- The paper's main contribution is the PERMA benchmark that shifts evaluation from static fact-recall to dynamic, event-driven memory integration.
- It introduces a robust two-phase pipeline that decomposes user interactions into fine-grained events to simulate authentic persona evolution.
- It compares LLMs and memory systems, revealing insights on token efficiency, noise resilience, and challenges in cross-domain personalization.
PERMA: Event-Driven Benchmarking of Personalized Memory Agents
Motivation and Limitations of Prior Work
The PERMA benchmark addresses critical limitations in the evaluation of LLM-based personalized agents. Existing frameworks overwhelmingly rely on scenario formulations that reduce the personalized memory challenge to "needle-in-a-haystack" retrieval. In these settings, static user preferences are presented as isolated statements, and the principal evaluation metric becomes factual recall in the presence of token-level distractors. This approach fails to capture the dynamic emergence of preferences, the integration of behavioral signals across sessions, and the myriad ambiguities and inconsistencies present in real interaction environments.
PERMA aims to capture the full complexity of real-world persona modeling by shifting the focus from static fact- or preference-recall to the maintenance of a temporally evolving persona state. The benchmark incentivizes and evaluates both continual preference integration and robust persona-state construction throughout protracted, noisy, and cross-domain interactions (Figure 1).
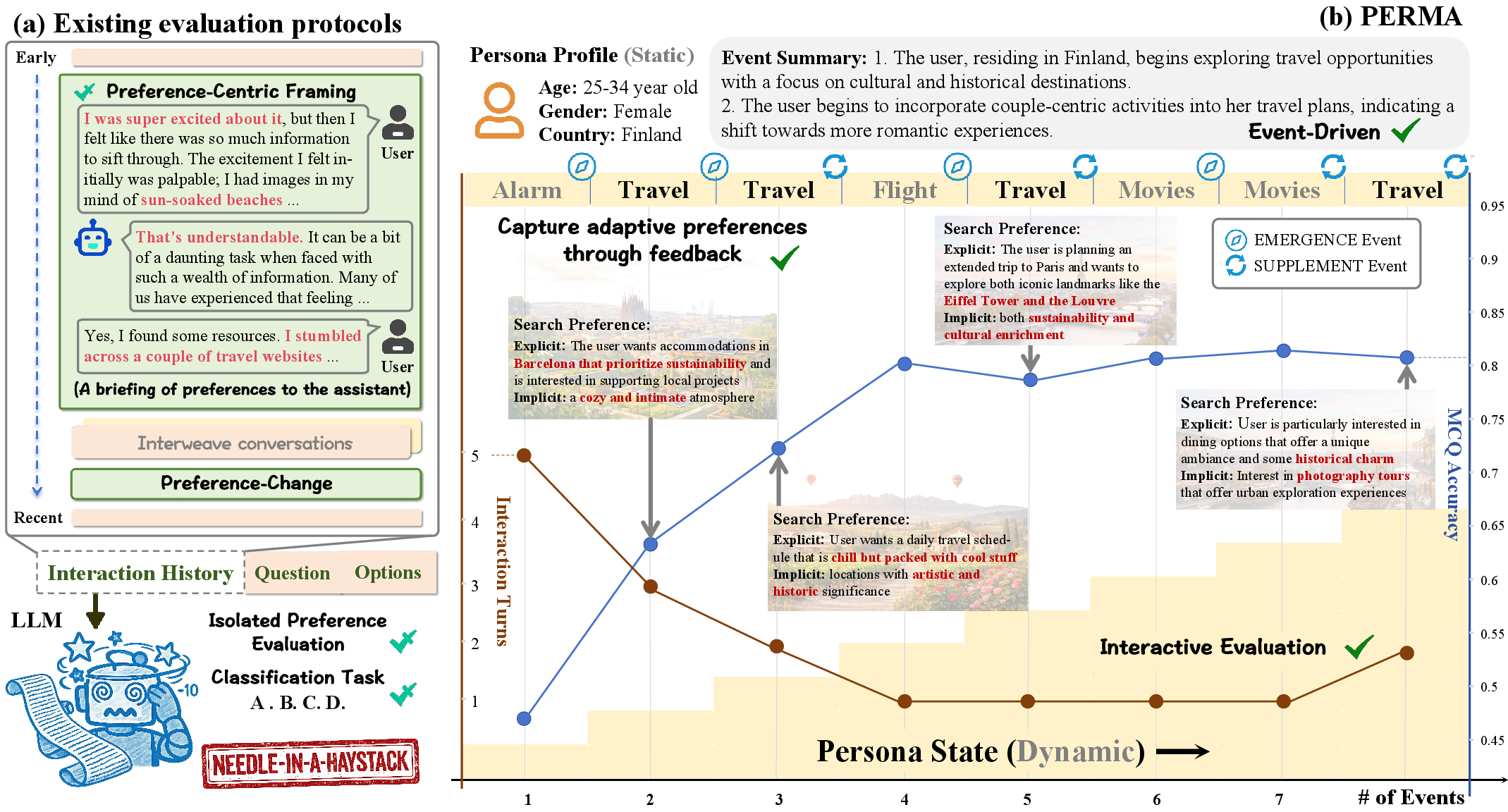
Figure 1: Comparison of evaluation paradigms—conventional benchmarks assess isolated preference retrieval, while PERMA integrates event-driven, temporally compounded preference tracking.
PERMA Data Construction and Event-Driven Evaluation
PERMA's dataset is constructed by leveraging authentic user profiles sampled from diverse geographies, demographics, and interests. User interaction histories are recast into temporally-ordered event sequences. Each interaction event is explicit or implicit in the emergence or supplementation of preferences, and all dialogues are systematically validated by LLM-based and human-in-the-loop pipelines for both coverage and linguistic naturalness.
The pipeline operates in two phases (Figure 2). First, a planner decomposes long-term user histories into fine-grained events, generating event-specific descriptions and objectives. These are then expanded into naturalistic, multi-turn dialogues by an LLM-based generator. Each session is categorized by type—emergence, supplement, or task probe. Task events (i.e., checkpoints) are interleaved at key positions to probe memory integration and resilience to cross-session/contextual interference.
Notably, text variability and user idiolects are explicitly simulated: prompt defects, ambiguous/inconsistent user behaviors, colloquialisms, multi-lingual fragments, and style-aligned turns are programmatically injected to reflect real usage distributions.
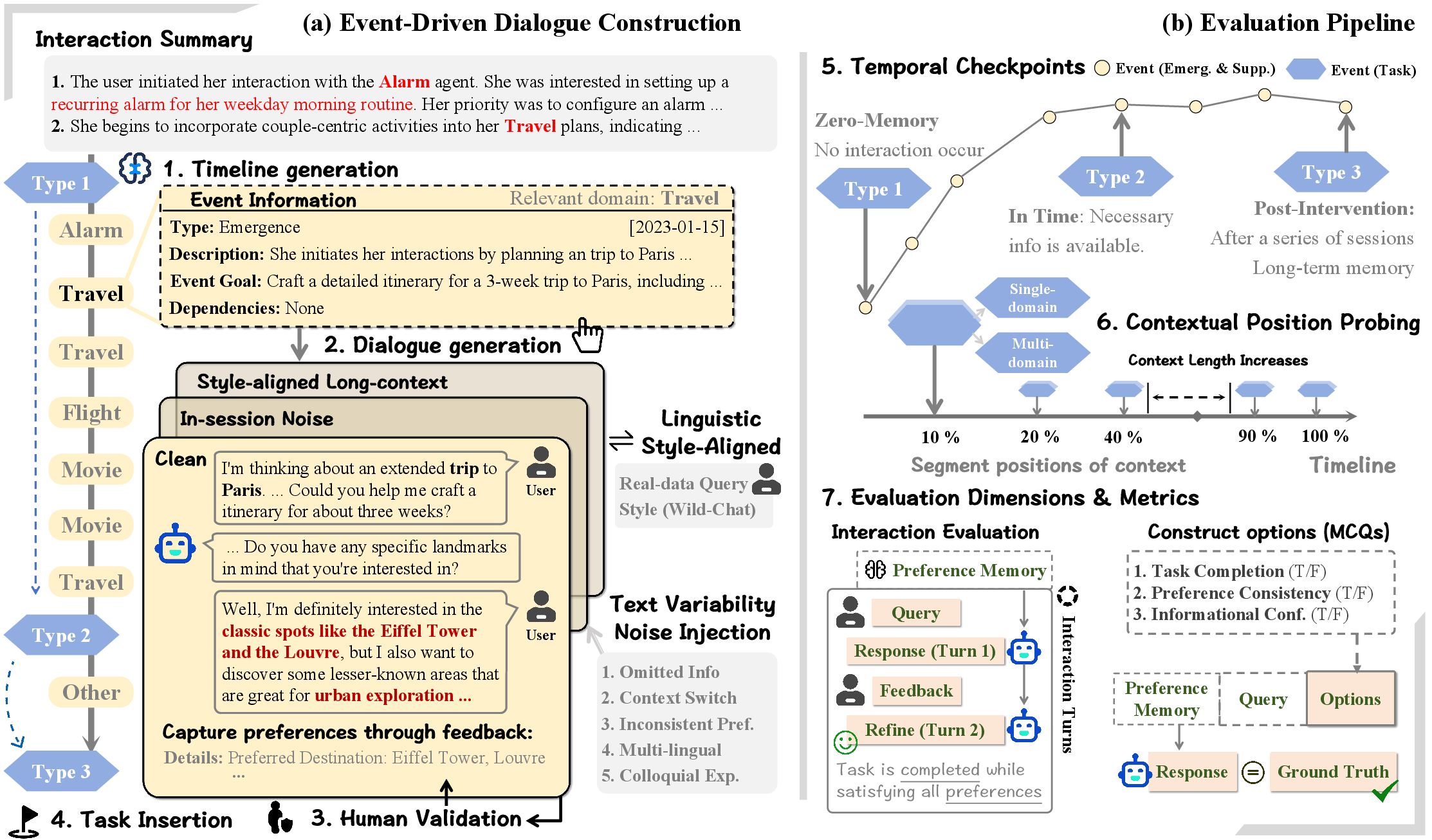
Figure 2: PERMA pipeline—timeline construction from user summaries, noise and style variability injection, and two-stage evaluation.
Evaluation Protocol and Metrics
PERMA comprehensively disentangles and probes memory fidelity, persona consistency, and retrieval efficiency:
- MCQ Probing: Task events are evaluated through carefully designed multiple-choice queries, ablating axes of task completion, preference consistency, and information confidence. This setup ensures models must demonstrate long-horizon synthesis rather than exploiting superficial cues.
- Interactive Evaluation: A user simulator, using the ground-truth persona state, provides iterative feedback until satisfactory agent responses are produced. This allows fine-grained measurement of Turn=1 (one-shot success), Turn≤2 (minor clarification), and overall Completion rates.
- Memory Fidelity & Efficiency: BERT-f1, LLM-as-a-judge memory scores, search duration, and token usage are used to assess the reconstruction and deployment cost of memory representations. These metrics reveal bottlenecks and trade-offs between token compression and retrieval quality.
Three temporal checkpoints are used: Type 1 ("zero-memory" baseline), Type 2 (post-domain session, maximal recall opportunity), and Type 3 (post-interference, maximal noise). Performance is further dissected by context depth and position (positional probing), allowing diagnosis of recency bias, catastrophic forgetting, and context-window saturation.
Model and System Comparison
Models evaluated include standalone LLMs (reasoning and chat variants), standard RAG pipelines, and state-of-the-art structured memory systems such as MemOS, Mem0, LightMem, Memobase, EverMemOS, and Supermemory. Across clean, noisy, and long-context conditions, experiments elucidate four primary dynamics:
- Reasoning LLMs excel at explicit persona consistency but degrade sharply when context length exceeds effective window size or when idiosyncratic lexical distribution increases (Figure 3).
- Memory systems demonstrate extreme token efficiency (up to 300× lower token usage) and higher stability across temporal drift, due to persistent persona representations. MemOS in particular provides robust performance across both MCQ and interactive settings with minimal recency collapse.
- Cross-domain and multi-session queries remain challenging (Figure 4), with all evaluated systems exhibiting significant accuracy and stability drops, especially under adversarial in-session noise or divergent style. This is attributed to structural limitations in retrieval segmentation (fixed top-k, absence of task-adaptive selection).
- Marginal utility of increased retrieval depth is highly system dependent (Figure 5): vanilla RAG pipelines benefit from expanded search due to coarse-grained chunk selection, whereas over-retrieval for memory agents introduces noise and degrades the downstream reasoning fidelity.
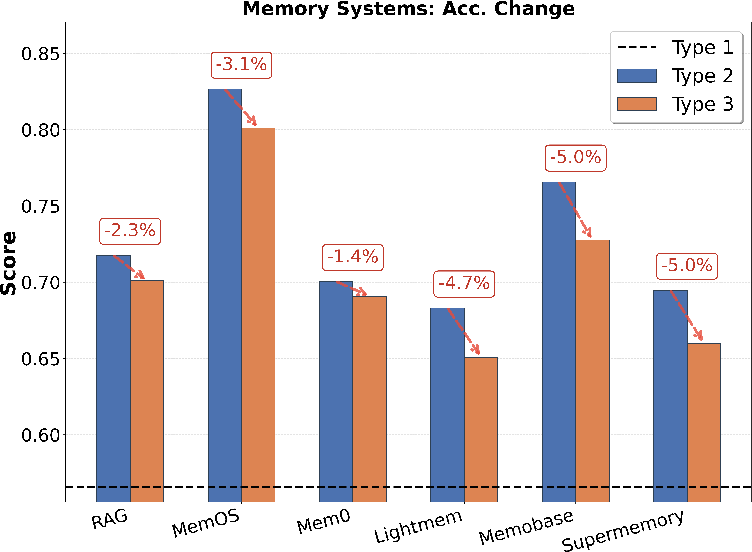
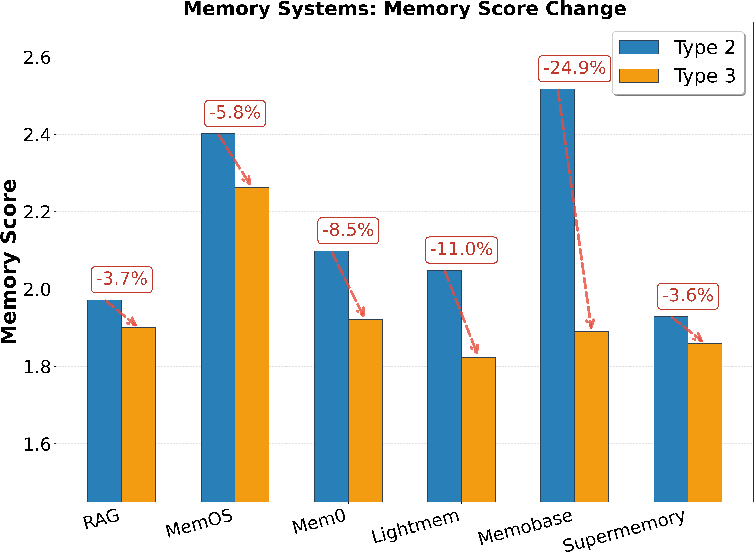
Figure 6: Memory system performance and robustness—MCQ accuracy and memory score trends across event checkpoints in clean single-domain evaluation.
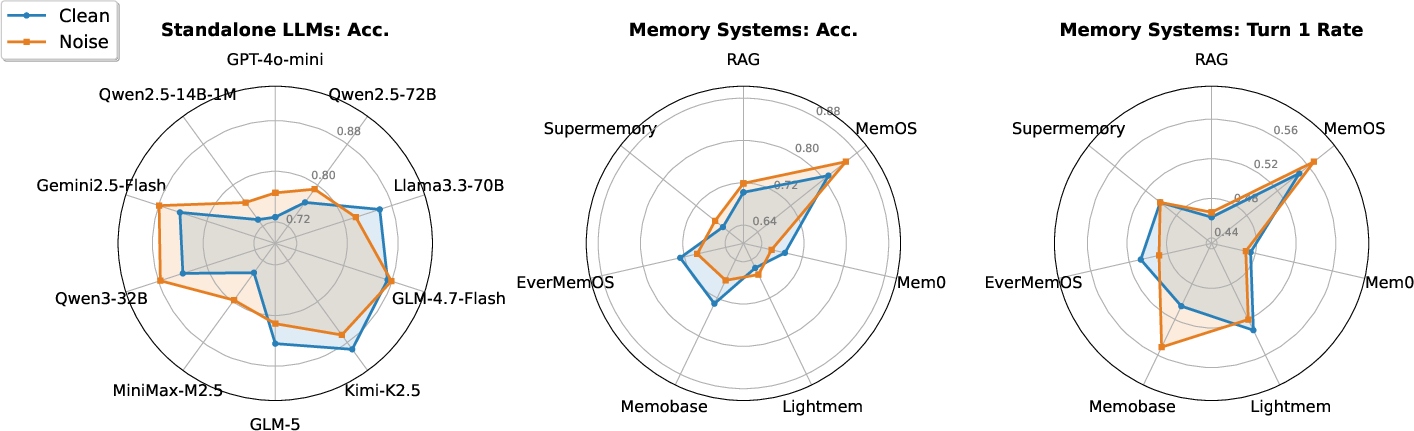
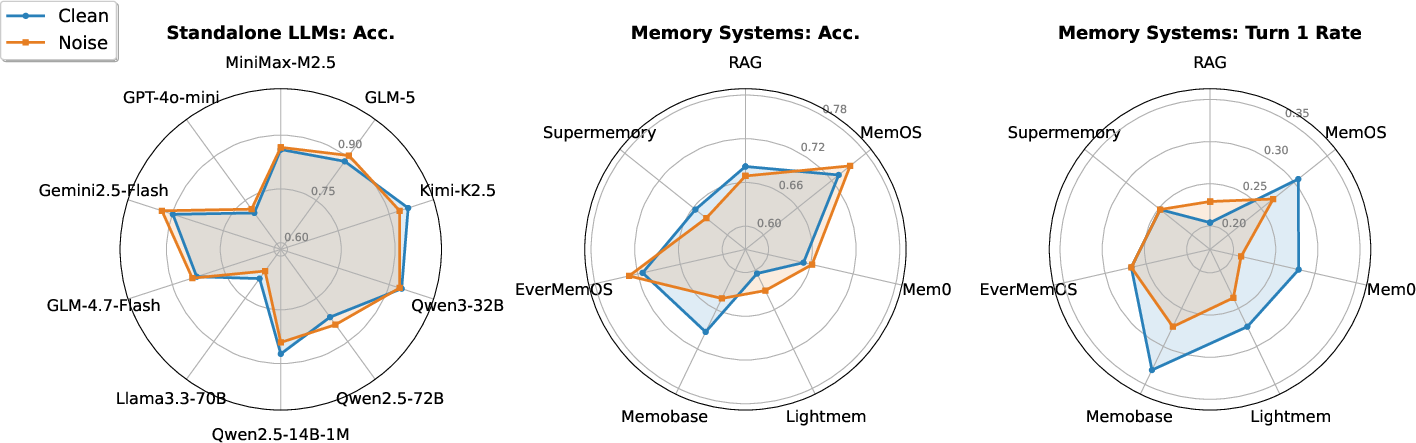
Figure 7: Cross-setting (clean/noise) MCQ and interactive Turn=1 performance for LLMs and memory systems.
Implications and Future Directions
PERMA's event-driven, temporally-evolving paradigm exposes crucial deficiencies in current personalization architectures. LLMs, despite large parameterization, exhibit severe context window limitations and cannot reliably track or infer emerging preferences under non-canonical linguistic patterns. Memory-augmented agents, though token efficient and resilient to synthetic context bloat, remain brittle under high cross-domain task entropy and lack flexible retrieval granularity. The presence of ambiguity- and style-induced in-session noise paradoxically improves some memory systems, but only up to the threshold where integration errors accumulate and persona drift undermines consistency.
Three primary implications emerge:
Conclusion
PERMA defines a new benchmark for assessing the full spectrum of challenges in event-driven, evolving persona memory—beyond static recall or "needle-in-a-haystack" search. It demonstrates that token compression and context window expansion alone do not address the complexity of personalization; structured, event-indexed, and evolution-aware memory architectures are essential. While MemOS and similar systems demonstrate marked gains in efficiency and resilience, robust multi-domain, high-entropy personalized agents remain a modeling and engineering frontier. Future progress will require advances in memory representation, event abstraction, and adaptive retrieval conditioned jointly on temporal evolution, cross-domain dependencies, and user behavioral noise.
(End.)