- The paper introduces a two-stage ML framework that achieves up to 97% symmetric accuracy in predicting GPU resource and power usage.
- It employs LightGBM on static Slurm logs pre-runtime and fine-grained DCGM telemetry during execution for robust predictions.
- Results show broad applicability across HPC applications, reducing resource overprovisioning and enabling dynamic energy management.
Two-Stage Machine Learning Framework for GPU Resource and Power Prediction in Heterogeneous HPC Environments
Background and Motivation
Modern high-performance computing (HPC) facilities face acute challenges in utilizing and provisioning GPU resources efficiently, driven by growing application complexity and increasingly stringent power budgets. Classical job submission systems such as Slurm, while providing static resource specifications, do not sufficiently capture the heterogeneous and dynamic patterns of GPU and memory utilization, nor do they provide capabilities for power-aware job scheduling. Applications like VASP, which dominate scientific workloads on systems such as NERSC's Perlmutter, exhibit broad variability in both computational and power demand, leading to resource overprovisioning, underutilization, and unpredictable energy costs. This context necessitates data-driven frameworks capable of accurate pre-runtime and runtime prediction of application resource and power needs using both static job descriptors and low-overhead, high-frequency telemetry.
Large-Scale Empirical Analysis of VASP GPU Jobs
The authors systematically analyze one month (March 2025) of VASP job data on Perlmutter, integrating Slurm historical logs and NVIDIA DCGM metrics, comprising 32,322 jobs. The analyzed dataset exposes key operational characteristics: GPU utilization for VASP jobs is consistently high, while GPU memory utilization exhibits substantial underutilization, with only 5% of jobs surpassing 34% memory usage. Power consumption, meanwhile, displays a heavy-tailed distribution, with most jobs in the 107–220 W average power range but a significant minority greatly exceeding this bracket.
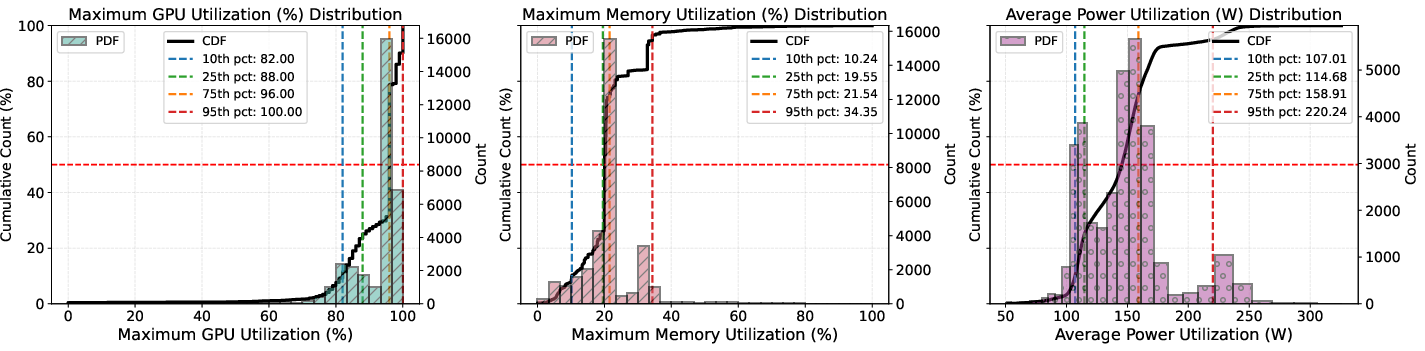
Figure 1: Distributions of maximum GPU utilization, maximum memory utilization, and average power for VASP GPU jobs on Perlmutter (March 2025).
These findings underwrite the need for generalizable prediction methods capable of mapping job descriptors and low-level metrics to actionable insights for both resource selection and power management.
Proposed Two-Stage Prediction Framework
The framework comprises two prediction stages, designed to operate both before job initiation and during job execution. Stage 1 exploits only Slurm submission features (job name, user, account, scientific category, requested CPUs/GPUs/memory/time limit); Stage 2 augments these with DCGM time-series telemetry, enabling fine-grained modeling of application runtime dynamics.
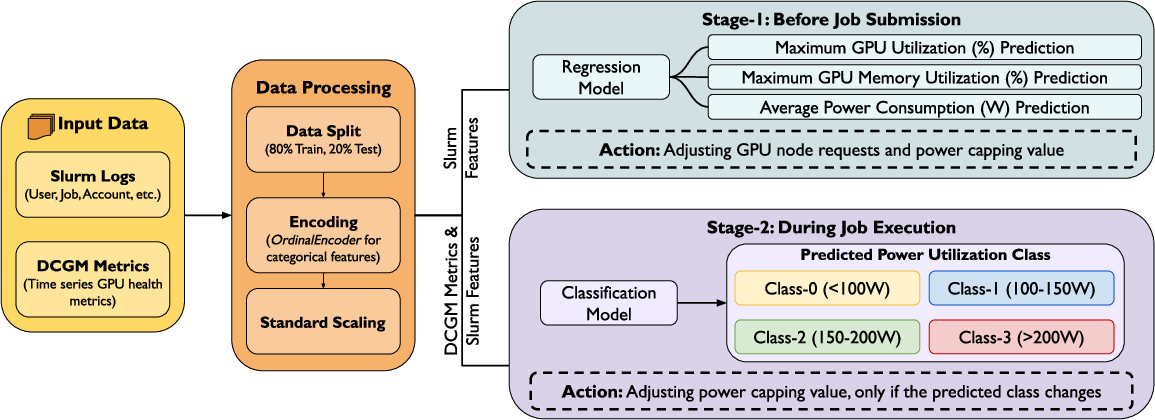
Figure 2: Overview of the proposed two-stage framework for GPU resource and power prediction.
Both stages employ LightGBM as the primary ML model, chosen for its scalability and favorable trade-off between accuracy and computational cost. Regression models are used for pre-runtime, continuous-valued prediction; runtime power modeling is recast as a classification task, with power usage discretized for compatibility with hardware-level power capping strategies.
Pre-runtime predictions achieve up to 97% symmetric accuracy for maximum GPU utilization, 94% for average power, and 88% for maximum memory utilization; R2 values indicate strong fit for average power and memory utilization. Contrasted with user-based KNN baselines (UoPC), the LightGBM-based framework generalizes robustly to all users, including infrequent submitters—a key requirement for system-wide deployment.
Feature importances reveal that wall-time limit, job name, and user dominate predictive power, indicating that users encode relevant application behavior in batch script metadata.

Figure 3: Before job execution prediction: Normalized feature importance scores from the LightGBM regression models for each target variable.
These results support automatic, low-overhead integration of the first-stage predictor into batch systems, enabling informed scheduling and provisioning without privileged user intervention.
Runtime Power Prediction Leveraging Fine-Grained DCGM Metrics
The runtime prediction component adopts a sliding window over DCGM metrics, using the previous 30 seconds of telemetry to forecast the average power consumption class at the next time interval. This approach is explicitly designed to inform system-level power capping mechanisms, and is validated against simple historical baselines (mean and max of prior windows).
The ML-based runtime predictor achieves 82% overall accuracy and 0.80 macro-averaged F1, vastly outperforming both naive alternatives (0.63 accuracy, 0.62 F1). Crucially, misclassification errors nearly always occur between adjacent power classes, providing operational robustness for dynamic energy management.
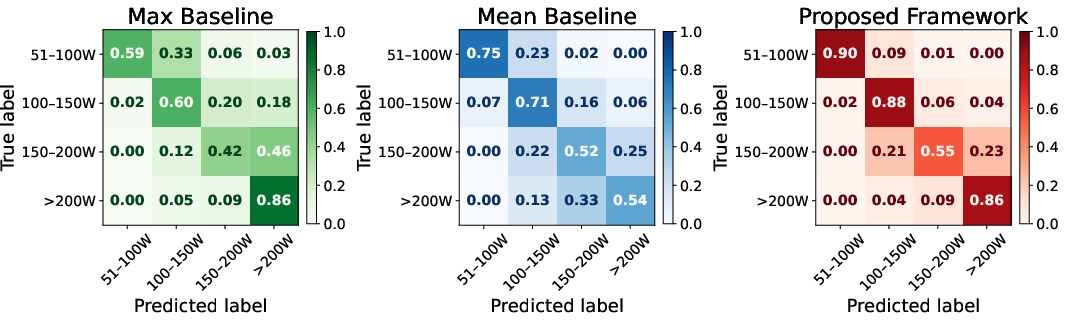
Figure 4: During job execution power prediction: Normalized confusion matrices comparing baseline methods and the proposed framework.
Examination of representative job windows demonstrates that the ML predictor closely tracks ground-truth power class evolution, whereas naive methods systematically lag or over/under-predict, particularly across transitions in workload behavior.
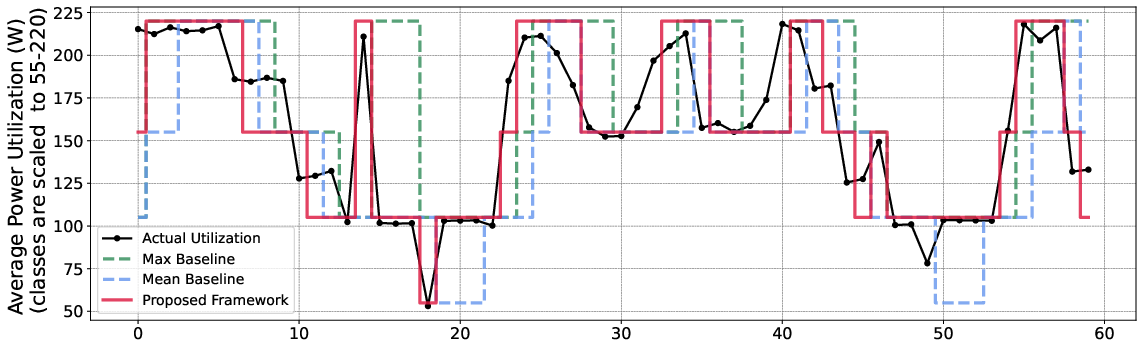
Figure 5: Test samples from a 10-minute VASP job execution window, showing runtime predictions of average power consumption class.
DCGM metrics—specifically power, memory, and SM utilization—are the most important runtime features; static Slurm attributes are largely non-informative, highlighting the necessity of real-time telemetry for power-aware system operations.
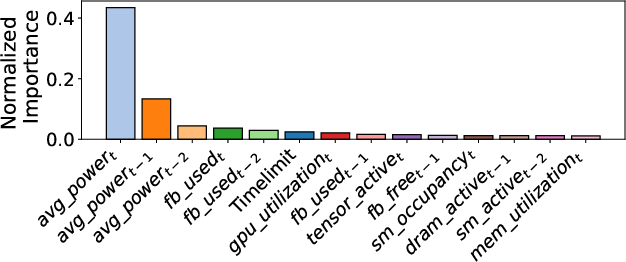
Figure 6: During job execution prediction: Normalized feature importance scores from the LightGBM classifier.
Generalizability and Broader Applicability
Although initial development and validation center on VASP workloads, the framework is found to generalize robustly to other HPC applications, including LAMMPS, Espresso, Atlas, and E3SM, with similar performance trends: average power prediction accuracy ranges from 0.73 to 0.92, and maximum GPU utilization from 0.69 to 0.80. Memory usage remains more variable across workloads but shows consistent improvement over static baseline methods.
This underscores the value of the proposed approach: it is agnostic to scientific domain, incorporates only widely-available input features (Slurm, DCGM), and exhibits minimal operational overhead, making it directly applicable to a range of GPU-accelerated scientific applications in large-scale heterogeneous HPC environments.
Practical and Theoretical Implications
The work closes the gap between static, user-driven resource requests and the inherently dynamic behavior of real-world scientific codes. Accurate pre-runtime predictions directly reduce overprovisioning and underutilization by guiding resource allocation decisions, while runtime power predictions enable automated, fine-grained power capping and energy-aware scheduling.
From a theoretical perspective, this framework demonstrates that tree-based ML models trained on modest, well-chosen features can effectively learn the mapping from application descriptors and high-frequency telemetry to resource and power requirements, across diverse workload families. This signals that more complex, deep learning-based approaches may not be universally required for deployment-scale power and resource prediction tasks in operational HPC.
Conclusion
This paper delivers a practical, end-to-end ML framework for two-stage GPU resource and power prediction in heterogeneous HPC settings, validated at scale on Perlmutter's production workloads (2604.02158). The high prediction accuracy, broad generalizability, and low deployment cost suggest that such methodologies will increasingly become foundational for sustainable, high-throughput, and energy-aware supercomputing. Future directions include real-time system integration, closed-loop adaptive scheduling, and the extension of the framework to cover multi-tenant resources and more irregular job types.