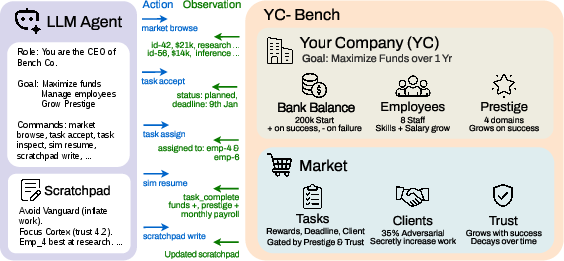
$\texttt{YC-Bench}$: Benchmarking AI Agents for Long-Term Planning and Consistent Execution
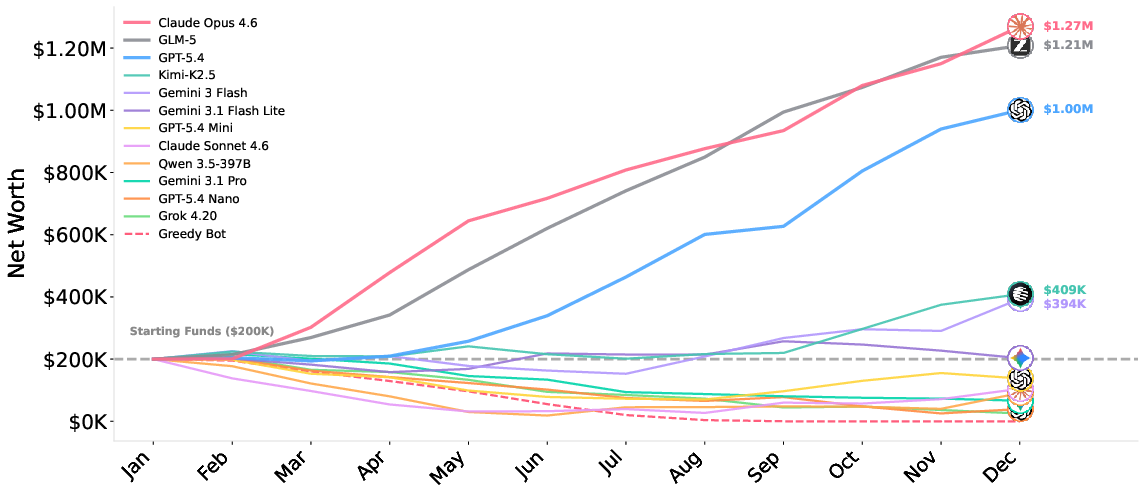
Abstract: As LLM agents tackle increasingly complex tasks, a critical question is whether they can maintain strategic coherence over long horizons: planning under uncertainty, learning from delayed feedback, and adapting when early mistakes compound. We introduce $\texttt{YC-Bench}$, a benchmark that evaluates these capabilities by tasking an agent with running a simulated startup over a one-year horizon spanning hundreds of turns. The agent must manage employees, select task contracts, and maintain profitability in a partially observable environment where adversarial clients and growing payroll create compounding consequences for poor decisions. We evaluate 12 models, both proprietary and open source, across 3 seeds each. Only three models consistently surpass the starting capital of \$200K, with Claude Opus 4.6 achieving the highest average final funds at \$1.27 M, followed by GLM-5 at \$1.21 M at 11$\times$ lower inference cost. Scratchpad usage, the sole mechanism for persisting information across context truncation, is the strongest predictor of success, and adversarial client detection is the primary failure mode, accounting for $47\%$ of bankruptcies. Our analysis reveals that frontier models still fail through distinct failure modes such as over-parallelization, demonstrating the capability gaps for long-horizon performance. $\texttt{YC-Bench}$ is open-source, reproducible, and configurable.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
YC-Bench: A plain‑language summary for teens
What is this paper about?
This paper introduces YC‑Bench, a “video game–like” test for AI agents. In the game, an AI runs a pretend startup company for a whole year. It has to choose which jobs (contracts) to take, assign the right employees, watch its cash, and avoid risky customers. The goal is simple: finish the year with more money than you started with.
What questions are the researchers asking?
They want to know:
- Can AI agents make smart plans that last a long time, not just quick fixes?
- Can they remember important facts over hundreds of decisions (like which customers to avoid)?
- Can they learn from mistakes that only show up much later (like a bad job leading to a missed deadline and a fine)?
- Which habits make an AI successful or likely to fail in this long, complicated setting?
How does YC‑Bench work? (Methods explained simply)
Think of YC‑Bench as a realistic business simulator with rules:
- You start with $200,000 and run a company for 12 months (hundreds of turns).
- Each turn, the AI sees some info (money, events) but not everything; it has to ask for details when needed. That’s called “partial information.”
- The AI picks contracts from different “clients,” assigns employees with different strengths, and pays salaries every month.
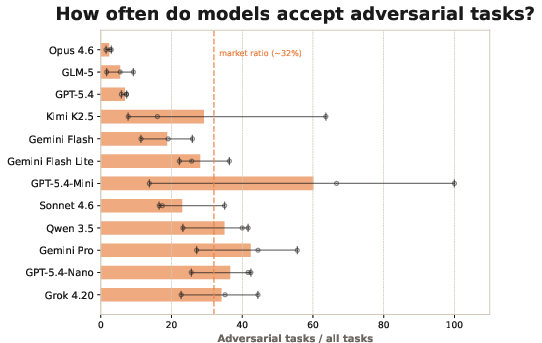
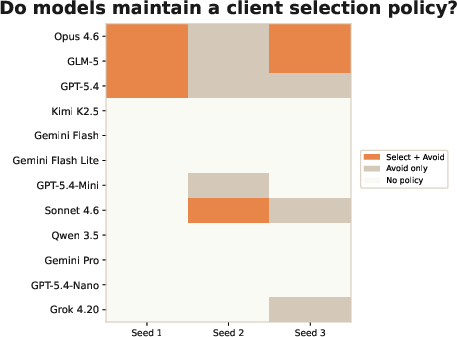
- Some clients are secretly “adversarial” (like scammy customers). Their jobs look great but are actually impossible to finish on time. The AI must figure out who these are by noticing patterns in its own history.
- There’s a memory limit: after about 20 turns, the AI “forgets” earlier conversation details unless it writes a short, persistent “scratchpad” (like keeping a notebook). This is the only way to remember things long‑term (e.g., “Never accept jobs from Client X”).
- Good decisions snowball into bigger rewards (trusted clients lower required work and unlock better jobs), while bad choices add up (salaries keep rising, missed deadlines cost money and reputation).
The researchers tested 12 different AI models and ran each three times. They also compared them to a simple “greedy” strategy that just picks the highest‑paying job and assigns everyone to it without thinking.
What did they find, and why does it matter?
Here are the main takeaways:
- Only a few AIs actually grew the business. Out of 12 models, only 3 consistently finished with more than the starting $200,000. The best average was about$1.27 million; another reached a similar level but with much lower computing cost.
- Remembering on purpose is crucial. The strongest predictor of success was using the scratchpad well—writing down which clients to trust, which to avoid, and which employees are best for each kind of work.
- “Tricky clients” sink companies. Not spotting adversarial clients caused 47% of bankruptcies. Many models either didn’t notice the pattern or didn’t act on it.
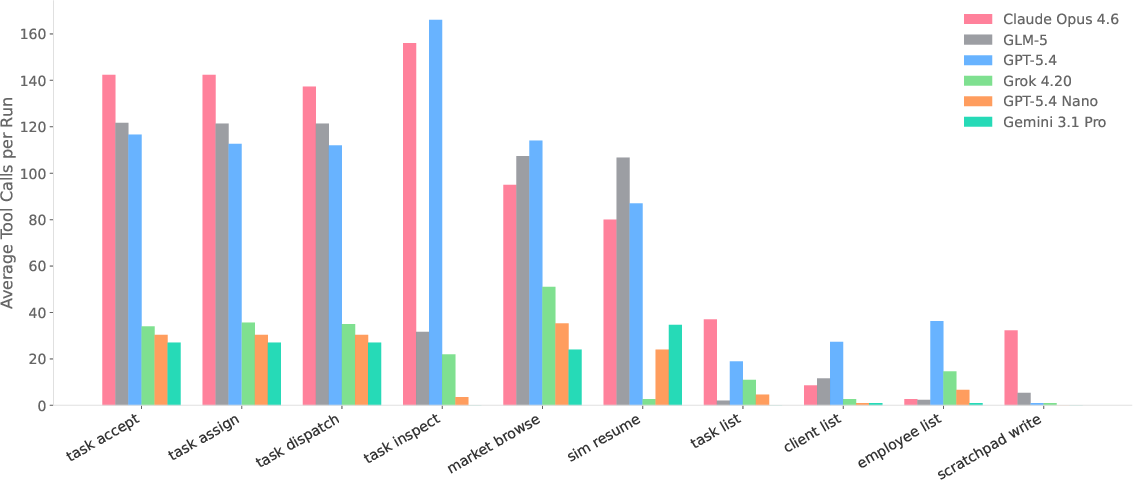
- Planning isn’t just thinking; it’s doing. Some AIs wrote good rules (“focus on one task at a time,” “check if we can finish before the deadline”) and then ignored them. Others repeated the same loop without reflecting. The best model both reflected and followed its own rules.
- Employee assignment matters a lot. Many failures came from assigning the wrong people to jobs or spreading them too thin, so tasks couldn’t be finished on time.
- Cost matters in the real world. Some models made lots of money in the game but cost a lot to run. Others earned less but were far more cost‑efficient (more “revenue per dollar of compute”).
Why it matters: Lots of common AI tests measure quick reasoning. YC‑Bench shows that long‑term success needs more: steady planning, memory, learning from delayed outcomes, and consistent execution. It reveals capability gaps that don’t show up on short, one‑step tasks.
What could this change or improve in the future?
- Better AI design: YC‑Bench highlights the need for AIs that can keep a reliable “notebook,” notice long‑term patterns (like risky clients), and then stick to the plan.
- Safer, more reliable agents: By testing how AIs handle uncertainty and sneaky problems, YC‑Bench can guide improvements for real‑world uses like project management, operations, and finance.
- Fairer comparisons: Because it’s open‑source and reproducible, researchers and developers can use YC‑Bench to compare models honestly and track progress on long‑term planning.
- Next steps: The authors suggest making the simulation even more realistic later (e.g., hiring/firing employees, random surprises), which could uncover new weaknesses and push AIs to improve.
In short: YC‑Bench is a year‑long startup simulator for AIs. It shows that to win over time, an AI must plan ahead, remember what matters, learn from slow feedback, avoid bad actors, and follow its own rules consistently.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves missing, uncertain, or unexplored:
- Causality of scratchpad effects: Only correlational evidence is provided that scratchpad use predicts success; no controlled ablations (e.g., same model with/without scratchpad, enforced memory discipline, or alternative memory mechanisms) establish causal impact.
- Memory design bias: The scratchpad is the sole long-term memory mechanism; the benchmark does not evaluate or compare structured memory alternatives (e.g., vector DB retrieval, MemGPT-style hierarchical memory, episodic vs semantic stores) or the trade-offs between memory length, cost, and performance.
- Fairness across model capabilities: A fixed 20-turn conversation history may advantage/disadvantage models with different native context limits or retrieval behaviors; the impact of context window size and prompt length on performance is not systematically studied.
- Sensitivity to environment parameters: No parameter sweeps test robustness to changes in adversarial client prevalence, work inflation magnitude, trust/decay rates, prestige scaling, salary growth, task deadlines, or reward distributions.
- Determinism vs realism: The environment is deterministic with hidden state; how results transfer to stochastic, noisy, or partially misspecified environments (delayed signals, observation errors, random shocks) remains untested.
- Simplified labor dynamics: Employees are fixed and cannot be hired/fired; the effects of staffing decisions, hiring pipelines, layoffs, ramp-up times, or skill drift on long-horizon planning are not evaluated.
- Limited exogenous disruptions: Only adversarial clients act as disruptions; the benchmark omits realistic shocks (market downturns, supply delays, regulatory changes) that could probe resilience and re-planning.
- Numerical, non-linguistic signals: Key quantities are provided as exact numbers; the benchmark does not test agents’ ability to parse noisy, incomplete, or narrative business reports, emails, or contracts expressed in natural language.
- Single-agent, non-competitive market: There is no competition for contracts or strategic interaction with other agents; how performance changes in competitive, multi-agent markets with bidding/negotiation is unknown.
- Narrow domain and task taxonomy: Four domains (training, inference, research, data engineering) are used; generalization to other industries, task mixes, or heterogeneous contract types (maintenance vs projects) is not assessed.
- Baseline coverage: Only a simple greedy baseline is included; comparisons to classical OR/heuristic planners, explicit schedulers, RL agents, or LLM+planner hybrids are missing.
- Statistical robustness: Only 3 seeds per model are reported; the paper lacks confidence intervals or significance tests to assess the reliability of model rankings and effect sizes.
- Attribution methodology transparency: The procedure for labeling task failure causes (e.g., adversarial vs misassignment vs overcommitment) is not fully specified (rules, thresholds, human validation, inter-rater reliability), leaving the breakdown’s validity uncertain.
- Cost-efficiency comparability: Revenue-per-API-dollar depends on provider pricing and may fluctuate; wall-clock latency, rate limits, and compute constraints are not incorporated, limiting operational relevance of the metric.
- Prompting and hyperparameter control: The impact of temperatures, decoding strategies, tool-calling formats, and system prompts across models is not ablated, leaving open whether performance gaps stem from modeling vs prompting.
- Version stability of proprietary models: Several evaluated models are preview/rapidly evolving; reproducibility across versions or over time is not quantified.
- Overfitting risk to an open benchmark: Because the environment is public and deterministic, models can be prompt-tuned to the benchmark; no hidden test scenarios or parameter-randomized variants are proposed to prevent benchmark gaming.
- Transfer validity: The paper does not test whether YC-Bench rankings predict performance on other long-horizon benchmarks (e.g., VB, BALROG games) or real-world agent tasks; cross-benchmark correlation is unknown.
- Reward shaping and metric diversity: Final funds is the primary scalar; no analysis of risk-adjusted returns, drawdowns, bankruptcy probability, portfolio stability, or multi-objective trade-offs (e.g., growth vs runway safety).
- Action granularity and tool reliability: The CLI actions are assumed reliable and atomic; the benchmark does not study tool failures, ambiguous API responses, or error recovery strategies.
- Reasoning–execution gap diagnosis: While observed, the root causes (planning errors, retrieval failures, self-consistency issues) are not disentangled with instrumentation (e.g., introspection probes, step-level audits) or targeted interventions.
- Learning across episodes: Despite references to multi-episode improvement, the experiments do not quantify whether agents learn policies over repeated runs (e.g., using summaries across episodes) or how quickly they improve.
- Seed difficulty calibration: The distribution of employee productivity, client sets, and task streams across seeds is not characterized; there is no analysis of whether certain seeds are systematically easier/harder.
- Trust and prestige dynamics validity: The chosen functional forms (linear prestige scaling, uniform trust decay) are not validated against real-world analogs or tested for alternative forms (e.g., diminishing returns, thresholds).
- Safety and reward hacking: The benchmark does not probe for emergent undesirable strategies (e.g., gaming metrics, deferring payroll via loopholes), nor does it stress test misalignment under high pressure or ambiguous rules.
- Multimodal information handling: The environment excludes documents, charts, or attachments; the ability to integrate multimodal signals into long-term plans remains unexplored.
- Human-in-the-loop settings: The benchmark evaluates fully autonomous agents; the effect of sparse human feedback, approval gates, or periodic interventions is not studied.
- Generalization over horizon length: Only a one-year horizon is used; how performance scales with longer/shorter horizons or with non-stationary regime shifts over time is unknown.
- Policy reproducibility within models: Run-to-run variance for the same model/prompt beyond three seeds is not reported, leaving intra-model stability underexplored.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage YC-Bench’s findings, artifact, and methodology today.
- Model selection and procurement for autonomous agents (software/finance/ops)
- What: Use YC-Bench to compare candidate LLMs by long-horizon reliability and cost-efficiency (e.g., revenue-per-API-dollar). Prefer models that show high profitability and disciplined scratchpad usage (e.g., GLM-5 where budgets are tight; Claude Opus where performance is paramount).
- Tools/products/workflows: “YC-Bench-in-the-loop” bakeoff before production; dashboards reporting bankruptcy probability, adversarial-task rate, trust buildup, and runway.
- Assumptions/dependencies: Benchmark dynamics are deterministic and industry-agnostic; requires mapping from simulated profit to domain-specific KPIs.
- Memory scaffolding for agents (software, enterprise automation)
- What: Adopt persistent scratchpads or memory vaults (e.g., MemGPT-like) as a default design pattern, since scratchpad usage is the strongest predictor of success in long-horizon tasks.
- Tools/products/workflows: Scratchpad middleware that auto-curates client lists, feasibility rules, and action checklists; CI rules that fail builds if scratchpad is underused.
- Assumptions/dependencies: Agents must support system-prompt injection or external memory stores; must respect organizational data governance.
- Risk-aware task acceptance policies (sales, professional services, BPO)
- What: Implement agent policies to blacklist/whitelist counterparties based on historical failures; add “adversarial client” detectors and enforce pre-acceptance checks.
- Tools/products/workflows: Client risk-scoring plugins; “acceptance guardrails” that block tasks failing feasibility or adversarial heuristics; audit logs tying failures to counterparties.
- Assumptions/dependencies: Requires reliable data capture on partner history; adversarial patterns differ by domain and need calibration.
- Portfolio focus to exploit “trust snowball” (CRM, platform marketplaces)
- What: Concentrate agent effort on a few counterparties early to compound trust-like benefits (reduced scope/work, higher-tier opportunities), mirroring the benchmark’s top performers.
- Tools/products/workflows: CRM integrations where agents track trust scores and prioritize tasks from “core accounts”; OKRs tied to deepening selected relationships.
- Assumptions/dependencies: Real environments must expose “trust” or proxy metrics (SLAs, discounts, easier processes) that actually compound with repeated success.
- Feasibility calculators and single-task enforcement (project management, software delivery)
- What: Equip agents with feasibility checks before task acceptance (required_qty/total_rate < hours_until_deadline) and enforce one-task-at-a-time or cap concurrency to avoid over-parallelization.
- Tools/products/workflows: Pre-acceptance feasibility modules; concurrency governors; automatic reallocation rules; alerts when estimated throughput < required pace.
- Assumptions/dependencies: Agent must know (or estimate) resource rates and deadlines; real throughput is stochastic and may need buffers.
- Cost-aware agent operations (finance, FinOps for AI)
- What: Optimize for “revenue per API dollar”; route simpler tasks to cheaper models (e.g., Kimi-K2.5, Gemini Flash) and keep complex planning with top models; set budget ceilings.
- Tools/products/workflows: Model-router with cost-performance thresholds; live spend dashboards and kill-switches when marginal ROI dips.
- Assumptions/dependencies: Requires accurate marginal value estimation per call; token costs vary by provider and may change.
- Pre-deployment red-teaming with adversarial scenarios (security, governance)
- What: Use YC-Bench to stress-test agents against adversarial counterparties and scope creep; track how quickly agents learn and avoid repeated traps.
- Tools/products/workflows: Adversarial task injectors in staging; failure-mode catalogs (e.g., adversarial acceptance rate, blacklist violations).
- Assumptions/dependencies: Needs domain-specific adversarial patterns and validation data to generalize beyond the benchmark.
- Training curricula for long-horizon coherence (L&D, academia, internal AI upskilling)
- What: Teach operators and students the “perceive → record → retrieve → act consistently” pipeline; run labs on client-selection strategy, memory discipline, and payroll/runway management.
- Tools/products/workflows: Coursework modules using YC-Bench; evaluation rubrics for memory quality and policy adherence.
- Assumptions/dependencies: Translating simulated lessons to sector reality needs domain mapping and real KPIs.
- MLOps guardrails for agentic systems (software engineering)
- What: Add deployment gates: agents must meet minimum YC-Bench scores on profitability, adversarial avoidance, and memory usage before shipping.
- Tools/products/workflows: CI checks; regression tests comparing new model versions against historical YC-Bench baselines.
- Assumptions/dependencies: Requires maintenance of benchmark versions and thresholds; risk of overfitting agents to the benchmark format.
- Personal productivity assistants with robust memory (daily life/education)
- What: Configure personal AI assistants to keep persistent scratchpads (deadlines, vendor reliability, “do-not-work-with” lists) and enforce feasibility before accepting commitments.
- Tools/products/workflows: Scratchpad templates for projects; “commitment sanity checks” and focus-mode enforcement.
- Assumptions/dependencies: Users must allow persistent storage; privacy and data retention policies apply.
- Vendor reliability tracking for procurement (operations, supply chain)
- What: Maintain live blacklists/whitelists based on on-time delivery, quality, and scope changes; instruct agents to avoid risky vendors despite attractive pricing.
- Tools/products/workflows: Procurement agent plug-ins; exception approvals required to engage blacklisted vendors.
- Assumptions/dependencies: Accurate vendor performance data; incentives aligned to discourage short-term “cheap but risky” choices.
- Benchmark-driven product marketing and pricing (AI vendors)
- What: Report YC-Bench results (profitability, cost-efficiency) to customers; tailor pricing/SLA tiers tied to long-horizon performance.
- Tools/products/workflows: Public scorecards; performance-based pricing pilots.
- Assumptions/dependencies: Customers accept benchmark relevance; periodic re-benchmarks needed as models update.
Long-Term Applications
These applications require further research, scaling, or domain adaptation beyond the current YC-Bench scope.
- Sector-specific long-horizon certification for autonomous agents (healthcare, finance, gov)
- What: Regulatory-style test suites adapted from YC-Bench to certify agents for sensitive workflows (e.g., revenue cycle, claims, case management).
- Tools/products/workflows: Standardized “agent driving tests” with adversarial injects; certification bodies and audit trails.
- Assumptions/dependencies: Requires sector datasets, safety rules, and interpretability standards; policy consensus needed.
- Realistic stochastic environments and exogenous shocks (operations, macro risk)
- What: Extend the benchmark to include hiring/firing, random disruptions, and natural-language noise (e.g., ambiguous requirements).
- Tools/products/workflows: Next-gen simulators for resilience testing (sick leave, supplier delays, demand shocks).
- Assumptions/dependencies: Higher simulation complexity; data for shock distributions and calibration.
- Architectures that close the reasoning–execution gap (AI research, software)
- What: Develop agent designs that tie reflection to action (e.g., policy compilation from scratchpad rules, action contracts, self-verification).
- Tools/products/workflows: “Policy binder” that converts written rules into executable constraints; plan–do–check–act loops with automatic enforcement.
- Assumptions/dependencies: Advances in tool-use reliability and controllability; careful avoidance of over-constraint or brittleness.
- Learned adversarial-counterparty detectors (finance, marketplaces, trust & safety)
- What: Train models to infer counterparty risk from multi-episode histories and subtle scope inflation patterns; generalize across domains.
- Tools/products/workflows: Sequence models over interaction logs; early-warning signals and “hold to review” workflows.
- Assumptions/dependencies: Requires labeled histories and feedback loops; potential for false positives with business impact.
- Memory management and curation systems (AgentOS)
- What: Automated memory pruning, salience scoring, and retrieval to keep only policies and facts that drive outcomes; reduce hallucinated or stale rules.
- Tools/products/workflows: Memory optimizers; change-detection and policy-refresh pipelines.
- Assumptions/dependencies: Requires robust instrumentation linking memory entries to performance; privacy-compliant storage.
- Cross-agent coordination and resource allocation (multi-team orgs, robotics fleets)
- What: Generalize from single-agent payroll/assignment to multi-agent coordination under partial observability and compounding costs.
- Tools/products/workflows: Coordinated schedulers; shared memory ledgers and conflict-resolution protocols.
- Assumptions/dependencies: Communication reliability and synchronization; added complexity in credit assignment.
- Long-horizon RL/finetuning curricula (AI research)
- What: Use YC-Bench variants for RL or constitutional/reflection fine-tuning targeting adversarial avoidance, disciplined memory, and focus.
- Tools/products/workflows: Self-play and curriculum learning with increasing horizon and adversarial intensity.
- Assumptions/dependencies: Stable training signals over long horizons; robust offline–online transfer.
- Organizational planning assistants with runway/payroll awareness (startups, SMEs)
- What: Agents that simulate cash runway, rising payroll, and task portfolio to advise founders on contract mix and client focus over quarters.
- Tools/products/workflows: FP&A-integrated planning copilot; scenario analysis with trust and prestige proxies (e.g., customer LTV, partner tiers).
- Assumptions/dependencies: Requires integration with finance systems; mapping “prestige” to real commercial unlocks.
- Education and assessment for operations management (academia, executive education)
- What: Case-based curricula and competitions that evaluate strategic coherence over hundreds of steps; scorecards on memory, risk, and focus.
- Tools/products/workflows: Courseware with instructor dashboards and auto-grading on long-horizon metrics.
- Assumptions/dependencies: Need domain contextualization and rubrics that reflect real-world constraints.
- Safety and governance analytics for autonomous operations (policy, compliance)
- What: Metrics and thresholds (e.g., max adversarial acceptance rate, blacklist violations, memory staleness) baked into governance for autonomous workflows.
- Tools/products/workflows: Continuous assurance pipelines; incident postmortems tied to memory and policy adherence signals.
- Assumptions/dependencies: Monitoring infrastructure and standardized telemetry; clarity on acceptable risk thresholds.
- Domain-adapted benchmarks (healthcare, education, energy)
- What: YC-Bench-style testbeds for clinical scheduling, tutoring over a semester, or energy dispatch over seasons.
- Tools/products/workflows: Sector simulators with delayed rewards and adversarial elements (e.g., insurer denials, disengaged students, price spikes).
- Assumptions/dependencies: Requires expert-designed dynamics and validation datasets; ethical and regulatory constraints.
- Economic simulations for market design and policy testing (economics, public policy)
- What: Use agent-based variants to study how different rules (e.g., penalties, trust decay, pricing) affect market outcomes and resilience.
- Tools/products/workflows: Policy sandboxes; stress tests for proposed regulations involving autonomous agents.
- Assumptions/dependencies: External validity from simulation to real markets; agreement on modeling assumptions.
In all cases, the core takeaways from YC-Bench—persistent memory as a first-class capability, risk-aware selection under partial observability, disciplined focus to harness compounding benefits, and sensitivity to cost-efficiency—translate into concrete design rules and evaluation gates for deploying agentic systems in consequential settings.
Glossary
- Action space: The set of all actions available to the agent at any point. "The full agent action space is in Appendix~\ref{app:action-space}."
- Adversarial clients: Clients whose tasks are intentionally structured to be nearly impossible by inflating required work after acceptance. "A subset of clients are adversarial: after the agent accepts one of their tasks, the environment inflates the work quantity, making the deadline nearly impossible to meet."
- Agentic capabilities: The capacity of LLMs to autonomously plan, decide, and act over multiple steps using tools and interactions. "The rapid growth of agentic capabilities of LLMs has spawned a rich ecosystem of benchmarks."
- Bankruptcy: The terminal state where company funds fall below zero, ending the episode. "The episode terminates when funds drop below zero (bankruptcy) or the horizon ends."
- CLI: Command-line interface used by the agent to interact with the environment via commands. "The agent operates through a CLI tool interface"
- Client blacklist: A recorded list of clients to avoid due to repeated failures or adversarial behavior. "building a client blacklist"
- Client trust: A per-client relationship metric that reduces future workload and unlocks higher-tier tasks when increased. "The agent builds trust with a client by completing its tasks successfully; higher trust reduces the work required on future tasks from that client and unlocks higher-tier tasks."
- Context truncation: The removal of older turns from conversation history due to context length limits. "Scratchpad usage, the sole mechanism for persisting information across context truncation, is the strongest predictor of success"
- Context window: The maximum number of recent turns retained in the agent’s context before older interactions are truncated. "through a 20-turn context window that forces the agent to use a persistent scratchpad for memory"
- Cost-efficiency: Performance relative to API inference cost, often measured as revenue per dollar spent. "There is also a significant gap in cost-efficiency with open-source models being more Pareto optimal than their counterparts."
- Deterministic but unknown dynamics: Environment transitions and observations that are fixed given actions but not revealed to the agent. "a POMDP-based benchmark with deterministic but unknown transition and observation dynamics."
- Deterministic transition function: A mapping from current state and action to a unique next state. " is the deterministic transition function"
- Domain prestige: A per-domain reputation level that gates task access and scales payouts. "The agent maintains a prestige level in each domain"
- Failure modes: Recurrent patterns of errors leading to poor outcomes (e.g., missed deadlines, bad assignments). "frontier models still fail through distinct failure modes such as over-parallelization"
- Frontier models: The most capable, cutting-edge LLMs at a given time. "frontier models still fail through distinct failure modes such as over-parallelization"
- Greedy baseline: A simple policy that always chooses the immediate highest-reward option without strategic planning. "We compare against a greedy baseline that, in each turn, accepts the highest-reward task available on the market"
- Information-asymmetry: A setting where some relevant variables are hidden and must be inferred from outcomes. "hidden employee skill rates that create an information-asymmetry puzzle"
- Multi-episode learning framework: A setup where agents can improve across restarts or repeated episodes. "a multi-episode learning framework that tests whether agents can improve across restarts."
- Observation space: The set of possible observations available to the agent at each turn. " is the observation space"
- Over-parallelization: Taking on too many tasks simultaneously, causing diluted focus and missed deadlines. "distinct failure modes such as over-parallelization"
- Pareto optimal: Achieving a superior trade-off such that improving one metric would worsen another. "open-source models being more Pareto optimal than their counterparts."
- Partially observable environment: An environment where the agent cannot directly observe the full state and must infer hidden factors. "in a partially observable environment where adversarial clients and growing payroll create compounding consequences for poor decisions."
- Partially Observable Markov Decision Process (POMDP): A framework modeling decision-making with hidden states and observations. "We formalize YC-Bench as a Partially Observable Markov Decision Process (POMDP)"
- Reward function: The mapping from state and action to a scalar signal measuring immediate utility. " is the reward function defined as the net change in company funds."
- Runway: The estimated time before funds are depleted given current burn rate. "Runway down to 1 month,"
- Scope creep: Expansion of task scope beyond initial estimates, increasing required work. "Analyzing how the models deal with adversarial clients, who have appealing rewards when accepting a task but have a lot more work than claimed (scope creep)."
- Scratchpad: A persistent memory channel where the agent writes notes to survive context truncation across turns. "the agent may write to a persistent scratchpad that is injected into the system prompt on every turn."
- Seed: A fixed random initialization used to replicate stochastic components across runs. "We evaluate 12 models, both proprietary and open-source, across 3 seeds each."
- Simulation clock: The controllable mechanism that advances simulated time to the next event. "Simulation Clock. The agent controls the passage of simulated time explicitly."
- State space: The set of all possible environment configurations. " is the state space"
- Throughput: The amount of work an employee completes per unit time in a given domain. "a senior-tier employee may have senior-level throughput in training but junior-level throughput in research."
- Trust-gated task selection: Choosing tasks based on earned client trust thresholds that unlock higher-tier opportunities. "tracking per-client success rates to optimize trust-gated task selection."
- Trust snowball: A compounding effect where increasing trust reduces workload, enabling more completions and further trust gains. "triggering a trust snowball: each success reduces future task workloads (up to 50\%), enabling more completions per month, which builds further trust."
Collections
Sign up for free to add this paper to one or more collections.

