- The paper presents a novel DIRECT framework that formalizes video mashup creation as a cross-modal optimization problem using a three-agent architecture.
- It details a hierarchical process with Screenwriter, Director, and Editor agents that coordinate global narrative planning, segment intent, and low-level shot selection via dynamic trimming.
- Quantitative and qualitative results on Mashup-Bench show significant improvements, with up to 40% enhanced segment cohesion compared to previous methods.
Hierarchical Multi-Agent Planning for Professional-Grade Video Mashup Creation
Automated video mashup creation—recomposing shots from large, heterogeneous source footage to produce fluid, rhythmically engaging videos—presents significant algorithmic and perceptual challenges. The task requires satisfying cross-level constraints: global alignment of visual narrative to musical structure, segment-level multimodal cohesion, and low-level continuity in motion, framing, and audio-visual synchrony. Existing automated editing systems, predominantly semantic-centric or music-aware retrieval frameworks, do not explicitly model this hierarchy of constraints. Consequently, they neglect global narrative alignment and fine-grained cinematic techniques, resulting in sequences that, despite semantic correctness, suffer from abrupt transitions and poor auditory-visual alignment.
The DIRECT Framework: Multi-Agent Decomposition and Cross-Level Optimization
The DIRECT framework ("DIRECT: Video Mashup Creation via Hierarchical Multi-Agent Planning and Intent-Guided Editing" (2604.04875)) introduces video mashup creation as a Multimodal Coherency Satisfaction Problem (MMCSP). It decomposes the task into three cooperative agents, each targeting distinct hierarchies within the editing process:
- Screenwriter: Anchors the global structure using multimodal analysis and music-driven alignment. The agent first clusters and captions the footage library, producing a semantic and thematic index, and then maps visual elements to musical sections, generating a plan that dictates high-level emotional and visual transitions.
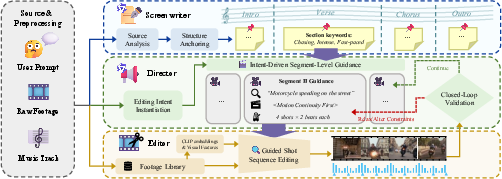
Figure 1: Overview of DIRECT’s hierarchical modules for multimodal orchestration in video mashup creation.
- Director: Instantiates local editing intent per segment. It discretizes the global plan into segment-wise constraints—a semantic query defining retrievable visual content, an editing heuristic (priority weighting across metrics), and rhythmic pacing guidance for alignment with music.
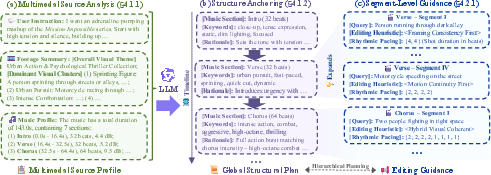
Figure 2: Visualization of hierarchical workflow—Screenwriter creates a temporal structural plan, Director expands this into intent-guided editing constraints.
- Editor: Executes low-level, intent-guided shot selection. Utilizing precomputed multimodal features (semantic, optical flow, saliency), the Editor solves a constrained path optimization problem over candidate shot sequences via an efficient beam search algorithm, augmented by dynamic sliding-window trimming for frame-level cut-point optimization.
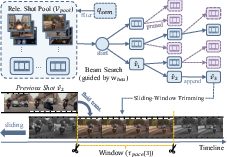
Figure 3: The Editor’s beam search with dynamic trimming ensures optimal shot sequences under segment-level intent constraints.
Crucially, the Director-Editor interaction is wrapped in a closed-loop validation protocol: if segment candidates fail to satisfy constraints, the Director iteratively relaxes or re-specifies the semantic query, enhancing robustness in cases of limited relevant footage.
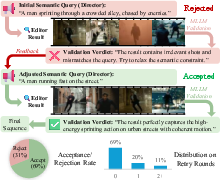
Figure 4: Closed-loop validation process detects and adapts to editing failures, triggering adaptive query adjustment.
Metrics and Benchmarking: Mashup-Bench
Reliance on ad hoc or semantic-only metrics is incompatible with the multifaceted quality requirements of professional mashups. DIRECT introduces a suite of explicit cross-modal metrics for evaluation, measuring semantic relevance, segment consistency, motion continuity, framing consistency, beat-cut synchronization, and energy correspondence. High-level goals (global alignment, local cohesion) are judged via structured human assessment, augmenting the objective benchmarks.
The accompanying benchmark, Mashup-Bench, consists of 38 videos spanning five genres, 64,000 shots, and ten diverse music tracks. Test cases—both intra- and cross-series—capture heterogeneous visual and musical pairings and serve as standard evaluation scenarios.

Figure 5: Statistics of Mashup-Bench—footage and genres spanned within the dataset.
Quantitative and Qualitative Results
DIRECT outperforms both agentic (VideoAgent), end-to-end (MMSC), and retrieval-based (T2V) baselines, particularly on low-level visual and auditory consistency metrics. Specifically, the dynamic trimming mechanism yields measurable gains in motion continuity and framing. Subjective evaluations (n=60) indicate substantial improvements (up to 40% in local segment cohesion over the strongest baseline), with DIRECT preferred for global narrative flow and segment-level multimodal synergy.

Figure 6: DIRECT achieves state-of-the-art visual and auditory coherence, outperforming baselines in both continuity and musical alignment.
An ablation study indicates that removing hierarchical planning modules (Screenwriter or Director) has marginal impact on explicit metrics but significantly degrades perceived global alignment and segment cohesion in subjective assessments. Removing dynamic trimming, however, degrades quantitative continuity scores directly, demonstrating the necessity of this low-level optimization step.

Figure 7: Illustration of visual continuity metrics, highlighting motion and framing transition scoring.
Efficiency and Modularity
Latency breakdown demonstrates the computational viability of the pipeline: offline precomputation of multimodal features enables fast online search. The framework maintains a low average generation time—∼10 minutes per mashup—while remaining modular to future improvements in feature extraction and agent reasoning.

Figure 8: System latency profile: most time is concentrated in MLLM reasoning and validation.
Implications and Theoretical Impact
DIRECT formalizes complex video editing as a unified cross-modal optimization task decomposable into hierarchical agentic subroutines. Its methodologically rigorous metrics, agent design, and robust closed-loop mechanisms set a new empirical and conceptual baseline for AI-driven creative editing. This approach suggests that further sophistication (for example, adaptive agent prompting, end-to-end differentiability, or attention to dataset scaling and compositional generalization) could drive even stronger results. Future directions include expanding MMCSP formalism to related editing domains (e.g., documentary summarization, event highlight generation) and integrating more adaptive perception backbones, especially as new multimodal foundation models emerge.

Figure 9: Representative shot sequences from DIRECT highlight achieved structural alignment and segment-level visual/auditory cohesion.
Conclusion
By re-casting video mashup creation as a hierarchical, constraint-driven optimization task and implementing a modular, agent-based architecture, DIRECT establishes a robust foundation for automated, professional-grade multimodal editing. Its superior empirical performance, grounded in a rigorous cross-modal benchmark and metric suite, underscores the necessity of explicit hierarchical planning for AI video editing. This framework provides a reference template for future systems targeting fluid integration of high-level intent with low-level coherence in multimodal creative tasks.