- The paper introduces ScheMatiQ, a system that converts natural language research questions into evidence-grounded, structured datasets.
- It employs LLM-driven observation unit discovery and iterative schema induction validated by human experts to enhance extraction precision.
- Empirical results in legal and computational biology domains show high recall and perfect precision, demonstrating its scalability in data annotation.
ScheMatiQ: A Framework for Query-Driven, Interactive Schema Discovery and Structured Data Extraction
Overview
ScheMatiQ addresses a central bottleneck in empirical research across diverse fields: the transformation of natural-language questions into high-quality, structured datasets suitable for analysis. Traditional annotation pipelines require significant manual effort in schema design and data labeling, leading to scalability limitations and human error. ScheMatiQ systematizes this pipeline by leveraging LLMs to perform observation unit identification, schema induction, and extraction of evidence-grounded table entries, all orchestrated through a tightly integrated, interactive web interface for human-AI collaboration. This essay examines the core architectural decisions, evaluates empirical findings, and analyzes the implications for computational research workflows.
Architectural Principles and System Pipeline
ScheMatiQ operationalizes three primary principles: (1) explicit query-driven workflow, (2) actionable human-in-the-loop control at every pipeline phase, and (3) evidence-traceable extraction from large corpora.
The pipeline is structured as follows:
- Observation Unit Discovery: Given a research question and a corpus, ScheMatiQ queries an LLM to infer the atomic unit of analysis required to instantiate table rows (e.g., judge, experiment, protein). The system supports both model-generated and expert-guided specification of these units.
- Schema Induction: With the observation unit anchored, ScheMatiQ performs iterative LLM-driven analysis of document batches to expand and refine schema fields. Proposed attributes are ranked and rationalized with respect to their question-relevance, allowing domain experts to directly edit, merge, or excise fields, and to trigger further rounds of schema refinement as the corpus evolves.
- Structured Data Extraction: The discovered schema is populated via LLM annotation that is both multi-hop (covering observation units that are distributed across documents) and evidence-constrained (values are only extracted when explicitly supported by spans in the text). Each output cell pairs a value with provenance information, maximizing interpretability and downstream verifiability.
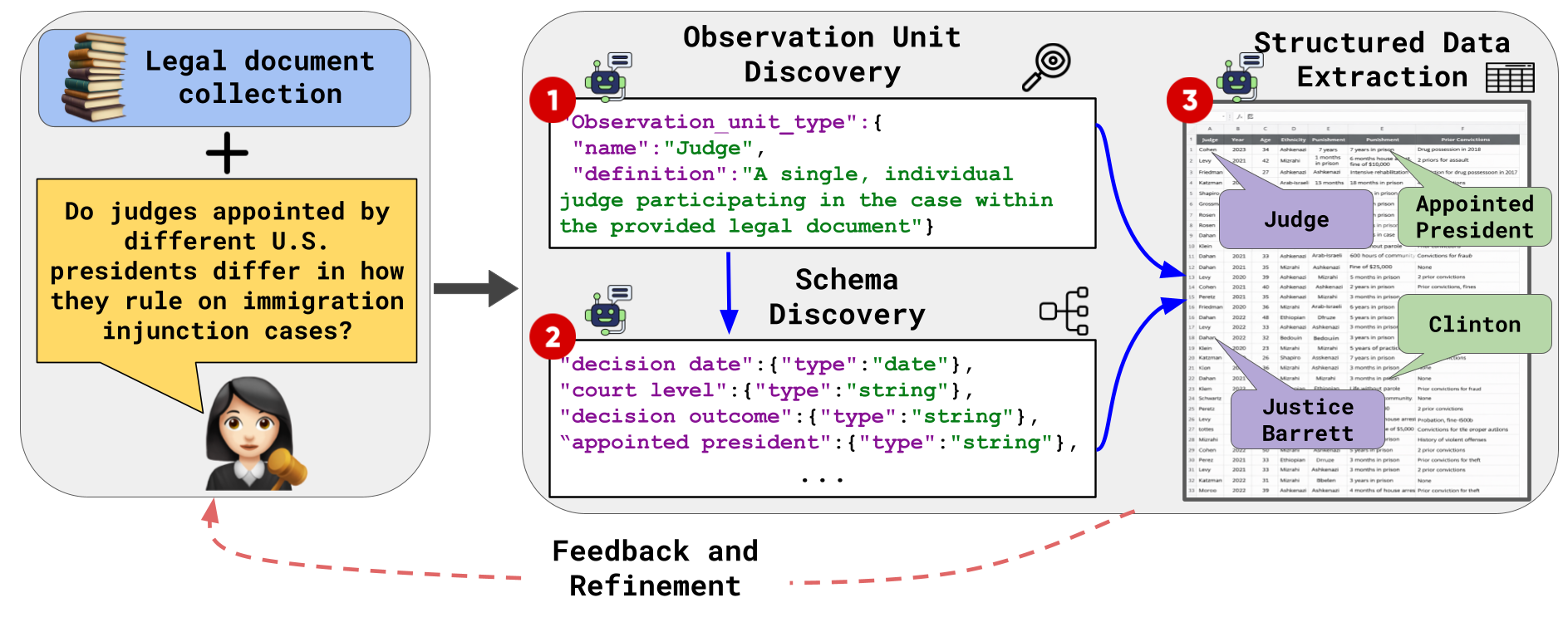
Figure 1: ScheMatiQ workflow: LLM-driven observation unit and schema discovery, followed by evidence-grounded structured extraction with expert feedback integration.

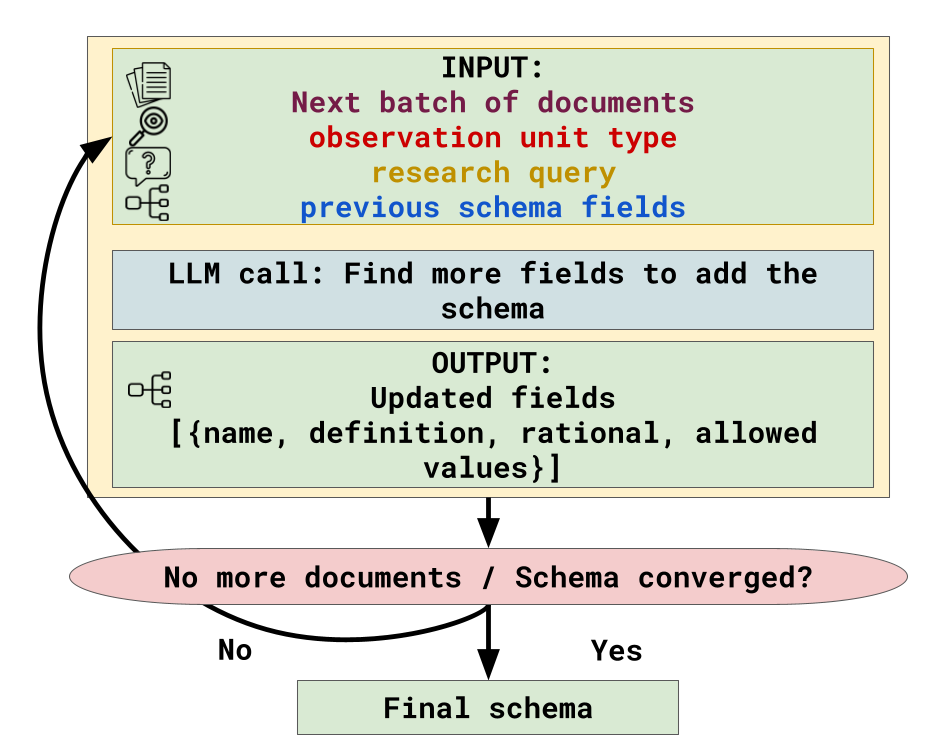
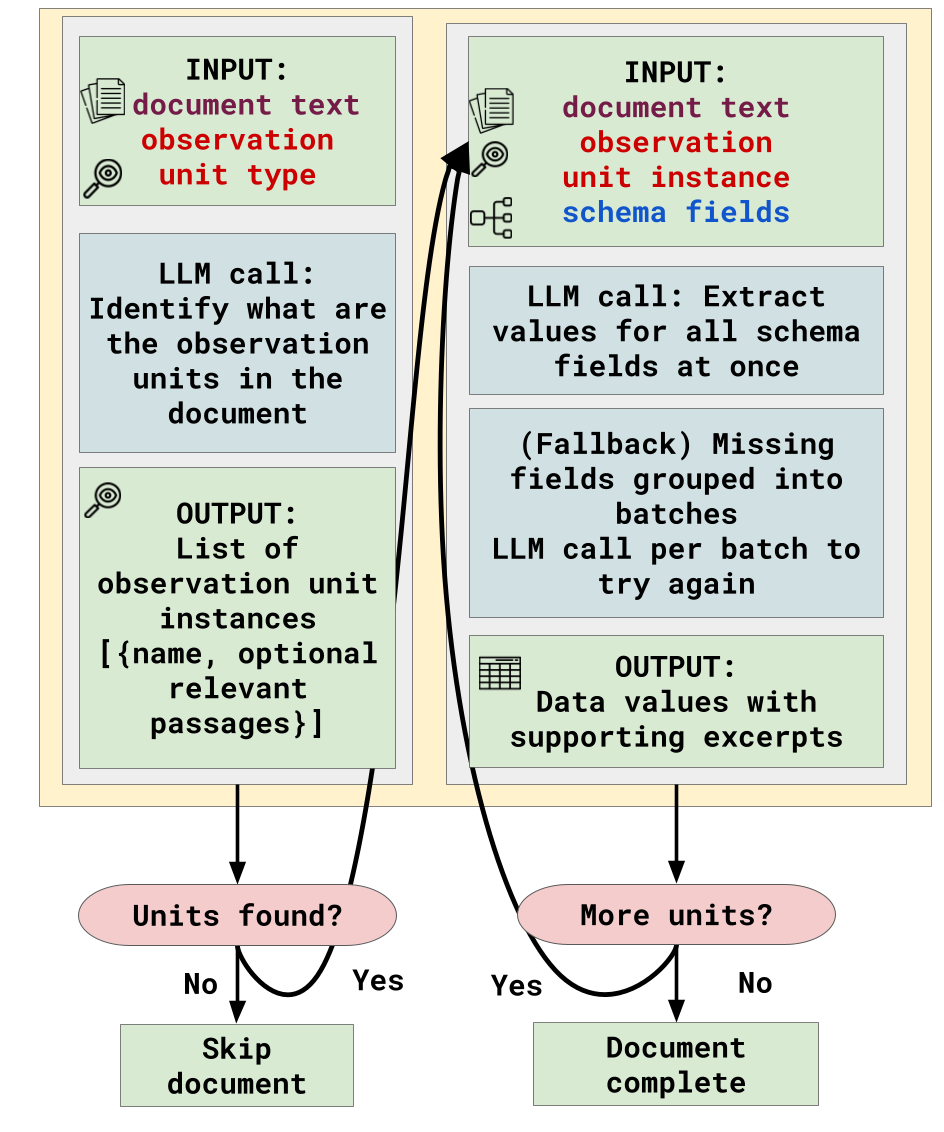
Figure 2: Flow diagram for observation unit discovery, illustrating the model-led and human-steered entity selection process.

Figure 3: ScheMatiQ web interface: configuration of queries, iterative schema review, and real-time table population, enabling fine-grained expert steering.
Empirical Evaluation
ScheMatiQ was empirically validated on two annotation benchmarks:
- Legal Research: Analysis of U.S. federal court decisions regarding immigration injunctions, reproducing and extending prior work that required extensive expert annotation of judges, appointing presidents, case context, and decision outcomes.
- Computational Biology: Extraction of protein-level evidence for the presence and characterization of nuclear export signals (NES) from NESdb scientific protocols.
Quantitative results demonstrate that ScheMatiQ recovers all but two broad, miscellaneous fields from gold-standard human schemas, while additionally surfacing new high-utility fields favored by experts. The supplementary fields proposed by ScheMatiQ received mean relevance ratings of 4.2/5 and 3.6/5 in computational biology and law, respectively.
In structured data extraction, ScheMatiQ achieves recall of 87% (proteins) and 74% (judges) with perfect precision in test cases. Error analysis indicates that nearly all false negatives are attributable to document-entity density, not misclassification or hallucination—a tractable avenue for further improvement.
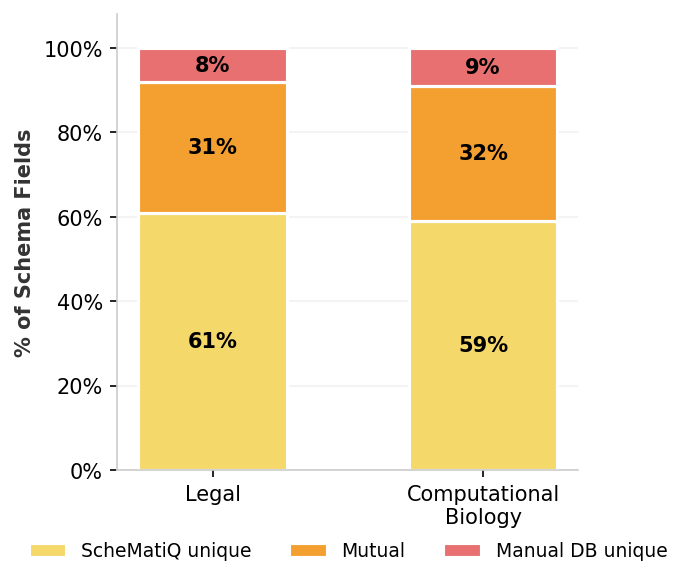
Figure 4: Schema-field coverage: proportion of gold, shared, and ScheMatiQ-unique attributes in legal and biology domains. New attributes (ScheMatiQ-only) received strong expert validation.
Ablation studies reveal that meaningful, question-specific schemas are not attainable from documents or questions in isolation; only the combined context yields fine-grained, research-aligned schemas. The system's effectiveness degrades significantly when the research question is omitted.
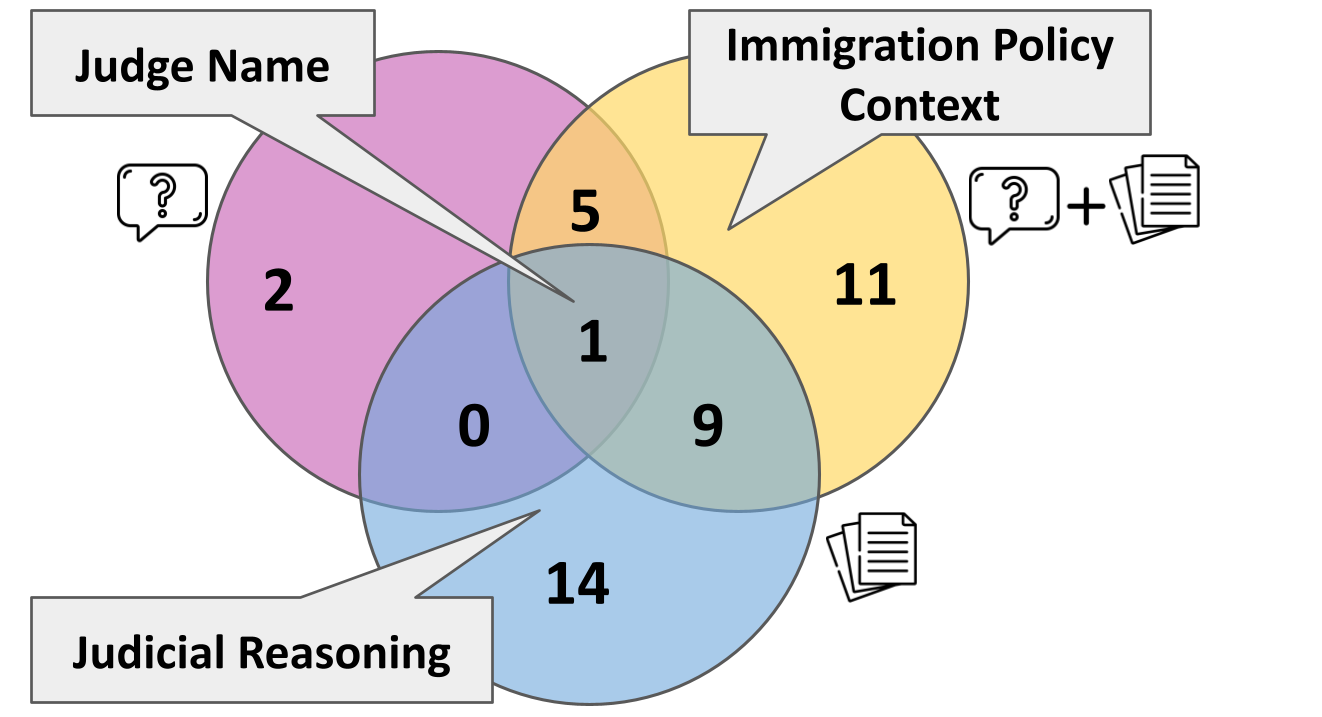
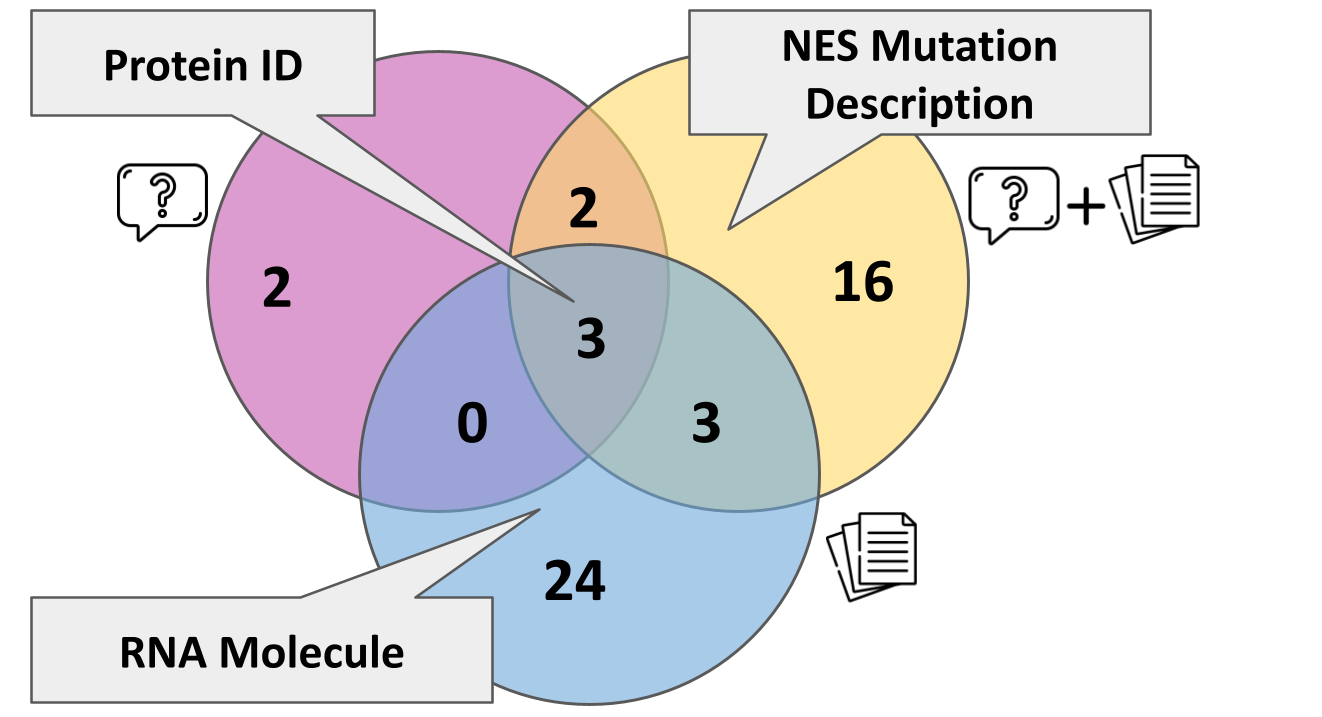
Figure 5: Venn diagrams of schema-field overlap in the legal domain demonstrate that only combined document-and-query contexts yield question-appropriate schema fields.
Workflow Flexibility and Human-AI Synergy
ScheMatiQ's web interface operationalizes actionable human-in-the-loop design, providing real-time streaming and full editability across all output artifacts. Experts can at any point alter the detected observation unit, add or prune schema fields, validate extracted values, or inject new evidence into the corpus. This iterative feedback process ensures the database is both model-efficient and domain-aligned.
Prompt engineering is core to the success of each pipeline stage. Simplified prompt structures were released for observation unit and schema discovery, demonstrating robustness and transferability with both proprietary APIs and open-weight models.

Figure 6: Sample LLM prompt structure for observation unit discovery, providing transparency and facilitating reproducibility.
Theoretical and Practical Implications
ScheMatiQ's design reorients schema discovery from static, pre-determined templates to dynamic, research question-conditional induction. By elevating the observation unit to first-class status, the system directly addresses prior limitations in context-agnostic schema generation, as seen in literature review table extraction and previous LLM-driven tabular summarization pipelines (2604.09237). The strict requirement for evidence-grounding also mitigates annotation hallucination, leveraging the latest advancements in long-context LLM architectures.
From a workflow perspective, the reduction in expert labor for schema design and data extraction vastly increases the scalability and reproducibility of empirical studies in fields where gold-standard annotation is a prohibitive bottleneck.
Future Directions
Several expansion paths are evident:
- Targeted refinement of extraction performance on high-entity-density documents via prompt engineering or cascade extraction.
- Comparative evaluation over additional domains such as medicine, history, policy analysis, and meta-scientific studies, using open-weight models to address reproducibility and privacy concerns.
- Leveraging ScheMatiQ-generated datasets as new benchmarks for long-context model development, joint inference, and few-shot schema induction research.
- Seamless integration with downstream statistical or causal analysis pipelines for automated research synthesis.
Conclusion
ScheMatiQ introduces a robust paradigm for question-driven, interactive schema discovery and grounded data extraction with full expert oversight. Its empirical results validate both its schema induction and extraction efficacy, supporting human researchers in transitioning from unstructured corpora to reliable, evidence-traceable datasets. The dual emphasis on question-sensitivity and human oversight marks a substantial practical advance for scalable, interpretable empirical research.