- The paper introduces an agentic reward model that leverages explicit tool calls to improve multimodal reasoning and mitigate hallucinations.
- It employs a think-act-observe loop with a two-stage reinforcement learning process to optimize accuracy and disciplined tool use.
- Experiments demonstrate up to a 16.2% improvement in reward modeling benchmarks, outperforming larger models in challenging multimodal tasks.
Motivation and Problem Statement
Alignment of large vision-LLMs (LVLMs) to human preferences relies on robust reward modeling. Traditional reward models exhibit several deficiencies when applied to complex multimodal reasoning: hallucination, weak or no visual grounding, inability to verify via external tools, and lack of interpretability. These issues become pronounced in scenarios requiring multi-step, evidence-conditioned judgment over multimodal contexts, such as long-document QA, fine-grained perception, and instruction-following tasks. In contrast to existing static scoring paradigms, "ARM-Thinker: Reinforcing Multimodal Generative Reward Models with Agentic Tool Use and Visual Reasoning" (2512.05111) introduces a reward modeling agent that leverages explicit tool calls and a structured reasoning loop for more reliable, interpretable, and verifiable evaluations.

Figure 1: Overview of ARM-Thinker: (a) ARM-Thinker autonomously invokes tools for evidence-grounded judgment, correcting errors that baseline models commit; (b) ARMBench-VL evaluates reward models across three tool-centric tasks; (c) ARM-Thinker’s agentic design leads to marked improvements across all evaluation axes.
ARM-Thinker Architecture and Training Paradigm
ARM-Thinker is designed as a multimodal agent executing a "think-act-observe" paradigm. This architecture enables the learning of complex strategies to invoke and sequence external tools for evidence gathering, refinement, and ultimately reward judgment. Concretely, three categories of tools are employed: (i) image crop/zoom-in for fine-grained visual focus, (ii) document retrieval/navigators for cross-page evidence localization in long documents, and (iii) a suite of instruction-following validators for constraint and format verification. Throughout each reasoning episode, ARM-Thinker maintains and updates an indexed memory for intermediate states, candidate responses, and visual artifacts.
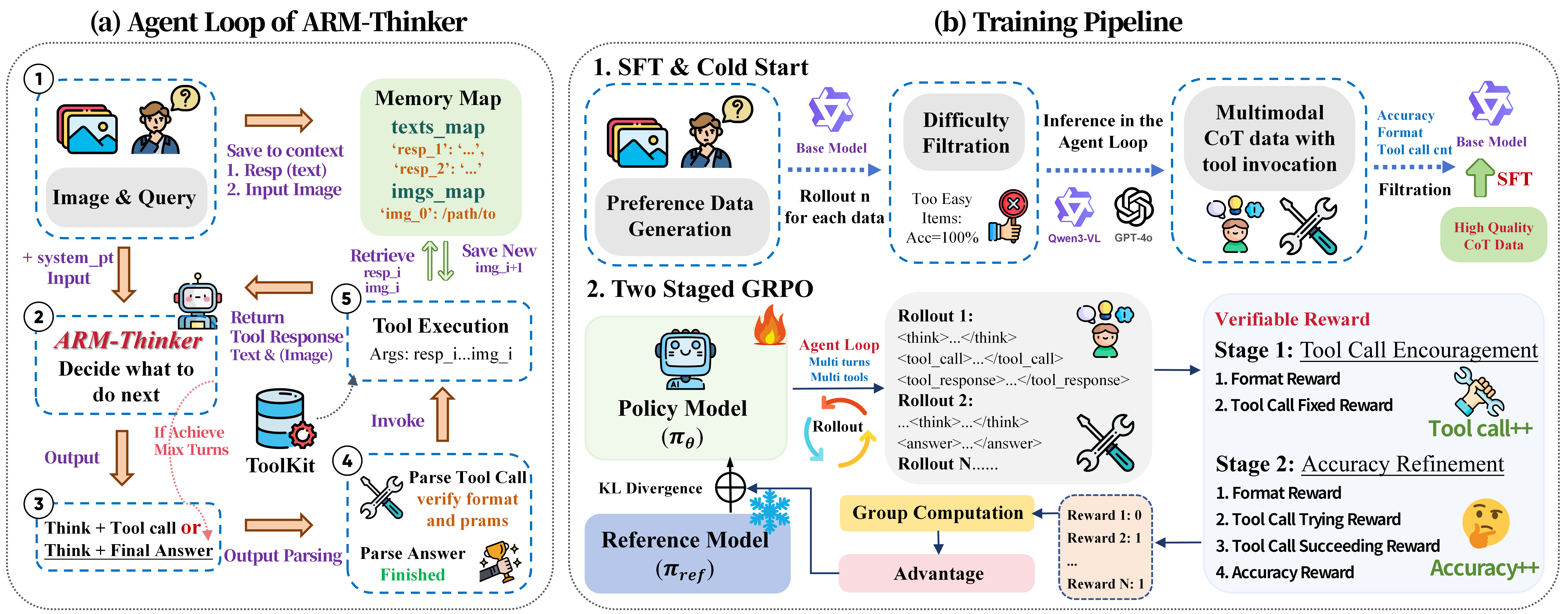
Figure 2: (a) ARM-Thinker iteratively invokes tools in a think-act-observe loop until sufficient evidence supports a reward judgment; (b) The training pipeline starts with SFT/cold start using filtered data and advances to two-stage GRPO for sequential optimization of tool use and accuracy.
Training involves two distinct phases. First, a supervised cold-start stage is executed using data filtered for difficulty, where the model is presented with explicit multimodal chain-of-thought (CoT) trajectories and tool usage annotations. Second, a two-stage reinforcement learning protocol based on Group Relative Policy Optimization (GRPO) is used: Stage 1 encourages exploration and proper invocation of tools, while Stage 2 shifts the objective to final factual accuracy and efficiency, leveraging adaptive, context-dependent reward signals for both correctness and disciplined tool use.
Data Pipeline and Preference-Based Supervision
Since publicly available datasets typically lack agentic, tool-centric interactions, ARM-Thinker relies on a scalable data-generation pipeline. This involves constructing preference pairs using ground-truth data and controlled negative samples generated by large models to ensure error diversity. Difficulty filtering ensures that only non-trivial, high-informative samples are retained for supervision.
Additionally, ARM-Thinker aggregates data from multiple sources targeting its three tool families: DeepEyes for image inspection, MM-IFEngine for instruction verification, and MP-DocVQA for long-document retrieval. For each sample, multimodal chain-of-thought trajectories with explicit tool annotation are constructed, refined, and filtered for correctness and behavioral relevance before being incorporated into the training pipeline.
ARMBench-VL: Agentic Reward Model Benchmark
To rigorously evaluate ARM-Thinker and subsequent agentic reward models, the authors construct ARMBench-VL, the first benchmark that assesses tool use as an integral part of reward judgment across three challenging multimodal settings:
- Fine-Grained Perception: The model must identify or differentiate visually subtle details, requiring image crop/zoom-in tools for local inspection.
- Multimodal Long Document QA: Tasks demand evidence localization in lengthy document page arrays, necessitating document retrieval and navigation.
- Instruction Following: Constraint satisfaction is assessed using a pool of textual verification tools.
ARMBench-VL is constructed with a combination of real and counterfactually-perturbed responses, containing both pairwise and single-response judgment formats, and integrates both general and challenging, tool-critical cases.
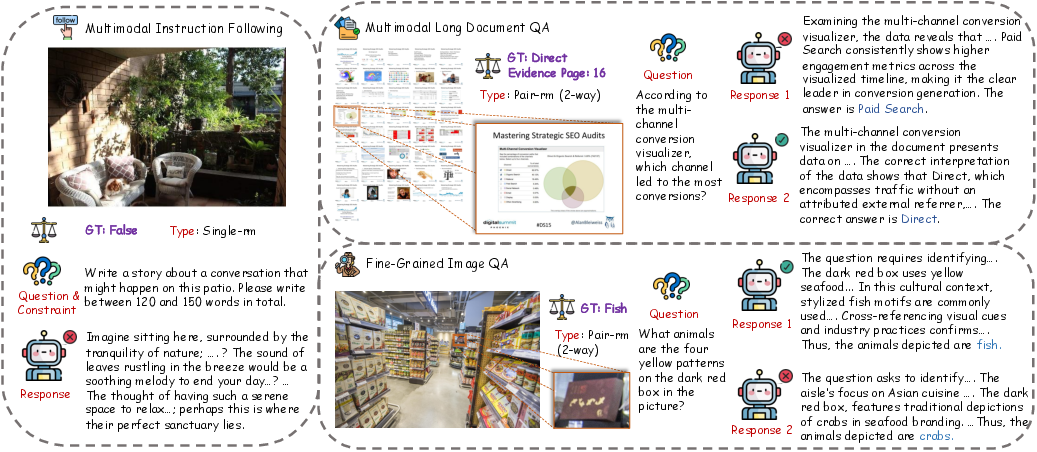
Figure 3: Representative examples from ARMBench-VL, illustrating the multimodal decision space and the explicit availability of tools for each track.
Experimental Results and Ablation Studies
ARM-Thinker yields robust improvements over all baselines on established and newly constructed evaluation suites:
- Reward modeling: +16.2% average improvement across VL-RewardBench, RewardBench-2, and ARMBench-VL.
- Tool-assisted visual reasoning: +9.6% gain on tool-centric "think-with-images" benchmarks.
- Generalizing beyond tool use: Consistent boost of +4.2% in multimodal math and logical reasoning benchmarks.
ARM-Thinker matches or outperforms much larger proprietary systems such as GPT-4o in reward modeling tasks, despite being only 7B parameters.
Analysis of Agentic Capability and Reward Design
Ablation experiments verify that the adaptive reward design in GRPO is essential. Using only accuracy-based or fixed tool-use bonuses leads to either under-use (minimal tool calls, performance plateau) or over-use (excessive, unproductive tool calls) of the available tools. ARM-Thinker's staged, context-sensitive reward schedule induces stable, disciplined, and effective tool usage, leading to higher accuracy and more interpretable reward traces.
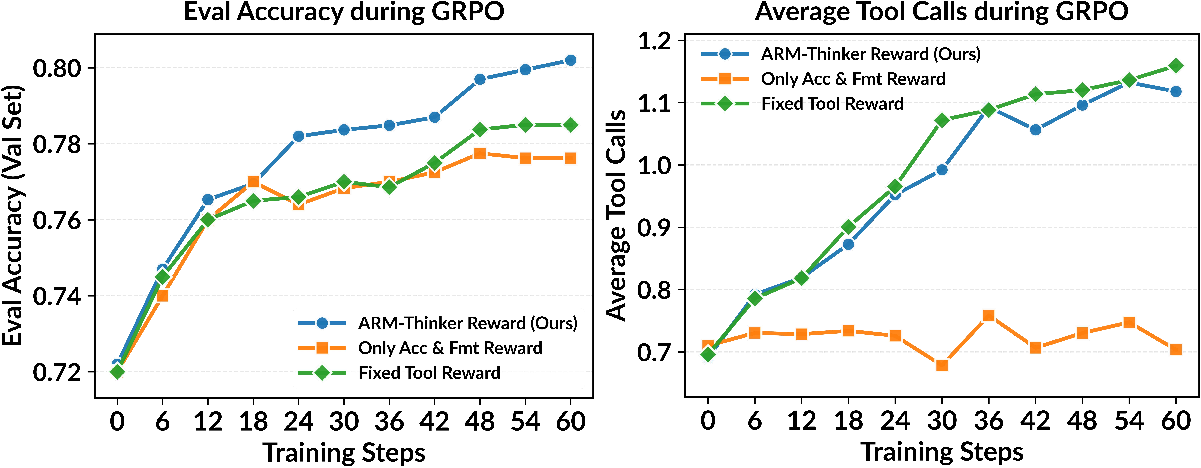
Figure 4: ARM-Thinker’s reward function reliably balances accuracy and effective tool use, outperforming alternative designs that result in over- or under-utilization of tools.
Further ablations confirm that ARM-Thinker's agent loop is not simply a wrapper, but genuinely equips the model with the capability to learn when external tools are informative, generalizing tool-use policies well beyond those explicitly encountered during training.
Implications and Prospects
The ARM-Thinker framework provides an explicit, scalable path toward grounded, interpretable, and reliable reward modeling in multimodal systems. Its successes indicate that passive, one-shot reward assignment is insufficient in settings that demand verifiable cross-modal reasoning. By casting reward attribution as a planning and verification problem—solved through iterative tool invocation—the approach substantially mitigates hallucination errors, superficial matching, and rewards for unsupported answers.
Practically, ARM-Thinker offers a template for new evaluation agents operating in more complex domains, especially as tasks, benchmarks, and user interfaces grow in complexity (e.g., temporal, multi-agent, or spatio-temporal settings). The agentic framework’s backbone- and modality-agnostic design is suited for extensibility to new tools and domains. Theoretical implications include providing an efficient pipeline for scalable, preference-based supervision and reinforcement learning in data-sparse agentic contexts.
Conclusion
ARM-Thinker introduces an agentic, tool-aware reward modeling paradigm that bridges the gap between passive post hoc scoring and active, evidence-driven judgment in LVLMs. By leveraging an explicit think-act-observe loop and flexible tool integration during reward computation, it achieves strong and consistent improvements in challenging multimodal tasks, establishes new standards in agentic reward model evaluation (ARMBench-VL), and demonstrates that RL-driven agentic reasoning substantially enhances both the accuracy and interpretability of reward models. The proposed methodology signals a clear direction for future multimodal reward modeling—integration of agentic capabilities, compositional tool use, and scalable, preference-grounded supervision will be central to further progress in trustworthy, generalizable multimodal AI.

