Bounding Hallucinations: Information-Theoretic Guarantees for RAG Systems via Merlin-Arthur Protocols
Abstract: Retrieval-augmented generation (RAG) models rely on retrieved evidence to guide LLM generators, yet current systems treat retrieval as a weak heuristic rather than verifiable evidence. As a result, LLMs answer without support, hallucinate under incomplete or misleading context, and rely on spurious evidence. We introduce a training framework that treats the entire RAG pipeline -- both the retriever and the generator -- as an interactive proof system via an adaptation of the Merlin-Arthur (M/A) protocol. Arthur (the generator LLM) trains on questions of unkown provenance: Merlin provides helpful evidence, while Morgana injects adversarial, misleading context. Both use a linear-time XAI method to identify and modify the evidence most influential to Arthur. Consequently, Arthur learns to (i) answer when the context support the answer, (ii) reject when evidence is insufficient, and (iii) rely on the specific context spans that truly ground the answer. We further introduce a rigorous evaluation framework to disentangle explanation fidelity from baseline predictive errors. This allows us to introduce and measure the Explained Information Fraction (EIF), which normalizes M/A certified mutual-information guarantees relative to model capacity and imperfect benchmarks. Across three RAG datasets and two model families of varying sizes, M/A-trained LLMs show improved groundedness, completeness, soundness, and reject behavior, as well as reduced hallucinations -- without needing manually annotated unanswerable questions. The retriever likewise improves recall and MRR through automatically generated M/A hard positives and negatives. Our results demonstrate that autonomous interactive-proof-style supervision provides a principled and practical path toward reliable RAG systems that treat retrieved documents not as suggestions, but as verifiable evidence.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making “retrieval-augmented generation” (RAG) systems more trustworthy. In RAG, a LLM answers questions by looking at outside documents. The problem is that today’s systems often treat those documents like rough hints rather than solid proof. That can lead to mistakes, like giving answers that aren’t supported by the text (“hallucinations”) or getting tricked by misleading information. The authors propose a new way to train and test RAG systems so they act more like careful fact-checkers who only answer when the evidence truly supports the answer.
What questions did the paper ask?
The paper asks easy-to-understand versions of three questions:
- How can we train an LLM to answer only when the provided context supports the answer, and to say “reject” (i.e., “I can’t answer with this evidence”) when the context is missing or misleading?
- How can we reduce hallucinations by teaching the model to rely on the exact parts of the context that matter?
- How can we measure, in a principled way, whether the model’s explanations are faithful to the evidence and not just lucky guesses?
How did the researchers approach the problem?
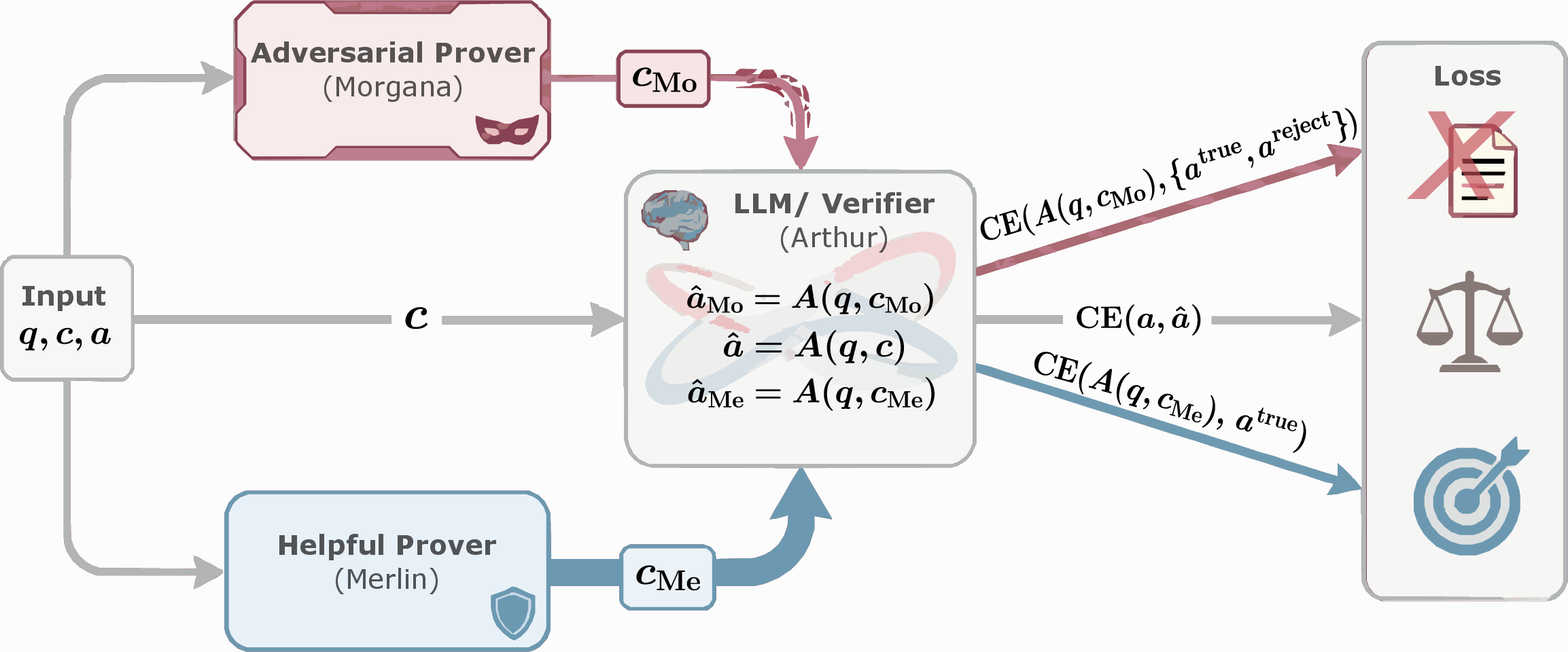
Key idea: turning RAG into a “proof game” (Merlin–Arthur)
Imagine a game with three characters:
- Arthur is the LLM that has to give the final answer (or say “reject”).
- Merlin is a helpful wizard who provides good, supportive evidence from the context.
- Morgana is a trickster who provides misleading or distracting evidence.
Arthur doesn’t know who created the context each time. He must learn to:
- Use good evidence to answer correctly (completeness).
- Avoid being fooled by bad evidence, either by refusing to answer or still answering correctly (soundness).
- Focus on the specific spans of text that truly justify the answer (groundedness).
This setup comes from the Merlin–Arthur (M/A) protocol, an idea from computer science that treats problem-solving like interactive proofs: a prover shows evidence, and a verifier checks it carefully.
How the “wizards” change the context
Merlin and Morgana don’t write new content; they “mask” parts of the existing context to see how Arthur’s answers change. Think of masking like temporarily hiding certain sentences or tokens so the model can’t use them.
To decide what to mask, they use a fast explainability tool called AtMan. AtMan acts like a smart highlighter: it tests which words or sentences matter most for the model’s prediction by briefly turning down their “attention” inside the model. This lets Merlin find the most helpful parts (and keep them visible), while Morgana finds the most harmful or misleading parts (and hides them). Importantly, AtMan doesn’t change the text itself; it just prevents certain tokens from influencing the model—like telling the model, “pretend these words aren’t there.”
Measuring trustworthiness
The paper uses three main checks:
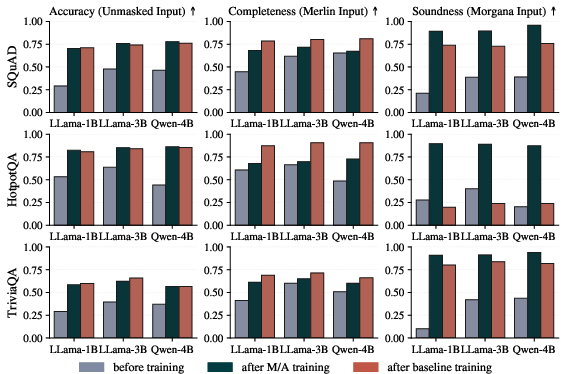
- Completeness: When Merlin provides good context, does Arthur answer correctly?
- Soundness: When Morgana tries to trick Arthur, does Arthur avoid wrong answers (by either answering correctly or choosing “reject”)?
- Groundedness: Is the correct answer actually supported by the specific spans in the context?
They also use an information theory idea—mutual information—to quantify how much the answer truly depends on the context. They introduce Explained Information Fraction (EIF), which is like asking: “Of all the useful information the model has, how much of it is guaranteed to come from the parts of the context we identified?” This helps compare explanation quality across tasks and models, even when benchmarks are imperfect.
To make evaluation fair, they condition some measures on cases where the model would be correct on the full input. That isolates explanation quality from the model’s general accuracy—so you aren’t blaming the explanation for errors that are really just overall model mistakes.
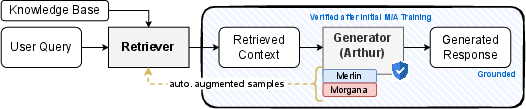
Training both the answerer and the searcher
RAG has two parts:
- The generator (Arthur): the LLM that produces answers.
- The retriever: the system that fetches relevant documents for Arthur.
They train Arthur on three versions of the context for each question:
- the original context,
- the Merlin-masked “helpful” context,
- the Morgana-masked “adversarial” context.
Arthur is rewarded for answering correctly with helpful context, and for either answering correctly or saying “reject” when the context is misleading. This teaches disciplined behavior without needing special labels for “unanswerable” questions.
They also train the retriever using hard examples created by Merlin and Morgana, plus “confounders” (documents that look similar but don’t contain the answer). This makes the retriever better at ranking truly useful documents higher than misleading ones.
What did they find?
Here are the main results across three question-answering datasets (SQuAD2.0, HotpotQA, TriviaQA) and multiple LLMs (Llama 1B, Llama 3B, Qwen 4B):
- Fewer hallucinations and better “reject” behavior: Compared to the original models, incorrect answers under misleading input dropped by 40–70 percentage points. Compared to standard finetuning, they dropped by 10–25 points. Models learned to abstain when the context was insufficient—without needing datasets that label “this question is unanswerable.”
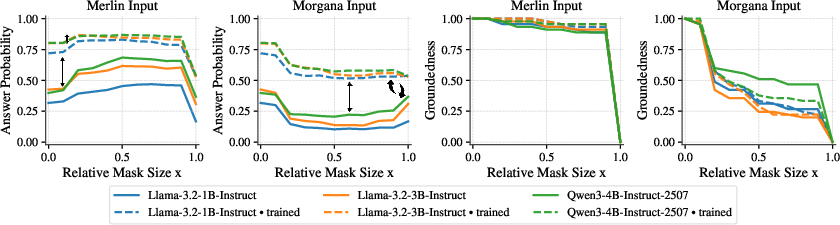
- More grounded answers: After training, the parts of the context the model relied on became more focused and aligned with human expectations. Attribution maps highlighted coherent, relevant spans instead of random or spurious tokens.
- Stronger guarantees: Their measurements showed solid mutual-information lower bounds, with conditional EIF around 0.3 in some settings. In plain terms: a substantial fraction of the model’s useful predictive information is verified to come from the right parts of the context.
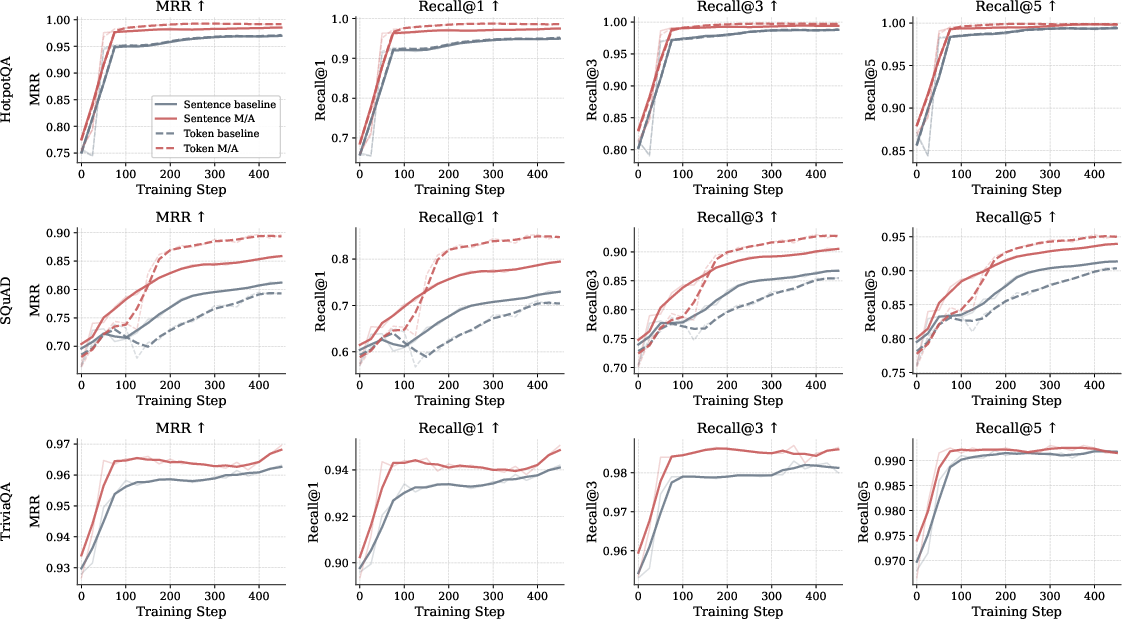
- Better retrieval: The retriever more often put the correct document at the top (improvements of about 3–8 percentage points in Recall@1) and improved its ranking quality (MRR). Using Merlin/Morgana-created “hard positives/negatives” made the retriever more robust.
Why does this matter?
RAG systems are increasingly used in areas where getting facts right really matters—like medicine, law, science, and public policy. This work shows a principled and practical way to:
- Treat retrieved documents as verifiable evidence, not just hints.
- Train LLMs to answer only when justified by the context, and to say “reject” when the evidence isn’t good enough.
- Quantify and certify how much the answer truly depends on the right parts of the context.
- Improve both the generator and the retriever at the same time with automatically created training signals, avoiding costly manual labels.
In short, turning RAG into an “interactive proof” game—with a helpful wizard and a trickster—makes the system more careful, more robust, and more explainable. This is a step toward reliable AI that doesn’t just sound confident, but can show its work.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and unresolved questions that future work could address.
- Formalization gap: The Merlin–Arthur (M/A) bounds are derived for binary classification, yet the paper applies them to open-ended sequence generation with abstention. Provide a complete, rigorous extension of completeness/soundness and mutual-information bounds to multi-class, structured outputs, and sequence-level correctness (beyond exact match).
- EIF validity beyond binary tasks: The Explained Information Fraction (EIF) uses the approximation , which assumes balanced binary tasks with symmetric errors. Derive EIF analogues for imbalanced, multi-class, and sequence-level settings typical in QA, and quantify approximation error on real data.
- Conditioning bias and coverage: Conditional evaluation restricts guarantees to (examples Arthur already gets right), potentially biasing EIF upward and ignoring difficult regions. Characterize coverage thresholds where conditional guarantees meaningfully reflect global behavior, and develop unconditional or semi-conditional bounds.
- Explainer fidelity: Attention-level masking (AtMan) is treated as a proxy for feature removal, but may not fully block information flow (e.g., via residual connections or unmasked heads). Validate explainer faithfulness with stronger interventions (e.g., token deletion, representation ablation, causal scrubbing) and quantify the gap between attention masking and true removal.
- Greedy top-k masking interactions: The mask selection scores each unit independently and then masks the top-k units simultaneously. Analyze and mitigate interaction effects among masked spans (e.g., synergy or redundancy), and compare greedy selection to combinatorial, submodular, or reinforcement-learned masking policies.
- Masking ratio sensitivity: The approach fixes a masking ratio (e.g., x=0.6). Conduct systematic ablations on masking fraction, adaptive schedules, and instance-specific ratios to understand trade-offs between robustness, accuracy, and reject behavior.
- Robustness to realistic adversaries: Morgana only removes influence (masking) rather than injecting plausible but false evidence, paraphrases, distractors, or prompt-injection content. Evaluate and train against content-adding adversaries (conflicting evidence, style perturbations, entity swaps, prompt injection) and measure soundness under these attacks.
- Multi-hop grounding guarantees: HotpotQA requires integrating evidence across documents. Provide explicit multi-hop guarantees (e.g., that multiple supporting spans are jointly necessary/sufficient), and devise metrics that verify compositional grounding rather than single-span reliance.
- Groundedness measurement noise: TriviaQA groundedness is approximated via string matching, which misses paraphrases and partial semantic matches. Replace with semantic span matching or human annotation to avoid under/over-estimating grounding improvements.
- Reject calibration and coverage–accuracy trade-off: The paper reports lower hallucinations via more Reject outputs but does not quantify false rejects or calibration. Measure AUROC/AUPRC for Reject vs Answer decisions, set operating points via cost-sensitive optimization, and analyze utility trade-offs for users.
- Training–inference mismatch: Losses rely on teacher forcing and next-token probabilities for
a_true/a_reject, while inference generates freely. Quantify the mismatch, test sequence-level training objectives (e.g., sequence-level CE, minimum risk training), and evaluate impact on free-form generations. - Runtime verification: Guarantees are established at training/evaluation time, but there is no mechanism for inference-time certificate of grounding (e.g., proof traces or verifiable spans). Explore lightweight runtime verifiers that confirm evidence use without prohibitive cost.
- Scale and generalization: Experiments use 1–4B LLMs and a small BERT-style retriever. Assess scalability to larger LLMs (e.g., 7–70B), mixed-modality inputs, longer contexts, and higher-throughput deployments, including compute/memory cost and training stability.
- Domain and language coverage: Benchmarks are English QA datasets. Test across domains (biomedical, legal, finance), low-resource languages, and noisy web corpora, and quantify robustness under domain and linguistic shift.
- Retriever baselines and components: The retriever is weakened intentionally and trained with InfoNCE on CLS embeddings. Compare against stronger bi-encoder/cross-encoder retrievers (DPR, ColBERTv2, E5, GTR), passage-level pooling variants, and hybrid sparse–dense retrieval, and isolate gains attributable to M/A-augmented positives/negatives.
- Evaluation independence: Validation sets include masked negatives created using the same masking scheme as training, risking evaluation bias. Construct evaluation corpora with independently sourced adversaries and confounders to avoid training–test leakage.
- End-to-end guarantees: The paper improves both generator and retriever separately, but does not derive or empirically validate end-to-end bounds linking retrieval quality, grounding, and reject behavior to overall RAG reliability. Develop compositional guarantees and measure system-level failure rates under retrieval errors.
- Conflicting evidence stress tests: Real-world corpora often contain contradictions across documents. Create benchmarks with controlled conflicting evidence and test whether Arthur truly rejects or reconciles conflicts, and whether Morgana can induce failures by selective masking/adding of conflicting spans.
- Morgana/merlin failure modes: If masking fails to isolate truly influential spans (e.g., due to noisy saliency), provers may produce misleading training signals. Diagnose failure cases, improve prover robustness (ensembles, multi-granularity masks), and quantify how prover quality affects completeness/soundness.
- Alternative XAI backends: The approach centers on AtMan. Benchmark other counterfactual explainers (e.g., leave-one-out, feature ablation, causal mediation, attention flow) for efficiency, fidelity, and training impact, and analyze whether guarantees hold across explainer choices.
- Statistical confidence: Report confidence intervals and significance tests for completeness/soundness/EIF, including sensitivity to dataset sampling, seeds, and masking randomness, to ensure guarantees are not artifacts of variance.
- Partial-credit answers: Exact match treats answers as strictly correct/incorrect. Incorporate semantic equivalence scoring for normalization, and revisit soundness/completeness definitions under graded correctness to avoid penalizing near-miss answers or synonyms.
- Hyperparameter transparency and ablation: Many knobs (masking ratio, unit granularity, loss weights, temperatures) lack comprehensive ablations. Provide full sensitivity analyses to identify robust default configurations and failure regions.
- Interaction with instruction tuning/alignment: The prompt enforces Reject behavior. Assess how prompt wording, system prompts, and alignment/RLHF policies interact with M/A training, and whether models depend on prompts to maintain soundness.
- Safety and security: Evaluate the protocol against prompt injection, jailbreaks, data poisoning, and retrieval poisoning, and investigate whether adversarial provers can be extended to defend against these real-world threats.
- Proof-carrying RAG: The current system has no mechanism for Arthur to output cited spans or structured proofs that can be automatically checked. Explore proof-carrying answers (citations, span IDs, entailment checks) to move from heuristic grounding to auditable evidence use.
- Computational efficiency: Generating per-unit masks and re-evaluations is linear in tokens but still expensive for long contexts. Explore sampling, low-rank influence approximations, or multi-stage pruning to reduce training cost while preserving effectiveness.
- Long-context and multi-document composition: The approach treats concatenated contexts but does not analyze token competition or positional bias in very long inputs. Study how masking interacts with position effects and attention dilution across documents.
- Data requirements: Some retriever augmentations rely on gold answer spans (unavailable in many domains). Develop span-agnostic proxies (e.g., weak supervision via NLI/entailment or distant supervision) to generalize the method where span labels are missing.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the paper’s methods, metrics, and training workflows.
- Evidence‑bound enterprise knowledge assistants with explicit reject behavior
- Sectors: software, finance, legal, healthcare, public sector
- What to deploy: a RAG assistant trained with the Merlin–Morgana protocol and AtMan masking to:
- answer only when context justifies it (“Reject” otherwise),
- highlight the exact sentences/tokens that support the answer,
- reduce hallucinations relative to standard finetuning.
- Workflow: integrate a “Merlin/Morgana” data augmentation stage into existing RAG training (LoRA on the generator; InfoNCE on the retriever), add a reject token to the output vocabulary, and instrument dashboards for completeness, soundness, and groundedness per query.
- Assumptions/dependencies: access to model internals for attention masking (AtMan) and finetuning; sufficient compute for mask generation and training; well‑formed retrieval corpora; clear UX around rejection pathways (e.g., escalation to a human).
- Hard‑negative/positive augmentation for retrievers using automated Merlin/Morgana contexts
- Sectors: enterprise search, customer support, edtech, documentation platforms
- What to deploy: train dense retrievers with “Morgana” adversarial documents and “Merlin” supportive masked documents as task‑specific hard negatives/positives, plus synthetic confounders (removed/replaced/scrambled answer sentences).
- Workflow: append M/A‑generated variants to retriever training and evaluation pools; optimize with InfoNCE and measure Recall@k/MRR; ship improved search ranking to production.
- Assumptions/dependencies: ability to create confounders (needs answer spans for some datasets); document segmentation into sentences; consistent domain ontologies.
- Reliability auditing and governance using conditional completeness/soundness and EIF
- Sectors: compliance/risk in finance and healthcare, public sector procurement, MLOps
- What to deploy: a governance dashboard that reports conditional completeness/soundness and Explained Information Fraction (EIF_cond) to certify how much of the model’s predictive signal is grounded in retrieved evidence.
- Workflow: run the Conditional Evaluation Protocol on held‑out data; set thresholds (e.g., minimum EIF_cond) for production gating; log per‑query metrics into model cards.
- Assumptions/dependencies: sufficiently accurate ground truth; balanced or well‑characterized label distributions for EIF estimates; metric instrumentation at inference.
- Evidence highlighting and citation UX for RAG answers
- Sectors: education, journalism, research, legal, developer tooling
- What to deploy: token/sentence‑level highlights showing which spans supported the answer; clickable citations to documents used; visual overlays for groundedness.
- Workflow: use AtMan to compute influence maps for the final answer; store highlighted spans with the response; expose them in the UI for transparency.
- Assumptions/dependencies: fine‑grained token/sentence segmentation; attention masking hooks; consistent document identifiers to enable citations.
- Safer customer‑facing chatbots with disciplined abstention
- Sectors: customer support, banking, insurance, healthcare triage
- What to deploy: chatbots that refuse when retrieved context is insufficient, with structured handoff to human agents and automatic retry with improved retrieval.
- Workflow: prompt with explicit reject policy; train with M/A losses (including treating “Reject” as a valid target under adversarial context); set response gates using soundness.
- Assumptions/dependencies: well‑designed escalation workflows; careful thresholding to balance helpfulness vs. abstention; evaluation of user impact.
- Stress‑testing suites for RAG pipelines via Morgana adversarial contexts
- Sectors: MLOps, security, QA
- What to deploy: a test harness that automatically generates misleading contexts (Morgana) and measures how often the model hallucinates; track soundness over releases.
- Workflow: batch generation of adversarial masks; regression tests with completeness/soundness/groundedness; report drift and failure modes by topic.
- Assumptions/dependencies: compute budget for mask probing; baseline inference harness; per‑domain coverage analysis.
- Documentation search and API assistance with evidence‑centric answers
- Sectors: developer tooling, software documentation platforms
- What to deploy: assistants that highlight the precise API docs supporting an answer and refuse when the docs don’t justify recommendations.
- Workflow: finetune retrievers with confounders from near‑duplicate API pages; instrument Merlin/Morgana supervision on the generator; enable reject gating.
- Assumptions/dependencies: structured technical documentation; accurate sentence boundary detection; alignment with developer workflows.
- Medical literature Q&A assistants as triage tools (not diagnostic)
- Sectors: healthcare (clinical knowledge access, payer policy lookup)
- What to deploy: systems that answer with guideline‑linked evidence and abstain when context is missing, serving clinicians as search amplifiers.
- Workflow: restricted corpora (guidelines, systematic reviews); Merlin/Morgana training; citation surfacing; reject→human/secondary search escalation.
- Assumptions/dependencies: not clinically validated; regulatory constraints; strong disclaimers and human oversight; robust de‑identification if patient data enters the context.
- Academic benchmarking and method development using EIF and conditional evaluation
- Sectors: academia and research labs
- What to deploy: replicable evaluation harnesses that separate explanation fidelity from predictive errors (conditional metrics) and report EIF; datasets with synthetic confounders for robust retriever testing.
- Workflow: public benchmarks augmented with M/A maskers; analysis notebooks; comparative studies of XAI methods under M/A bounds.
- Assumptions/dependencies: open access to model internals for AtMan; standardized evaluation splits; community adoption of metrics.
Long‑Term Applications
Below are applications that are promising but require further research, scaling, or validation before broad deployment.
- Certified “Evidence‑Bound AI” for regulated sectors
- Sectors: healthcare, finance, public sector
- What could emerge: third‑party certification schemes that require minimum EIF_cond, completeness/soundness thresholds, and standardized audit trails for RAG systems.
- Dependencies: standards bodies and regulatory buy‑in; scalable and domain‑specific test suites; independent auditing infrastructure.
- Inference‑time interactive proof‑of‑evidence gating
- Sectors: real‑time assistants, safety‑critical ops
- What could emerge: controllers that run fast Merlin/Morgana probes at inference to decide whether to answer, seek more evidence, or reject; attach “proof” artifacts to each response.
- Dependencies: low‑latency mask generation; efficient approximations to AtMan; careful engineering to keep user‑perceived latency acceptable.
- End‑to‑end training with learned provers
- Sectors: advanced AI platforms, research
- What could emerge: neural Merlin/Morgana agents trained jointly with Arthur (generator) and the retriever, using reinforcement learning and counterfactual objectives to optimize evidence selection and adversarial robustness.
- Dependencies: training stability; significant compute; safety guardrails for adversarial agents; reliable attribution under distribution shift.
- Multi‑modal, multi‑hop RAG with mutual information guarantees
- Sectors: robotics (procedural grounding), manufacturing (maintenance manuals+sensor data), insurance claims (text+images), medical imaging+text
- What could emerge: AtMan‑style maskers for vision/audio/code to enable Merlin/Morgana proofs across modalities; verified multi‑hop reasoning chains with aggregated evidence.
- Dependencies: new XAI tooling for non‑text modalities; high‑quality multi‑modal datasets with supporting evidence annotations; extended theory beyond binary approximations.
- Security‑hardened agents resistant to prompt‑injection and contextual deception
- Sectors: cybersecurity, trust & safety
- What could emerge: systems trained under Morgana‑style adversarial contexts that simulate injection/distractor attacks, raising soundness and rejection under compromised inputs.
- Dependencies: realistic adversarial corpora; continuous red‑teaming pipelines; generalization from synthetic to real threats.
- Legal contract intelligence with clause‑level proofs
- Sectors: legal tech, compliance
- What could emerge: assistants that propose clause interpretations and modifications only with clause‑level evidence; attach “proof packs” that meet internal policy thresholds (EIF_cond, soundness).
- Dependencies: contract corpora with clause segmentation; domain adaptation; legal validation studies; governance processes.
- Standardization and adoption of EIF as a cross‑industry reliability metric
- Sectors: policy, procurement, MLOps
- What could emerge: EIF integrated into procurement requirements, model cards, SLAs; cross‑vendor comparability for RAG reliability claims.
- Dependencies: community consensus on definitions; calibration across tasks/model sizes; public tooling for EIF calculation.
- Personal knowledge managers with verified local citations (privacy‑preserving)
- Sectors: consumer productivity, daily life
- What could emerge: on‑device assistants that only answer when local notes/files contain sufficient evidence; highlight supporting fragments; reject otherwise.
- Dependencies: efficient, low‑compute maskers; device‑level finetuning frameworks; user consent and privacy controls.
- Energy and industrial operations copilots with evidence‑gated recommendations
- Sectors: energy, manufacturing, transportation
- What could emerge: copilots that surface procedure steps and safety policies from manuals, only recommend actions with grounded evidence, and abstain in ambiguous contexts.
- Dependencies: rigorous validation and incident analyses; integration with existing control room workflows; domain safety approvals.
Cross‑cutting assumptions and dependencies that impact feasibility
- Model access: AtMan and masking require hooks into attention and teacher‑forcing; closed API models may limit deployment unless vendors expose compatible interfaces.
- Compute: generating Merlin/Morgana masks and multi‑context training is more expensive than standard finetuning; inference‑time gating adds latency unless approximated efficiently.
- Data quality: gains depend on retrieval corpus relevance and, for confounders, availability of answer span/sentence annotations (or robust proxies).
- Metric validity: EIF approximations assume balanced/symmetric error settings; care is needed to adapt metrics to open‑ended generative tasks and imbalanced domains.
- UX and policy: rejection must be designed into the user experience (escalation paths) and aligned with organizational policies for handling abstentions in production.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from gradient updates. "using AdamW \citep{loshchilov2018decoupled} with a learning rate of ."
- artificial confounders: Synthetic hard-negative documents created by altering answer-containing sentences to test retriever robustness. "We introduce the artificial confounders (hard negatives) to increase the difficulty of the retrieval task and evaluate the retrievers robustness to fine-grained contextual differences."
- Arthur: The verifier/generator LLM in the Merlin-Arthur protocol. "Arthur (A) is an autoregressive LLM that generates answers token after token."
- AtMan: A linear-cost perturbation-based explainability method that suppresses attention to estimate token influence. "We instead build on AtMan \citep{deiseroth2023atman}, a linear-cost perturbation-based explainer that measures how suppressing the attention of individual tokens changes the model's probabilities."
- attention-level masking: Masking implemented by zeroing attention to selected tokens instead of inserting special mask tokens. "we follow \cite{deiseroth2023atman} and apply attention-level masking."
- autoregressive LLM: A LLM that generates sequences token by token conditioned on prior tokens. "Arthur (A) is an autoregressive LLM that generates answers token after token."
- bfloat16: A 16-bit floating-point format used to speed up training with adequate numeric range. "We fine-tune all LLMs for a minimum of 200 steps with LoRA \citep{hu2022lora} (rank 8, , dropout ) in bfloat16, using AdamW \citep{loshchilov2018decoupled} with a learning rate of ."
- binary entropy function: The entropy function for Bernoulli variables, used in information-theoretic bounds. "via the binary entropy function and entropy :"
- causal attention mask: A transformer constraint preventing attention to future tokens; here extended to suppress selected tokens. "by extending the causal attention mask with an additional suppression at the respective columns for token positions of , , as:"
- CLS token: The special classification token used to represent entire sequences in BERT-like models. "We obtain document embeddings by using the final hidden state of the special token as the representation of the entire text."
- Completeness Error: The probability that Arthur fails to predict correctly when given Merlin's features. "Completeness Error (): The probability that Arthur fails to classify correctly given Merlin's features."
- Conditional Evaluation Protocol: An evaluation scheme that conditions on correct predictions to isolate explanation fidelity. "a Conditional Evaluation Protocol that isolates explanation fidelity from the modelâs predictive performance,"
- cosine similarity: A metric for similarity between embeddings based on the cosine of the angle between vectors. "where is a temperature parameter, and is the cosine similarity between the query and document embeddings."
- Exact Match: An accuracy metric for QA measuring exact string equality with the gold answer. "We compute accuracy using exact match."
- Explained Information Fraction (EIF): A normalized measure of certified mutual information relative to baseline capability. "This allows us to introduce and measure the Explained Information Fraction (EIF), which normalizes M/A certified mutual-information guarantees relative to model capacity and imperfect benchmarks."
- InfoNCE: A contrastive loss function used to train embedding-based retrievers. "We train the retriever using a standard contrastive loss $\mathcal{L}_{\text{InfoNCE}$."
- Interactive Proof Systems: A computational framework where a verifier interacts with a prover to check claims; inspires the M/A protocol. "inspired by the Merlin-Arthur protocol from Interactive Proof Systems~\citep{arora2009computational}."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method for large models. "We fine-tune all LLMs for a minimum of 200 steps with LoRA \citep{hu2022lora} (rank 8, , dropout ) in bfloat16, using AdamW \citep{loshchilov2018decoupled} with a learning rate of ."
- Mean Reciprocal Rank (MRR): A ranking metric averaging the inverse rank of the first relevant item. "For the retriever we report Recall@ and Mean Reciprocal Rank (MRR)."
- Merlin: The helpful prover supplying evidence to support correct answers. "Merlin provides helpful evidence, while Morgana injects adversarial, misleading context."
- Merlin-Arthur (M/A) protocol: An interpretability/training framework modeling RAG as an interactive proof with helpful and adversarial provers. "via an adaptation of the Merlin-Arthur (M/A) protocol."
- Model Coverage: The probability mass of inputs where Arthur is correct, used to condition evaluation. "The mass of the reliable region is captures by the Model Coverage,"
- Morgana: The adversarial prover that injects misleading context to induce errors. "Merlin provides helpful evidence, while Morgana injects adversarial, misleading context."
- Mutual Information: A measure of shared information between variables; used to certify feature–label dependence. "This precision bound directly constrains the Mutual Information (I) between the features and the class label via the binary entropy function and entropy :"
- parametric knowledge: Information internal to the pretrained model rather than derived from retrieved context. "Arthur falls back to its parametric knowledge once all context is removed."
- Recall@: A retriever metric indicating whether a relevant document appears in the top-k results. "For the retriever we report Recall@ and Mean Reciprocal Rank (MRR)."
- reject behavior: The model's ability to abstain when evidence is insufficient or misleading. "This reject behavior emerges without requiring annotated unanswerable questions."
- Soundness Error: The probability that adversarial features cause Arthur to misclassify. "Soundness Error (): The probability that Morgana successfully fools Arthur into a misclassification."
- teacher forcing: An evaluation/training mode where ground-truth tokens are fed to condition next-token predictions. "we evaluate Arthur under teacher forcing: after it generates the first token, we feed the ground-truth answer prefix into the model and read the next-token distribution for all answer options, measuring probabilities for $a^{\text{true}$ and $a^{\text{reject}$."
- token-level masking: Masking that treats each token as an independent unit to be suppressed. "Token-level masking: Each token constitutes its own candidate mask unit."
- top- selection: Selecting the k most influential units based on their effect on answer probabilities. "We instantiate Merlin and Morgana as agents that identify the most influential units to mask via top- selection."
- XAI: Explainable AI methods for interpreting model behavior; here used to guide training. "Both use a linear-time XAI method to identify and modify the evidence most influential to Arthur."
Collections
Sign up for free to add this paper to one or more collections.

