- The paper introduces a three-stage asynchronous sensor pipeline model for accurate energy attribution across heterogeneous exascale architectures.
- It employs a derivative-based method to reconstruct instantaneous power, aligning energy consumption with application events.
- The study highlights significant energy efficiency improvements, informing runtime adaptation and system co-design for AMD platforms.
Fine-Grained Power and Energy Attribution on AMD Exascale Nodes
Introduction
This essay offers an in-depth analysis of "Fine-Grained Power and Energy Attribution on AMD GPU/APU-Based Exascale Nodes" (2604.06056). The work addresses significant challenges inherent in high temporal and spatial attribution of power and energy usage on heterogeneous exascale systems, focusing particularly on AMD’s MI250X (Frontier) and MI300A (Portage) platforms. The study presents a methodologically rigorous approach for sensor characterization, signal reconstruction, and region-level attribution, with implications for practical application profiling, system co-design, and runtime adaptation for power efficiency.
Sensor Pipeline Model and Measurement Challenges
Fielding multiple telemetry sources—ranging from fine-grained on-chip counters (rocm-smi/amd-smi) to board-level and node-level Cray Power Management (PM) sensors—the heterogeneity in spatial scope, update rate, latency, averaging/filtering, and timestamp semantics severely impedes the task of accurate energy attribution. The authors introduce a three-stage asynchronous model that decouples (i) hardware sensor acquisition, (ii) driver/sysfs refresh/publication, and (iii) application-layer sampling.
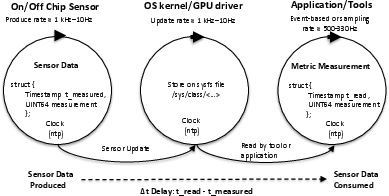
Figure 1: Three asynchronous stages for sensor measurement, driver refresh, and tool sampling induce observable lag and complexity in cache coherence and timestamp assignment.
This abstraction enables clear delineation of sensor-intrinsic lag (Δt), latency between measurement and usability by software, and sources of cache/miss artifacts in metric time series.
Sensor Characterization and Derived Power
The authors rigorously quantify response dynamics including sensor delay, response/rise time, and recovery/fall time using synthetic workloads with deterministic power transitions. Native sensor interfaces (e.g., rocm-smi power) typically report heavily smoothed data, thereby hiding short-lived events and introducing temporal distortion at scale.
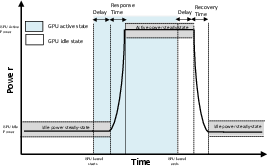
Figure 2: GPU power sensor illustrates delayed, smoothed signal transitions due to hardware and software-level filtering—impairing ability to precisely localize actual computation intervals.
In contrast, the paper’s core methodological advancement is reconstructing instantaneous power (Pinst) through explicit differentiation,
Pinst(i)=ΔtE(i)−E(i−1)
where E is the cumulative energy counter. This streaming ΔE/Δt technique sharply enhances the alignment of phase transitions with application events, significantly mitigating the deleterious impact of internal low-pass filtering.
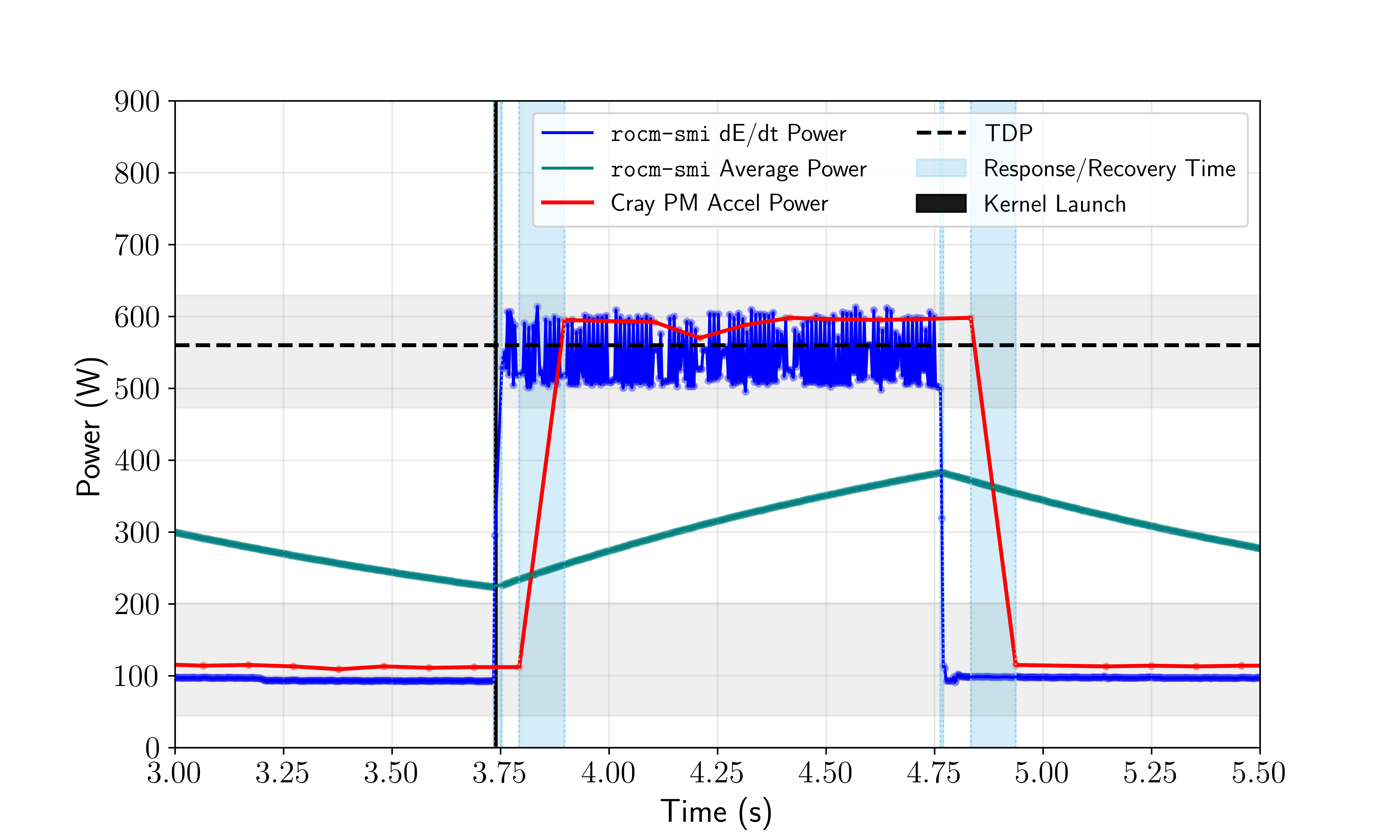
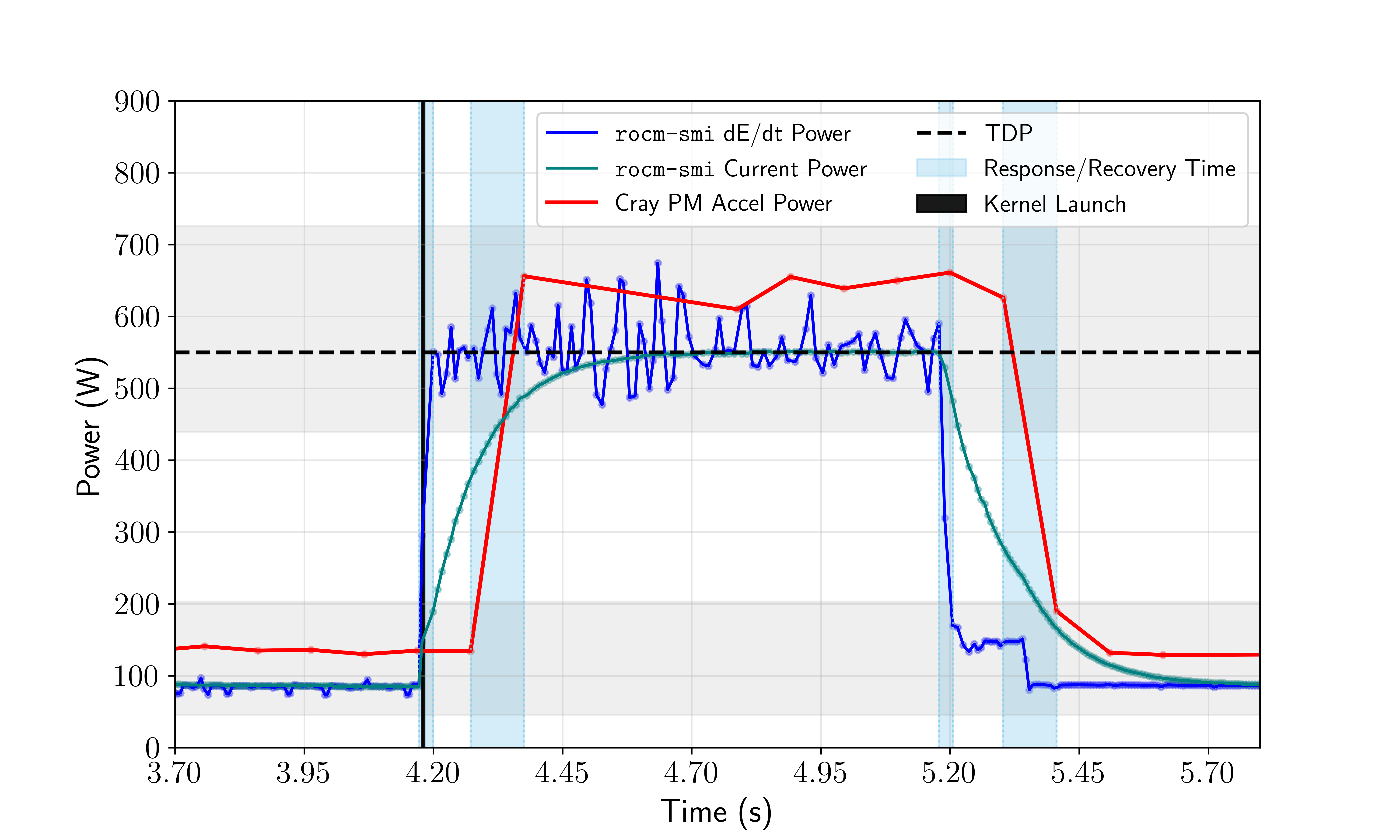
Figure 3: Power measurement for MI250X under square-wave load demonstrates close temporal correspondence of derived ΔE/Δt signal to true TDP excursions, outperforming native averages and PM counters.
Observed discrepancies are consistently within manufactural loss margins (5–10% for placement differences), validating cross-sensor calibration.
Aliasing, Jitter, and Update Interval Effects
Aliasing presents a significant barrier as both hardware and logging layer update intervals can independently suppress or distort observable workload transitions. By a combination of controlled square-wave workloads and FFT-based frequency-domain analysis, the work delineates the aliasing threshold set by physical sensor update rates (1 ms for MI250X/MI300A energy, 100 ms for Cray PM) and exposes additional instrumentation-induced downsampling and jitter contributions.
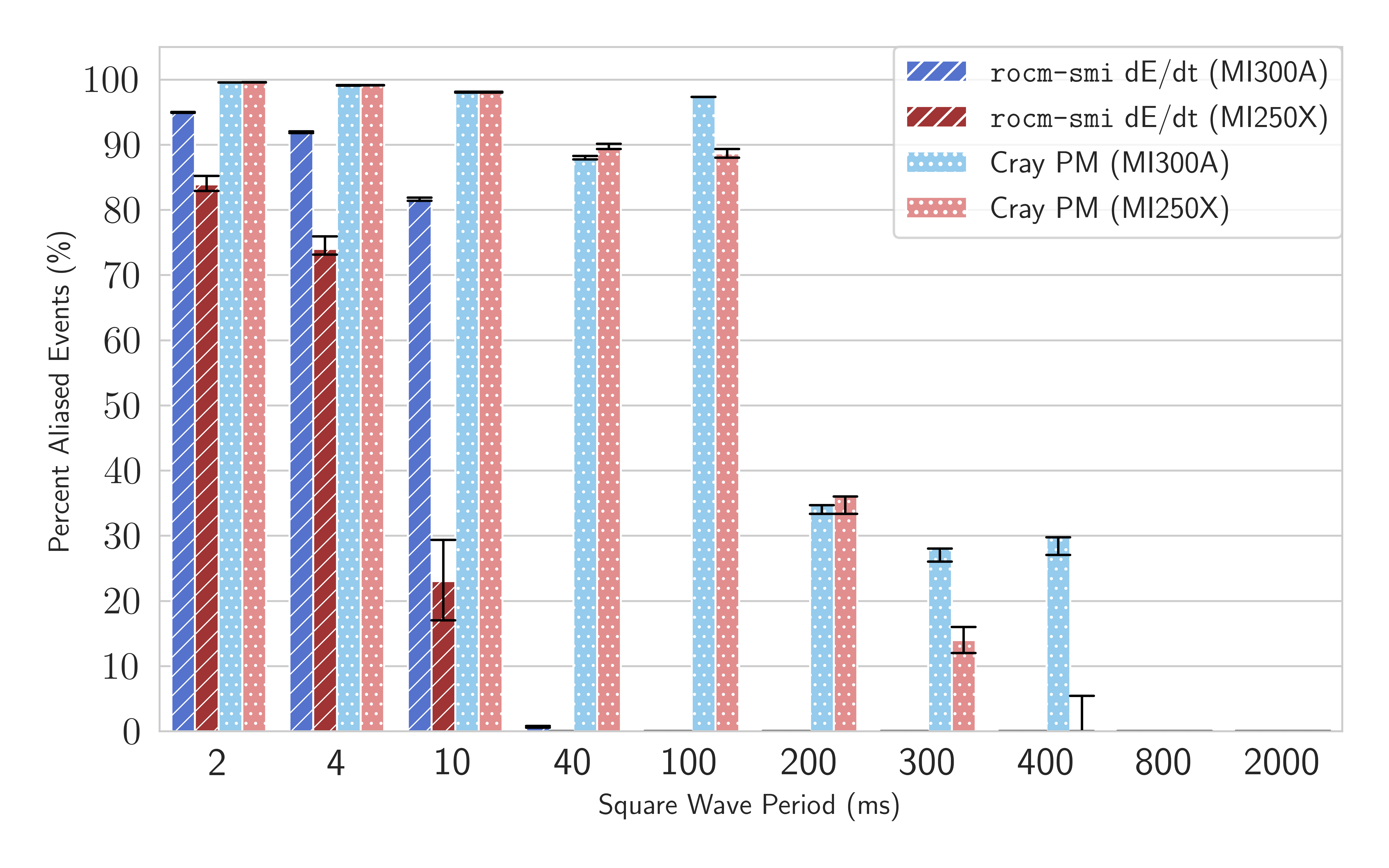
Figure 4: Median impact of aliasing on power transition detection reveals the critical role of sensor and tool-level cadence; rates above the physical update interval are neither observable nor reliable for region attribution.
The analysis clearly demonstrates that for reliable fine-grained attribution, workload and instrumentation timescales must align with sensor refresh limits.
Node-Level and Component-Level Attribution
The decomposition of node-level energy into instantaneous power streams for discrete components—GPU, CPU, memory, NICs—is accomplished using synchronized, multi-sensor tracing (Score-P with PAPI integration) and subsequent alignment to annotated regions of interest. This enables accurate attribution of energy usage across tightly coupled and bursty application phases.
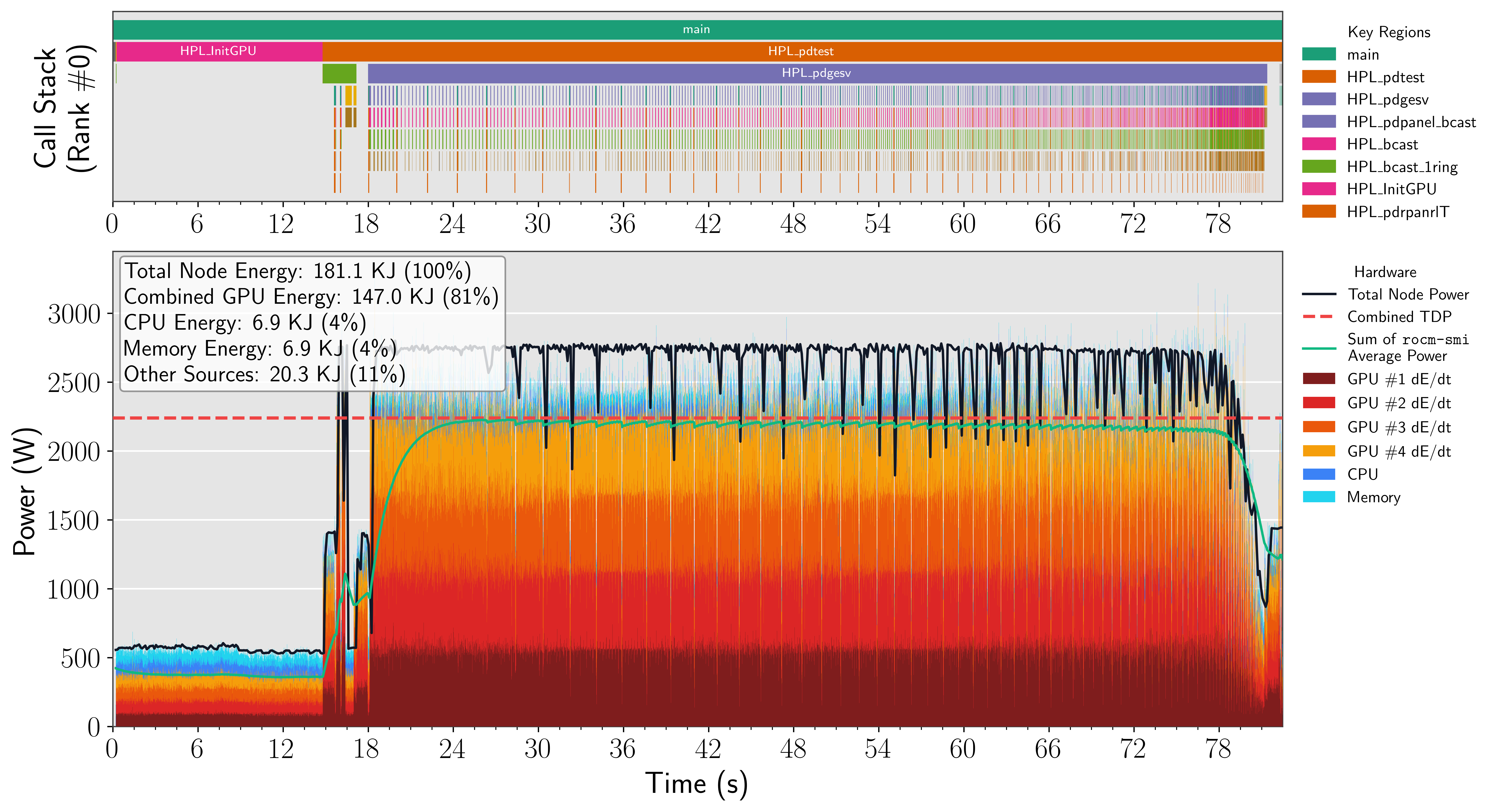
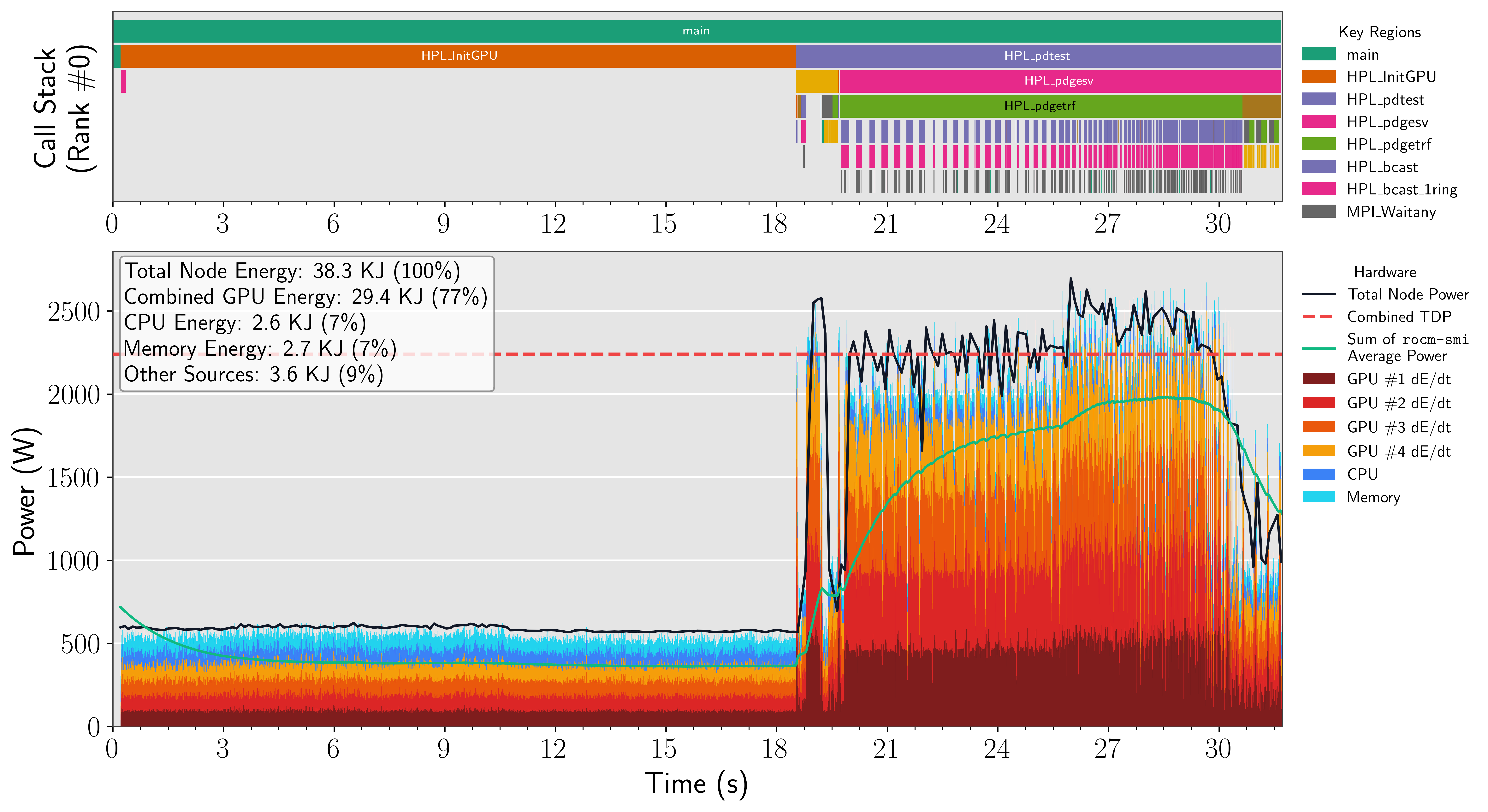
Figure 5: Frontier rocHPL full-precision stacked instantaneous power; MI250X GPUs dominate node power during computation despite static CPU/memory/NIC contributions.
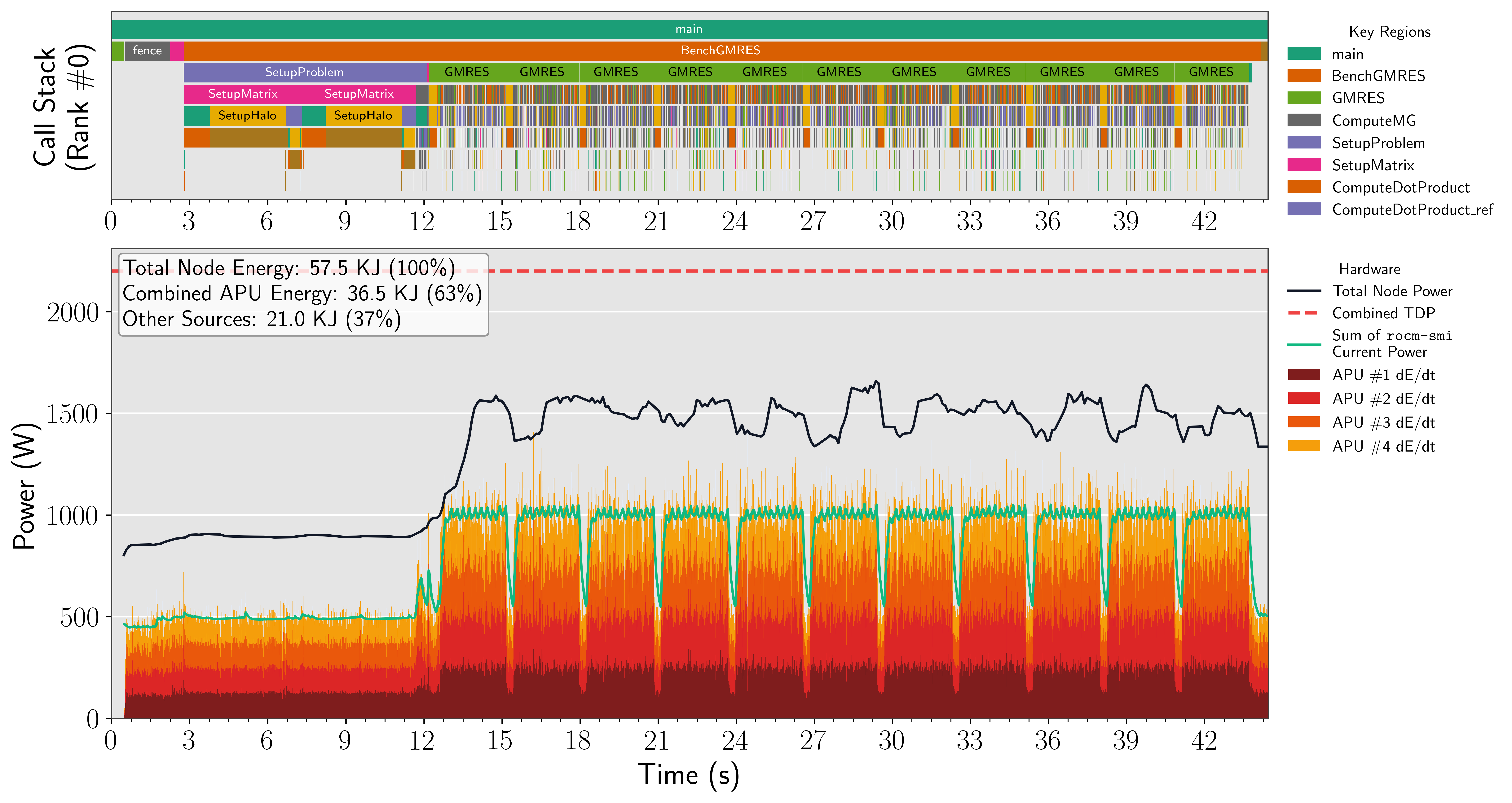
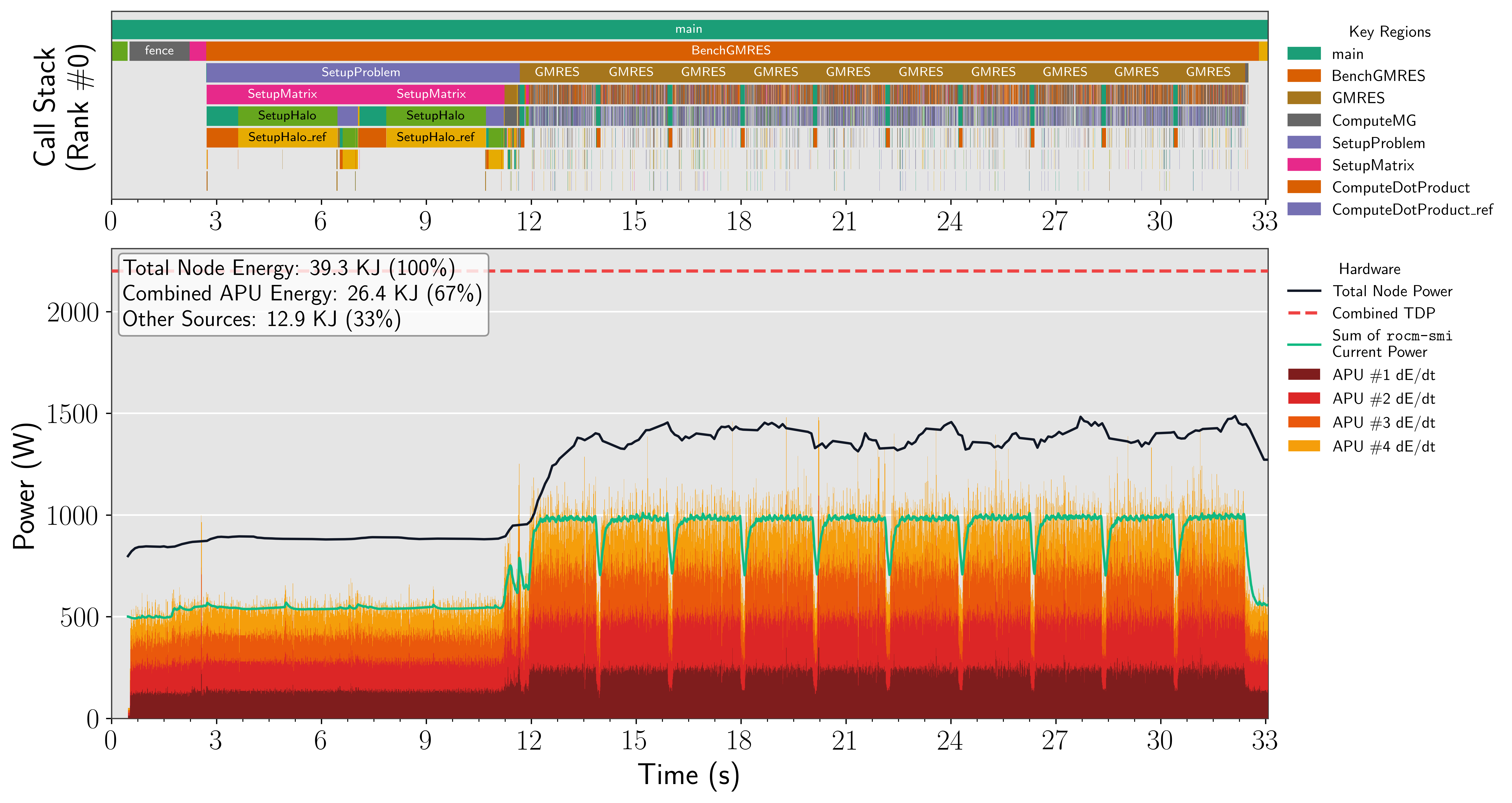
Figure 6: Portage HPG-MxP full-precision stack; compute and Krylov phases yield high APU power, juxtaposed with communication segments of lower consumption.
The results demonstrate that mixed-precision variants (rocHPL-MxP, HPG-MxP) deliver substantial node-level energy reductions (up to 81% on Portage) primarily through reduced time-to-solution, while instantaneous power per device changes less drastically.
The study extends data collection infrastructure (Score-P, PAPI, fastotf2 in Chapel) to support high-throughput, node-parallel operation with overheads well below 1%. Output traces in OTF2 format are converted and post-processed in parallel, with fine-grained alignment to phase intervals and process/rank context. Methodological rigor is supported by detailed correction for static offsets (e.g., Portage NIC-APU shared rails) and robust statistical analyses across 512 MI250X and 480 MI300A GPUs.
Theoretical and Practical Implications
Theoretical Implications:
- The three-stage model and confidence window formalism for region attribution set a framework for interpreting asynchronous metric streams on emerging architectures.
- The demonstration that derivative-based instantaneous power reconstruction is robust across sensor classes informs future cross-architecture, cross-sensor methodologies.
Practical Implications:
- The Score-P/PAPI workflow enables routine attribution of energy to phase-level events, directly supporting kernel library tuning, runtime power capping, and application-level energy scaling.
- Quantitative evidence that mixed-precision methods primarily win via faster execution (not lower peak power) has implications for node scheduling and system design, e.g., trade-offs between throughput and peak thermal design.
Future Directions
As hardware advances present even more complex sensor integration and tighter power envelopes, methodologies for trustworthy, fine-grained attribution can drive:
- Co-design of sensor and driver stacks with hardware vendors for lower-latency and less filtered measurements.
- Integration with runtime system scheduling and power cap enforcement based on real-time attribution.
- Automated analytics pipelines for classification and prediction of power/performance behavior in dynamic multiprogramming contexts.
Conclusion
This work establishes a detailed, empirically validated methodology for fine-grained, phase-resolved power and energy attribution on AMD MI250X/MI300A-based exascale nodes (2604.06056). By combining sensor pipeline modeling, instantaneous power derivation, and phase-aware trace alignment, it delivers robust tools and protocols for energy profiling and optimization relevant to current and forthcoming exascale-class systems. The approach is transferable to future architectures and provides a solid basis for both research and operational advances in energy-aware high-performance computing.

