Hybrid-Gym: Training Coding Agents to Generalize Across Tasks
Abstract: When assessing the quality of coding agents, predominant benchmarks focus on solving single issues on GitHub, such as SWE-Bench. In contrast, in real use, these agents solve more various and complex tasks that involve other skills such as exploring codebases, testing software, and designing architecture. In this paper, we first characterize some transferable skills that are shared across diverse tasks by decomposing trajectories into fine-grained components, and derive a set of principles for designing auxiliary training tasks to teach LLMs these skills. Guided by these principles, we propose a training environment, Hybrid-Gym, consisting of a set of scalable synthetic tasks, such as function localization and dependency search. Experiments show that agents trained on our synthetic tasks effectively generalize to diverse real-world tasks that are not present in training, improving a base model by 25.4% absolute gain on SWE-Bench Verified, 7.9% on SWT-Bench Verified, and 5.1% on Commit-0 Lite. Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9% on SWT-Bench Verified). Code available at: https://github.com/yiqingxyq/Hybrid-Gym.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building and training “coding agents” — AI programs that can read, explore, and modify code — so they can handle many different software tasks, not just one type. The authors create a new “training gym” called Hybrid-Gym. It’s like a practice arena filled with smart drills that teach the agent general, reusable skills such as finding code in big projects, thinking through problems, and making correct changes. Their goal is to help agents perform well on a variety of real-world tasks without overfitting to a single benchmark.
Key Objectives
The paper asks three simple questions:
- What do many real coding tasks have in common?
- Which skills should we teach so an agent can handle lots of different tasks?
- Can we design training tasks that are easy to build but still teach those valuable skills?
Methods and Approach
What is a coding agent?
A coding agent is an AI that can interact with a codebase (a project’s files), search for the right places to change, edit files, run commands, and check if its fixes work. Think of it like a helpful robot assistant that can navigate a giant library of code, find the book page it needs, and write in the margin to fix a mistake.
Breaking tasks into components
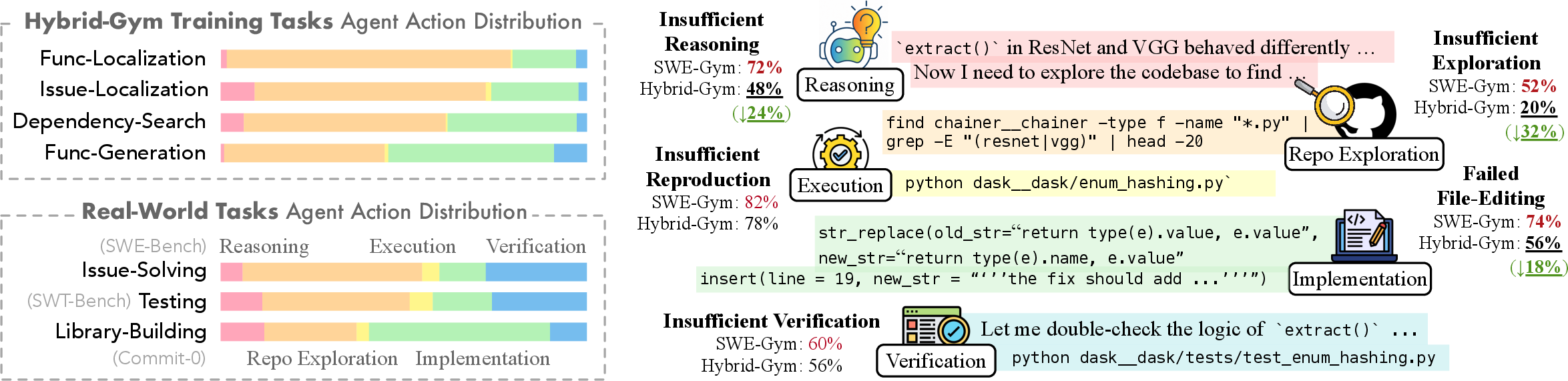
The authors looked at how agents solve coding problems and split the process into simple parts:
- Reasoning: thinking through the problem and planning a solution.
- Repository exploration: searching the codebase to find the right files or functions.
- Implementation: actually writing or editing code.
- Verification: checking if the solution works.
- Executing existing code: running tests or scripts already in the project.
They found that most actions across many tasks are spent on reasoning, exploring, and implementing — and these can be trained without fully setting up the project to run (which is hard and time-consuming).
The Hybrid-Gym training tasks
To teach those shared skills, the authors built four scalable training drills that don’t require complicated project setup but still feel like real coding work. Each drill ends with making a change in the code (like leaving a helpful comment or adding code), so the agent learns to produce “patches” — the same kind of output needed in real tasks.
These are the four drills:
- Function Localization: Given a short description, find the matching function in the codebase and add a docstring (a comment explaining the fix plan) to that function.
- Issue Localization: Given a real GitHub issue, locate the relevant file and add a comment with a plan to fix it.
- Dependency Search: Given a function, find all the functions/classes it directly calls and add comments in those spots. This teaches careful code reading and linking.
- Function Generation: Given a function’s description, re-implement the function body. To check if it works, they extract just the needed parts to a small script and generate tests for that script — much easier than setting up the entire project.
Why this approach? It matches how real coding works (make structured edits), includes exploration of a large codebase, and requires non-trivial reasoning — but avoids the heavy setup of making the whole project executable.
How training was done
- The team used stronger “teacher” AI models to generate successful solution steps (“trajectories”) for these tasks.
- Then they fine-tuned “student” models on those trajectories (this is called distillation — like a student learning from a teacher’s worked examples).
- They evaluated on three real benchmarks:
- SWE-Bench: fix real issues in open-source projects.
- SWT-Bench: generate tests.
- Commit-0: build or implement missing library features.
- They measured how often the agent produced correct fixes (resolved), edited the right file (localized), avoided getting stuck (non-loop), and succeeded on test generation and library tasks.
Main Findings and Why They Matter
- Training on Hybrid-Gym drills made agents perform much better on different real tasks, even though the drills didn’t directly train for those tasks. For example, on the big SWE-Bench Verified test, the 32B model improved by about 25 percentage points.
- Hybrid-Gym also improved performance on other tasks: about 8 percentage points on test generation (SWT-Bench Verified) and about 5 points on library building (Commit-0 Lite).
- Mixing Hybrid-Gym with in-domain datasets (data designed for a specific task) gave even better results. Hybrid-Gym teaches general skills (think, search, edit reliably), while in-domain data teaches task-specific patterns.
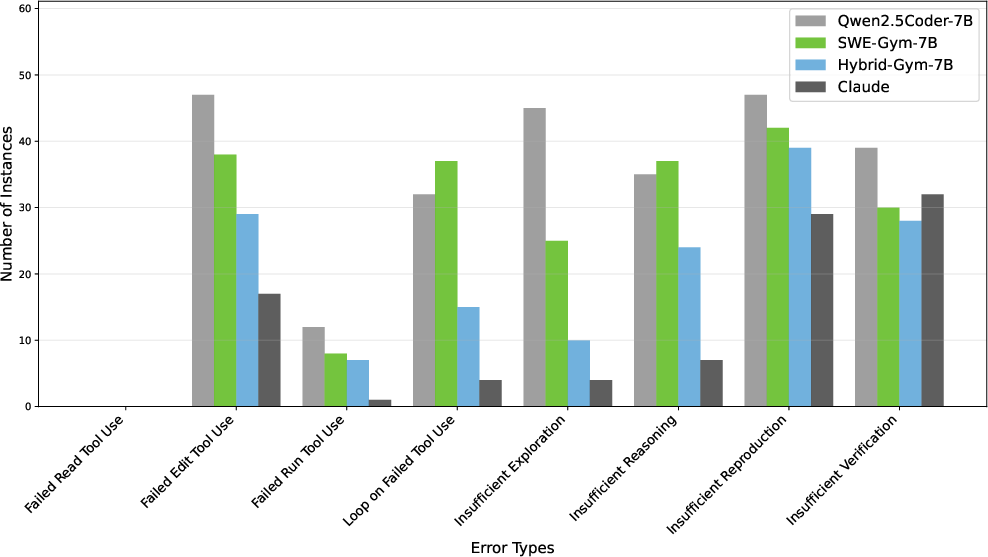
- The drills reduced common failures: not exploring enough, weak reasoning, and broken file editing. This helped the agent produce more correct, non-empty patches.
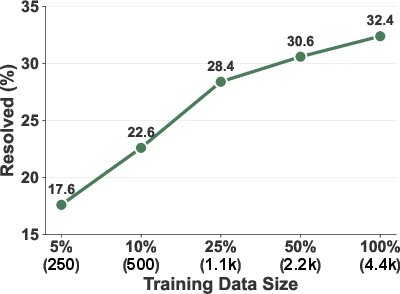
- Scaling helps: using more of these training trajectories keeps improving performance.
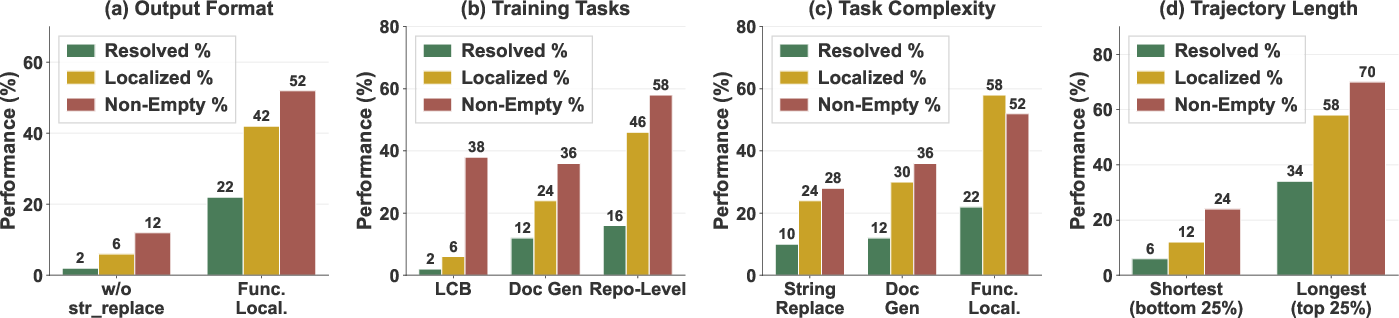
- Design principles matter:
- Output format should match the real tasks: agents must practice producing actual code patches, not just text explanations.
- Repo exploration is essential: script-only tasks don’t transfer as well to big codebases.
- More complex tasks and longer trajectories (more steps) help the agent learn deeper, reusable behaviors.
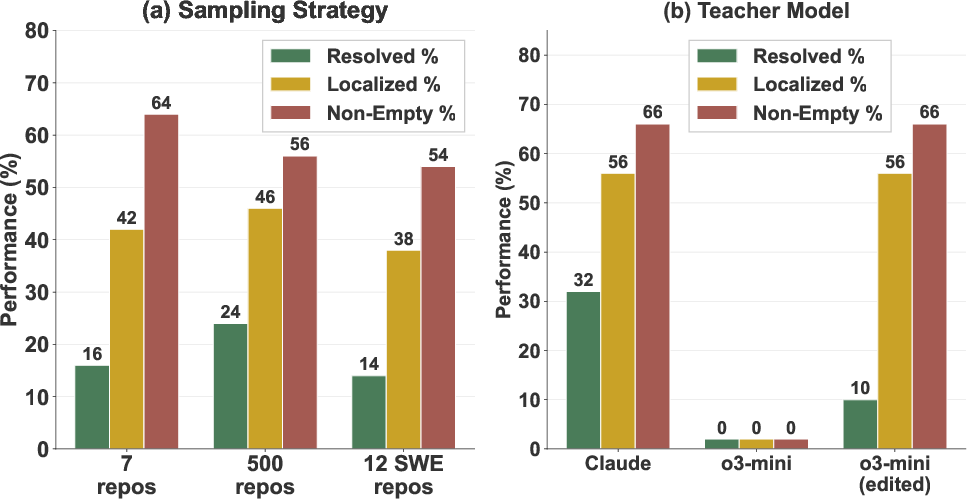
- Teacher choice and data sampling matter:
- Some teacher models structure their steps in ways that can hurt learning (e.g., separating thinking and action too much). Editing those trajectories to combine reasoning + action improved results.
- Training with diverse repositories is better than sticking to the same ones used in evaluation. Variety teaches general skills, not just project-specific tricks.
Implications and Impact
- Hybrid-Gym shows you can train coding agents to generalize using scalable, low-cost drills that avoid heavy project setup, yet still teach the hardest parts: thinking, searching, and editing.
- This makes it easier to build large training sets and keep improving agents over time.
- The approach helps bridge tasks: solving issues, writing tests, and building libraries all benefit from a shared core skill set.
- For developers and tool builders, this suggests focusing training on producing real patch-style outputs, exploring codebases, and non-trivial reasoning — not just single-file code generation.
In short, Hybrid-Gym is like a smart practice gym for coding agents. By drilling the right shared skills with the right structure, it teaches agents to be better “generalists” who can handle many kinds of software tasks — efficiently and at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items summarize what remains unresolved or only partially addressed in the paper and suggest concrete directions for future work:
- Limited language coverage: all tasks, tooling, and static analysis (Jedi) are Python-centric. Assess whether Hybrid-Gym transfers to other ecosystems (e.g., Java, JavaScript, C/C++) and replace/extend static analysis tooling beyond Python.
- Non-executable repository scope: training intentionally avoids full repo setup and runtime. Evaluate whether learned skills transfer to tasks that require building, installing, running tests, and debugging runtime failures at repository scale.
- Benchmark breadth and fidelity: results are reported on SWE-Bench Verified, SWT-Bench Lite/Verified, and Commit-0 Lite. Test on full Commit-0, additional agent benchmarks (e.g., SWE-Bench Pro/Multi-modal), and real-world developer prompts to strengthen external validity.
- Training method comparison: the work uses rejection sampling finetuning only. Compare SFT vs RL (e.g., DPO/RLAIF, offline/online RL), vs hybrid methods to quantify method-specific gains for task generalization.
- Teacher model selection and mixing: effects are shown for a few teachers (Claude, Qwen3, o3-mini) but no principled selection/mixing strategy is provided. Develop criteria and ablations for teacher choice, mixture weights, and consistency across teachers.
- Trajectory formatting sensitivity: separating reasoning and actions harmed transfer for o3-mini. Systematically study how rationale/action structuring, turn granularity, and tool-call density affect downstream learning and propose robust formatting guidelines.
- Data quality and labeling reliability: action/component categorization relies on o3-mini with limited manual checks (20 cases). Quantify inter-annotator agreement, label noise, and the impact of mislabeling on analyses and derived principles.
- Evaluation of function generation: RepoST-style extraction/testing may omit important project context. Measure how often extracted tests fail to capture real dependencies, and quantify test quality (coverage, mutation score, flakiness).
- Potential leakage in function generation: descriptions are produced from the original function before removal, enabling teacher recovery. Enforce stronger leakage controls (e.g., paraphrase or human-written specs, semantic obfuscation) and measure difficulty.
- Safety and negative side effects: improvements focus on resolved/non-empty patches; unintended edits, regressions, and maintainability are not assessed. Add rollback metrics, patch safety checks, and human code review evaluations.
- Multi-file and large-scale refactoring: str-replace-centric edits may underrepresent cross-file refactors, API changes, and project-wide consistency fixes. Introduce tasks requiring multi-file edits, VCS usage (git add/commit/revert), and coherent project-wide changes.
- Robustness to environment variability: only Linux/OpenHands tools are evaluated. Test across different agent scaffolds, shells, OSes (Windows/macOS), and toolsets (e.g., ripgrep, language servers) to assess portability.
- Memory and context limits: repo exploration over very large codebases (monorepos) and long-horizon reasoning are not analyzed. Stress-test token/context limits, indexing strategies, and persistent memory mechanisms.
- Active sampling and curriculum: while repo diversity helps, the optimal sampling across repositories, tasks, and trajectory complexity is not established. Explore active data selection, curriculum schedules, and task mixing strategies.
- Scaling beyond 4.4k trajectories: scaling laws are shown up to 4.4k; diminishing returns and inflection points are unknown. Extend scaling studies, estimate sample efficiency, and analyze cost-performance trade-offs.
- Cost accounting completeness: environment setup cost excludes LLM inference costs. Report full data curation/training budgets (tokens, wall-clock, GPU hours) to enable reproducibility and fair comparisons.
- Variance and statistical confidence: confidence intervals, seed variability, and run-to-run stability are not reported. Provide statistical analyses for all benchmarks to assess robustness of gains.
- Ground truth for issue localization: evaluation checks “same file as actual fix,” which can be ambiguous and noisy for arbitrary issues. Improve ground truth construction (e.g., linking commits to issues, precise line-level localization) and quantify label noise.
- Generalization to test authoring specifics: SWT-Bench improvements are reported, but which test-writing competencies (fixtures, parametrization, assertions, mocking) improved remains unclear. Add fine-grained test quality metrics and error taxonomies.
- Human-in-the-loop validation: user studies with developers and longitudinal real-world deployments are missing. Evaluate productivity gains, iteration speed, and trust in agent outputs with practitioner feedback.
- Integration with real workflows: PR generation, commit hygiene, CI integration, and code review interaction are not assessed. Add tasks and metrics aligned to common workflows and CI pipelines.
- Automated task discovery: principles are proposed, but a systematic method to generate new high-transfer tasks is not provided. Develop automatic task synthesis pipelines guided by transferability predictors or meta-learning.
Practical Applications
Overview
The paper introduces Hybrid-Gym, a scalable suite of synthetic, repository-level training tasks for coding agents that emphasize transferable skills such as reasoning, repository exploration, and patch-based code editing. The tasks—function localization, issue localization, dependency search, and function generation—avoid heavy environment setup while matching the output formats of real-world downstream tasks. Empirically, Hybrid-Gym substantially improves task generalization across SWE-Bench (issue resolution), SWT-Bench (test generation), and Commit-0 (library build), and offers actionable principles for designing effective training data and workflows.
Below are practical, real-world applications derived from the paper’s findings, organized by time horizon. Each bullet highlights sectors, tools/products/workflows, and feasibility assumptions.
Immediate Applications
These applications can be deployed now with existing tools and infrastructure.
- Improved fine-tuning pipelines for coding agents on scalable, synthetic repo-level tasks (software)
- What: Use Hybrid-Gym’s tasks (function/issue localization, dependency search, function generation) to post-train agents via rejection sampling finetuning (RSF), boosting generalization across diverse coding tasks.
- Tools/Workflows: OpenHands-like agent scaffolds;
grep/find/cd/ls-centric repo exploration; patch-based editing (str_replace); static analysis (Jedi) for dependency resolution; adapted RepoST-style test script extraction. - Assumptions/Dependencies: Access to LLMs capable of tool use (e.g., Qwen2.5Coder, Claude), Python-heavy repos, reproducible docker images, licensing-compliant repositories, basic CI to apply/evaluate patches.
- Repository exploration assistants for large codebases (software; education)
- What: Deploy assistants trained on Hybrid-Gym to locate functions, issues, and dependencies across large repos—useful for onboarding new engineers or students.
- Tools/Products: “Repo Explorer Assistant” that automates navigation and searches; docstring generation for plan-of-fix comments.
- Assumptions: Patch-friendly workflows; read access to repos; basic static analysis; agent tool-calling enabled.
- Triage support for GitHub issues with patch-oriented plans (software; open-source operations)
- What: Use issue localization to attach actionable fix plans directly in relevant files, improving triage precision and developer throughput without executing full test suites.
- Tools/Workflows: Automated localization pipelines plugged into GitHub Actions; labeling and routing to the right teams; patch preview on PRs.
- Assumptions: Maintainers approve patch-oriented comments; safe write access to branches; governance for agent-suggested edits.
- Lightweight dependency mapping for impact analysis and change reviews (software; DevOps)
- What: Automate the identification of direct function/class dependencies to inform code reviews, refactoring, and risk analysis in CI.
- Tools/Products: “Dependency Mapper” step in CI pipelines that annotates touched functions/classes; static analysis with Jedi; PR risk scoring.
- Assumptions: Python codebases or suitable static analyzers for other languages; guardrails for noisy or ambiguous resolutions.
- Isolated test generation for specific functions without repo installation (software QA/testing; education)
- What: Adapt RepoST-style scripts to extract function and dependencies, then generate tests that can execute with minimal package installation.
- Tools/Workflows: Test script generator for targeted regression tests; integration into PR checks; teaching aids for unit-test practice.
- Assumptions: Functions and their imports can be resolved; minimal package installs supported; unit-test runner setup in CI.
- Patch-format enforcement in agent outputs to reduce “chat-only” drift (software)
- What: Train or constrain agents to produce patch outputs (diff-like edits) rather than purely conversational plans, aligning with downstream tasks (SWE-Bench, SWT-Bench).
- Tools/Products: “Patch-only agent” wrapper; output contracts in tool-calling APIs; validators that reject non-patch outputs.
- Assumptions: Teams accept patch-based interactions; editor integrations (IDE/PR) support diffs; policy for reviewing auto-edits.
- Trajectory editing and teacher selection utilities (software; MLOps)
- What: Edit trajectories to stitch rationale+action steps (avoiding “think-only” turns) and select diverse teacher models to improve distillation effectiveness.
- Tools/Products: “Trajectory Editor” to merge adjacent thought/action; “Teacher Sampler” to mix Claude/Qwen3 outputs; monitoring dashboards for error categories.
- Assumptions: Access to teacher outputs; logs retain tool calls; privacy-compliant data handling.
- Data sampling strategies to maximize repo diversity for better generalization (software; MLOps)
- What: Prefer sampling across many repositories rather than many instances from few repos; do not over-index on evaluation repos.
- Tools/Workflows: “Sampling Planner” that enforces max-diversity sampling; curriculum scheduling by repository coverage.
- Assumptions: Repository corpus availability; metadata tracking; compute budget to handle diverse contexts.
- Education: practical labs on repo-level reasoning and tool use (education)
- What: Use Hybrid-Gym tasks as coursework for repository exploration, function localization, and patch generation to teach students agentic coding.
- Tools/Products: Classroom exercises with controlled repos; grading scripts that check patch application and dependency annotations.
- Assumptions: Managed compute environment; safe sandboxes; academic licenses for datasets.
- Research: task transfer evaluations and controlled ablation frameworks (academia)
- What: Reproduce studies on output format matching, repo exploration necessity, trajectory complexity, and scaling laws; propose new Hybrid-Gym-compatible tasks.
- Tools/Workflows: OpenHands-style harness; o3-mini/o3-based categorization of actions; ablation suite that varies format, complexity, and trajectory length.
- Assumptions: Access to benchmarks (SWE-Bench, SWT-Bench, Commit-0); reproducible docker images; teacher models for data generation.
Long-Term Applications
These applications require further research, scaling, or development before broad deployment.
- General-purpose, robust coding agents for multi-stage engineering workflows (software; enterprise)
- What: Agents capable of issue resolution, test generation, refactoring, and library building across heterogeneous repos and languages, with consistent patch outputs.
- Potential Products: “Enterprise Coding Copilot” that integrates with IDEs, PRs, CI/CD, and change management workflows.
- Dependencies: Cross-language static analysis; stronger tool-calling reliability; safety and audit trails; organizational buy-in for agentic edits.
- Automated maintenance and refactoring bots at scale (software; DevOps; finance/healthcare/energy compliance)
- What: Bots that proactively localize issues, map dependencies, propose patches, and generate tests under regulatory and security constraints (e.g., PII handling, SOX).
- Tools/Workflows: Policy-aware agents; security scanning integrated with fix planning; staged rollout with canary testing and rollback.
- Assumptions: Mature risk controls; robust patch validation; change approval workflows.
- Standardization of patch-first agent output formats and tool-calling APIs (policy; software)
- What: Industry standards for patch-format outputs, tool-calling contracts, provenance, and auditability to reduce ambiguity and improve safety.
- Tools/Products: Patch schema spec; auditing middleware; compliance checkers for agent-generated diffs.
- Dependencies: Multi-stakeholder collaboration; legal and compliance frameworks; open tooling.
- Cross-language extensions and domain-specific static analysis (software; robotics; embedded systems)
- What: Extend Hybrid-Gym principles to Java, C/C++, Rust, and domain-specific languages, including robust dependency resolution beyond Python.
- Tools/Workflows: Language-agnostic analyzers; adapters for build systems; repository setup strategies for complex monorepos.
- Assumptions: Availability of analyzers; reliable multi-language tool-chains; dataset curation.
- Curriculum learning and adaptive data selection for agent training (academia; MLOps)
- What: Automatic curricula that progress from simple patch edits to complex multi-file reasoning; adaptive sampling to maximize learning signals (e.g., long trajectories).
- Tools/Products: “Curriculum Scheduler” integrated with training; trajectory quality scoring; human-in-the-loop vetting.
- Dependencies: Reliable metrics for learning signal; scalable training infrastructure; teacher diversity.
- Self-supervised or RL-enhanced agent training on synthetic and real repos (academia; software)
- What: Move beyond RSF to reinforcement learning or self-play tasks that improve tool use, exploration strategies, and robustness.
- Tools/Workflows: Reward shaping for patch correctness/non-loop behavior; sandboxed repos; large-scale synthetic corpora.
- Assumptions: Safe and reproducible environments; cost-effective training; reliable automatic evaluation.
- Agent governance and change management policies for enterprise adoption (policy; software)
- What: Formal policies for agent access controls, patch approvals, traceability, rollback mechanisms, and accountability.
- Tools/Products: “Agent Governance Toolkit” integrated with DevSecOps; observability dashboards; incident response for agent errors.
- Dependencies: Organizational standards; legal/regulatory acceptance; cultural change management.
- IDE-native, real-time repo exploration copilots with patch previews (software; education)
- What: Agents embedded in IDEs that propose localized edits with live diffs, dependency annotations, and test suggestions.
- Tools/Products: IDE plugins; contextual patch validators; “Explain-My-Edit” for learning.
- Assumptions: Stable APIs; UX research; performance guarantees.
- Data markets for synthetic, repo-level trajectories and evaluation harnesses (software ecosystem)
- What: Curated, license-compliant datasets with diverse repositories, tasks, and teacher trajectories; standardized evaluation harnesses.
- Tools/Products: Dataset hubs; reproducible docker images; scoring frameworks.
- Dependencies: Community contribution; licensing clarity; sustainability models.
- Sector-specialized agents for regulated environments (healthcare, finance, energy, robotics)
- What: Agents trained with Hybrid-Gym-style tasks tailored to domain codebases (e.g., HL7/FHIR pipelines, trading systems, SCADA integrations), focusing on safe patch generation and dependency-aware changes.
- Tools/Workflows: Domain-specific static analyzers; compliance-aware patch validation; test generation constrained by regulatory rules.
- Assumptions: Domain datasets; policy alignment; safety and reliability guarantees.
Key Assumptions and Dependencies Influencing Feasibility
- Access to capable teacher models and agent scaffolds (e.g., Claude, Qwen; OpenHands).
- Patch-format outputs must match downstream expectations; agents need reliable tool-calling.
- Static analysis availability (currently strong for Python; weaker for some languages).
- Low-friction environment setup (Hybrid-Gym advantage: minimal docker images and minimal package installs).
- Repository diversity in training data is crucial; training only on evaluation repos is not sufficient.
- Organizational acceptance of agent-generated patches and governance for change management.
- Security, compliance, and auditability requirements (especially in regulated sectors).
- Benchmark-driven evaluation (SWE-Bench, SWT-Bench, Commit-0) and consistent metrics (resolved, localized, non-loop).
Glossary
- Agent scaffold: A framework that provides the tools and interfaces an agent uses to interact with an environment. "using OpenHands as the agent scaffold~\cite{openhands}"
- Agentic frameworks: Systems or scaffolds enabling agents to plan and act through tool-mediated interactions. "which only requires seq-to-seq generation, without any agentic frameworks"
- Code patch: A set of changes applied to a codebase to modify or fix functionality. "the format is generating a code patch in the codebase, which requires file editing."
- Dependency search: Identifying functions or classes directly called by a given function within a codebase. "such as function localization and dependency search."
- Distillation-based training: A method where a student model learns from trajectories or outputs produced by a stronger teacher model. "Under the setting of distillation-based training, a training task is useful only if there is a performance gap between the student and teacher models"
- Docstring: A documentation string placed within code to describe functionality or plans. "we require the agent to write a docstring containing the fix plan."
- Docker image: A portable package containing software and dependencies used to create reproducible environments. "requires only 2 docker images to build all training instances."
- Downstream tasks: Target tasks used to evaluate the transfer and effectiveness of training, distinct from the training tasks themselves. "Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9\% on SWT-Bench Verified)"
- Executable repository: A code repository set up so its tests or programs can be executed (e.g., with packages installed). "setting up executable repositories is often viewed as a prerequisite for constructing training examples."
- execute-bash: An agent tool for executing shell commands within the environment. "The tools built for the OpenHands agent~\cite{openhands} include bash command execution (execute-bash), file viewing (view), and file editing (str-replace)."
- Function generation: A task requiring the agent to implement a function body based on a description. "we design the function generation task that requires actual code generation."
- Function localization: Finding the specific function in a codebase that matches a description or target behavior. "Function localization aims to locate the code based on the description"
- Issue localization: Identifying the file or code region related to a problem described in an issue. "issue localization locates the problematic code based on an issue."
- Jedi: A static Python analysis tool used to resolve names to their defining modules. "we adopt Jedi, a static Python analysis tool, to resolve imported names to their defining modules."
- LiveCodeBench (LCB): A script-level code generation benchmark focusing on single-file function generation. "we implement a script-level task, LiveCodeBench (LCB) \cite{livecodebench}, which primarily evaluates function generation in a single file."
- Localized rate: The percentage of generated patches applied to the correct file. "the localized rate: the percentage of code patches applied to the correct file"
- Non-loop rate: The percentage of trajectories that do not repeat the same action three times consecutively. "the non-loop rate: the percentage of trajectories without any ``loops'', which is defined as repeating the same action three times consecutively~\cite{swegym}"
- OpenHands: An open-source coding agent framework offering tools for repository interaction. "The tools built for the OpenHands agent~\cite{openhands} include bash command execution (execute-bash), file viewing (view), and file editing (str-replace)."
- Patch-like outputs: Outputs structured as concrete edits applied to code, akin to patches. "the production of patch-like outputs is not a superficial formatting choice but a crucial skill that the agent needs to learn."
- Rejection sampling finetuning: A training approach that finetunes on successful sampled trajectories while rejecting unsuccessful ones. "we adopt the rejection sampling finetuning setting"
- Repo-exploration: Navigating and searching a repository to locate relevant files and code segments. "We observe that a large number of actions in successful trajectories are spent on reasoning, repo-exploration, and implementation."
- Repository diversity: Variety in the set of repositories used for training, which can enhance generalization. "Repository diversity improves training effectiveness, but training on the same repositories used in evaluation does not inflate performance gains."
- Scaling law: Empirical relationship showing performance improvements as training data or model size scales. "Scaling law analysis."
- Seq-to-seq generation: Sequence-to-sequence modeling used to generate outputs from inputs without interactive tools. "which only requires seq-to-seq generation, without any agentic frameworks"
- Static Python analysis: Analyzing Python code without executing it to infer dependencies or resolve names. "we adopt Jedi, a static Python analysis tool, to resolve imported names to their defining modules."
- str-replace: An agent tool to edit files by replacing strings at specified locations. "file editing (str-replace)."
- SWE-Bench Verified: A benchmark split evaluating issue resolution on curated GitHub repositories with verification. "improving a base model by 25.4\% absolute gain on SWE-Bench Verified"
- SWT-Bench Verified: A benchmark evaluating test generation with verified outcomes. "improving a base model by 25.4\% absolute gain on SWE-Bench Verified, 7.9\% on SWT-Bench Verified"
- Teacher model: A stronger model whose trajectories or outputs supervise a student model during distillation. "the teacher model (Claude-Sonnet-4.5, \citet{claude45})."
- Tool API: The interface through which agents invoke tools during interaction with the environment. "we wrap the coding template and test script in LCB in a dummy repository so that the model interacts with the same harness and tool API."
- Trajectory: A sequence of agent actions and states recorded while solving a task. "successful trajectories are spent on reasoning, repo-exploration, and implementation."
Collections
Sign up for free to add this paper to one or more collections.

