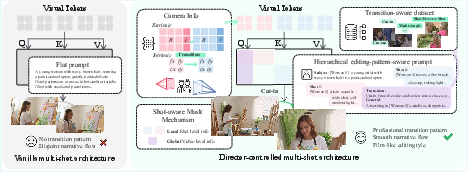
ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions
Abstract: Shot transitions play a pivotal role in multi-shot video generation, as they determine the overall narrative expression and the directorial design of visual storytelling. However, recent progress has primarily focused on low-level visual consistency across shots, neglecting how transitions are designed and how cinematographic language contributes to coherent narrative expression. This often leads to mere sequential shot changes without intentional film-editing patterns. To address this limitation, we propose ShotDirector, an efficient framework that integrates parameter-level camera control and hierarchical editing-pattern-aware prompting. Specifically, we adopt a camera control module that incorporates 6-DoF poses and intrinsic settings to enable precise camera information injection. In addition, a shot-aware mask mechanism is employed to introduce hierarchical prompts aware of professional editing patterns, allowing fine-grained control over shot content. Through this design, our framework effectively combines parameter-level conditions with high-level semantic guidance, achieving film-like controllable shot transitions. To facilitate training and evaluation, we construct ShotWeaver40K, a dataset that captures the priors of film-like editing patterns, and develop a set of evaluation metrics for controllable multi-shot video generation. Extensive experiments demonstrate the effectiveness of our framework.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ShotDirector, an AI system that can create short films made of multiple shots (like scenes in a movie) and control how those shots transition from one to the next. Instead of just stitching clips together, ShotDirector tries to “think like a director,” using camera choices and editing patterns to tell a smooth, coherent story—just like professional filmmaking.
What questions did the researchers ask?
To make AI-generated videos feel more like real movies, the team wanted to know:
- How can we control the way one shot changes to another (the transition), not just the content within each shot?
- How can an AI follow common film editing patterns, such as cut-in, cut-out, shot/reverse-shot, and multi-angle?
- Can we guide the model with camera settings (where the camera is, where it points, how it moves) and with structured text instructions that reflect editing rules?
- Will this make multi-shot videos look better, stay consistent, and feel more like real film editing?
How did they do it?
The researchers combined two big ideas—camera control and editing-aware instructions—and trained the AI on a curated movie-style dataset.
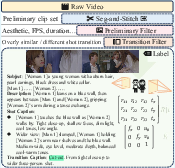
1) Building a film-style dataset (ShotWeaver40K)
They collected and cleaned up thousands of multi-shot video sequences from films, making sure transitions were meaningful (not random). For each video:
- They wrote layered captions: a general description of the story, plus per-shot descriptions.
- They labeled the transition type (for example, “cut-in” means moving from a wide shot to a closer shot of the same subject).
- They estimated camera poses (how the camera rotates and moves between shots).
This dataset teaches the AI what real editing looks like and gives it examples to learn from.
2) Teaching the model to listen to the camera
They injected camera information directly into the video-generation process. Think of it like telling a video game camera exactly where to stand and where to point.
Two kinds of camera inputs are used:
- Extrinsic parameters: the camera’s position and orientation (like “stand here and face left”).
- Plücker embedding: a math way to describe the line of sight from the camera to each pixel, which helps the model understand how the camera “sees” the scene. You can think of this as a map of “every ray of vision” the camera uses.
Together, these signals let the AI control viewpoint changes smoothly—so transitions feel intentional, not random.
3) Teaching the model to follow editing rules
They added a “shot-aware mask,” which is basically a set of rules about which parts of the video and text should influence each moment in the generation process:
- Global context: shared information (the main subject, overall scene, and the transition type).
- Local context: details specific to each shot (what’s happening in this shot, its style, framing, etc.).
Analogy: Imagine a group conversation. The mask tells each person (token) who they’re allowed to listen to—sometimes everyone (global), sometimes just their small group (local). This keeps the whole story consistent but lets each shot have its own unique look and purpose.
4) Training strategy
They trained the model in two stages:
- Stage 1: Learn editing patterns from the real film-style dataset (ShotWeaver40K).
- Stage 2: Mix in synthetic camera-controlled videos to strengthen camera pose control and stability.
This helps the model both understand storytelling and follow precise camera directions.
What did they find?
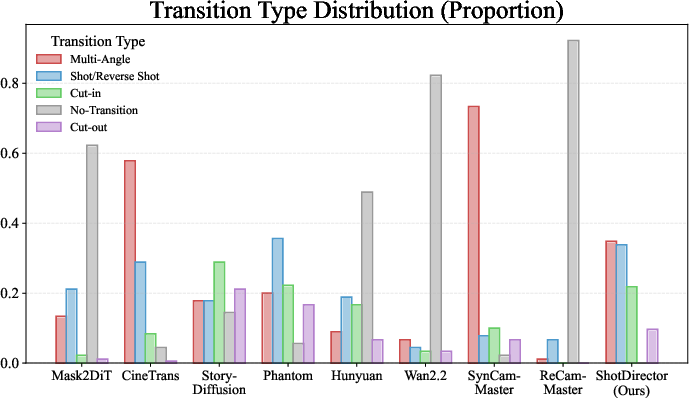
ShotDirector generated multi-shot videos that:
- Follow the requested transition types more accurately (for example, if asked for "cut-in," the model reliably does it).
- Look more film-like, with smoother storytelling and better rhythm.
- Keep characters and scenes more consistent across shots, while still making each shot visually distinct.
- Achieve strong overall quality and control compared to other methods they tested.
They also did “ablation studies” (turning features off and on to see their effect) and found:
- Camera information (both extrinsic and Plücker) improves control over viewpoint changes.
- The shot-aware mask is crucial for balancing global coherence (same characters/story) and local diversity (each shot has its own look).
- The two-stage training improves both transition control and visual quality.
In short, ShotDirector made transitions less like sudden clip changes and more like purposeful editing choices a director would make.
Why does this matter?
This work pushes AI video generation closer to real filmmaking. Instead of making a sequence of unrelated clips, ShotDirector can:
- Help creators, students, and storytellers design scenes with professional editing patterns.
- Support pre-visualization in film and animation (planning shots before shooting).
- Improve content for games, education, and social media where narrative flow matters.
- Serve as a foundation for future tools that let people “direct” AI videos with simple instructions.
Looking ahead, the team suggests exploring longer videos, more complex transition types, and deeper control over film language—steps that would make AI an even better creative partner for directing and storytelling.
Key terms explained (in simple words)
- Shot: A single continuous piece of camera footage. Multi-shot videos have several shots put together.
- Transition: How the video moves from one shot to the next (e.g., cut-in, cut-out, shot/reverse-shot, multi-angle).
- Diffusion model: A type of AI that starts from “visual noise” and gradually turns it into a clear video by following guidance.
- Camera pose (6-DoF): The camera’s position (where it is) and orientation (which way it faces); “6 degrees of freedom” means it can move in 3 directions and rotate around 3 axes.
- Plücker embedding: A mathematical way to describe the sightline from the camera to each pixel, helping the AI understand how the camera views the scene.
- Mask (shot-aware): Rules that control what information each part of the model can use, keeping global story consistency while allowing local shot differences.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each point is concrete and intended to guide future research.
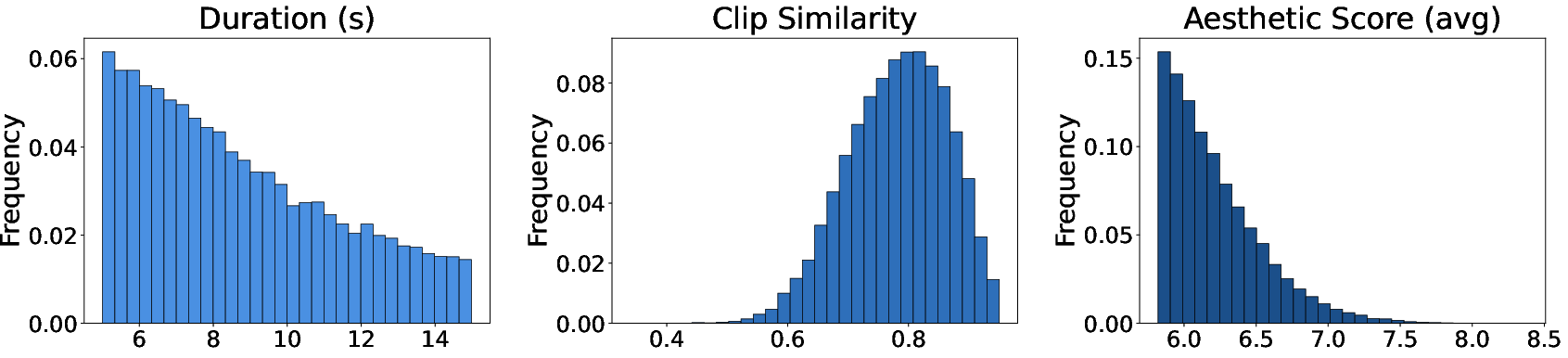
- Dataset composition and bias remain unspecified: the distribution of genres, eras, cultures, camera rigs, indoors/outdoors, and lighting conditions in ShotWeaver40K is not reported, making it unclear which cinematographic priors the model actually learns and where it may fail.
- Reliance on GPT-5-mini for hierarchical captions and transition labels is unvalidated: no human verification, inter-annotator agreement, or error analysis is provided for the script-, shot-, and transition-level annotations.
- Camera intrinsics source is unclear: the paper uses Plücker rays requiring , but does not specify how intrinsics (focal length, principal point, distortion) are estimated for real footage, nor quantify the impact of intrinsics errors on generation quality.
- Pose estimation noise is acknowledged but not systematically studied: robustness to noisy or missing extrinsics/intrinsics at inference, and the model’s behavior under pose–caption mismatches, remain untested.
- Limited transition taxonomy: only four abrupt cut types (shot/reverse-shot, cut-in, cut-out, multi-angle) are modeled, excluding widely used film grammar (match cuts, cross-cutting, montage, inserts, cutaways, J/L-cuts, dissolves, wipes, iris, smash cuts, rack focus, crash zoom), with no pathway described for expanding beyond cuts.
- No audio modeling: transitions that rely on sonic leads/lags, rhythm, dialogue timing, or music (e.g., J/L-cuts, sound bridges) are not represented or evaluated.
- Global visual context is restricted to the first frame: using only the initial frame as “global” may be insufficient for longer sequences or evolving scenes; alternatives (e.g., dynamic global memory, keyframe pools, learned story states) are not explored.
- Scalability to longer narratives is untested: maximum shot count, sequence duration, memory use, and runtime for minute-long videos (or acts/scenes) are not reported, nor are failure regimes at longer horizons.
- Evaluation scale and validity require strengthening: only 90 prompts are used, with no statistical significance testing, no expert editor studies, and limited human evaluation to validate “professional editing” claims.
- Automated transition-type classification (Qwen) is unvalidated: the classifier’s accuracy, bias, and agreement with human editors on generated videos are not reported.
- FVD and “real film-edited videos” reference set are under-specified: the real set’s composition and alignment to the model’s training distribution are unclear, and per-transition-type FVD is not analyzed.
- 3D scene consistency is not guaranteed: Plücker/extrinsic injection does not enforce coherent scene geometry, object permanence, occlusion reasoning, or metric scale; these aspects are neither evaluated nor constrained.
- Continuity rules are not explicitly modeled or measured: adherence to the 180-degree rule, eyeline match, screen direction, and axis of action in dialogue or action sequences is unassessed.
- User controllability remains low-level: the interface expects 6-DoF poses and intrinsics; no high-level “director intent → camera plan” planner or inverse mapping from narrative directives to poses is provided.
- Motion and capture effects are unaddressed: handling moving subjects, handheld jitter, motion blur, rolling shutter, and lens distortion during transitions is not studied or controlled.
- Legal/ethical and reproducibility concerns: the use of raw movie footage, licensing status, dataset access, and ethical considerations (e.g., deepfake risks, watermarking) are not discussed.
- Training scale choices lack exploration: the effect of larger backbones, longer training schedules, and alternative optimizers or curricula on controllability and quality is not analyzed.
- Baseline fairness is uncertain: tuning efforts, prompt parity, and compatible masking/control settings for compared methods are not documented, leaving room for confounding in comparisons.
- Camera-control evaluation (RotErr/TransErr) lacks clarity: ground-truth camera data for real videos are unavailable, making metrics meaningful primarily for synthetic data; comprehensive camera-control metrics (including focal/aperture changes, dolly vs. zoom) are missing.
- Cinematographic look parameters are omitted: aperture, shutter, ISO, sensor size, lens characteristics (bokeh, vignetting, chromatic aberration) and their influence on storytelling are not modeled or controlled.
- Failure mode analysis is absent: no systematic report of when ShotDirector produces artifacts (flicker, identity drift, background discontinuities), misclassifies transitions, or collapses diversity vs. consistency.
- Domain generalization is untested: performance on non-film content (sports, documentaries, news, vlogs, animation) and user-shot videos is unknown.
- Multi-scene narrative structure is out of scope: the framework targets within-scene multi-shot transitions, not scene changes, act-level structuring, or subplot weaving.
- Mask scheduling design is underexplored: the choice to keep all tokens visible early and then apply shot-aware masks is not compared to alternative schedules (e.g., learned masks, adaptive visibility, curriculum masking) or assessed for long-range dependencies.
- Joint calibration of camera branches is unspecified: how discrepancies between the extrinsic and Plücker branches (e.g., mismatched ) are reconciled, and whether the model learns to trust one branch over the other, is not examined.
- Diversity–consistency trade-offs are not characterized: controllability–quality curves, user-adjustable knobs, and Pareto analyses are missing, despite the centrality of these trade-offs in editing.
- Human validation of “professional editing” is missing: editor/judge panels, crowd studies, or task-based evaluations (e.g., comprehension, emotional engagement) are needed to substantiate claims of film-like transitions.
- Open-sourcing details are unclear: availability of ShotWeaver40K, annotation schema, camera parameters, evaluation prompts, and code to reproduce training/evaluation is not confirmed.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage ShotDirector’s controllable multi-shot generation, camera parameter injection, shot-aware masking, dataset, and evaluation suite. Each bullet highlights the sector, practical workflow or product, and key assumptions or dependencies.
- Industry — Previsualization and animatics for film/TV and ads
- What: Rapidly generate multi-shot previews with explicit transition types (shot/reverse-shot, cut-in/out, multi-angle) and camera poses to explore narrative pacing and coverage before principal photography.
- Workflow/Product: “AI Director” panel in existing NLEs (Premiere, DaVinci) or previs tools; text/script → hierarchical prompts → multi-shot renders with tunable 6-DoF camera extrinsics and intrinsic-aware Plücker ray maps.
- Assumptions/Dependencies: Access to a strong base T2V model; GPU/cluster capacity; legal usage and rights for datasets; teams can supply or estimate camera parameters per shot.
- Industry — Automated storyboarding and shot planning
- What: Generate annotated shot lists and visual references that encode transition types and camera specifications from a scene description.
- Workflow/Product: Script-to-shotlist service that outputs frames/clips plus metadata (camera matrices, framing, transition type) for import into scheduling and shot-design tools.
- Assumptions/Dependencies: Reliable camera pose estimation (e.g., VGGT or similar); consistent mapping between hierarchical prompts and tokens via the shot-aware mask.
- Industry — Cutscene generation for games and interactive media
- What: Produce consistent, film-like multi-shot sequences for in-game cinematics with controllable camera changes and narrative rhythm.
- Workflow/Product: Engine plugin (Unreal/Unity) that calls a generation service to output pre-rendered cutscenes matching design prompts; variant generation for A/B testing.
- Assumptions/Dependencies: Integration layer between engine and T2V backend; content safety checks for IP and ratings; latency acceptable for production iteration.
- Industry — Branded content and social media video production
- What: Generate short-form multi-shot videos with consistent subjects (via reference-to-video transfer) and professional transitions for marketing, product demos, or influencer posts.
- Workflow/Product: “Brand-safe generator” that takes reference images, brand guidelines, and hierarchical prompts to produce on-message multi-shot ads or reels.
- Assumptions/Dependencies: Reference-to-video modules (e.g., VACE-like) available; identity/brand consistency embeddings; content moderation; cloud inference cost control.
- Industry — Automatic trailer/teaser generation and re-versioning
- What: Create trailers with specific editing patterns (e.g., faster cut-ins for mobile viewers, wider cut-outs for theatrical contexts).
- Workflow/Product: Campaign tool that auto-generates multiple cut patterns and formats; export to EDL/XML for human fine-tuning in NLEs.
- Assumptions/Dependencies: Automated aesthetic and imaging quality scoring (MUSIQ, aesthetic predictors) in the loop; distribution platform constraints (aspect ratio, duration).
- Academia — Benchmarking and evaluation of multi-shot generation
- What: Adopt the provided evaluation metrics suite (transition confidence, type accuracy, FVD, semantic/visual consistency) to compare models.
- Workflow/Product: Open-source evaluation scripts, prompts, and protocols to standardize reporting across labs.
- Assumptions/Dependencies: Access to models and inference; reliance on third-party assessors (Qwen, TransNetV2, ViCLIP); reproducibility of metric runs.
- Academia — Dataset use for learning cinematic priors
- What: Train models on ShotWeaver40K to study how editing conventions emerge in generative systems.
- Workflow/Product: Curriculum for generative film-language research; ablation studies on hierarchical prompting and camera conditioning.
- Assumptions/Dependencies: Dataset licensing; compute for two-stage training (real + synthetic SynCamVideo augmentation).
- Daily Life — Consumer “Director Mode” for scripted or memory videos
- What: Mobile or web apps that turn a text outline or photo set into multi-shot videos with selectable transition types and camera styles.
- Workflow/Product: Guided UI with templates (“two-person dialogue,” “product reveal,” “event recap”) leveraging shot-aware masks for local/global prompt control.
- Assumptions/Dependencies: Cloud inference or strong on-device hardware; simple UX for specifying transitions; content filters and watermarks.
- Policy — Quality control and disclosure for AI-edited sequences
- What: Employ the evaluation suite to audit and certify transition clarity, narrative coherence, and aesthetic quality; embed provenance signals in outputs.
- Workflow/Product: “AI Editing QA” service for platforms to verify multi-shot quality and attach disclosure tags.
- Assumptions/Dependencies: Agreement on accepted metrics; watermarking standards; governance frameworks for synthetic video distribution.
Long-Term Applications
These use cases require further research, scaling, or productization—particularly around longer sequences, real-time constraints, compositional control, and multimodal integration.
- Industry — Virtual production co-director with live camera guidance
- What: Real-time suggestion/generation of next shots and transitions on LED stages, mapping prompt-level narrative intent to camera moves and editorial rhythms.
- Workflow/Product: On-set “co-director” system that fuses 6-DoF tracking data, scene layouts, and hierarchical prompts to propose shots and automatically generate previs proxies.
- Assumptions/Dependencies: Low-latency inference; robust multi-camera calibration; integration with stage tracking and asset pipelines; safety approvals on set.
- Industry — End-to-end script-to-edit pipeline with EDL export
- What: From script breakdown to multi-shot generation, auto-assembling an editable timeline with cinematographic metadata and placeholders for human revision.
- Workflow/Product: “AI Assistant Editor” that produces EDL/XML timelines, transitions, camera notes, and beat sheets; integrates iterative human adjustments.
- Assumptions/Dependencies: Reliable mapping from long scripts to scene-level hierarchical prompts; long-context generation stability; standardized metadata schemas.
- Industry — Personalized multi-modal ad generation at scale
- What: Mass-create variations of multi-shot ads with culturally localized transitions, pacing, and framing optimized by engagement models.
- Workflow/Product: Campaign orchestration platform that autogenerates variants and runs A/B tests; selects cut patterns per audience segment.
- Assumptions/Dependencies: Attribution-safe personalization; compliance with regional ad policies; data governance; integrations with analytics.
- Industry — Game engine “autocinematics” with runtime adaptability
- What: Generate or adapt multi-shot sequences on the fly based on player behavior, with controlled transitions and camera logic.
- Workflow/Product: Runtime cinematic controller that composes transitions and frames in response to gameplay signals.
- Assumptions/Dependencies: Real-time constraints; content caching; alignment with engine rendering; guardrails for continuity and ratings.
- Academia — Formalization of film language in generative models
- What: Build hierarchical priors over editing, framing, and rhythm; extend to complex conventions (eye-line matches, L-cuts/J-cuts, montage, cross-cutting).
- Workflow/Product: Expanded datasets and models that capture advanced editorial semantics; new metrics for narrative coherence and emotional focus.
- Assumptions/Dependencies: Larger curated cinematic corpora; refined captioning with expert annotations; multimodal narrative evaluators.
- Academia — Generalized hierarchical prompting for other modalities
- What: Transfer the shot-aware mask and hierarchical prompt design to audio (sound design transitions), 3D scene generation, and interactive storytelling.
- Workflow/Product: Cross-modal “structure-aware” generative frameworks that enforce global/local context consistency.
- Assumptions/Dependencies: Modality-specific tokenization and masking; compositional evaluation metrics; multi-agent orchestration.
- Robotics and XR — Camera path simulation and training
- What: Use generative multi-shot sequences as simulated environments for training drone/camera operators and testing autonomous filming strategies.
- Workflow/Product: “Virtual cinematography lab” that generates controlled scenarios with explicit camera poses and transitions for skill practice or algorithm development.
- Assumptions/Dependencies: Domain transfer to real-world camera dynamics; physics-aware extensions; integration with simulators.
- Daily Life — Real-time co-editing assistants for creators
- What: Assist users during live capture or editing sessions by suggesting next shots and transitions aligned to narrative intent.
- Workflow/Product: Smart capture modes on phones/gimbals; NLE assistants that propose sequence-level edits and transition types with previews.
- Assumptions/Dependencies: Real-time inference; UI acceptance; battery/compute limits on devices; privacy and safety features.
- Policy — Standards for provenance, disclosure, and labor impacts
- What: Define and enforce metadata standards for AI-generated multi-shot sequences, and assess impacts on editorial labor markets.
- Workflow/Product: Industry guidelines for watermarking, credits, and model reporting; certification programs for ethical use in media production.
- Assumptions/Dependencies: Cross-industry consensus; regulatory buy-in; auditable pipelines and model cards.
Cross-cutting assumptions and dependencies
- Model readiness: Requires access to high-quality base T2V models and the ShotDirector components (camera extrinsics + Plücker embedding, shot-aware masks).
- Data and licensing: Use of curated cinematic datasets must meet copyright and licensing requirements; synthetic augmentation (SynCamVideo) aids robustness.
- Compute and latency: Many applications need GPU clusters; real-time variants require significant optimization or on-device acceleration.
- Prompting and UX: Effective hierarchical prompt design and user-friendly tooling are critical; shot-aware masking must be correctly implemented in the architecture.
- Safety and governance: Content moderation, watermarking/provenance, and identity safeguards are necessary for commercial and consumer deployments.
- Evaluation reliability: Current metrics depend on third-party models (Qwen, TransNetV2, ViCLIP, MUSIQ); ongoing validation and standardization are needed.
Glossary
- 3D priors: Pre-existing three-dimensional geometric constraints used to guide generation models. "Subsequent works further incorporate geometric constraints or 3D priors \cite{bahmani2025ac3d,bahmanivd3d,houtraining,xu2024camco}."
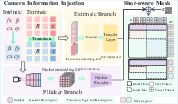
- 6-DoF poses: Six degrees of freedom describing a camera’s 3D rotation and translation. "Specifically, we adopt a camera control module that incorporates 6-DoF poses and intrinsic settings to enable precise camera information injection."
- Ablation studies: Controlled experiments removing or modifying components to assess their impact. "In this section, we conduct ablation studies to evaluate the contribution of each component in our framework."
- Adam optimizer: A gradient-based optimization algorithm combining momentum and adaptive learning rates. "we use the Adam optimizer \cite{adam2014method} with a learning rate of "
- Attention layers: Neural network components enabling tokens to weigh and integrate information from others. "the visual latents from the -th shot are processed through the attention layers in the DiT architecture"
- Camera extrinsic parameters: Pose components describing a camera’s rotation and translation relative to world coordinates. "The extrinsic branch employs an MLP to directly inject the camera extrinsic parameters into visual latents:"
- Camera intrinsic parameters: Internal camera properties (e.g., focal length) defining projection from 3D to image coordinates. "Conventionally, the camera pose is defined by the intrinsic and extrinsic parameters, denoted as and "
- Cinematography-aware captions: Structured textual annotations encoding shot content, camera settings, and editing patterns. "Moreover, cinematography-aware captions provide explicit annotations of editing patterns along with detailed camera parameters for each shot"
- Cut-in: Film transition moving to a closer framing of the same subject. "cut-in (transition to a closer framing of the same subject)"
- Cut-out: Film transition moving to a wider, more contextual view. "cut-out (transition to a wider contextual view)"
- Denoising process: The iterative procedure in diffusion models that removes noise to synthesize data. "To integrate conditioning signals into the denoising process, we perform training based on \cite{wan2025wan}."
- Diffusion Transformer: A transformer-based architecture for scalable diffusion modeling. "Building upon architectures such as Diffusion Transformer \cite{DiT}"
- End-to-end diffusion frameworks: Models that jointly generate entire sequences, enabling interactions across shots. "More recently, end-to-end diffusion frameworks \cite{guo2025longcontexttuning,qi2025mask2dit,jia2025moga} have been proposed to enable inter-shot interaction within the generative process"
- Extrinsic branch: The network pathway that injects camera pose (rotation/translation) features into the model. "The extrinsic branch employs an MLP to directly inject the camera extrinsic parameters into visual latents:"
- Fréchet Video Distance (FVD): A metric estimating distributional distance between sets of real and generated videos. "Fréchet Video Distance \cite{unterthiner2018towards,unterthiner2019fvd} measures the distributional gap between generated and real film-edited videos."
- Group attention mechanism: Custom attention design that partitions tokens into groups for scalable long-sequence modeling. "MoGA \cite{jia2025moga} introduces customized group attention mechanism that enables the model to handle longer multi-shot sequences effectively"
- Hierarchical editing-pattern-aware prompting: Layered text guidance encoding overall narrative plus shot-level editing semantics. "an efficient framework that integrates parameter-level camera control and hierarchical editing-pattern-aware prompting."
- Latent diffusion framework: Generative approach operating in a compressed latent space, improving efficiency and quality. "the latent diffusion framework \cite{ho2020denoising, rombach2022high}"
- Long Context Tuning (LCT): Technique to adapt models for long-range dependencies across shots. "LCT \cite{guo2025longcontexttuning} employs a specialized positional encoding scheme to facilitate shot-level modeling."
- MoGA (Mixture-of-Groups Attention): A method introducing group-based attention for handling long multi-shot sequences. "MoGA \cite{jia2025moga} introduces customized group attention mechanism that enables the model to handle longer multi-shot sequences effectively"
- Multi-angle: Transition switching between distinct viewpoints of the same action. "multi-angle (switching between different viewpoints of the same action)"
- Multi-shot video generation: Synthesizing sequences composed of multiple shots with intentional transitions and narrative flow. "multi-shot video generation \cite{chen2024seine,qi2025mask2dit,guo2025longcontexttuning,wu2025cinetrans,ttt}, which aims to synthesize film-like narratives through shot transitions"
- Plücker branch: The pathway that encodes per-pixel viewing rays via Plücker coordinates for spatial geometry. "Furthermore, the Plücker branch follows the conventional formulation to represent the spatial ray map corresponding to the camera information."
- Plücker embedding: Representation of 3D lines (viewing rays) combining moment and direction to encode camera geometry. "We employ Plücker embedding \cite{sitzmann2021light} to encode the geometric information of each pixelâs viewing ray"
- Positional encoding scheme: A method for injecting position information into models to handle structured sequences. "LCT \cite{guo2025longcontexttuning} employs a specialized positional encoding scheme to facilitate shot-level modeling."
- RotErr: Metric quantifying rotation error in camera pose control. "Following \cite{he2024cameractrl}, we adopt RotErr and TransErr to measure camera pose control performance"
- Self-attention: Mechanism allowing each token to attend to others within the sequence. "added to the visual tokens associated with the -th shot prior to self-attention:"
- Shot segmentation: Process of detecting boundaries between shots in raw video. "we perform shot segmentation \cite{soucek2024transnet} and similar-segment stitching \cite{girdhar2023imagebind}"
- Shot/reverse shot: Alternating perspective structure commonly used to depict dialogue. "shot/reverse shot (dialogue-based alternation of perspectives)"
- Shot-aware mask mechanism: Structured masking that constrains token interactions to global/local contexts per shot. "we adopt a shot-aware mask mechanism that guides each token to incorporate both global and local cues in visual and textual domains"
- Similar-segment stitching: Technique to assemble segments with related content into coherent sequences. "we perform shot segmentation \cite{soucek2024transnet} and similar-segment stitching \cite{girdhar2023imagebind}"
- Synchronized multi-camera generation: Coordinated synthesis across multiple cameras ensuring consistency. "SynCamMaster \cite{baisyncammaster} and ReCamMaster \cite{bai2025recammaster} introduce frameworks for synchronized multi-camera generation and 3D-consistent scene modeling."
- Temporal coherence: Consistent motion and appearance over time in generated video. "synthesizing realistic and temporally coherent videos from textual descriptions"
- Token visibility: Controlling which tokens can attend to which others to manage information flow. "employ a shot-aware mask mechanism to regulate token visibility across global and local contexts."
- TransErr: Metric quantifying translation error in camera pose control. "Following \cite{he2024cameractrl}, we adopt RotErr and TransErr to measure camera pose control performance"
- Transition Type Accuracy: Evaluation of whether generated transitions match the specified type. "Qwen \cite{wang2024qwen2} is further employed to assess the Transition Type Accuracy, measuring whether the generated transition type aligns with the prompt."
- TransNetV2: Model for detecting and scoring shot transitions. "we use TransNetV2 \cite{soucek2024transnet} to compute the Transition Confidence Score"
- Two-stage training scheme: A curriculum that trains on real data first, then augments with synthetic data for robustness. "we adopt a two-stage training scheme."
- VGGT: Method for estimating camera rotation and translation from video frames. "VGGT \cite{wang2025vggt} estimates camera rotation and translation relative to the first shot"
- ViCLIP: Vision-LLM features used to assess text–video alignment and consistency. "use ViCLIP \cite{internvid} feature similarity to quantify text-video alignment."
- Visual latents: Compressed latent representations of video frames used by diffusion models. "The extrinsic branch employs an MLP to directly inject the camera extrinsic parameters into visual latents:"
- Visual tokens: Tokenized representations of visual features used in transformer-based diffusion. "Finally, the dual-branch camera information is added to the visual tokens associated with the -th shot prior to self-attention:"
- Visual fidelity: The realism and quality of generated imagery. "Despite their visual fidelity, the produced multi-shot videos remain devoid of cinematic narrative structure and intentional shot design characteristic of professional filmmaking."
- Warm-up phase: Initial training period focusing on specific components before joint optimization. "During the warm-up phase, only the dual-branch encoder is trained, with the extrinsic branch limited to its transfer layer."
Collections
Sign up for free to add this paper to one or more collections.