- The paper introduces LatentAudit, a fast white-box method that uses mid-to-late transformer activations and a Mahalanobis distance-based metric to assess answer-evidence alignment.
- The paper demonstrates robust performance across models and domains with AUROC scores above 0.91 and sub-millisecond latency, ensuring efficient deployment.
- The paper further enables on-chain verifiable audits via zk-SNARK circuits, addressing privacy and operational efficiency in high-stakes applications.
LatentAudit: Real-Time White-Box Faithfulness Monitoring for RAG with Verifiable Deployment
Introduction and Problem Setting
Automated verification of answer faithfulness in retrieval-augmented generation (RAG) systems remains an open challenge, particularly for high-stakes domains such as medical and legal decision support. Prominent methods depend on either routing outputs to large, external judge models (like GPT-4) or performing ensemble consistency checks, both of which introduce significant latency and privacy issues. Most approaches treat the RAG generator as a black box, failing to leverage the rich internal structure of transformer LLMs.
This work introduces LatentAudit, a white-box, real-time auditor for RAG faithfulness. Unlike previous approaches, LatentAudit leverages the mid-to-late residual activations of open-weight LLMs, directly measuring the alignment between generated answers and retrieved evidence in a high-dimensional geometric space. The method employs a Mahalanobis distance-based decision rule and calibrates a threshold using only a small held-out set, without training auxiliary networks. Furthermore, the pipeline is compatible with zero-knowledge proof systems (zkML), supporting verifiable deployment on-chain without disclosure of sensitive activations or model weights.
LatentAudit Pipeline: Mechanistic and Mathematical Foundations
LatentAudit operates in two modular stages: a real-time activation auditor and an optional verifiable deployment layer.
1. Answer-State Representation and Pooling
The auditor targets the residual-stream representations at mid-to-late transformer layers (empirically, layers 14–16 for Llama, others for different families). For each inference, the activations corresponding to the salient answer span tokens are mean-pooled to produce a stable answer-state vector.
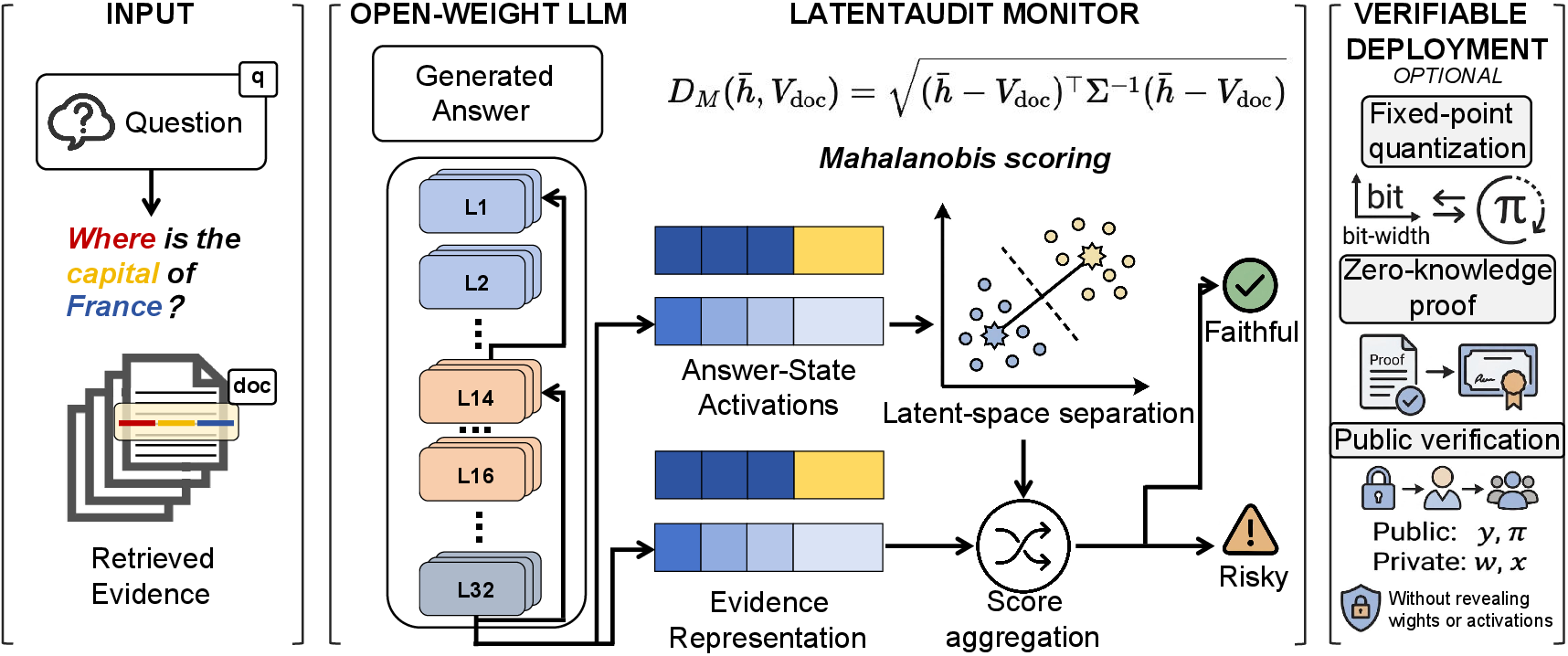
Figure 1: Overview of the LatentAudit pipeline, from RAG input to geometric monitor and optional zk-SNARK verifiable output.
2. Evidence-Answer Alignment via Residual-Stream Geometry
The retrieved evidence is embedded using a sentence encoder (all-MiniLM-L6-v2), then mapped via a linear projection (fit using ridge regression on a tiny calibration split) to align dimensions with the LLM residual stream. The Mahalanobis distance between the pooled answer-state and projected evidence embedding provides the alignment score. The inverted covariance for this metric is also estimated from the calibration set. This approach directly accounts for the anisotropy in LLM latent spaces, where Euclidean distance fails to provide sufficient separation between supported and hallucinated completions.
3. Thresholding and Decision Rule
A threshold τ∗ maximizing Youden's J statistic on the calibration set partitions answers as faithful or risky. This simple quadratic rule does not require training an auxiliary classifier and yields a fixed-size summary, making inference highly efficient.
4. Zero-Knowledge Verifiable Deployment
Because the Mahalanobis test is a quadratic form in finite fields, the same decision can be implemented as a compact zk-SNARK circuit (Groth16 via EZKL), making it possible to publicly verify audit claims on-chain without revealing the model's internal activations or proprietary details.
Emergence and Robustness of the Latent Faithfulness Signal
Emergence of Discriminative Power in Residual Activations
Internal-state based faithfulness monitoring is only feasible if the geometric regularity exists and is accessible. t-SNE analyses across audit layers and models show that separability between faithful and contradicted generations emerges conspicuously in the mid-to-late residual layers.
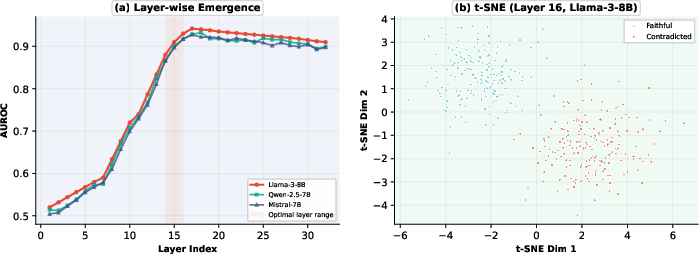
Figure 2: Discrimination between faithful and contradicted completions emerges sharply in the mid-to-late residual activations (layer 16).
Numerically, on PubMedQA with Llama-3-8B, the monitor achieves a 0.942 AUROC at only 0.77 ms overhead, closely trailing the GPT-4o judge while remaining several orders of magnitude faster and more cost-efficient.
Geometric Separation: Architecture and Domain Invariance
Rigorous cross-model and cross-domain experiments were conducted across five SOTA model families (Llama-2/3, Qwen-2.5/3, Mistral) and three QA benchmarks (PubMedQA, TriviaQA, HotpotQA). The faithfulness signal, as revealed by the Mahalanobis auditor, is not confined to any single model family or domain. AUROC scores remain above 0.91 for all substantial test conditions.
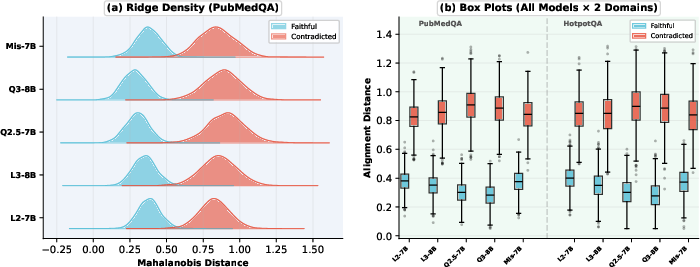
Figure 3: The separation between faithful and contradicted completions is robust across families and domains, enabling a fixed-threshold decision.
Per-model Mahalanobis distance distributions are consistently bimodal across architectures, further suggesting robustness.
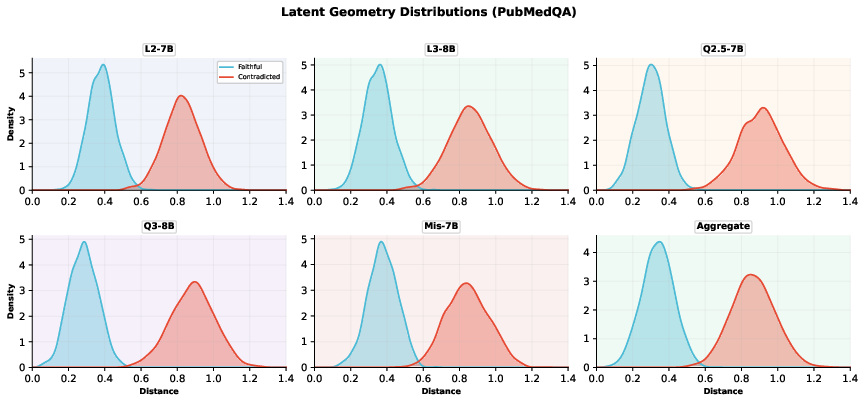
Figure 4: Per-model Mahalanobis distance distributions on PubMedQA demonstrate clear separation, aggregated and per-family.
Stress Testing Realistic RAG Failures
RAG pipelines rarely fail only by outright contradiction; retrieval misses and incomplete evidence are more difficult. The stress test expands the negative class to include (1) outright contradicted, (2) retrieval-miss, and (3) partial-support examples.
LatentAudit achieves 0.9566–0.9815 AUROC for PubMedQA and 0.9142–0.9315 for HotpotQA under this four-way stress regime. The hardest challenge is partial support, where high lexical overlap is not indicative of evidence-faithfulness but the geometric metric remains discriminative.
Deployment Efficiency and zkML Integration
A principal advantage of LatentAudit lies in its computational and financial cost profile. The Mahalanobis audit adds less than 1 ms per query (0.77 ms), compared with ∼5300 ms for GPT-4o judges or 28.5 seconds for SelfCheckGPT. For on-chain or verifiable deployment, 16-bit fixed-point quantization preserves 99.8% of the floating-point AUROC, and zk proving/verification times keep deployment within practical bounds.
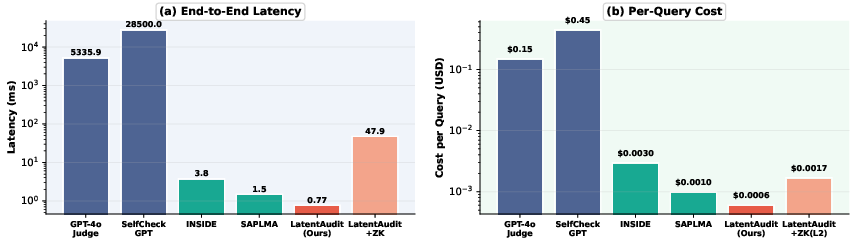
Figure 5: End-to-end latency analysis; the audit adds sub-millisecond overhead, with optional zk proof only moderately increasing total deployment cost.
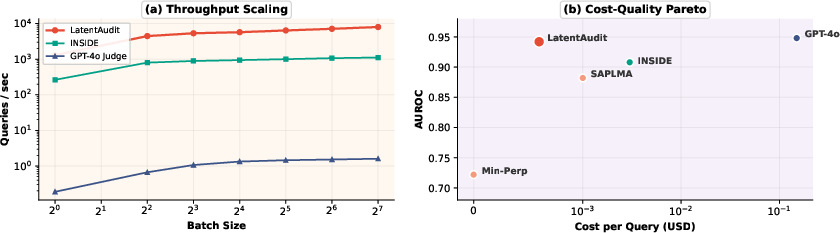
Figure 6: (a) Throughput scaling as a function of batch size; (b) LatentAudit’s cost-quality trade-off is strictly Pareto-dominant compared to judge-model baselines.
Limitations and Theoretical Implications
- Open-weights Restriction: The auditor presumes access to internal activations and cannot be applied directly to black-box models without adaptation.
- Evidence Poisoning: Monitoring faithfulness to retrieved content, not ground-truth, means security depends on the retrieval mechanism.
- Frontier Scaling: While performance is stable up to 8B parameters, scaling properties for much larger models (e.g., 70B+) remain to be empirically characterized, though the authors hypothesize greater geometric separability.
The broader theoretical implication is that transformer residual geometry, specifically in mid-to-late layers, systematically encodes faithfulness to conditioning context, and this structure is sufficiently regular for white-box auditing without training additional neural machinery.
Conclusion
LatentAudit effectively shifts the paradigm for faithfulness monitoring in RAG from slow, black-box, output-level behavioral testing toward fast, mechanistic, and white-box interventions leveraging residual-stream geometry. Its sub-millisecond latency, domain-invariance, ease of calibration, and direct composability with zkSNARK-based verifiable deployment position it as a practical blueprint for robust, efficient, and auditable RAG serving in production environments.
Future research directions include latent editing for proactive hallucination correction, advanced feature engineering (e.g., head-specific or layer-specific pooling), and formal analysis of scaling laws in very large models.