DELTA-Code: How Does RL Unlock and Transfer New Programming Algorithms in LLMs?
Abstract: It remains an open question whether LLMs can acquire or generalize genuinely new reasoning strategies, beyond the sharpened skills encoded in their parameters during pre-training or post-training. To attempt to answer this debate, we introduce DELTA-Code--Distributional Evaluation of Learnability and Transferrability in Algorithmic Coding, a controlled benchmark of synthetic coding problem families designed to probe two fundamental aspects: learnability -- can LLMs, through reinforcement learning (RL), solve problem families where pretrained models exhibit failure with large enough attempts (pass@K=0)? --and transferrability -- if learnability happens, can such skills transfer systematically to out-of-distribution (OOD) test sets? Unlike prior public coding datasets, DELTA isolates reasoning skills through templated problem generators and introduces fully OOD problem families that demand novel strategies rather than tool invocation or memorized patterns. Our experiments reveal a striking grokking phase transition: after an extended period with near-zero reward, RL-trained models abruptly climb to near-perfect accuracy. To enable learnability on previously unsolvable problem families, we explore key training ingredients such as staged warm-up with dense rewards, experience replay, curriculum training, and verification-in-the-loop. Beyond learnability, we use DELTA to evaluate transferability or generalization along exploratory, compositional, and transformative axes, as well as cross-family transfer. Results show solid gains within families and for recomposed skills, but persistent weaknesses in transformative cases. DELTA thus offers a clean testbed for probing the limits of RL-driven reasoning and for understanding how models can move beyond existing priors to acquire new algorithmic skills.
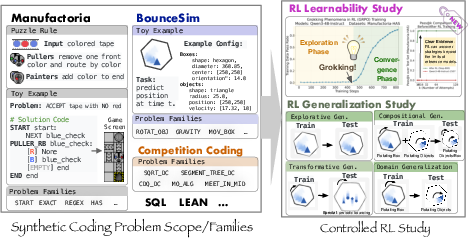
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper asks a big question: Can we teach AI coding models to actually learn brand‑new ways of solving problems, not just polish what they already know? To study this fairly, the authors built a controlled set of coding puzzles called DELTA-Code. They then trained LLMs using reinforcement learning (RL)—a “learn by trying and getting feedback” method—to see if the models could unlock new problem‑solving strategies and then use those strategies on tougher, different versions of the puzzles.
What questions the paper tries to answer
- Learnability: If a model keeps failing a whole family of problems even after many tries, can RL teach it a new step‑by‑step method so it finally succeeds?
- Transferability (generalization): After it learns a method, can the model use it on new, harder, or different versions of the problems—not just the ones it was trained on?
How the researchers tested this (methods, explained simply)
To make the tests fair and clear, the team designed synthetic (computer-generated) coding puzzles with rules they controlled, so they knew exactly what skill each puzzle required.
They focused on two main puzzle sets:
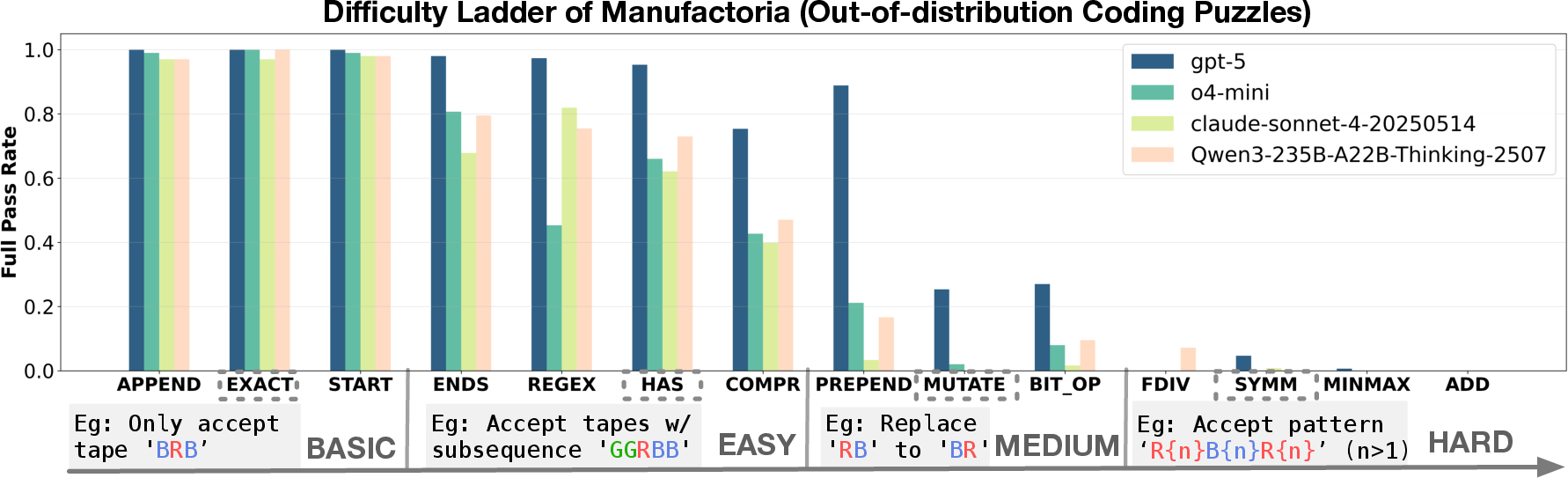
- Manufactoria: Inspired by a classic puzzle game, but reimagined with a brand‑new, custom programming language the AI has never seen. You must write small “factory programs” that accept or reject colored tape patterns. This makes it “out‑of‑distribution” (OOD), meaning it’s unlike the data the model saw before and can’t be solved by memorization.
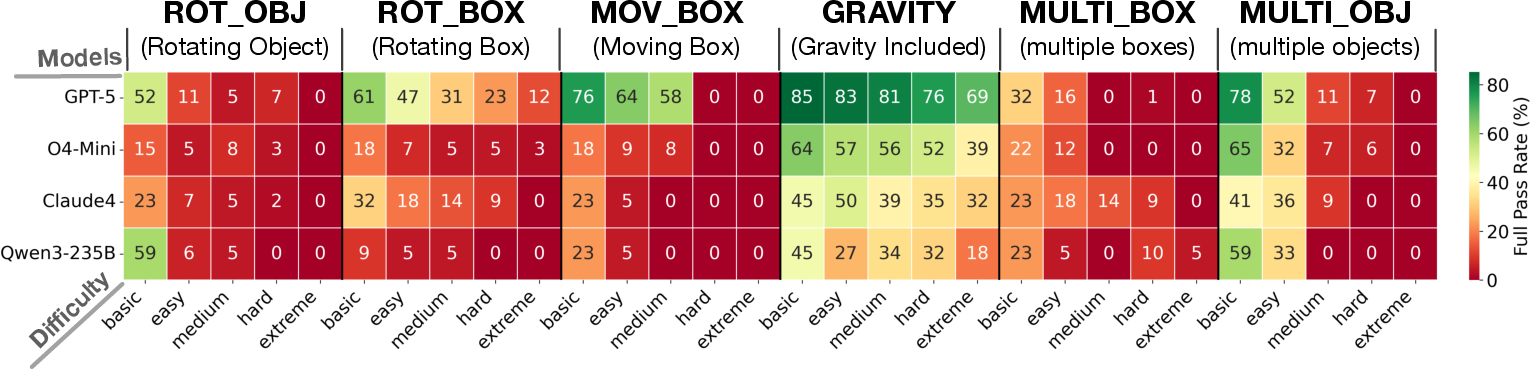
- BouncingSim: Write a simulator that makes a ball bounce around in shapes with exact physics. The program must output the ball’s position at a given time, tested against a reliable physics engine.
Why coding puzzles? Coding comes with automatic test cases. That means the model can get “partial credit” (dense rewards) when some tests pass, not just all-or-nothing grades. This is perfect for RL, because models need frequent, informative feedback to learn hard things.
How RL training worked (with simple analogies):
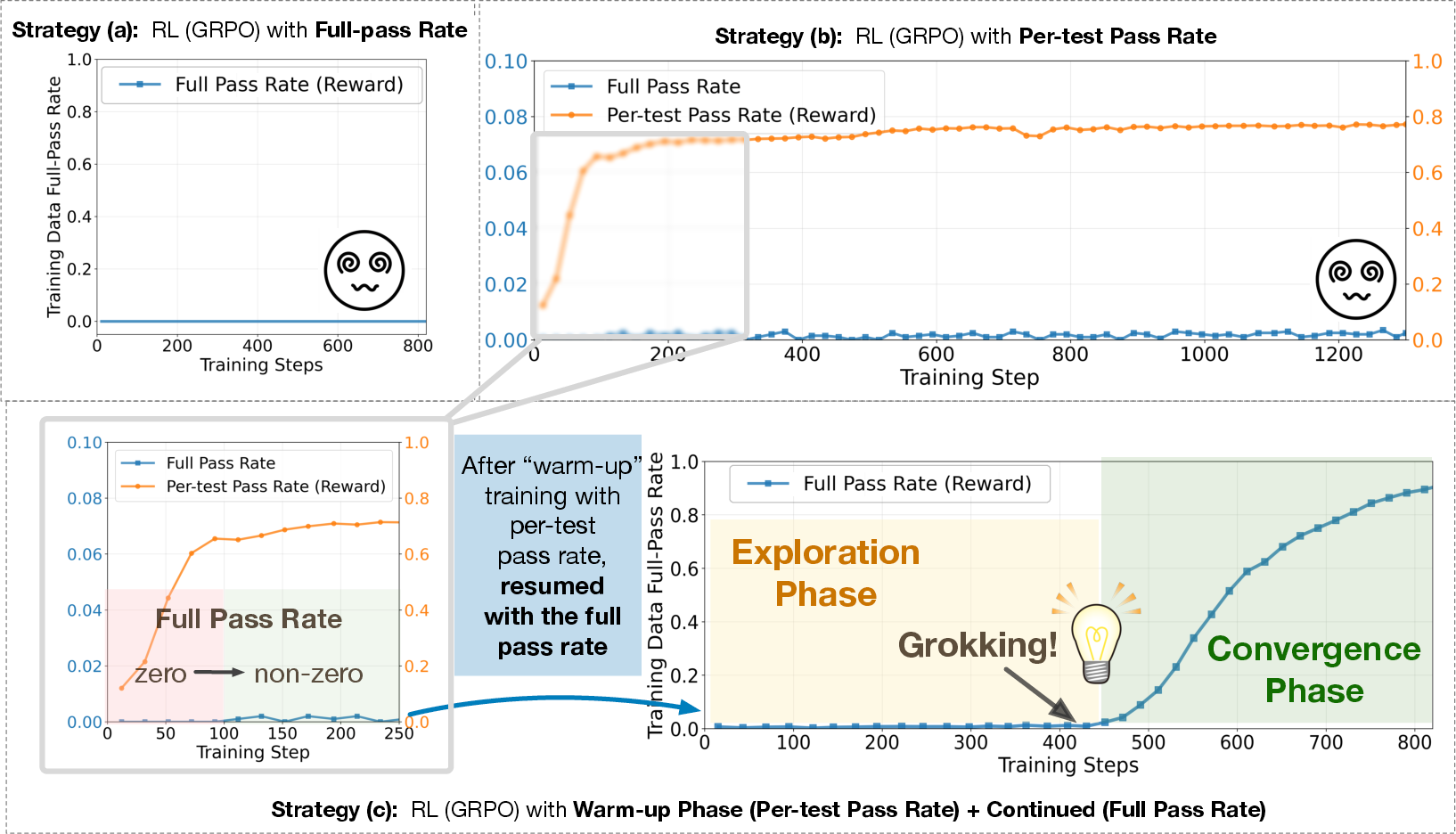
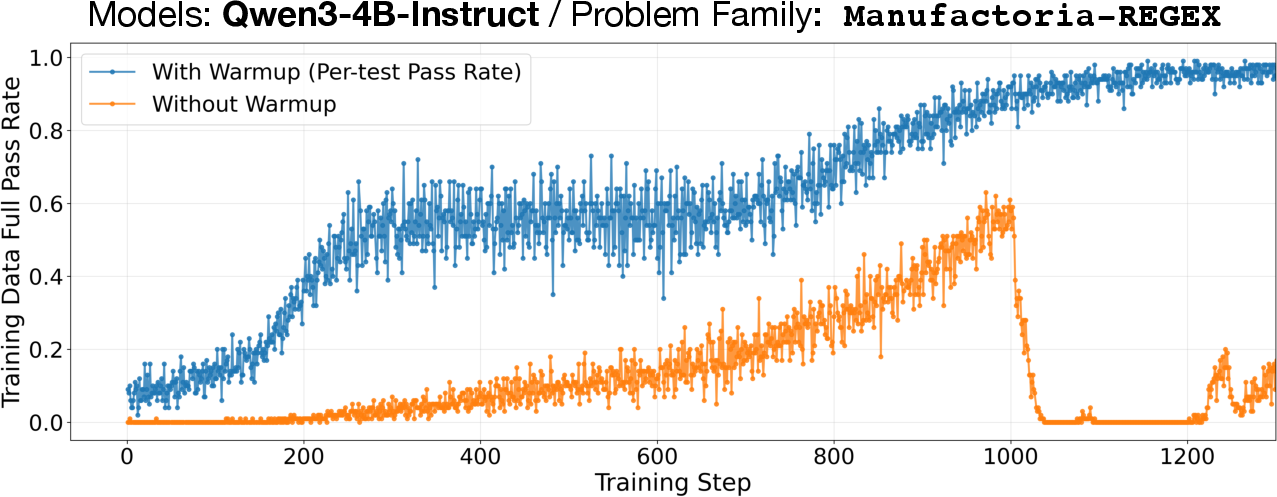
- Warm-up with dense rewards: At first, the model gets points for each test it passes, like getting partial credit on a quiz. This helps it move from “totally lost” to “on the right track.”
- Switch to strict rewards: Later, the model only gets a point if it passes all tests—like needing a perfect score to “win.” This sharpens the final solution.
- Extra helpers they tried:
- Experience replay: Save good past attempts and show them again so the model can learn from them—like keeping a notebook of solved examples.
- Feedback-in-the-loop: When the program fails, feed the error info back into the model mid‑generation to encourage a fix—like a teacher writing hints on your paper.
- Curriculum: Practice on easier, closely related puzzles before the harder target—like leveling up in a game.
What they found (main results)
- RL can unlock brand-new strategies the model didn’t have before.
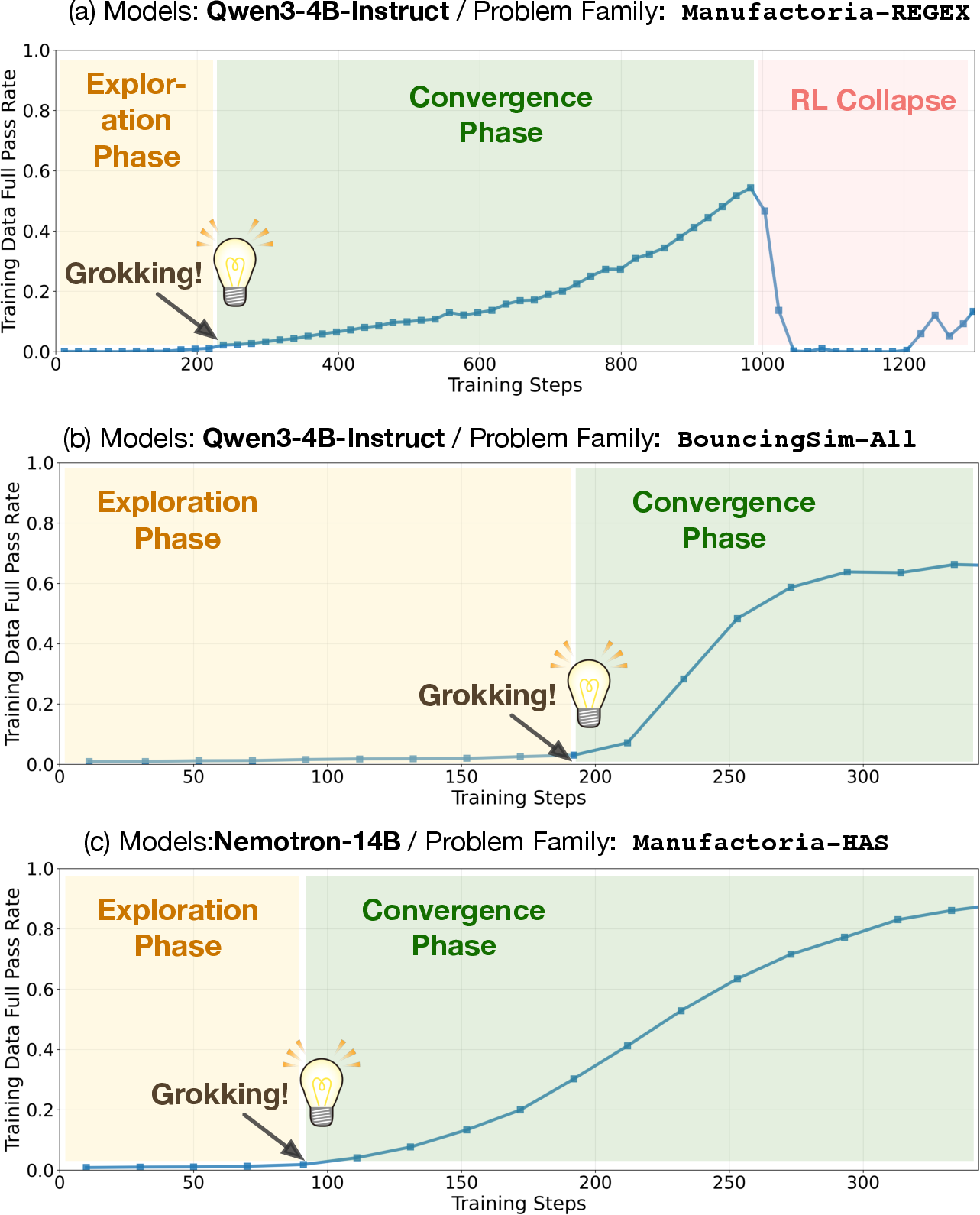
- On some Manufactoria problems, the base model failed every time even after many tries (this is called pass@K=0; think “we let it guess 128 times and it never got it”). After the warm-up + strict RL training, it suddenly learned the right procedure and reached near-perfect scores.
- This jump wasn’t gradual. It showed a “grokking” moment—after a long flat period of almost no progress, performance suddenly shot up. Think of practicing skateboard tricks for days with no success, and then it suddenly “clicks.”
- The training recipe matters a lot.
- Starting with partial-credit rewards (dense rewards) was crucial to escape the “no progress” zone.
- Adding experience replay and feedback sometimes sped things up but could also make training less stable.
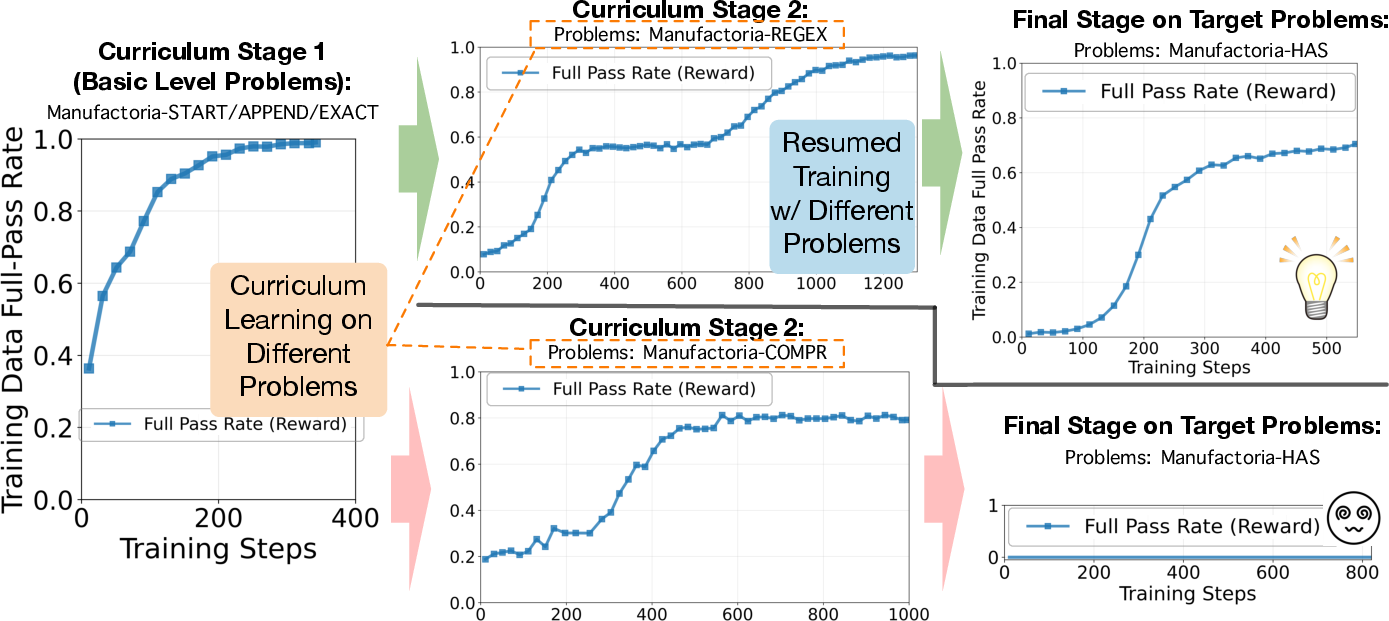
- Curriculum helped only when the “pre‑training” puzzles used truly similar thinking steps. A mismatch (even at the same difficulty) didn’t help.
- Generalization works—up to a point.
- Exploratory generalization: After training, models handled harder versions of the same skill pretty well (success dropped as difficulty rose, but there were still gains).
- Compositional generalization: When two learned skills were combined (like bouncing inside a rotating box with a rotating object), models did surprisingly well. Coding helps here because you can glue together working parts (functions, modules).
- Transformative generalization: When the test required a qualitatively different idea (like special initial states that cause perfectly repeating motion), models mostly failed. This needs genuinely new concepts, not just more of the same skill.
- Warm-up helps even when the task isn’t impossible.
- Even if the base model could rarely solve some cases, a brief warm-up with partial-credit rewards made learning faster and smoother.
- Not a magic wand.
- On some very hard families (e.g., a tougher Manufactoria variant), warm-up and RL still couldn’t break through. Model capacity and task difficulty still set limits.
Why this matters
- A cleaner way to study real reasoning: DELTA-Code gives researchers a controlled playground to test whether RL truly teaches new procedures, not just polishes guesses. Because the puzzles are synthetic and well-defined, we can pinpoint what changed in the model’s skill.
- Training design is as important as data: The same model can look weak or strong depending on the reward design and training steps. Staged rewards (partial credit first, strict later) can be the difference between “stuck forever” and “sudden mastery.”
- Building blocks for broader science and math: Coding naturally provides test cases for partial credit. If we build similar step‑by‑step checkers or rubrics for math and science, these RL tricks could help models learn tough reasoning there too.
- Clear limits guide future work: Models still struggle when a problem demands a completely new concept (transformative generalization). That shows where research should focus next: helping models invent new “schemas,” not just combine or scale existing ones.
In short: With the right feedback and training plan, reinforcement learning can teach LLMs genuinely new coding strategies and help them use those skills in new situations—though truly novel, concept-changing challenges remain the hardest frontier.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable directions for future research.
- Quantifying OOD status of Manufactoria: provide contamination checks (nearest-neighbor retrieval in pretraining corpora, fuzzy-matching of syntax/semantics, code-structure novelty metrics) to empirically validate “OOD-ness.”
- Distinguishing genuine algorithm acquisition from generator memorization: test transfer under adversarial generator changes (syntax perturbations, alternative DSLs, rule inversions) and measure solution diversity (program equivalence classes, automata abstractions).
- Mechanistic evidence for “new strategies”: extract and analyze learned finite-state machines or program schemas from generated solutions; study representation changes (e.g., probing, CCA, circuit-level analyses) before/after grokking.
- Compute/sample efficiency is underreported: specify and analyze tokens, wall-clock, gradient steps per unlocked family, and success per unit compute to understand practicality and scaling costs.
- RL algorithm coverage is narrow: compare GRPO to RLVR, PPO, A2C, off-policy methods, and policy-gradient variants to test whether RL-induced grokking is algorithm-agnostic.
- Decoding/proposal generation details missing for pass@K: standardize temperature, sampling strategy, deduplication, and failure-handling to make pass@K comparable and reproducible across studies.
- Two-phase warm-up lacks principled switching criteria: investigate automatic schedules (e.g., reward-signal thresholds, success-rate heuristics, bandit/meta-RL triggers) for transitioning from dense to binary rewards.
- Reward shaping beyond per-test pass rate: evaluate graded signals (test coverage weighting, static analysis lint rewards, partial-spec compliance, branch coverage) and their impacts on exploration and stability.
- Predicting “unlockability”: define diagnostics (e.g., gradient sparsity measures, partial-reward curvature, search-space hardness proxies) that forecast whether a family (like PREPEND) can be unlocked with given capacity.
- Experience replay design is underexplored: study buffer size, prioritization (e.g., TD-error, novelty), aging, off-policy corrections (importance sampling, V-trace) to reduce instability and accelerate convergence.
- Feedback-in-the-loop shows instability: assess multi-round verifier interaction, structured error messages, constraint-based repair, and on-policy integration to stabilize learning from feedback.
- Transformative generalization remains near zero: experiment with invariant discovery (symbolic constraints), hybrid neuro-symbolic modules, meta-learning for schema creation, and search-based program synthesis to target qualitative shifts.
- Cross-family/cross-domain transfer claims are limited: systematically quantify transfer across Manufactoria, BouncingSim, competitive programming, SQL, and Lean, including negative transfer and retention effects.
- Real-world robustness beyond synthetic templates: evaluate on human-authored problems and untemplated instances to test dependency on generator regularities and narrative surface cues.
- Unit-test sufficiency and reward hacking risks: add fuzzing, differential testing, mutation testing, adversarial test generation, and formal verification to reduce overfitting to tests.
- Numerical robustness in BouncingSim: document floating-point tolerances, integrator choices, determinism guarantees, and cross-engine validation (Box2D vs. other physics engines) to ensure reliable oracles.
- Tool-use constraints are unclear: enforce sandboxing, restrict external library calls, and audit generated code to verify that improvements arise from reasoning rather than tool delegation.
- Catastrophic forgetting and broader capability shifts unmeasured: test post-RL retention on unrelated tasks and families; quantify trade-offs between specialization and general competence.
- Model scale and architecture effects: establish scaling laws for learnability/grokking across sizes and families; test different architectures (Mixture-of-Experts, instruction-tuned vs. base) for generality.
- Data mixture and curriculum selection are ad hoc: systematically vary mixing ratios, family diversity, and ordering; formalize “structural compatibility” metrics to automatically discover effective curricula.
- Verification-in-the-loop parameters: study frequency, granularity, and format of verifier feedback; compare single-shot vs. iterative correction and integrate constraint solvers or SMT for stronger guidance.
- Generator bias and distributional severity: quantify difficulty via controlled knobs; report hardness curves; evaluate sensitivity to prompt wording, token budgets, and test distribution shifts.
- Statistical rigor and reproducibility: report variance, confidence intervals, seeds, and hyperparameter sensitivity; release full training logs and evaluation pipelines for independent replication.
- Theoretical account of RL grokking in LLMs is absent: develop and test theories linking reward sparsity, exploration dynamics, representation phase transitions, and credit assignment in sequence models.
- Warm-up vs. supervised fine-tuning: compare dense-reward warm-up against supervised training on partial solutions or hints to isolate the benefit of RL-specific exploration.
- Automatic curricula and meta-learning: explore automated curriculum search (e.g., Bayesian optimization over families, teacher–student frameworks) and meta-RL to adapt curricula per model/family.
- Extension beyond coding is speculative: validate the proposed principles in math/formal logic with stepwise checkers, theorem provers, and rubric-based scoring; measure whether dense-to-binary staging yields similar grokking.
- Pass@K=0 frontier tracking in mixed pools: design evaluation protocols that isolate hard subsets over time (e.g., persistent sampling, per-instance learning curves) to avoid dilution by easier items.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s released code, training recipes, and evaluation methodology.
- RL warm-up for code LLMs — Software
- What: Integrate staged dense-to-binary reward training (per-test pass rate warm-up followed by full-pass reward) into existing GRPO/PPO pipelines to unlock previously unsolved algorithmic families.
- Tools/workflows: “RL Studio for Code” plugin that wraps unit-test harnesses, dense reward shaping, and checkpoint switching; CI jobs that auto-run RL fine-tunes on hard program families.
- Assumptions/dependencies: Access to reliable unit tests and verifiers; sufficient compute; base model with minimal capacity; tasks framed as program synthesis with executable tests.
- Verifier-in-the-loop IDEs — Software, Education
- What: Augment IDE copilot flows with automatic test execution and failure-feedback injection (replace EOS with failing cases to steer regeneration).
- Tools/workflows: IDE extensions that run unit tests as the model generates code, inject counterexamples, and support iterative correction; replay cache of successful traces.
- Assumptions/dependencies: High-quality, fast test harnesses; guardrails for off-policy instability noted in the paper.
- Experience replay for code assistants — Software
- What: Cache successful reasoning traces/snippets and reattach them on similar prompts to improve success on hard tasks.
- Tools/workflows: Retrieval-augmented generation that indexes validated code solutions; prompt templates that include 1–3 recent successful traces.
- Assumptions/dependencies: Task similarity detection; careful handling of off-policy reuse to avoid instability.
- DELTA-based model evaluation gates — Industry QA, Policy
- What: Use DELTA’s controlled families (including OOD Manufactoria) as release gates for code models; report pass@K at large K and isolate “hard subset” performance.
- Tools/workflows: Benchmark dashboards tracking exploratory/compositional/transformative axes; “hard-subset monitor” to surface pass@K=0 cases.
- Assumptions/dependencies: Adoption of controlled, synthetic benchmarks in org QA; willingness to report axis-specific metrics beyond aggregate scores.
- Curriculum-aligned training for targeted skills — Academia, Software
- What: Build curricula that structurally match target families (e.g., REGEX→HAS) to accelerate grokking, avoiding misaligned families (e.g., COMPR→HAS).
- Tools/workflows: Curriculum planners that analyze structural skill overlap; data mixers tuned to family compatibility.
- Assumptions/dependencies: Domain expertise to diagnose skill alignment; monitoring for curriculum failures.
- Robust text-to-SQL assistants with backward generation — Finance, BI, Enterprise Software
- What: Adopt the paper’s pipeline that generates SQL first, verifies execution, derives unit tests, and regenerates NL queries for query–SQL consistency.
- Tools/workflows: SQL verifiers; unit-test generators for enterprise schemas; UI that shows verified results and counterexamples.
- Assumptions/dependencies: Stable DB access; schema-grounded validators; careful handling of data mutation queries.
- Lean formalization helpers — Education, Research Software
- What: Use controlled Lean families (algebra, number theory, inequalities, geometry) to train/evaluate proof assistants and guide students through graded steps.
- Tools/workflows: Problem generators with compositional variants; stepwise proof checkers; curriculum modules for math courses.
- Assumptions/dependencies: Availability of Lean toolchain; mapping between NL problems and formal statements.
- Simulation code validation with BouncingSim — Robotics, Graphics, Gaming
- What: Test LLM-generated physics/simulation code against deterministic oracles (e.g., Box2D), ensuring geometry-aware reasoning.
- Tools/workflows: Scenario generators across ROT_OBJ/ROT_BOX/MOV_BOX/GRAVITY/MULTI_* families; automatic oracle comparison; scorecards for parametric and compositional shifts.
- Assumptions/dependencies: Accurate oracles; numerical stability checks; well-defined physics constraints.
- Training governance and reporting — Policy, Compliance
- What: Standardize reporting to include grokking dynamics, training-phase choices, and axis-specific generalization, not just aggregate metrics.
- Tools/workflows: System cards that document reward design (dense→binary), experience replay, verifier-in-the-loop; dashboards that show phase transitions.
- Assumptions/dependencies: Policy buy-in; shared benchmark protocols; reproducibility of training logs.
- Learner-facing algorithmic practice with dense feedback — Daily Life, Education
- What: Educational platforms offering templated families with per-test feedback to help students “grok” algorithmic strategies.
- Tools/workflows: Interactive puzzle sets (e.g., Manufactoria-style) with immediate graded hints; staged test regimes mirroring the paper’s warm-up.
- Assumptions/dependencies: Content curation; scalable autograders; fairness and anti-cheating measures.
Long-Term Applications
The following applications require further research, scaling, or engineering to reach production-level robustness.
- Cross-domain RL with verifiable signals (math, logic, science) — Academia, Software
- What: Port dense-to-binary staged RL to mathematics (rubrics, step checkers), formal logic (theorem provers), and science (simulation/constraint evaluators).
- Tools/workflows: Stepwise graders, theorem-prover APIs, simulation oracles; adaptive curricula for transformative reasoning.
- Assumptions/dependencies: Reliable verifiers beyond coding; data design to avoid shortcuts and leakage; larger model capacity.
- Transformative reasoning acquisition — Software, Research
- What: Train models to discover qualitatively new solution schemas (periodicity, invariants) that remained near zero in the paper.
- Tools/workflows: Specialized evaluators for invariants/degenerate dynamics; exploration incentives beyond pass/fail; diversity-promoting replay.
- Assumptions/dependencies: Algorithmic innovation in RL objectives; richer reward shaping; prolonged training budgets.
- Safety-critical code synthesis with formal verification — Healthcare, Automotive/Aerospace, Energy
- What: Combine RL grokking with formal methods (Lean/Coq, model checking) to synthesize and verify control or device software.
- Tools/workflows: Proof-carrying code pipelines; end-to-end verification-in-the-loop; compliance reporting.
- Assumptions/dependencies: Industrial-grade formal specs; regulator acceptance; extremely low error tolerance; significant engineering investment.
- Enterprise-grade natural language database interfaces — Finance, Enterprise Software, Policy
- What: Production text-to-SQL systems with unit-test derivation, result verification, and governance (auditing, PII safety).
- Tools/workflows: Schema-aware NLI; query provenance; risk controls on data mutation; standardized test suites.
- Assumptions/dependencies: Complex multi-DB support; latency constraints; organizational adoption and data governance frameworks.
- Autonomous algorithm discovery for unknown tasks — Software, Robotics
- What: LLMs that, via prolonged RL, reliably unlock new algorithmic strategies on unseen, OOD problem families.
- Tools/workflows: Continual RL training farms; task generators; skill libraries that track learned procedures and transferability.
- Assumptions/dependencies: Large-scale compute; catastrophic forgetting mitigation; robust OOD detection and isolation.
- Sector-specific simulation coders — Engineering (CAD/CAE), Energy, Climate
- What: Assistants that generate physically accurate simulation code (CFD, grid dynamics, structural analysis) verified against domain oracles.
- Tools/workflows: Domain-specific oracles; uncertainty quantification; compositional scenario generators.
- Assumptions/dependencies: High-fidelity simulators; numerical robustness; integration with proprietary toolchains.
- Benchmarking standards and regulation — Policy, Standards Bodies
- What: Industry-wide standards for controlled OOD benchmarks, hard-subset reporting, and documentation of RL training choices.
- Tools/workflows: Standardized datasets and splits; certification protocols; public scoreboards with axis-level metrics.
- Assumptions/dependencies: Multi-stakeholder consensus; maintenance funding; alignment with safety evaluation.
- Personalized learning curricula with dense feedback — Education, Daily Life
- What: Adaptive tutors that use graded signals and curriculum alignment to help learners progress from exploratory to compositional skills.
- Tools/workflows: Skill graph mapping; micro-assessments; staged rewards; learning analytics tied to “grokking” detection.
- Assumptions/dependencies: Valid pedagogical models; privacy-preserving telemetry; content generalization beyond programming.
- RL training governance and phase-change monitoring — Industry, MLOps
- What: Tooling that detects grokking transitions, manages exploration plateaus, and schedules compute for hard-subset progress.
- Tools/workflows: Training telemetry; alerting on phase transitions; auto curriculum switching; replay memory hygiene.
- Assumptions/dependencies: Robust observability; reproducible pipelines; policy for intervening in training.
- Marketplaces for verified synthetic tasks — Industry, Academia
- What: Curated repositories of templated, verifiable families across domains to train/evaluate reasoning with clean distributional controls.
- Tools/workflows: Task generators, oracle libraries, contamination checks, licensing frameworks.
- Assumptions/dependencies: Community contributions; quality assurance; sustainable hosting and governance.
Glossary
- AM–GM: The arithmetic mean–geometric mean inequality, a fundamental result in real analysis used in inequality proofs. "inequalities; e.g., AMâGM, CauchyâSchwarz, Jensen"
- Boden’s creativity typology: A framework categorizing creative behavior into exploratory, combinational, and transformational forms. "DELTA extends OMEGAâs controlled tests along three axes aligned with Bodenâs creativity typology"
- BouncingSim: A synthetic programming benchmark involving a 2D bouncing-ball simulator used to test geometry-aware reasoning. "Full-pass rate (\%) on BouncingSim by model, family (ROT_OBJ, ROT_BOX, MOV_BOX, GRAVITY, MULTI_BOX, MULTI_OBJ), and difficulty tier (BasicExtreme)."
- Box2D: A physics engine used here to produce ground-truth trajectories for simulation tasks. "with ground-truth trajectories produced by Box2D"
- CDQ divide-and-conquer: An advanced divide-and-conquer technique used in competitive programming to handle certain convolution-like problems efficiently. "Each family groups problems sharing the same core algorithm (e.g., Moâs algorithm, CDQ divide-and-conquer)"
- Compositional generalization: The ability to integrate previously learned skills to solve new tasks that combine them. "Compositionalâcombine previously separate skills (e.g., bouncing ball with both rotating obstacles and boxes)"
- Cross-family transfer: Generalizing learned strategies from one problem family to different families. "as well as cross-family transfer"
- Curriculum learning: A training strategy that orders tasks from easier to harder to facilitate learning. "Selective curriculum learning as an alternative."
- Dense reward: A reward signal that provides graded feedback (not just binary success/failure), aiding learning on sparse-reward tasks. "staged warm-up with dense rewards"
- Difficulty ladder: A structured progression of problem difficulty levels used to evaluate and train models. "The Manufactoria difficulty ladder."
- Elastic collisions: Physics interactions where kinetic energy is conserved; here, central to the simulation tasks. "The goal is to synthesize a program that simulates elastic collisions in polygonal containers"
- EOS token: The special end-of-sequence token in LLM generation. "by replacing the EOS token with feedback"
- Experience replay: An RL technique that logs and reuses successful trajectories to improve learning stability. "Experience replay. The long exploration phases mainly stem from the sparsity of positive reward signals."
- Expert iteration: A training approach that iteratively improves a policy by learning from expert or high-quality trajectories. "closely related to expert iteration"
- Exploratory generalization: Extending known skills within the same family to harder or varied instances. "Exploratoryâextend known skills within a family (e.g., hexagon to octagon)"
- Feedback-in-the-loop: Injecting verifier or environment feedback directly into model generation to guide corrections. "Experience Replay + Feedback-in-the-loop"
- Finite-state automata: Abstract machines used to recognize patterns; here, analogous to the logic in Manufactoria. "resembles constructing finite-state automata or tag systems"
- GRPO: A reinforcement learning method for LLMs that optimizes generation based on reward differences across rollouts. "GRPO/PPO pipelines typically rely on a pass/fail reward"
- Grokking: A sudden phase transition from near-zero performance to mastery after prolonged training. "Our experiments reveal a striking grokking phase transition"
- Hierarchical paths: Database structures (e.g., recursive relationships) used as a category in text-to-SQL tasks. "problem family spec (7 categories: joins, set algebra, subqueries, windows, aggregation, hierarchical paths, data mutation)"
- Lean: A formal proof assistant and language used for mechanized mathematics. "LEAN. Four Lean-formalized math familiesâlean_algebra, lean_number_theory, lean_inequality, lean_geometry"
- Manufactoria: An out-of-distribution programming puzzle family with custom syntax inspired by a classic game. "Manufactoria is a classic Flash game (2010) in which players build automated factories to sort robots based on their colored tape patterns."
- Mo’s algorithm: A technique for answering offline range queries efficiently by special ordering. "Each family groups problems sharing the same core algorithm (e.g., Moâs algorithm, CDQ divide-and-conquer)"
- Numerically stable integration: Methods of updating continuous dynamics that avoid error accumulation. "and numerically stable integration"
- Off-policy: Using data generated by a different policy than the one currently being optimized. "likely because the reused traces are off-policy."
- OMEGA: A controlled benchmark of math problem families focusing on generalization axes. "OMEGA~\citep{sun2025omega} offers 40 synthesizable math families"
- Oracle: A trusted reference implementation used to verify correctness of generated programs. "the program must output the objectâs location at a target time and is scored against an oracle"
- Out-of-distribution (OOD): Test cases drawn from a distribution different from training, used to assess generalization. "transferabilityâ if learnability happens, can such skills transfer systematically to out-of-distribution (OOD) test sets?"
- Pass/fail reward: A sparse binary reward granting +1 only for completely correct solutions. "GRPO/PPO pipelines typically rely on a pass/fail reward: a perfect solution earns +1, anything else earns 0"
- pass@K: An evaluation metric measuring success rate over K independent attempts. "pass@K = 0 indicates that the model fails to solve the task even after many sampled attempts."
- Per-test pass rate: A dense reward reflecting the fraction of unit tests a solution passes. "programming enables cheap, graded feedback via perâtest case pass rates"
- Phase transition: A sharp, sudden change in learning dynamics or performance during training. "a striking grokking phase transition"
- PPO: Proximal Policy Optimization, a standard RL algorithm often used for policy updates. "GRPO/PPO pipelines typically rely on a pass/fail reward"
- ProRL: A prolonged RL approach claimed to expand reasoning boundaries in LLMs. "ProRL can expand reasoning boundaries on tasks where the base model performs poorly"
- RLVR: Reinforcement Learning with Verifiable Rewards; a framework for training with automatic correctness checks. "\citet{yue2025incentive} argue that although RLVR-trained models outperform their base models at small "
- Rollout: A single generated attempt or trajectory sampled during RL training. "GRPO~\citep{guo2025deepseek} depends on reward differences across rollouts."
- Staged training: A two-phase scheme using dense rewards first, then switching to binary rewards to achieve exact solutions. "supports staged training (dense reward then binary full-pass reward)"
- Tag systems: A computational model manipulating strings via deletion and appending rules, analogous to puzzle logic. "resembles constructing finite-state automata or tag systems"
- Templated problem generators: Programmatic templates that synthesize controlled problem instances to isolate skills. "DELTA isolates reasoning skills through templated problem generators"
- Transformative generalization: Generalizing to qualitatively new solution schemas not covered during training. "Transformativeâdiscover unconventional solutions"
- Verification-in-the-loop: Incorporating automated checking or test execution during training/generation to guide learning. "verification-in-the-loop."
- Warm-up stage: An initial phase that uses dense rewards to escape zero-signal regimes before switching to strict objectives. "Warm-up phase."
Collections
Sign up for free to add this paper to one or more collections.