- The paper introduces Market-Bench, a multi-agent testbed that integrates quantitative procurement with semantic marketing to evaluate LLM performance under economic constraints.
- It demonstrates that only select models, notably Gemini variants, achieve high profit margins through superior procurement efficiency in competitive auction environments.
- Evaluation metrics reveal that while language aids market entry via persona alignment, sustained advantage stems primarily from quantitative optimization rather than semantic differentiation.
Market-Bench: A Benchmark for Evaluating LLMs under Economic and Trade Competition
Motivation and Problem Statement
Prevailing LLM benchmarks seldom capture dual-process reasoning, instead isolating either quantitative or semantic faculties. This fails to probe whether LLMs can effectively coordinate optimization and communication within resource-limited, competitive economies—environments where mathematical decisions and persuasive language are simultaneously prerequisite for survival. "Market-Bench: Benchmarking LLMs on Economic and Trade Competition" (2604.05523) closes this evaluative gap by introducing a controlled, reproducible multi-agent testbed where LLMs are directly responsible for procurement, pricing, and marketing under budget and supply constraints, with economic fitness linked to both numerical optimization and language-grounded consumer engagement.
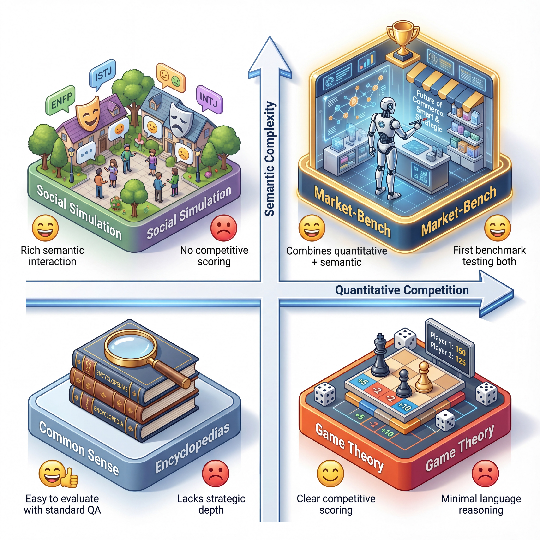
Figure 1: Market benchmarks typically separate quantitative competition and semantic complexity; Market-Bench unifies both under economic scarcity.
Market-Bench Environment Design
Market-Bench operationalizes a competitive two-stage supply chain with 20 LLM agents functioning as retailers. Each agent must:
- Procure inventory: Submit bids in constrained multi-unit first-price auctions with hard budget and reserve-price enforcement.
- Set retail prices and market: Choose item-wise prices and generate a brief, free-form slogan as a marketing message.
What differentiates Market-Bench is the Persona-Gated Attention mechanism. Buyers are sampled with hidden personas reflecting distinct motivational "tribes" (Thrifty, Ethical, Hype, Quality), each with their own semantic "slogan sensitivity." An agent's slogan is embedded and compared (cosine similarity) to buyer personas; buyers only consider sellers whose slogans align with their latent preferences. Only after passing this semantic "gate" does classic price competition occur. This tightly couples language understanding with economic outcomes, creating a hard test of composite LLM ability.
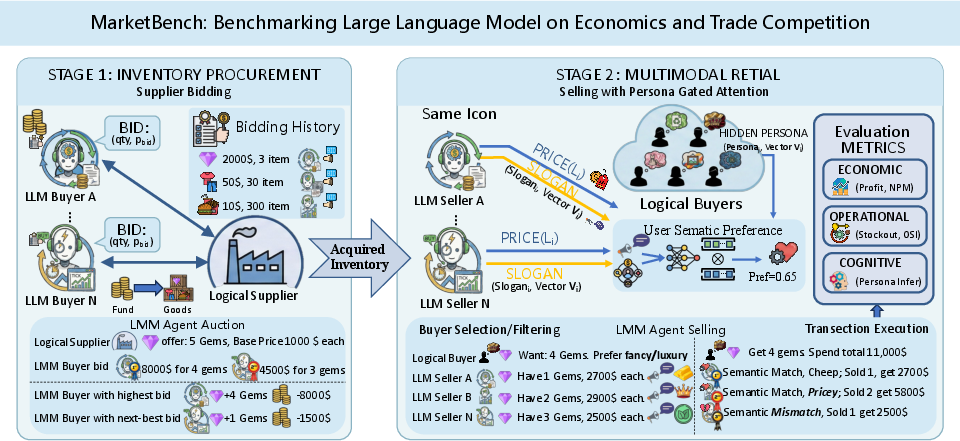
Figure 2: Market-Bench: Agents manage procurement, pricing, and marketing; language-persona alignment gates market access, evaluated with multidimensional economic and cognitive metrics.
Metrics and Evaluation Methodology
Market-Bench produces complete transaction-level logs for every episode, enabling calculation of both agent- and market-level metrics:
- Economic: Net profit margin (NPM), cumulative profit, risk-adjusted return (RAR).
- Operational: Inventory efficiency (IEI), stockout rate, BidEfficiency, FillRate, Order Stability Index (OSI).
- Cognitive: Mean Match Score (MMS)—average semantic similarity between agent slogans and buyer personas.
Market-level indices (Gini, Theil, CV, HHI, CR4, Active Ratio) are also computed to examine emergent macrodynamics such as inequality, concentration, and participation.
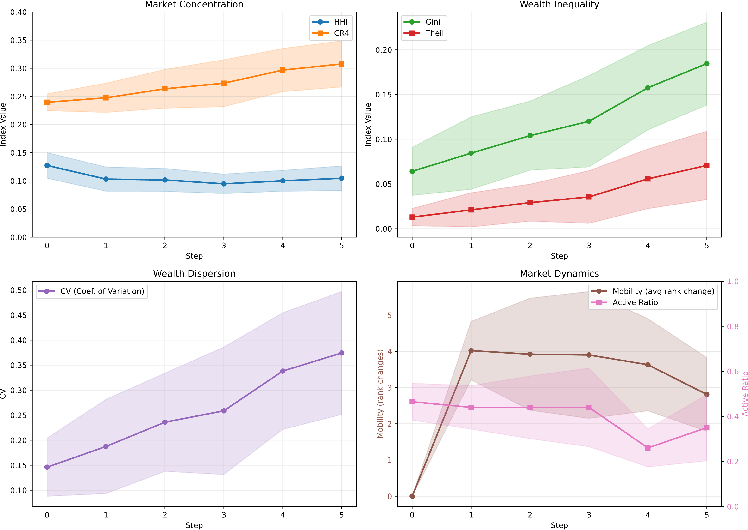
Figure 3: Market-level indices show rapid rises in inequality (Gini, Theil, CV), increasing top-4 share, and declining activity.
Experimental Results
The core finding is highly non-uniform performance across 20 LLMs, with significant separation into a "winner-take-most" regime. Despite uniform access to procurement and buyer pools, only a select minority of agents, notably Gemini 2.5 Pro and Gemini 2.5 Flash, consistently accumulate capital and maintain positive profit margins: NPM reaches up to 0.190 (Gemini 2.5 Flash) and cumulative profit up to 36,589 (Gemini 2.5 Pro). Many agents, including those with large parameter counts, remain consistently break-even or slip into bankruptcy, despite similar language-persona matching (MMS).
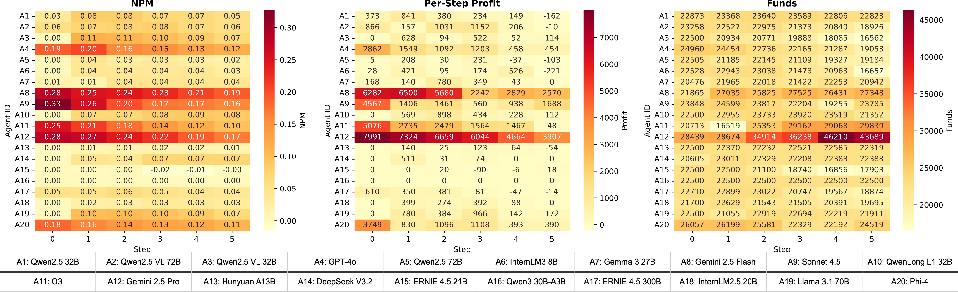
Figure 4: Economic metrics over time; a minority of models (Gemini variants) accumulate capital rapidly while the majority break even or decline.
A strong positive correlation exists between procurement success (BidEfficiency, FillRate) and profitability. Agents unable to consistently win supply in the auction rarely recover on downstream operations, regardless of pricing or slogan alignment. The regime is bimodal—early auction winners compound advantages; losers face persistent stockouts and stagnation.
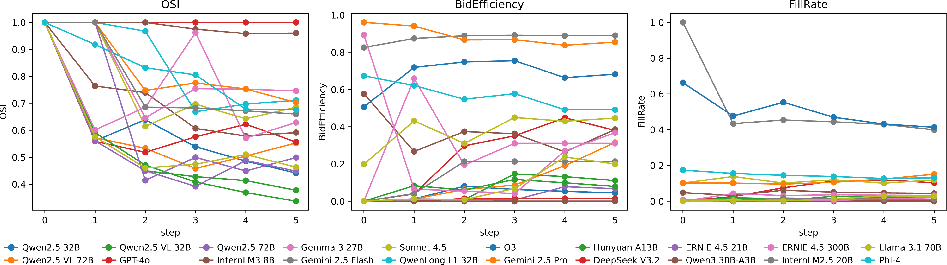
Figure 5: Agents with sustained high procurement efficiency (BidEfficiency) also maintain high FillRate and operational stability (OSI).
Language strategy exhibits rapid early adaptation but ultimately converges toward a "messaging equilibrium," with semantic similarities stabilizing after step one. There is only weak correlation between slogan-persona matching and realized profit, suggesting that, in this environment, language serves as a soft gate to entry rather than a distinct axis of sustainable advantage. Agents cluster near a generic slogan optimum aligned with dominant buyer personas, rather than exploiting nuanced segmentation or sustained differentiation.
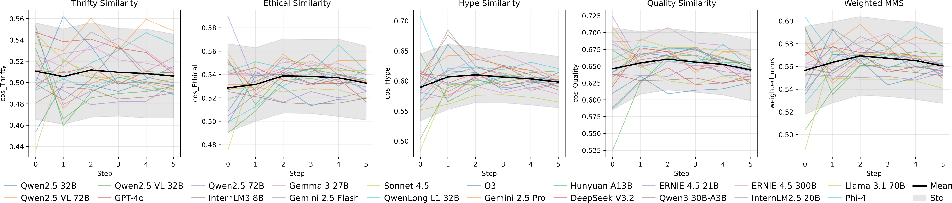
Figure 6: Slogan-persona similarities shift dramatically at entry but quickly stabilize, indicating fast strategic adaptation.
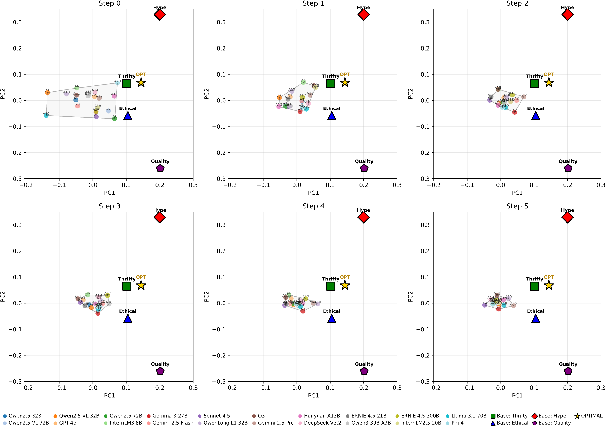
Figure 7: Slogan embedding clusters rapidly collapse—feedback drives agents into similar messaging strategies by step 5.
Theoretical and Practical Implications
- Coordination under Scarcity: Market-Bench demonstrates that, in resource-constrained competitive environments, economic differentiation arises not primarily from language or raw model scale but from the agent’s ability to couple strategic procurement (auction theory/optimization) with robust operational discipline.
- Emergent Inequality and Multiwinner Oligopoly: Standard indices confirm rapid stratification: Gini coefficients and CR4 rise, but the HHI remains well below monopolization thresholds, reflecting a stable oligopoly.
- Language as Admission, Not Differentiator: While slogans are necessary for market entry (by persona alignment), they confer little persistent benefit unless paired with procurement competence.
- Process Traceability for Model Diagnosis: The fully logged trajectories enable pinpointing not just model-level strengths/weaknesses but diagnosing at the process level—revising inventory, margin management, and semantic adaptation.
Open Challenges and Future Directions
The weak profit correlation with language matching reveals an open research problem: most LLM agents fail to exploit the semantic dimension for durable strategic segmentation. Breaking the emergent "messaging equilibrium" will likely require end-to-end agents able to co-optimize language and numeric policy, possibly through mechanisms for explicit persona inference, adaptive narrative generation, and joint modeling of revenue and audience fragmentation.
The Market-Bench architecture supports extensions to dynamic/stochastic supply, cross-market arbitrage, extended time horizons, and multilingual buyer populations, which will be required to stress-test next-generation LLM agents designed for real-world economic contexts.
Conclusion
Market-Bench introduces the first end-to-end, closed-loop economic testbed for LLM evaluation where both quantitative optimization and strategic language are jointly required for competitive survival. Empirical results falsify the presumption that large or language-proficient models will automatically excel: victory is dominated by agents capable of procurement competence, with language acting mainly as a market entry filter. This rigorously defined benchmark sets a new standard for research into LLM-enabled agent economies and exposes the compositional reasoning and adaptation frontier that future models must surpass to be effective in economic or market-facing applications.

