- The paper introduces an innovative annotation-driven retrieval paradigm that automates schema induction for precise, cost-effective document analysis.
- It leverages SchemaBoot to generate hierarchical, Pareto-optimal schemas, enabling deterministic SQL-like querying over structured indices.
- Empirical evaluations show a 12% improvement over baselines with an F1-score of 0.87, drastically reducing LLM token consumption.
AnnoRetrieve: Annotation-Driven Structured Retrieval for Unstructured Document Analysis
Motivation and Paradigm Shift
The proliferation of unstructured textual data across enterprise and web domains has created a significant bottleneck for information retrieval. Conventional retrieval pipelines—namely vector-based semantic search followed by LLM-driven extraction (“Retrieve-then-Extract”) and pre-emptive entity/relation extraction for knowledge graph construction (“Extract-All-then-Query”)—are increasingly insufficient. The former relies on dense embedding similarity and frequent LLM calls, yielding high cost and coarse granularity; the latter suffers from computational overhead and poor scalability. The paper introduces a third paradigm: annotation-driven retrieval, where structural annotation precedes retrieval, enabling schema-aware querying for enhanced precision and efficiency.
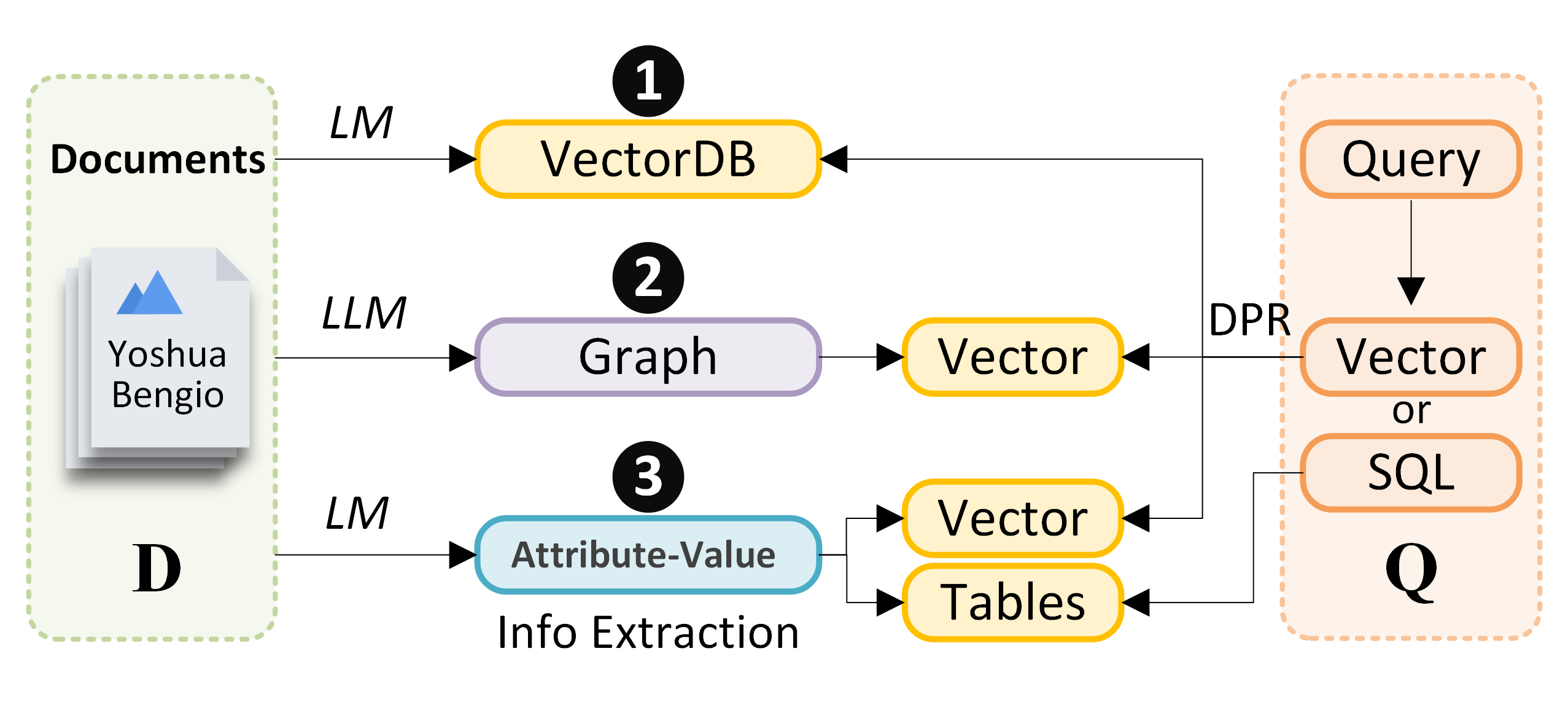
Figure 1: An architectural overview illustrating flows from raw documents to structured knowledge and hybrid query processing. Structured Semantic Retrieval achieves precise retrieval via semantic understanding combined with structured reasoning.
System Architecture and Pipeline
AnnoRetrieve operationalizes the annotation-driven paradigm through a modular pipeline:
- SchemaBoot: Employs multi-granularity semantic pattern mining and constraint-driven optimization to automate schema induction, discarding manual schema design.
- Annotator: Utilizes the induced schema with models like GliNER2 for high-fidelity attribute-value extraction and population of a structured index.
- Structured Semantic Retrieval (SSR): Executes SQL-like, schema-constrained queries over the structured index for precise, low-latency retrieval without LLM involvement at query time.
The transition from document corpus D to structured annotation store A under schema S radically redefines the retrieval function as R(q,A,S), emphasizing structural constraints over semantic similarity.
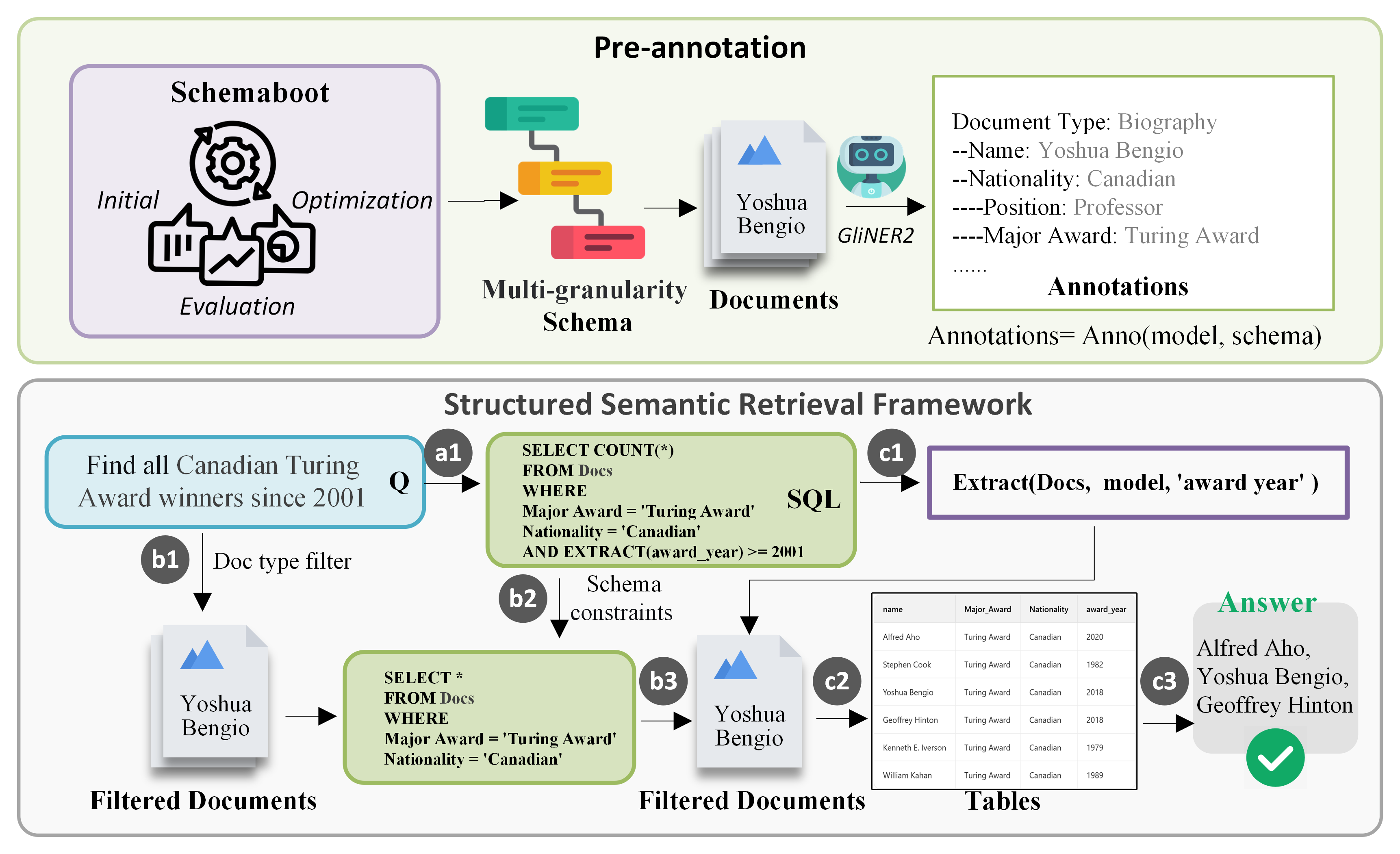
Figure 2: AnnoRetrieve's pipeline unifies automated schema-guided annotation and structured semantic retrieval, ensuring precise answers to complex queries via hybrid semantic-structured reasoning.
Schema Induction via SchemaBoot
SchemaBoot formulates optimal schema discovery as a constrained multi-objective optimization problem. It generates candidate schemas with hierarchical fields at multiple granularities (fast, semantic, detail), balancing document coverage, discriminative power, annotator consistency (via Fleiss' Kappa), and semantic alignment to historical queries. The Pareto-optimal schemas are evaluated under constraints (depth, branching factor, annotation time, storage overhead), and the selection is performed using NSGA-II. This process not only maximizes retrieval utility for the specific corpus and query profile but also mitigates redundancy and incomplete coverage seen with LLM- or manually-generated schemas.
Efficient Structured Annotation and Index Construction
With a high-quality schema in place, annotation is conducted via GliNER2, populating A as layered relational and document stores for different schema segments. Attribute-value pairs indexed in this way facilitate hybrid retrieval: rapid filtering by high-level fields and deep semantic matching or aggregation by detailed fields.
Structured Semantic Retrieval (SSR) Engine
SSR delivers hybrid query processing by parsing natural language queries into schema-bound constraints, which are translated into SQL predicates. Its core EXTRACT operator extends querying flexibility by allowing conditions on both annotated fields and unstructured content within a unified execution plan. Unlike vector-based methods, SSR evaluates queries directly over the structured store, achieving near-constant indexing time and scalable candidate filtering. Extraction for virtual or composite fields is performed by deterministic text scanning, obviating the need for costly LLM inference.
Empirical Evaluation
AnnoRetrieve is validated on three benchmark datasets (LCR, WikiText, SWDE), covering heterogeneous and complex document types. It is evaluated against baselines such as VectorDB, Graph RAG, ZenDB, Palimpsest, QUEST, ClosedIE, and direct LLM querying (GPT-4). On all datasets and query types, AnnoRetrieve achieves F1-score of 0.87, outperforming all baselines by at least 12% absolute (QUEST: 0.78, LLM: 0.72) while maintaining competitive latency and significant LLM token cost reduction.
Notably, Graph RAG and Palimpsest incur substantially higher upfront or query-time LLM invocation (over 200K tokens for complex join queries), underscoring the cost-efficiency gains from annotation-driven structuring. Ablation studies highlight the synergistic impact: removal of SchemaBoot or SSR causes F1-score drops (manual schema: 0.71; pure vector retrieval: 0.63), while unoptimized schemas inflate LLM cost (52K tokens vs. 29K). SchemaBoot achieves an induced schema F1 of 0.89, surpassing LLM-generated schemas (0.75), and schema cohesion/completion scores strongly correlate (ρ>0.85) with downstream retrieval performance.
Theoretical and Practical Implications
AnnoRetrieve establishes an actionable framework for efficient document intelligence by unifying schema-driven structuring and precise semantic-structured query execution. By shifting complexity to a single offline structuring phase, it enables scalable, high-precision retrieval for enterprise, legal, scientific, and web domains. The annotation-driven paradigm not only reduces LLM cost and latency but also supports progressively complex analytical reasoning (multi-entity joins, progressive SQL decomposition) that traditional methods cannot efficiently realize.
Key architectural features—automated schema optimization, hybrid indexing, and SSR—can be extended to support multi-modal data, federated retrieval, and continuous schema evolution. The demonstrated performance implies utility for next-generation database systems, RAG-driven QA pipelines, and AI-powered business intelligence.
Future Directions
Further research could address schema adaptation for dynamic corpora, integration with small-scale LMs for specialized annotation, and expansion to multimodal (image, audio) document collections. The SSR engine's progressive reasoning and hybrid querying could be leveraged for advanced analytics and explainability. Advancements in structured annotation algorithms and schema induction metrics will refine the paradigm's accuracy and scalability.
Conclusion
AnnoRetrieve introduces a principled, annotation-driven retrieval paradigm that transforms unstructured document analysis by prioritizing structure-aware querying over semantic similarity. Through automated schema induction and hybrid structured retrieval, it achieves superior accuracy, cost-efficiency, and scalability compared to SOTA baselines. The paradigm anchors future developments in AI-driven document analytics, emphasizing the centrality of intelligent structuring for robust, precise, and practical information retrieval (2604.02690).