foundation for continued advances in scalable reinforcement learning for agents operating under multimodal, high-dimensional observation and action spaces.
Future work may explore more advanced, learned semantic alignment modules, active curriculum shaping for trajectory-length penalties, and the integration of MAPO in multi-agent cooperative settings or compositional toolchains. As MLLMs continue to expand into domains requiring tight integration of reasoning and physical or simulated action, process-consistency constraints like MAPO's are likely to become foundational.
Conclusion
"Walk the Talk" (2604.06777) presents MAPO, a theoretically and empirically validated policy optimization framework that effectively closes the reasoning-action gap in agentic multimodal models. By embedding fine-grained, automatic semantic verification directly within the reasoning trajectory and combining it with outcome rewards using group-based RL, the method enforces end-to-end process consistency, resulting in superior alignment, performance, and stability. The approach is extensible across modalities and tools, offering a robust paradigm for building future scalable, reliable AI agents.