- The paper demonstrates a novel Unlearn-and-Reinvent pipeline that enables LLMs to intentionally forget and then reconstruct canonical algorithms.
- It employs GRPO-based on-policy unlearning and hierarchical prompting to achieve a 50% to 90% success rate for reinventing simpler algorithms.
- Test-time reinforcement learning and verifier feedback significantly enhance algorithmic synthesis, though complex algorithms like KMP remain challenging.
Can LLMs Reinvent Foundational Algorithms? — An Expert Analysis
Introduction
This work examines whether LLMs possess the capacity to independently reinvent foundational algorithms from computer science after explicit removal of such knowledge via a post hoc unlearning procedure. The investigation centers on the proposed Unlearn-and-Reinvent pipeline, which conducts parametric algorithmic ablation at the LLM level and subsequently probes the potential for de novo algorithm synthesis. The setting thus critically separates genuine innovation from memorized retrieval, allowing for a systematic study of LLM-driven algorithmic invention.
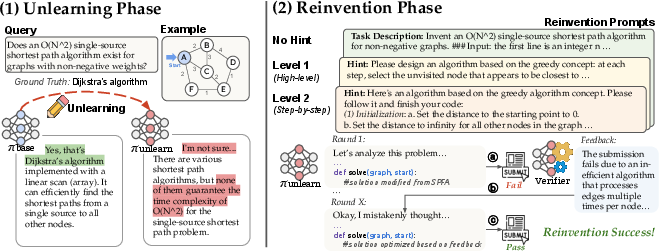
Figure 1: The Unlearn-and-Reinvent pipeline structure, comprising an on-policy LLM unlearning phase and a reinvention phase that optionally utilizes hierarchical hints and verifier-mediated RL-based exploration.
Methodology
Unlearning Phase: GRPO-Based On-Policy Algorithmic Erasure
The study circumvents the computational cost of retraining LLMs on curated corpora by employing an on-policy, Group Relative Policy Optimization (GRPO) based unlearning approach. The unlearning objective is formulated to maximize forgetting of specific algorithmic knowledge (Dforget), while preserving general model utility via retention sets (Dretain). The cold start mechanism ensures that reward attribution is non-degenerate at initialization.
The reward design prohibits three categories of reward hacking:
- Knowledge leakage (either explicit or implicit conceptual echoing)
- Algorithm-name hallucination/name corruption
- Collapse of response coherence (gibberish outputs)
As demonstrated empirically, this robust design achieves near-complete forgetting (Forgetting Rate ∼100%) across ten canonical targets while maintaining general coding, math, and function-calling capabilities.
Reinvention Phase: Controlled Algorithm Discovery
Post-unlearning, the LLM is evaluated on its ability to synthesize functional solutions to problems classically solved by the elided algorithms. Reinvention tasks are instantiated as code-writing prompts embedded in a sandboxed Python interpreter, scoped by strong performance and resource constraints, and tested against private cases.
Hierarchical prompting provides orthogonal intervention:
- No hint (bare task description)
- Level 1: Conceptual hint (e.g., high-level strategy)
- Level 2: Detailed stepwise outline (sub-algorithmic granularity)
Failures are diagnosed by a generative verifier, which supplies semantic feedback. This setup supports a high-resolution analysis of latent inventiveness and facilitates test-time RL via reward shaping, targeting correctness and execution efficiency.
Main Empirical Findings
Algorithm Reinvention Capacity and its Boundaries
Qwen3-4B-Thinking-2507, the strongest backbone tested, independently reinvents up to 50% of foundational targets (e.g., Gray Code, Euclidean GCD, certain shortest path algorithms) with zero external hints. Reinvention rates climb to 90% at stepwise guidance (level 2 hints), but high algorithmic complexity—exemplified by KMP, Manacher, and Strassen—remains out of reach for all models despite maximal prompting.
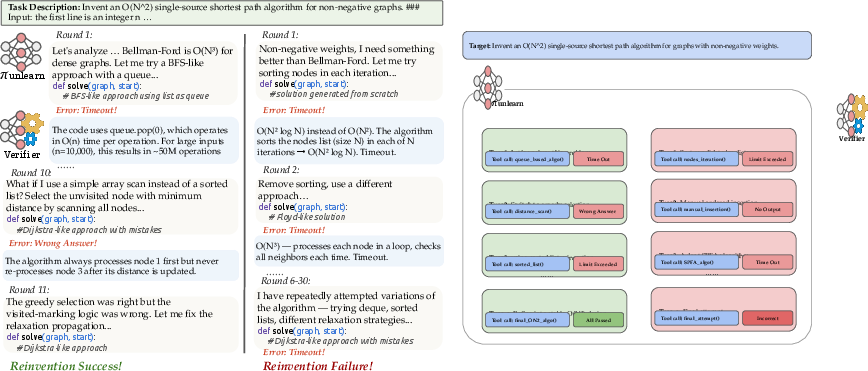
Figure 2: Divergent reinvention trajectories for Dijkstra’s algorithm — one converging on a successful synthesis via iterative repair and verifier feedback, the other falling into a non-productive local minimum.
Effect of External Hints
Stepwise monotonic improvements in Reinvention Success Rate (RSR) are observed with increased hint granularity, particularly for moderately challenging graph problems. However, even exhaustive prompts are consistently insufficient to enable reinvention of KMP and Strassen, indicating that LLMs, post-unlearning, lack the inductive mechanisms for non-local algorithmic synthesis.
Test-Time Reinforcement Learning
Test-time RL over candidate solutions further enhances exploration and solution quality. Strikingly, test-time RL enables successful reinvention of Strassen's algorithm at level 2, where static decoding utterly fails.
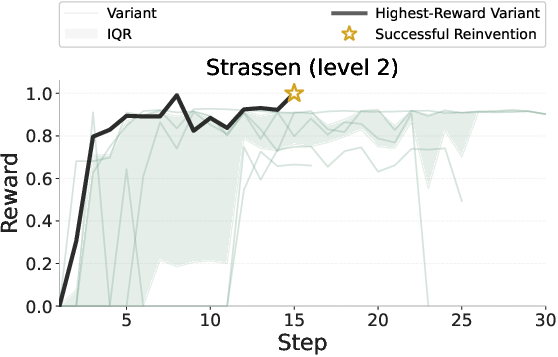
Figure 3: Reward curve for Strassen’s algorithm (level 2), showing reward emergence and convergence to a viable solution post-test-time RL.
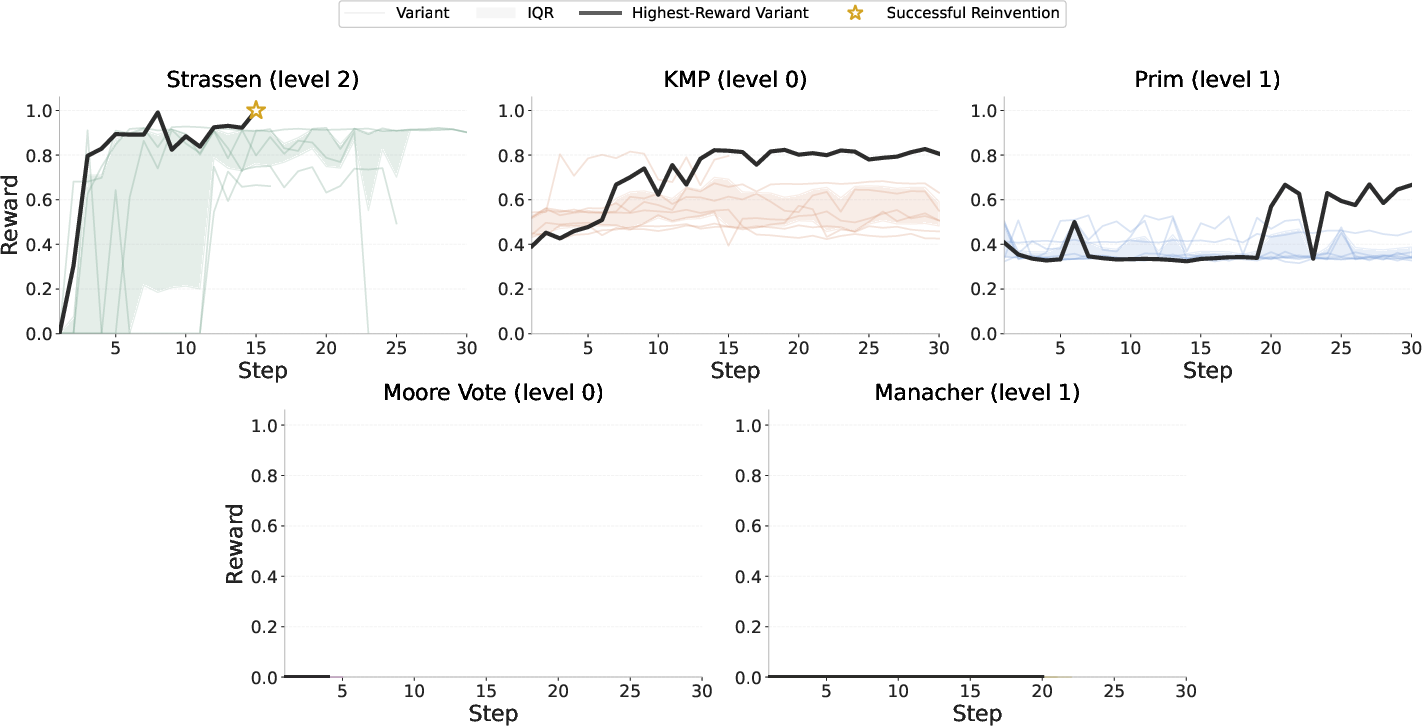
Figure 4: Complete RL reward curves across targets; only Strassen (level 2) admits reward signal sufficient for successful optimization.
Sustained Exploration: Role of Generative Verifier
Verifiers substantially mitigate the “thought collapse” phenomenon, where outputs degenerate into brevity and lack of exploration under self-critique. Ablation reveals that rounds with verifier feedback show lengthened interaction traces and higher convergence rates. Oracle verifiers further amplify these effects but the benefit saturates rapidly.
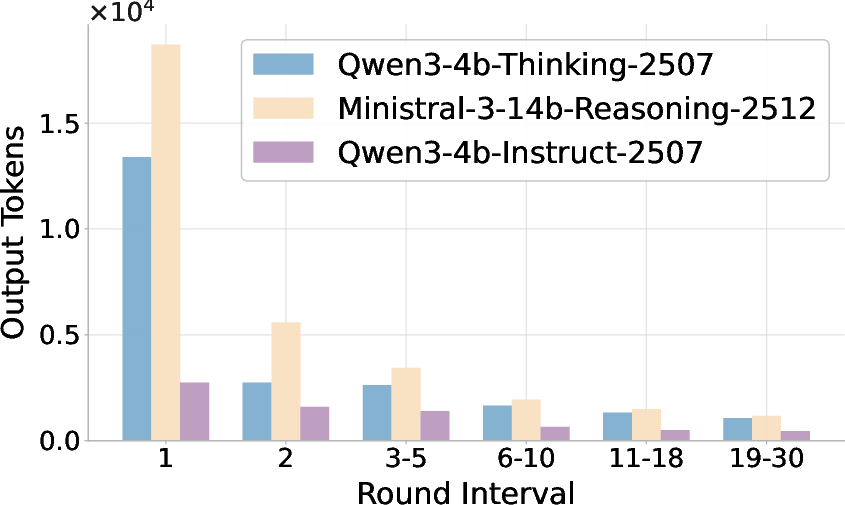
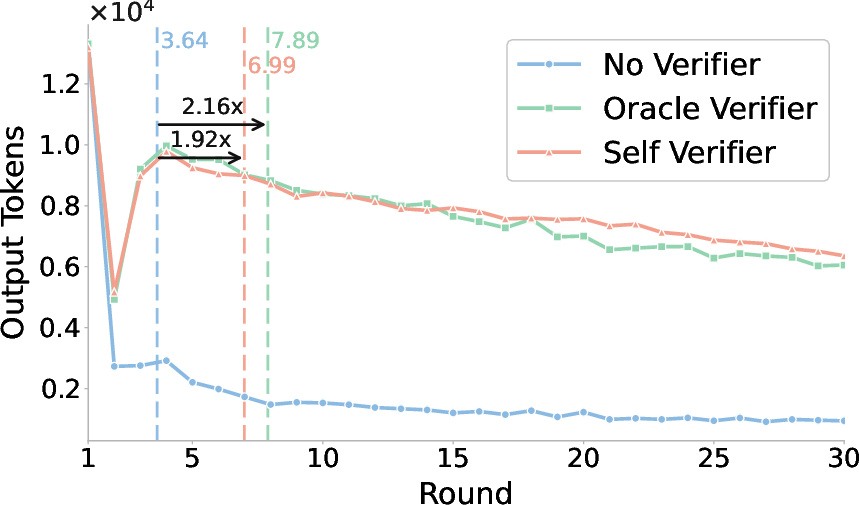
Figure 5: Evolution of candidate output length over rounds, with and without verifier feedback. Verifiers preserve exploration depth and delay collapse.
Analysis and Theoretical Implications
The results demonstrate that current LLMs, absent explicit memorized knowledge, can reconstruct a significant subset of algorithmic primitives through program search and verifier-aided feedback, but remain confined by the compositional complexity barrier. Only those classes for which the solution space is small or the inductive bias aligns with algorithmic locality are tractable.
Test-time RL acts as a proximal optimizer, capable of exploiting weak prior signals and diagnostic gradients, but does not instantiate fundamentally new algorithmic schemas. In practice, the discovered behavior aligns with path-search in solution space, limited by model-internal heuristics and availability of guiding information.
This technique—parametric algorithm ablation via unlearning, followed by structured reinvention—institutes a falsifiable protocol for measuring LLM "innovativeness" under controlled exposure and forms a compelling blueprint for computational creativity studies.
Limitations and Future Work
While the pipeline achieves high empirical forgetting rates, full removal of algorithmic priors cannot be formally certified due to the limits of post hoc unlearning (as opposed to corpus-level retraining). The evaluation is constrained to 10 handpicked algorithms, raising open questions about broader generalizability to theories, scientific law discovery, or open-ended mathematical conjectures.
Future research directions include:
- Extending ablation–reinvention protocols to broader classes such as theorem proving and empirical science
- Scaling up to larger LLMs with explicit mechanism probing at the representation level
- Formalizing the hardness of algorithmic rediscovery as a function of inductive complexity and solution space size
Conclusion
This work rigorously demonstrates that open-weight LLMs, after targeted algorithmic unlearning, retain the capacity to synthesize a non-trivial but limited subset of foundational computer science algorithms. The critical dependencies are the problem structure and the availability of structured feedback and hints. The boundary between tractable and intractable reinvention is sharply delineated by the internal reasoning biases, model size, and inferential search capabilities. The introduction of guided ablation-reinvention pipelines is projected to become a key methodology in the systematic study of generative scientific discovery in autonomous AI agents.