- The paper introduces a novel framework that personalizes AI agents by modeling file-system behavioral traces through controlled simulations.
- It details three core components—FileGramEngine for trace simulation, FileGramBench for diagnostic evaluation, and FileGramOS for multi-channel memory consolidation.
- Experimental results demonstrate that FileGramOS achieves 59.6% accuracy, outperforming baselines while highlighting significant sim-to-real challenges.
FileGram: Grounding Agent Personalization in File-System Behavioral Traces
Introduction and Motivation
Personalized AI coworkers embedded within operating system file systems are vital for next-generation human-AI interaction, yet remain fundamentally limited by the lack of data, benchmarks, and rigorous methodology for memory-centric adaptation. "FileGram: Grounding Agent Personalization in File-System Behavioral Traces" (2604.04901) directly addresses these limitations via a unified framework rooted in atomic file-system behavioral traces, introducing three core components: FileGramEngine for persona-driven behavioral trace generation, FileGramBench for diagnostic benchmark evaluation, and FileGramOS, a bottom-up multi-channel memory architecture.
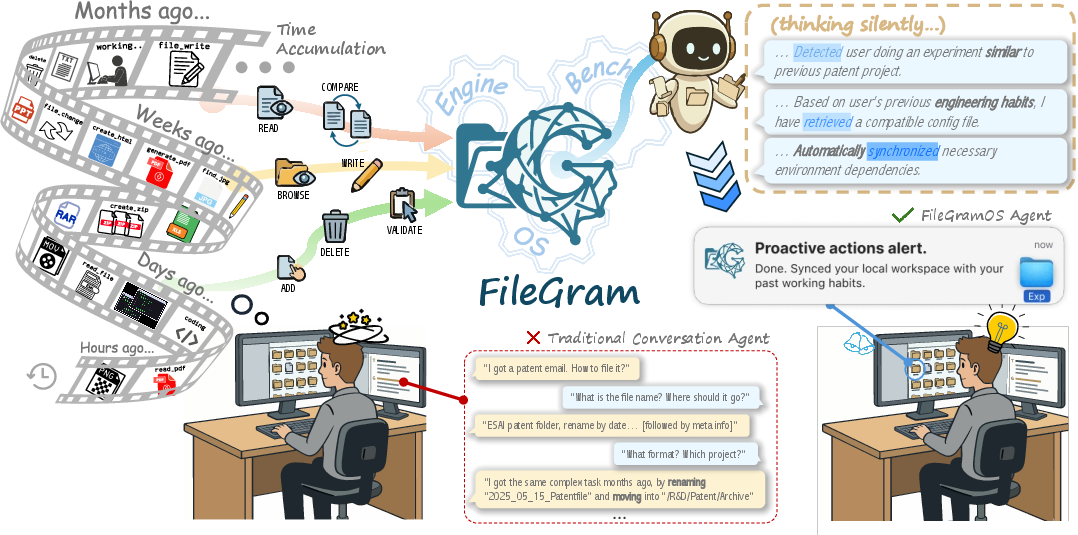
Figure 1: An overview of FileGram, integrating an AI coworker in the file system with persistent, cross-session behavioral memory, intent inference, and workspace synchronization.
The paper hypothesizes that file-system-level signals, particularly sequences of atomic operations and the delta between file versions, provide enduring and discriminative user behavioral signatures. By modeling such signals, agents can infer user intent and continually align with nuanced idiosyncrasies of workflow and organization that are not recoverable from dialogue alone. The work aims to (i) bypass privacy barriers and the paucity of real session data via controlled simulation, (ii) provide the first benchmark for comprehensive evaluation of memory and personalization capabilities at the file system level, and (iii) propose an architecture maximizing behavioral signal retention and structured abstraction.
FileGramEngine: Persona-Conditioned Behavioral Trace Simulation
FileGramEngine generates large-scale, fine-grained multimodal action traces by conditioning agent behavior on 20 personas, each defined over six rigorously controlled behavioral dimensions (consumption, production, organization, iteration, curation, and cross-modal preference), discretized into low/medium/high (L/M/R) tiers. These personas execute 32 tasks spanning text and multimodal settings, yielding 640 trajectories, 20,028 atomic actions, and over 10,000 output files. Key attributes include controlled perturbations to model realistic behavioral drift, with deliberate local tier shifts in select sessions to anchor evaluation of anomaly detection and drift attribution.
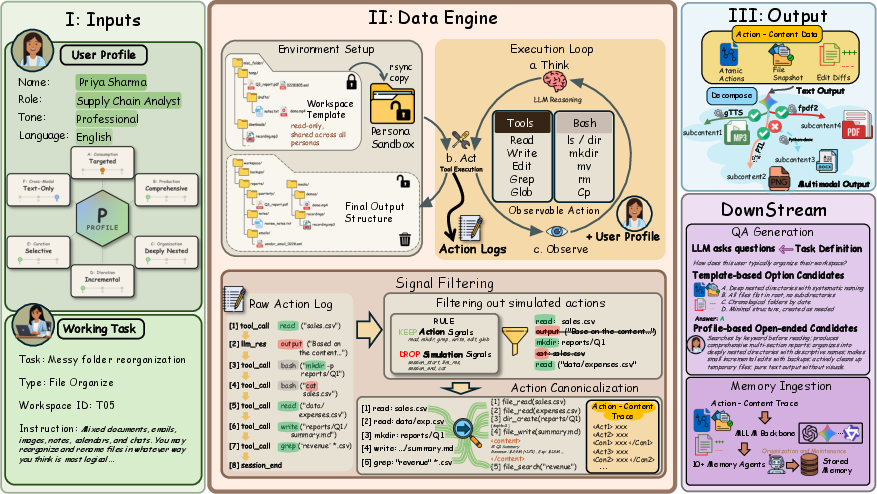
Figure 2: FileGramEngine’s pipeline creates profile-conditioned traces by simulating agent execution in isolated workspaces, canonicalizing tool traces, and aligning multimodal outputs for standardized evaluation.

Figure 3: Data yield—20 personas and 32 tasks generate 640 trajectories, ∼10K multimodal output files, and over 20K actions.
The canonicalization pipeline removes simulation artifacts, isolates genuine action signals, and records both procedural (logs of actions such as file_read, file_write, dir_create, etc.) and delta-based content changes, retaining high-fidelity behavioral context. Multimodal post-processing spans PDF, image, slide, and audio renderings, bolstering the modality coverage for robust evaluation.
FileGramBench: Memory-Centric Diagnostic Benchmark
FileGramBench is the first benchmark to focus on file-system-grounded, memory-centric personalization. It provides 4.6K QA items across four tracks targeting procedural, semantic, and episodic memory capabilities:
- Profile Inference and Reconstruction: Identifying persona by behavioral attribute classification, behavioral fingerprint matching, or open-ended profile summarization.
- Pattern-Level Inference: Disentangling ambiguous interleaved traces and predicting behavior on held-out tasks.
- Anomaly and Drift Detection: Detecting sessions with induced behavioral shifts and attributing the perturbed dimension/direction.
- Multimodal Grounding: Applying previous tracks using only rendered files or real human screen activities.
Tracks include both synthetic (simulated) and real-world settings, with synthetic data offering controlled, attribute-aligned supervision, while screen recording collections externally validate model generalization under realistic, noisy conditions.
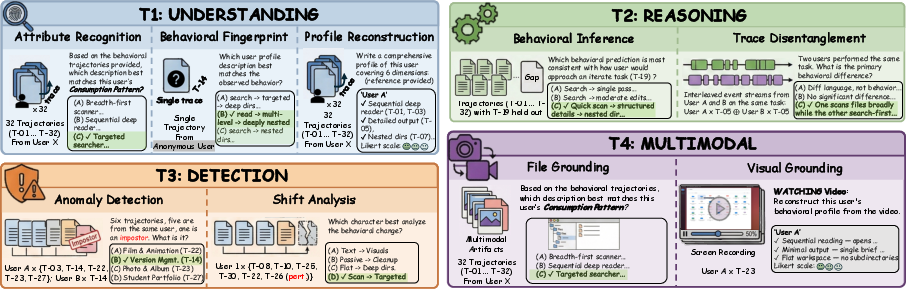
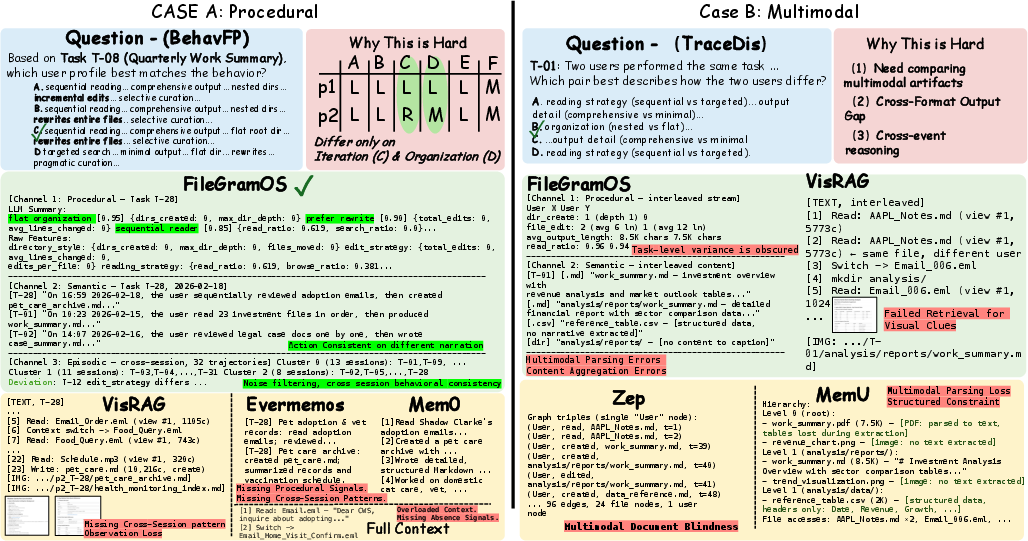
Figure 4: Representative FileGramBench QA examples span multiple task formats, including multiple-choice and open-ended queries, to probe procedural, semantic, and episodic recall and attribution.
All evaluation is model-agnostic, using LLMs (e.g., Gemini 2.5-Flash) for both QA synthesis and open-ended answer judging via Likert scales, ensuring fairness and rigor in comparative assessment.
FileGramOS: Bottom-Up, Multi-Channel Behavior Memory
FileGramOS implements a memory system tailored to file-system trace ingestion, employing a bottom-up design that (i) encodes per-trajectory behavioral features (Engrams), (ii) consolidates these features across sessions along three orthogonal memory channels—procedural, semantic, episodic—and (iii) performs query-adaptive retrieval.
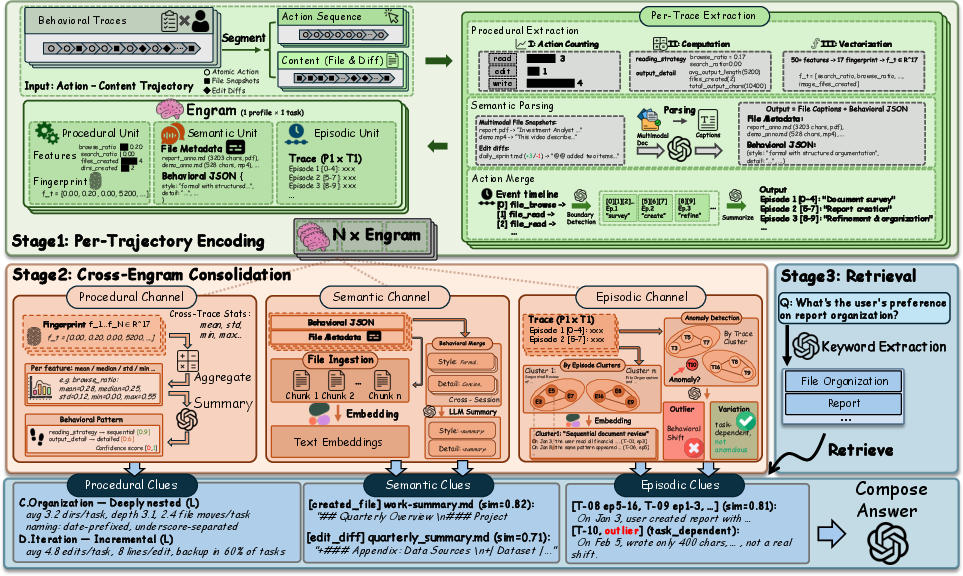
Figure 5: FileGramOS architecture—a three-stage pipeline: per-trajectory encoding to Engram, channelized consolidation (procedural, semantic, episodic), and query-adaptive retrieval for memory-centric question answering.
Stage 1: Per-Trajectory Encoding. Atomic actions and content deltas are vectorized into a 17-dimensional procedural fingerprint, semantic descriptors via multimodal model embedding, and episodic boundaries (logical session segments). Each trajectory contributes a compact Engram containing all three representations.
Stage 2: Cross-Engram Consolidation. Engrams are aggregated across sessions: procedural fingerprints yield robust profile statistics (mean, std, etc.), semantic units group content and stylistic cues, and episodic units allow for clustering and outlier/anomaly detection (behavioral drift) with LLM-based analysis for distinguishing intentional variation from outlier noise.
Stage 3: Query-Adaptive Retrieval. Upon tasking with a query, FileGramOS retrieves and composes relevant procedural, semantic, and episodic clues, supporting fine-grained, evidence-grounded answers rather than relying on monolithic or prematurely abstracted memory.
Experimental Evaluation
Comprehensive experiments on FileGramBench reveal critical findings:
Modality invariance is demonstrated: FileGramOS exhibits minimal degradation moving from text to multimodal files, as it abstracts behavioral cues from denoised trace statistics rather than content-specific features. Conversely, VisRAG and other vision-centric methods capture formatting cues but are blind to operation-level or structural statistics, limiting their procedural and episodic memory fidelity.
Transitioning to real screen recordings exposes a sharp performance drop (to single-digit accuracy for all methods), quantifying the current sim-to-real gap and underscoring the necessity for further research in modeling naturalistic, noisy user behavior and detecting subtle, gradual drift.
Implications and Theoretical Significance
FileGram reframes the agent memory problem from interaction/dialogue to file-system traces, separating transient surface-level cues from persistent operational habits. This has several notable implications:
- Procedural trace signals are essential for robust, interpretable personalization. Early memory abstraction based on dialogue or episodic narratives is lossy for behavioral discrimination.
- Multichannel memory substrates (procedural, semantic, episodic) are complementary and necessary for capturing different axes of behavioral variance, detection, and attribution. Channel ablation confirms the procedural channel is most critical for performance.
- Open sim-to-real gaps exist: All evaluated approaches, including FileGramOS, underperform dramatically on real user recordings, motivating future integration of richer, less structured sensory input to complement current trace-based methods.
- Benchmarking and methodological standardization: By open-sourcing both the data pipeline and the diagnostic benchmark, FileGram provides the community with a reproducible, extensible platform for evaluating memory-centric file-system agents.
On a theoretical level, the systematic separation of evidence abstraction stages, controlled evaluation of shift attribution, and demonstration of the limits of current multimodal memory architectures signal the need for new memory-augmented models with explicit trace-level reasoning and robust multitask adaptation.
Conclusion
FileGram provides a rigorous foundation for file-system behavioral personalization, comprising a persona- and task-controlled trajectory generation engine, a comprehensive memory-centric diagnostic benchmark, and a structured, bottom-up, tri-channel memory OS. The framework highlights the limitations of existing dialogue/narrative-first and multimodal memory architectures, demonstrating the necessity of preserving and abstracting procedural file-system signals for robust, user-aligned agent adaptation. Despite substantial gains, generalization to the real-world, especially in unstructured, screen-level contexts, remains unsolved and marks a frontier for memory-centric AI agent research.