- The paper introduces a framework that recasts retrieval as an MMKP and generation as an NLI-guided MCTS search to improve answer faithfulness.
- Empirical results show superior Recall@5 and enhanced exact match and citation accuracy over traditional RAG methods in complex query settings.
- The approach offers a scalable method to reduce redundancy and prevent hallucinations, ensuring evidence-grounded and reliable responses.
Self-Correcting RAG: Enhancing Faithfulness in Retrieval-Augmented Generation via MMKP and NLI-Guided MCTS
Introduction
Retrieval-Augmented Generation (RAG) augments LLMs by conditioning them on externally retrieved documents, extending their effective knowledge and constraining model hallucination. However, RAG workflows exhibit two critical deficiencies: (1) inefficient use of context windows due to redundancy or poor coverage in retrieval, and (2) hallucinations in generated answers, especially on complex multi-hop or noisy queries. The paper "Self-Correcting RAG: Enhancing Faithfulness via MMKP Context Selection and NLI-Guided MCTS" (2604.10734) introduces a unified framework that rigorously addresses both failures by recasting retrieval as a combinatorial optimization problem and generation as an inference-time search with logical grounding.
Self-Correcting RAG: Framework and Workflow
The proposed system bifurcates the RAG pipeline into two synergistic modules:
- MMKP Context Selector: Rather than selecting top-k documents by relevance, the system formalizes context construction as a Multi-dimensional Multiple-choice Knapsack Problem (MMKP), clustering candidate documents to enforce diversity and maximize information density under strict token and redundancy constraints.
- NLI-Guided MCTS Generator: For answer generation, a Monte Carlo Tree Search (MCTS) planner is deployed at inference time. An auxiliary Natural Language Inference (NLI) model evaluates the logical entailment between generated sentences and the selected evidence, penalizing contradictions and dynamically pruning unreliable reasoning paths.
This design is visually juxtaposed with the conventional RAG pipeline, highlighting the shift from greedy top-k ranking to constraint-aware, search-driven optimization.
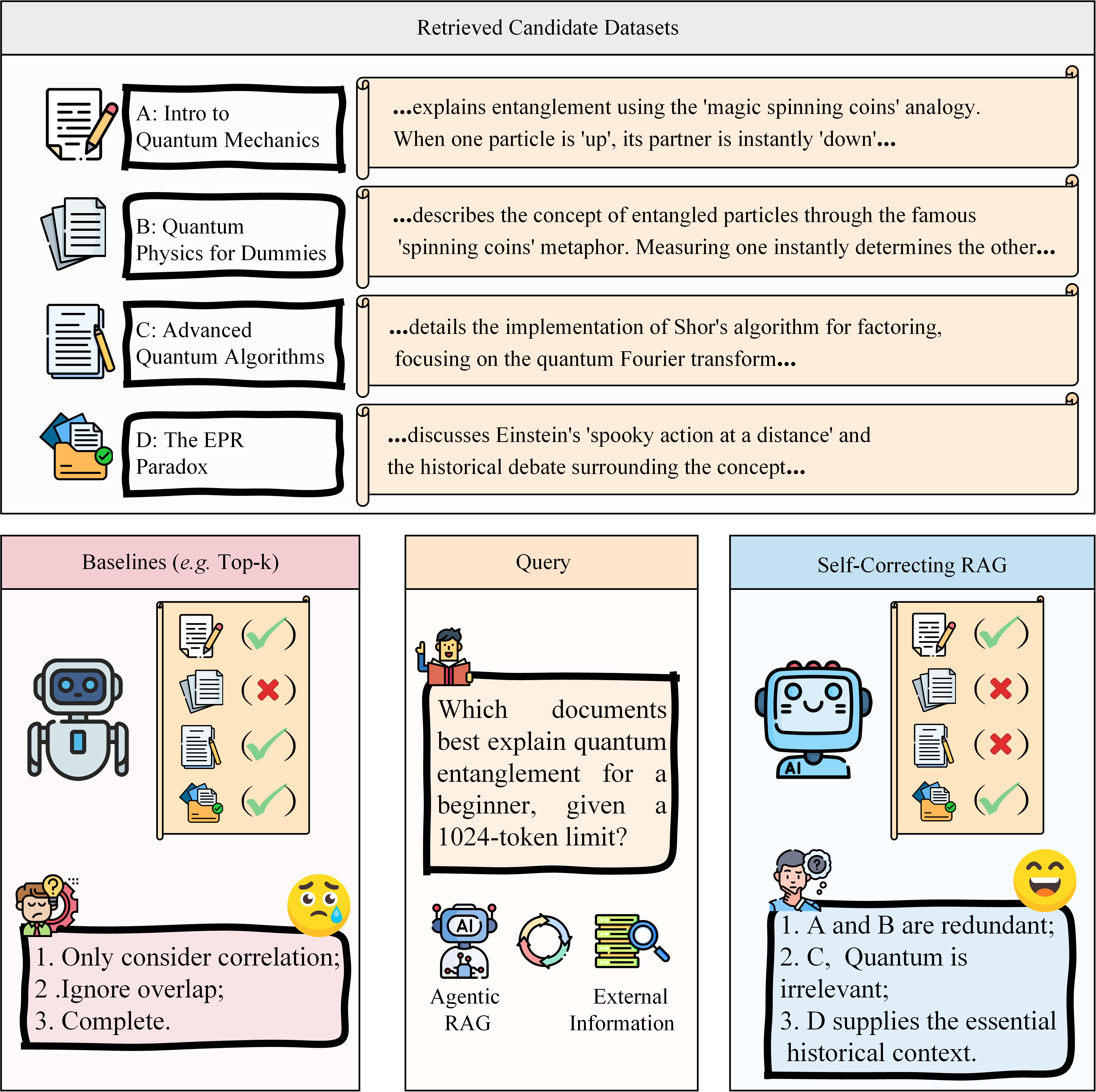
Figure 1: Baseline Top-k RAG performs simple relevance-based selection, while Self-Correcting RAG leverages an MMKP optimizer and NLI-MCTS to enforce faithfulness and information density.
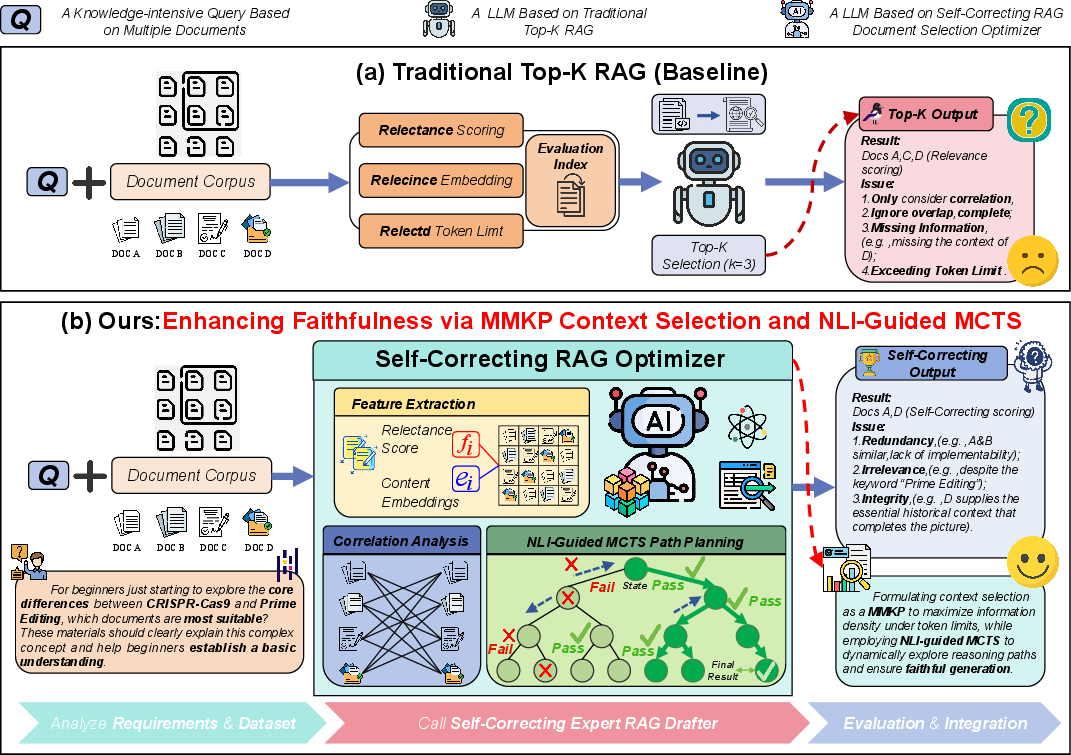
Figure 2: The methodology reformulates document selection as MMKP and leverages NLI-guided MCTS search to ensure backtrackable, evidence-grounded reasoning.
MMKP-Based Context Selection
Theoretical Model
Given a pool of retrieved document chunks U for a query, the MMKP approach first performs semantic clustering to construct mutually exclusive groups, discouraging the selection of redundant documents. Each candidate is associated with a multi-dimensional cost vector (token count, redundancy, etc.) and a fused utility function incorporating relevance and diversity. The knapsack objective maximizes the aggregated utility, constrained by token and redundancy budgets:
maxi=1∑mj∑vijxijs.t.i,j∑wijxij⪯C
This approach optimizes for both diversity and coverage, providing theoretical and empirical advantages over greedy or margin-based re-ranking methods. The combinatorial optimization is solved with a Pareto-pruned dynamic programming algorithm, ensuring tractable runtime with polynomial scaling in practice.
Empirical Effectiveness
Experiments demonstrate substantially increased Recall@5 passage retrieval, indicating improved evidence density and coverage under token constraints, especially when compared to Top-k and MMR strategies.
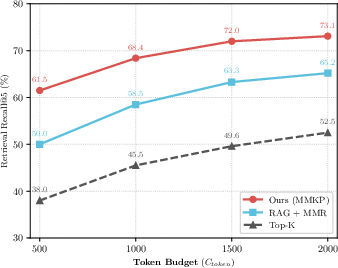
Figure 3: The MMKP selector maintains significantly higher Recall@5 across different token budgets, demonstrating superior robustness under tight context constraints.
NLI-Guided MCTS for Faithful Generation
Inference-Time Logical Search
Linear generation is vulnerable to error propagation and hallucination, given the lack of lookahead and the inability to globally coordinate constraints over multi-hop reasoning. The Self-Correcting framework recasts answer synthesis as an MDP, searched with MCTS. At each node, the generator can expand the answer or request additional retrieval. Each reasoning trajectory is evaluated by aggregating NLI-based entailment and contradiction signals between the answer and selected evidence snippets.
Severe penalties for contradiction (e.g., wcon≪0) aggressively prune branches with hallucinated facts. This supervision is not baked into the weights; rather, it is applied during test-time compute, enabling dynamic correction and backtracking before answer emission.
Empirical Outcomes
In multi-hop and noisy domains, Self-Correcting RAG achieves consistent improvements over both pipeline and agentic baselines in exact match, F1, and citation faithfulness, especially for queries requiring cross-document synthesis or those susceptible to missing/evasive evidence.
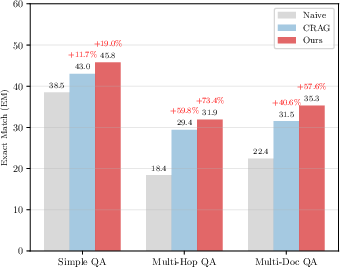
Figure 4: Complexity analysis reveals that Self-Correcting RAG demonstrates scaling advantages as query difficulty increases, outperforming baselines notably on complex tasks.
Qualitative and Analytical Case Studies
Case analyses expose the core failure modes of traditional RAG: context crowding by semantically duplicative documents and heuristic/parametric bias when critical entities are evicted. The MMKP selector constrains redundancy and guarantees the inclusion of essential, complementary factoids. The MCTS planner, guided by NLI, actively prunes hallucinated branches—whereas static decoders cannot recover from such errors.
- In temporal comparison (e.g., magazine founding dates), the baseline model hallucinates when crowded by single-entity evidence, while MMKP enables balanced context and NLI-MCTS backtracks from incorrect hypotheses (see Figure 1 and qualitative section).
- In multi-attribute aggregation under distractor noise (e.g., CEO tenure with DeepMind, Google), the MMKP selector suppresses uninformative clusters, and MCTS forces arithmetic-based comparison, rejecting heuristic fallacies and enforcing factually grounded trajectories.
Ablation and Sensitivity
Ablation studies isolate the gains from MMKP context selection (recall, answer presence) and NLI-MCTS (faithfulness, contradiction reduction). Combined, these mechanisms drive significant end-to-end QA improvements under a fixed context and retrieval architecture. Sensitivity analysis confirms the optimality of setting mid-range redundancy penalties and moderate MCTS simulation budgets, with diminishing returns at extreme values.
Theoretical and Practical Implications
The paper provides formal NP-hardness proofs for RAG-MMKP and delineates efficient approximation strategies (heuristic DP with Pareto pruning, FPTAS for 1-D knapsack). MCTS consistency is shown under bounded logical reward and a sufficiently accurate NLI oracle, thus supporting the search efficacy for finite-horizon QA.
Practically, this work establishes a blueprint for combining retrieval, reasoning, and test-time logical control in a unified system. The explicit search-based self-correction can be adapted for longer contexts, domain-specialized NLI models, and potentially, end-to-end reward fine-tuning in retrieval-augmented LLMs.
Limitations and Future Directions
The principal limitation is increased inference latency due to search-based dynamic generation and on-the-fly NLI verification. The current approach remains unsuitable for strict real-time scenarios, pointing to future research on sample-efficient planning and hardware acceleration. Robustness is also bounded by the capabilities and domain coverage of off-the-shelf NLI models; domain-specific fine-tuning and joint learning approaches may further improve verification sensitivity. Strict redundancy constraints occasionally prune complementary, low-frequency perspectives, suggesting the need for adaptive diversity calibration.
Looking forward, extending this paradigm to long-context processing, multimodal input, and constrained generative planning (e.g., executable code, structured tables) will be promising for reliable, faithful, retrieval-grounded generation in open-domain and safety-critical applications.
Conclusion
Self-Correcting RAG rigorously advances the state of retrieval-augmented language modeling via the combined application of MMKP-based context optimization and NLI-guided MCTS. It delivers strong empirical gains in both retrieval quality and generation faithfulness across challenging multi-hop and noisy information environments. The framework's theoretical grounding, practical scalability, and modular composition set a new standard for robust reasoning in RAG systems, with clear paths for further research in computational efficiency, domain adaptation, and trustworthiness.