- The paper introduces a dual-path pipeline that combines schema-guided LLM and rule-based extraction to improve missing-person intelligence consolidation.
- It employs a multi-engine text extraction with OCR fallback and geocoding to harmonize data from varied structured and narrative sources, achieving an F1 score of 0.8664 in LLM extraction.
- The approach ensures auditability through central schema validation and provenance tracking, setting a foundation for enhanced investigative analytics and SAR modeling.
Schema-Guided Extraction and Validation of Missing-Person Intelligence from Heterogeneous Data Sources
Introduction and Motivation
Missing-person and child-safety investigations depend on rapid, evidence-driven consolidation of information from diverse sources, including structured forms, poster bulletins, and unstructured OSINT narratives. Variability in document layout, terminology, and data quality introduces significant barriers to operational triage and downstream spatial analytics. The work "LLM-based Schema-Guided Extraction and Validation of Missing-Person Intelligence from Heterogeneous Data Sources" (2604.06571) introduces the Guardian Parser Pack, a dual-path document-to-schema pipeline that systematically unifies heterogeneous case documents via auditable, schema-first extraction, harmonization, and validation.
System Architecture
The Guardian Parser Pack architecture is engineered for robust heterogeneity handling and auditability, supporting both deterministic (rule-based) and probabilistic (LLM-driven) extraction pathways within a shared processing backbone. The pipeline integrates multi-engine PDF text extraction (with OCR fallback), source detection, source-specific parser routing, harmonization, geocoding, schema validation, warning logging, LLM-based repair, and provenance preservation.
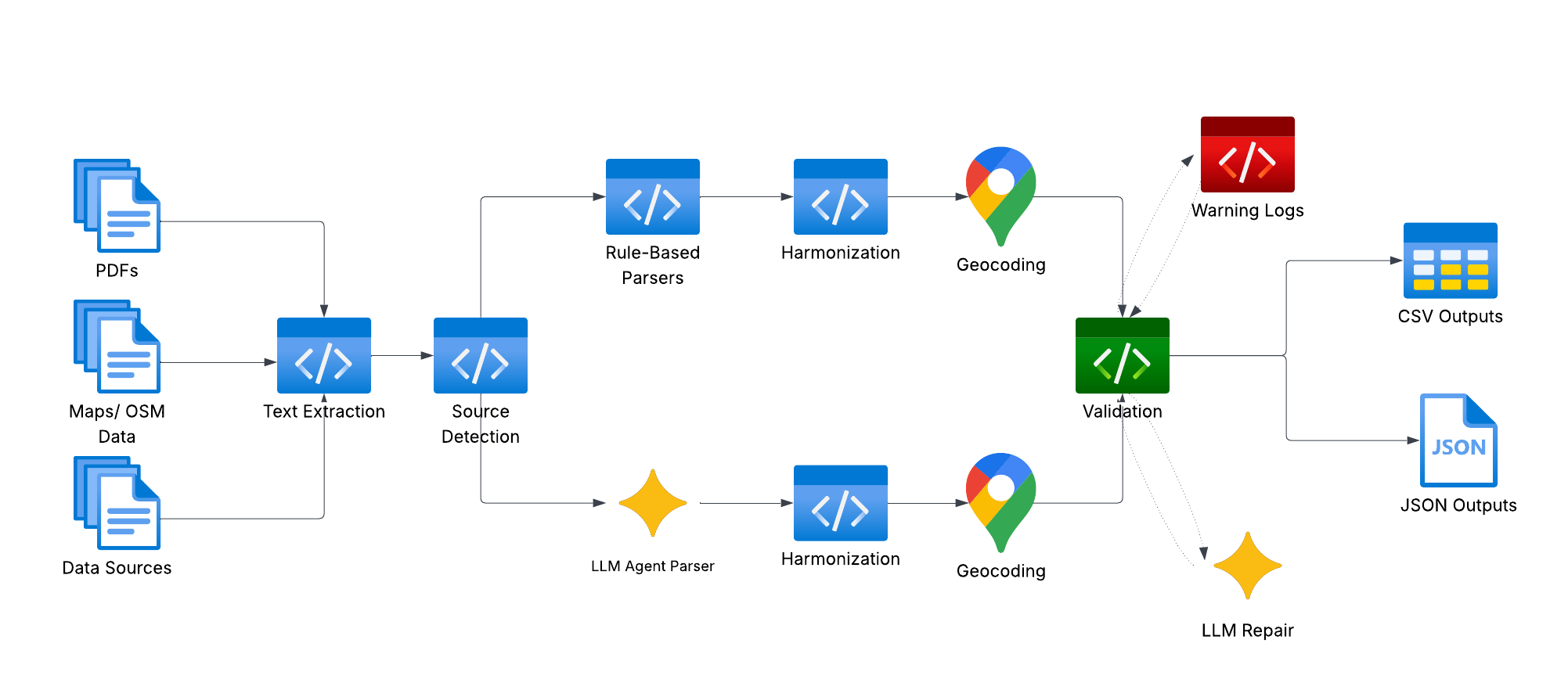
Figure 1: Dual-path system architecture showing parallel extraction pipelines and centralized harmonization, geocoding, and validation services.
Deterministic extraction leverages source-specific routings—form header detection, regex-based attribute mapping—for high-throughput document classes. The LLM extractor is schema-guided, narrowly tasked with JSON generation under prescribed constraints, invoked for narrative-heavy or irregular layouts. Both pathways utilize the identical downstream harmonization layer, geocoding service (converting ambiguous location strings into standardized coordinates via OpenStreetMap and caching), and schema validation for compliance and auditability.
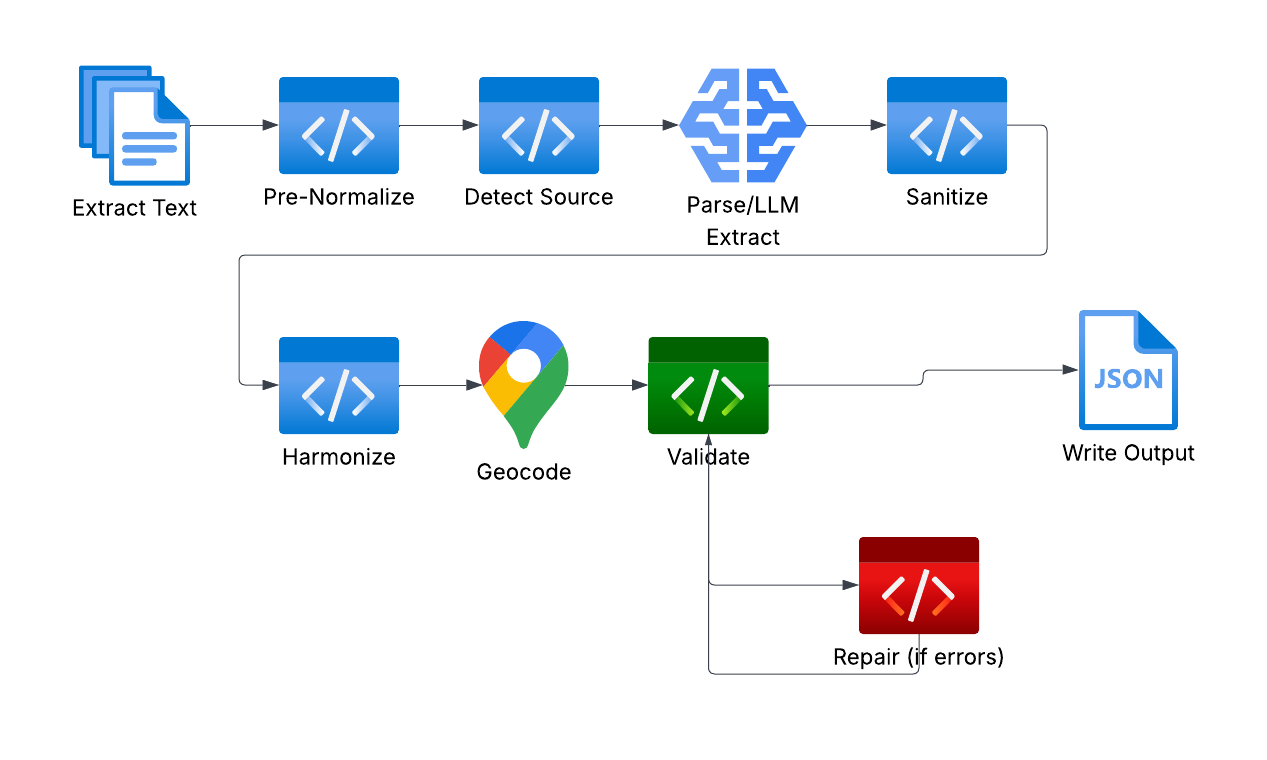
Figure 2: Core parsing and reasoning pipeline: extraction, harmonization, validation, and repair loop.
Implementation and Data Flow
The pipeline ingests PDFs originating from structured sources (NamUs, NCMEC, state bulletins) and narrative profiles (Charley Project, FBI poster scans). Text extraction employs a multi-engine cascade, falling back to OCR to maximize coverage for scan-heavy archives. Source detection is marker-driven, enabling adaptive parser selection based on repository conventions. Deterministic parsers rely on explicit label mappings, while the LLM-assisted pathway is activated for loosely structured narratives, constrained by prompt-engineered JSON schemas and context truncation.
Output artifacts are provided in both schema-aligned JSONL and flattened CSV, supporting programmatic ingestion and rapid human review. Each record is partitioned into demographic, spatial, temporal, narrative, outcome, and provenance blocks. Spatial grounding leverages geocoding, normalizing location mention into latitude/longitude required for downstream analytics.
Illustrative Example
A NamUs PDF form (Figures 3 and 4) demonstrates the pipeline’s operation. The document is subjected to text extraction, source detection (NamUs-specific headers), and routed to the corresponding parser. Fields are mapped—demographic descriptors, dates, spatial context, narrative circumstances—and harmonized.

Figure 3: Page 1 of a NamUs missing person document used as input to the pipeline.

Figure 4: Page 2 of the NamUs document, containing further case details.
Rule-based parsing yields structured records with explicit labels. LLM extraction recovers additional narrative-bound attributes, harmonizes field nomenclature, and ensures schema compliance. Spatial blocks are geocoded when explicit coordinates are absent. Validation checks guarantee record integrity; validator-guided repair is available for schema violations.
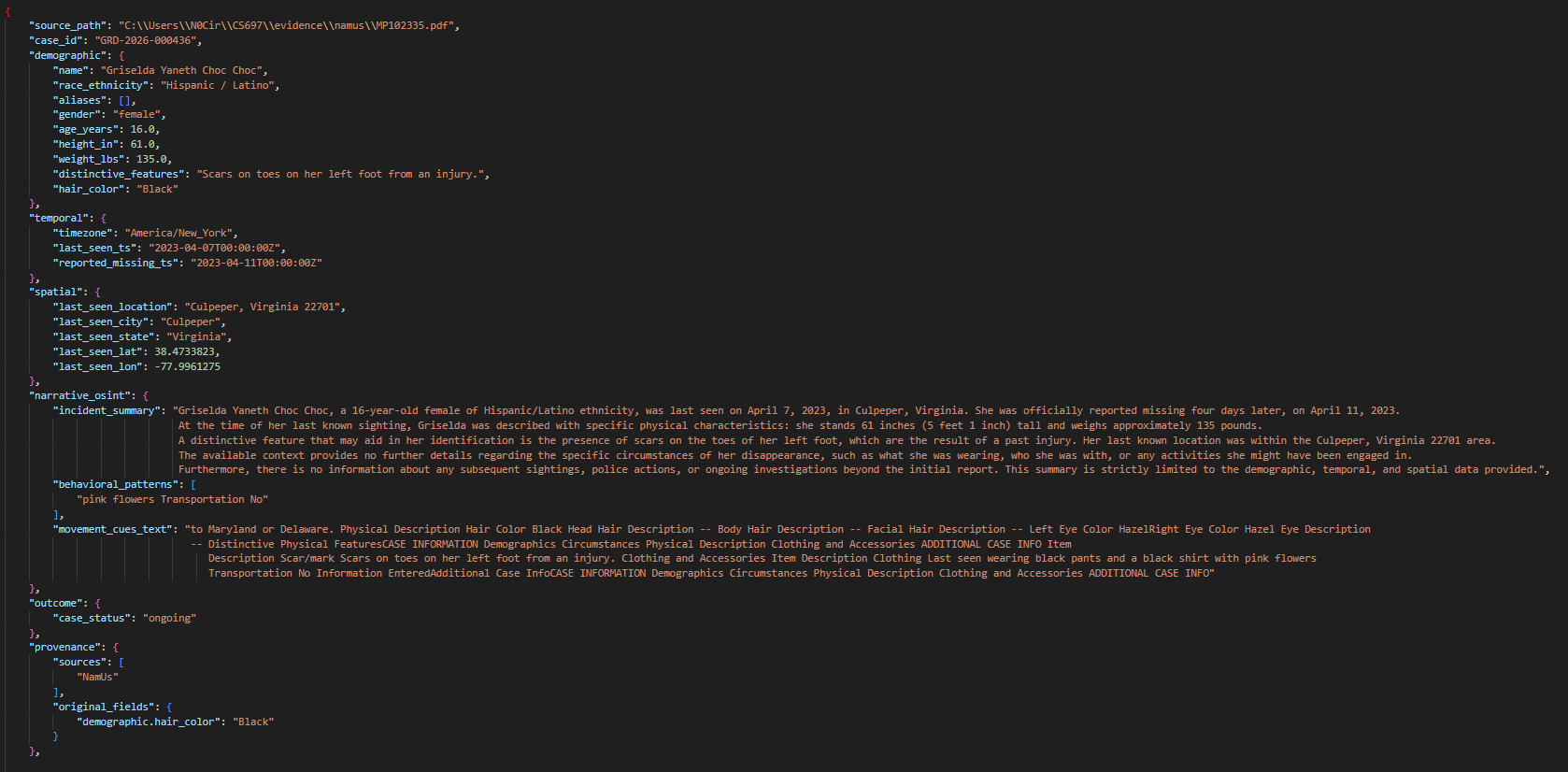
Figure 5: LLM parser path output as JSON: schema-aligned and including harmonized narrative and spatial data.
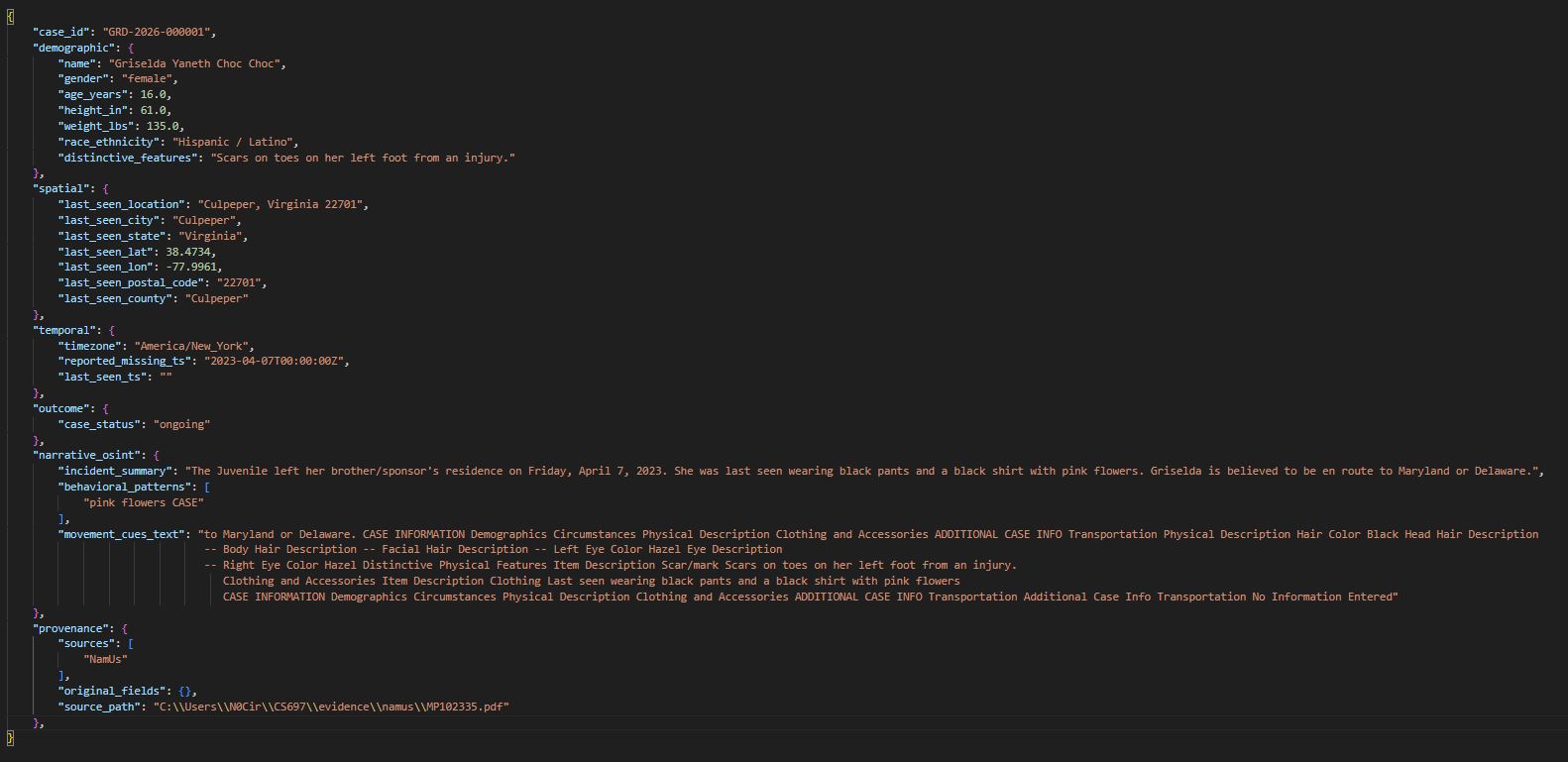
Figure 6: Rule-based parser path output for the same document, limited to explicit labels and less coverage in narrative fields.
Evaluation and Results
Rigorous quantitative evaluation was conducted using both gold-aligned extraction metrics and corpus-level operational indicators:
- Extraction Quality: On a hand-aligned subset of 75 cases, the LLM pathway outperformed deterministic parsing across all metrics—precision, recall, and F1 (all 0.8664 for LLM vs. 0.2593–0.2641 for deterministic). Structured field accuracy was 0.8810 for LLM, compared to 0.3090 for deterministic.
- Field Completeness: On 517 parsed records per pathway, the LLM-assisted path achieved higher key-field completeness (96.97%) than deterministic (93.23%). Geocoding succeeded for both pathways (100%), with plausible rates at 95.36% (LLM) vs. 94.78% (deterministic).
- Validation and Repair: All LLM outputs passed schema validation outright; no repair was triggered, underscoring the effectiveness of schema-first constraining.
- Performance: Deterministic parsing exhibited significantly lower latency (0.03 s/record) compared to LLM (3.95 s/record).
Design, Trade-offs, and Alignment with Research Questions
The Guardian Parser Pack addresses four core research questions:
- Extraction and Normalization (RQ1): Dual-path architecture, robust text acquisition, schema-driven harmonization, and coverage for both explicit and narrative forms.
- Validation and Provenance (RQ2): Central schema validation mitigates silent extraction errors; provenance preserved through source labeling and transformation tracking.
- Robustness and Auditability (RQ3): Layered fallback, conservative LLM usage, shared downstream services, and explicit warning reporting enable graceful degradation and consistent evaluation.
- Evaluation Trade-offs (RQ4): LLM pathway delivers high completeness and recall in narrative contexts, at the cost of latency; deterministic parsing is optimal for stable layout, high-throughput ingestion.
Implications and Future Directions
The Guardian Parser Pack fundamentally improves operational readiness for missing-person investigations by providing a reliable, auditable, and schema-consistent extraction pipeline suitable for downstream geospatial modeling and analytics. Practical implications include increased analytic fidelity in hotspot analysis, mobility forecasting, and search planning workflows.
The conservative integration of LLMs, constrained by schema validation and candidate status, aligns with ethical recommendations to minimize AI-induced harm in sensitive domains. The approach also reinforces the need for role-restricted LLM deployment, avoiding unbounded reasoning or judge behaviors in high-stakes settings.
Ongoing research should focus on enhanced uncertainty quantification, controlled weak supervision for labeled dataset construction, and tighter coupling with SAR mobility models propagating uncertainty through search forecast surfaces. Retrieval-augmented prompting and robustness to document drift remain core priorities for future system revisions.
Conclusion
The Guardian Parser Pack constitutes an auditable, schema-guided pipeline for unifying heterogeneous missing-person intelligence, achieving robust extraction quality across structured and narrative documents while preserving provenance and operational traceability. Dual-path extraction with centralized harmonization and validation, coupled with conservative LLM integration and validator-guided repair, enables reliable downstream analytics in investigative contexts. Performance results demonstrate significant gains in extraction completeness and recall for the LLM pathway, with transparent trade-offs in throughput and latency. The architecture provides a principled foundation for future work in uncertainty quantification, weak supervision, and integration with geospatial SAR modeling.

