- The paper formalizes LLMs as reasoning oracles, introducing a transfer function that quantitatively links context quality to the probability of correct outputs.
- It rigorously analyzes branching, genetic, and random sampling algorithms, detailing how decaying models influence convergence rates and algorithmic efficiency.
- Empirical validation with Gemini 2.5 Pro supports the theory, offering actionable insights into resource allocation and optimal test-time inference strategies.
Overview and Motivation
"Algorithmic Thinking Theory" (2512.04923) addresses the notable empirical gap uncovered by modern LLMs: while models like Gemini 2.5 Pro achieve substantial performance on various reasoning benchmarks, significant divergence persists between single-sample accuracy (pass@1) and multi-sample or iterative synthesis accuracy (pass@k). Empirical evidence demonstrates that neither naive sampling nor best-of-k selection suffices for challenging benchmarks such as IMO problems; advanced answer aggregation and solution refinement are necessary for LLMs to fully exploit their latent problem-solving capacity. This paper formalizes the class of "reasoning algorithms" that operate over LLMs conceived as probabilistic "reasoning oracles", yielding a theoretical foundation for the design and analysis of scalable, compositional test-time inference strategies.
The foundation of the paper is the abstraction of an LLM as a reasoning oracle: given a context (possibly an empty set or collection of other solutions), the oracle stochastically samples a new solution. The core construct is a transfer function F that quantitatively relates the context—its composition and quality (e.g., number of correct solutions)—to the probability that the oracle outputs a correct response. Within this schema:
- Solution space: S, with solutions scored by $\score: S \to \{0,1\}$ (binary, correct/incorrect).
- Oracle call: A(C) generates s∈S stochastically, with the output quality distribution governed by the multiset of scores in C via F.
- Reasoning algorithm: A DAG of at most n oracle calls, each potentially contextualized by prior solutions.
A pivotal component of the modeling is the decaying model: a context containing at least one correct solution results in improved (but decaying with context size) success probability versus a context of only incorrect solutions. Special cases include the uniform model (flat improvement up to a limit) and models with exponential or polynomial decay as context size grows.
Analysis of Reasoning Strategies
The paper rigorously analyzes three families of reasoning algorithms:
- Branching Algorithm: Builds a tree of solutions, merging independently sampled answers at each level, and applying the oracle at "leaves" before synthesizing further up the tree.
- Genetic Algorithm: Maintains populations at each layer, applying the oracle to random subgroups sampled from the previous population, closely mirroring evolutionary methods and practical techniques like Recursive Self-Aggregation (RSA).
- Random Sampling Algorithm: Grows a solution sequence by repeatedly resampling that sequence itself as context.
A central finding is that, for the class of decaying models, these algorithms converge to the optimal success probability as the number of queries increases, with the branching and genetic algorithms displaying quantifiable convergence rates.
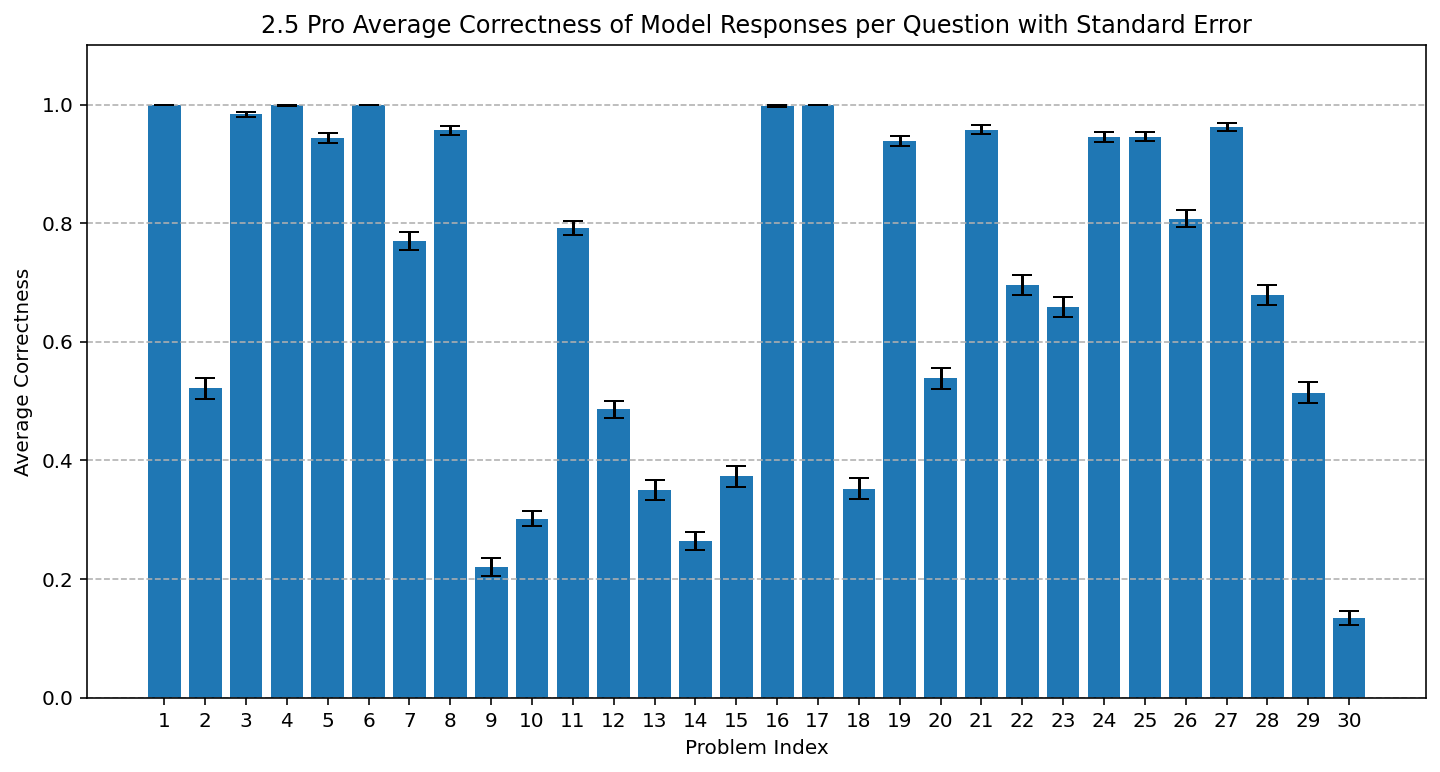
Figure 1: Average AIME 2025 accuracy per question for Gemini 2.5 Pro, demonstrating strong model performance and significant variability across questions.
Oracle Monotonicity and Optimality
Two properties—weak and strong oracle monotonicity—are identified as key determinants in the structure of optimal algorithms:
- Weak monotonicity: Better context yields stochastically better outputs.
- Strong monotonicity: Adding more correct solutions never reduces expected final score; thus, in strongly monotone settings, using the maximal available context is always optimal.
For the uniform model (constant improvement up to context size k), the optimal success probability x∗ is the fixed point of x=q−(q−p)(1−x)k, where q and p are, respectively, the oracle's probability of success given at least one correct/only incorrect solution in the context.
Convergence Rates and Algorithmic Efficiency
The convergence behavior of each algorithm is quantitatively analyzed. Key results include:
- Branching algorithm: Error decays exponentially with the depth (number of levels), with rate set by the fixed point derivative.
- Genetic algorithm: Error decays polynomially in the number of oracle calls, achieving the rate O(n−1/2).
- Random sampling: Performance transitions between those of branching and genetic algorithms, with the convergence exponent determined by both context size and decay rate.
Empirical Validation
The theoretical framework is validated through controlled experiments using Gemini 2.5 Pro on the AIME 2025 dataset:
- Figure 1 demonstrates varying base accuracy per question.
- Figures 2 and 3 empirically probe the decay hypothesis: as the number of incorrect solutions provided in context increases, the improvement in accuracy from providing a correct solution diminishes, following exponential or polynomial decay trends.
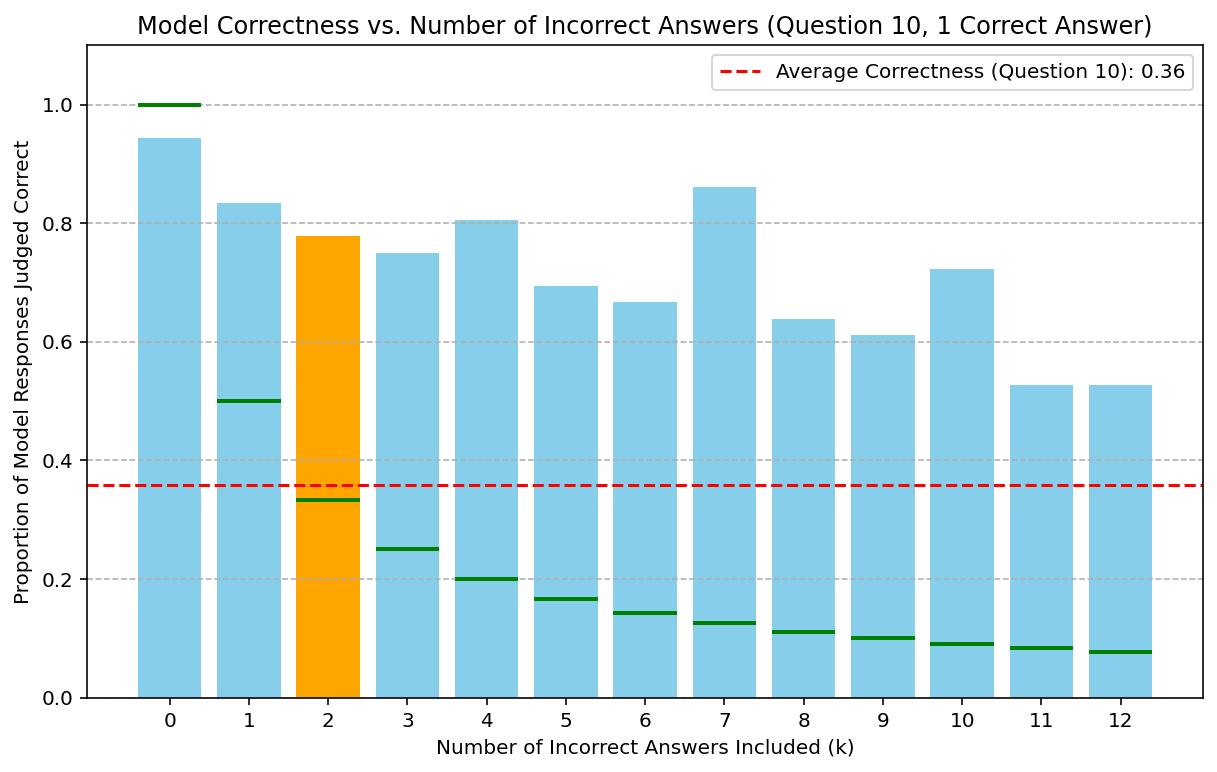
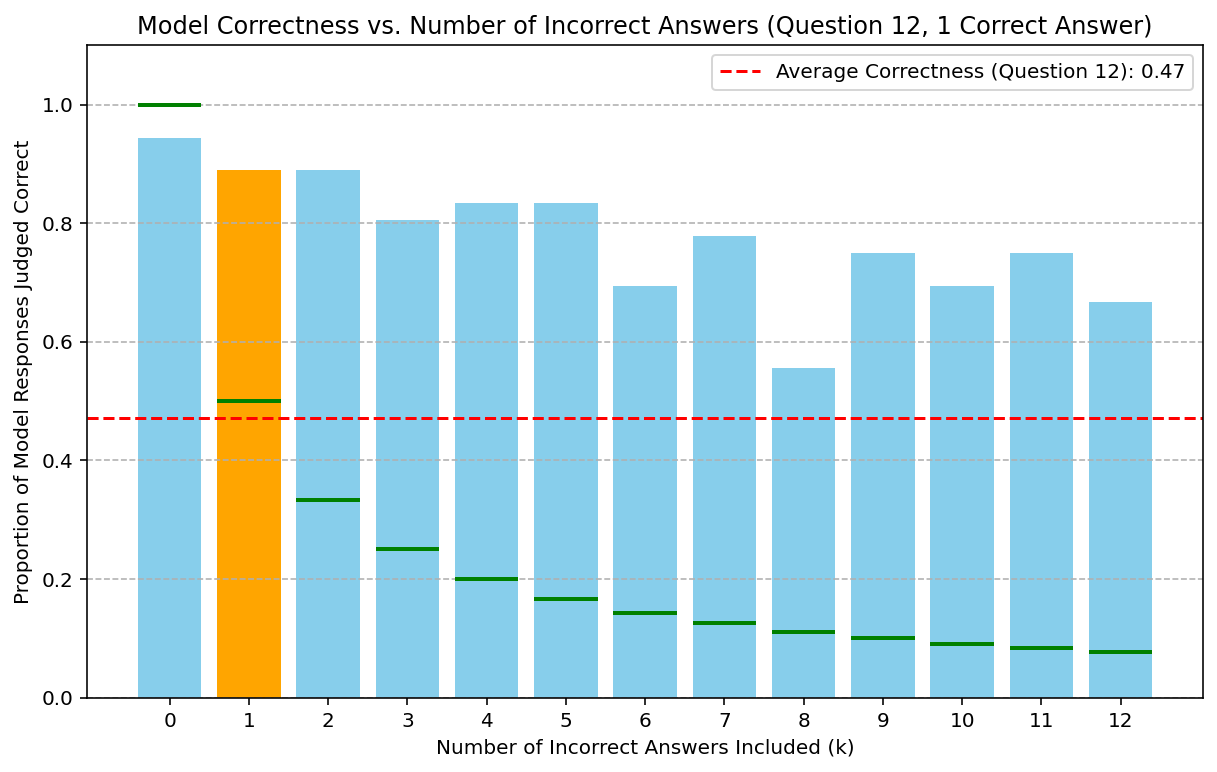
Figure 2: Gemini 2.5 Pro accuracy as a function of incorrect solutions in the context; clear decaying trend supports the "decaying model" hypothesis for context utilization.
Providing multiple correct solutions among fixed-size contexts leads to smoother, monotonic gains in verification accuracy (Figure 3), confirming the theoretical transfer function behavior and further supporting the decaying model.
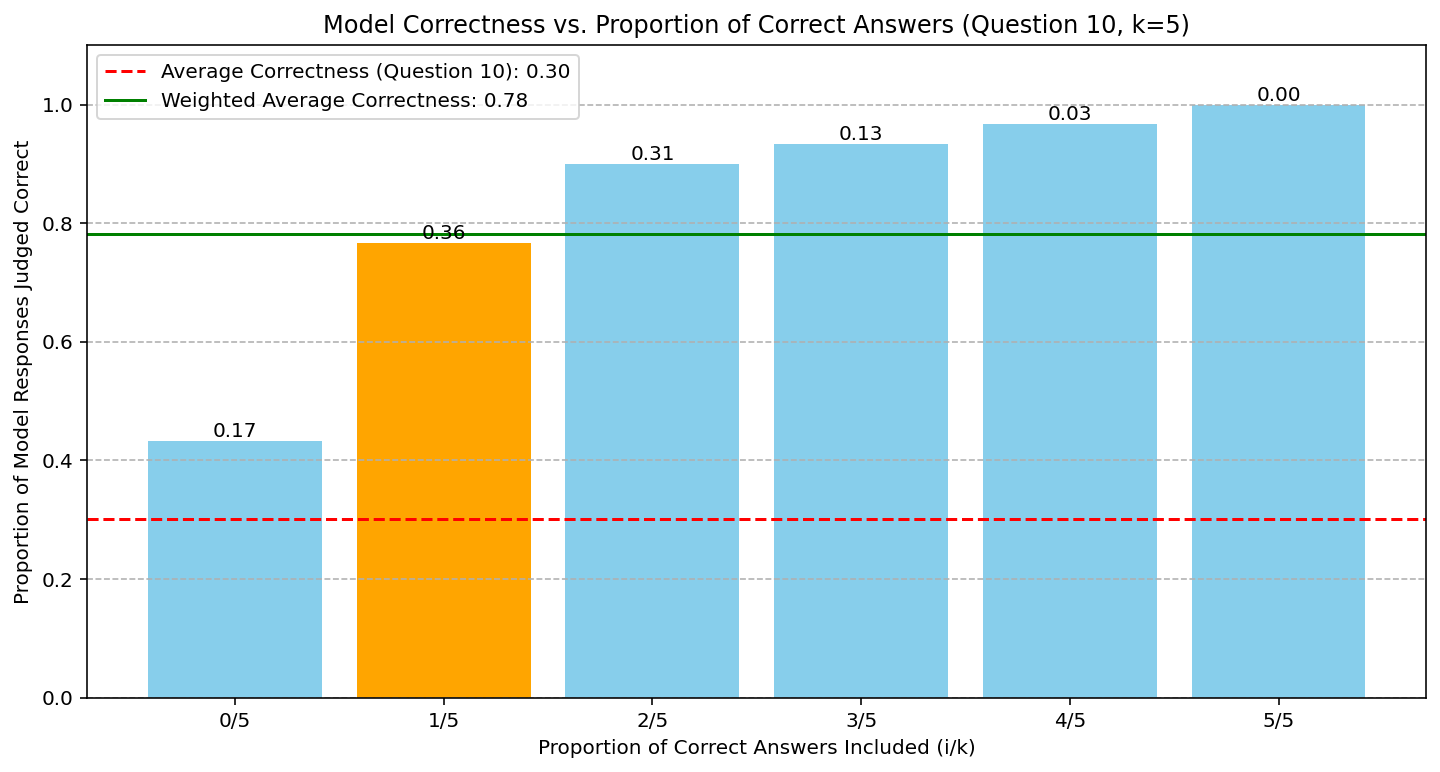
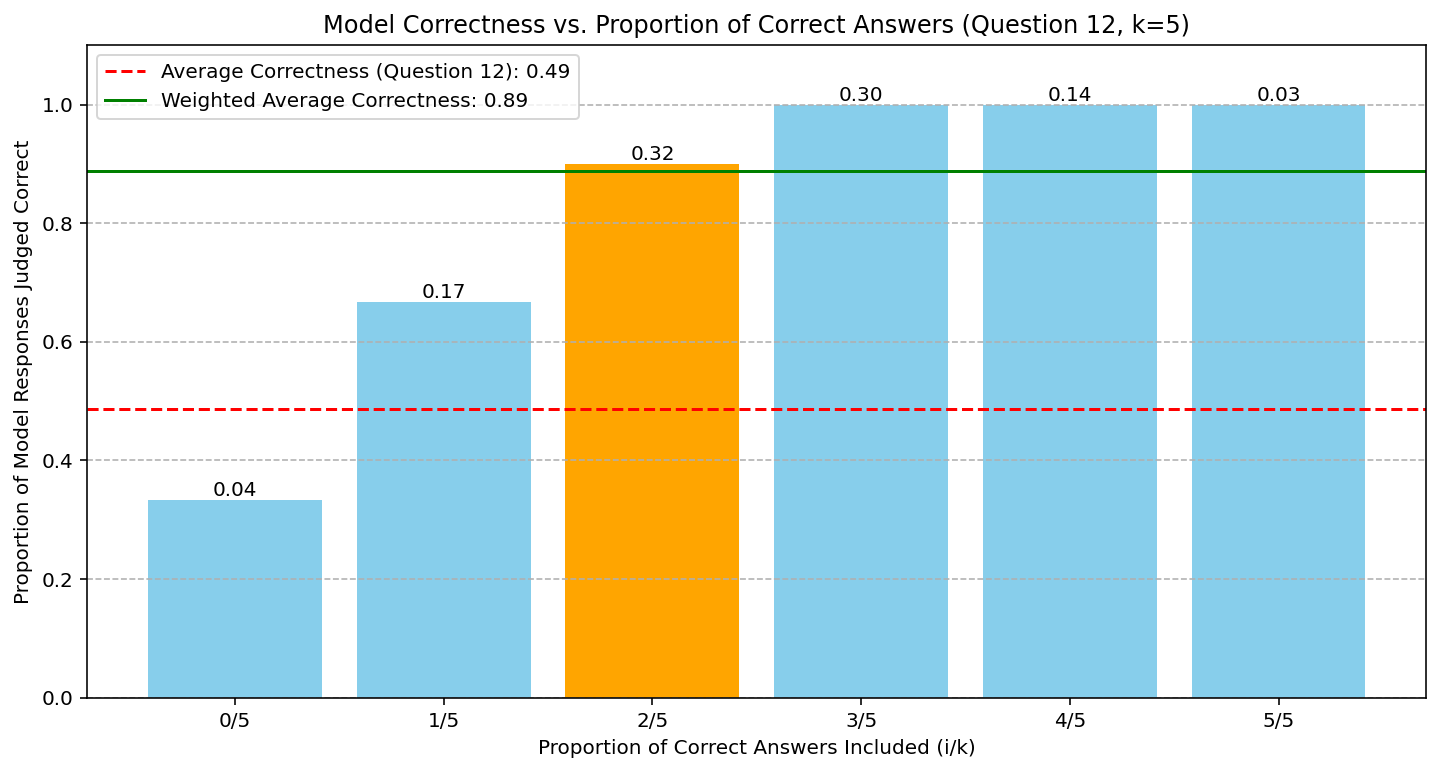
Figure 3: Model accuracy when supplying five context solutions, varying the correct-to-incorrect ratio; accuracy grows smoothly with the number of correct solutions, validating the aggregation potential central to the transfer function perspective.
Practical and Theoretical Implications
By unifying aggregation and synthesis-focused methods—such as RSA, Tree of Thoughts, and advanced answer merging—under a principled probabilistic oracle model, the paper offers a platform for:
- Algorithm design: The formalism guides the construction of scalable, test-time computational pipelines tailored to the decay properties empirically measured for a given model and domain.
- Resource allocation: Tradeoffs between depth (parallelism), compute, and final accuracy are rendered explicit.
- Limits of aggregation: The possibility of "overthinking," where too large a context degrades performance, is naturally predicted by non-monotonic or strongly decaying transfer functions, in agreement with recent empirical studies.
Future work is set to address several open frontiers: introducing richer (non-binary) solution quality scores, modeling answer diversity, and exploring the impact of context composition beyond correctness alone. These extensions would potentially connect algorithmic reasoning theory with established lines of research in ensemble methods, information theory, and dynamical systems applied to probabilistic computation.
Conclusion
"Algorithmic Thinking Theory" formalizes a central empirical phenomenon in LLM-based reasoning: iterative aggregation and synthesis across diverse, partially correct solutions can unlock model capability far exceeding the naive pass@k paradigm. By providing a robust, generalizable theoretical model and linking it directly to experimental results, the work delineates the boundaries, tradeoffs, and optimal strategies for designing and scaling test-time reasoning algorithms. Its theoretical foundation sets the stage for principled advances in AI system design, enabling inference-time algorithms that meaningfully amplify the reasoning power of base models without further training.

