- The paper introduces a cascaded video generation pipeline that uses global shot planning to synchronize music, text, and visuals for expressive video synthesis.
- It leverages diffusion transformers with a novel camera adapter and timestep-aware dynamic windows to ensure smooth, temporally consistent video sequences.
- Direct Preference Optimization is integrated to align with human evaluators, achieving superior motion naturalness and reduced translation error.
Music-Driven Multi-Stage Video Generation with YingVideo-MV
Introduction
YingVideo-MV introduces a cascaded, music-driven video generation system that synthesizes expressive, high-fidelity music-performing portrait videos. The framework unifies multiple modalities—including music, text, and image conditioning—through explicitly planned global shot lists, temporally-aware diffusion architectures, and a novel strategy for temporal consistency across long sequences. The system demonstrates substantial advances in video synthesis tasks, notably through unified audio-text-visual shot planning, explicit and fine-grained camera trajectory control, and Direct Preference Optimization (DPO) for human-perceptual alignment.
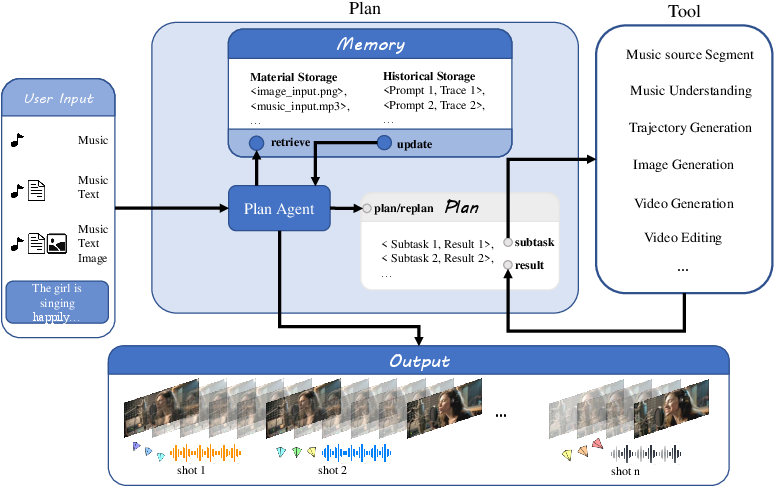
Figure 1: YingVideo-MV’s cascaded pipeline integrates multimodal inputs and global planning, yielding music-performing videos with high-fidelity portraits, dynamic camera, and synchronized audio-visual content.
Cascaded Generation Pipeline and Planning
YingVideo-MV treats music video (MV) generation as a sequential decision process, orchestrated by the MV-Director agent. The agent ingests high-level goals, multimodal user inputs, and leverages a rich operational toolbox encompassing music segmentation, semantic analysis, camera trajectory design, and scene synthesis modules. The pipeline is two-staged:
- Global Planning (MV-Director): Decomposes the music into semantically meaningful sub-clips by detecting beat-wise boundaries, assigning each segment corresponding shot intent, emotional tone, and narrative structure—derived with the assistance of MLLMs for music understanding and script-level annotation.
- Clip-wise Generation: Using the shot list, the pipeline synthesizes high-fidelity portrait images, generates smooth and expressive camera trajectories, and orchestrates visually coherent audio-synchronized video clips. Outputs are refined for global continuity and are post-processed to enhance consistency across scene transitions.
This explicit separation of planning and generation elevates the system’s control and alignment with cinematic language, giving rise to strong narrative logic and aesthetic flexibility.
Multi-Modal Architecture and Camera Trajectory Modeling
At its core, YingVideo-MV utilizes a Diffusion Transformer (DiT) backbone architecture enhanced for multimodal conditioning. Inputs—reference images, audio (via Wav2Vec embeddings), and camera trajectories—are encoded and injected throughout the DiT at each block, with image/text embeddings modulating visual tokens and an audio adapter improving phoneme-alignment.
A key technical contribution is the camera adapter, which maps Plücker-embedded camera parameters into the DiT’s latent space. This enables explicit and contextually smooth camera control, a historically challenging feature for dynamic music video synthesis.
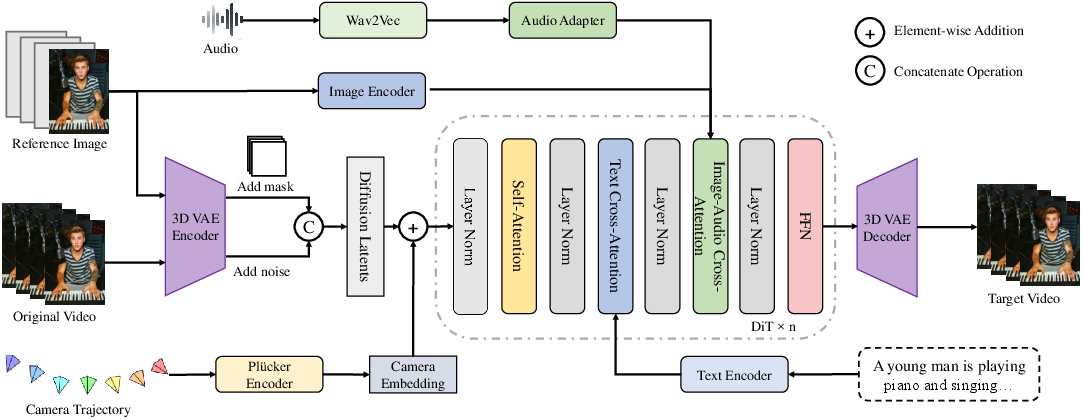
Figure 2: Video generation architecture, combining image, text, music embeddings, and a camera adapter into the DiT backbone to enable precise and synchronized audiovisual generation.
Temporal Consistency: Timestep-Aware Dynamic Window Inference
Long-sequence generation is traditionally hampered by content drift and temporal incoherence. YingVideo-MV introduces a timestep-aware dynamic window range strategy: instead of naive clip-by-clip or uniform sequence denoising, the system adaptively slides and overlaps denoising windows. The method ensures adequate context for each clip, avoids artifacts from improper window sizing, and smoothly transitions between sequence regions.
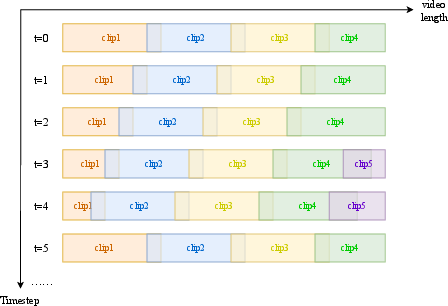
Figure 3: Timestep-aware dynamic window strategy adaptively adjusts overlap and segmentation, ensuring consistency throughout denoising and generation.
This approach, compared to competitors like Sonic and Stable Avatar, achieves better trade-offs between reusing contextual frames and minimizing degenerate self-attention on diverged regions, significantly improving long-range visual smoothness.
Direct Preference Optimization for Human Alignment
To bridge the gap between automated metrics and genuine perceptual preference, YingVideo-MV integrates DPO in training. The model is aligned via pairwise preference data—aggregating Sync-C (lip sync), hand-quality rewards, and overall video reward—so that generated outputs are preferentially optimized along trajectories most valued by human evaluators. The DPO loss steers denoising towards more rewarded solutions while retaining the stability of the underlying diffusion prior.
Experimental Evaluation
Qualitative Assessments: Generated sequences display natural facial motion, robust identity preservation, and articulate synchronization between body movement and camera motion, even in challenging zoom-in/zoom-out scenarios.

Figure 4: Music-driven camera motion visualizations, emphasizing precise coordination between performer and camera across sequences.
Quantitative Results: On benchmarks such as HDTF, CelebV-HQ, and EMTD, YingVideo-MV achieves competitive or superior performance on FID/FVD, CSIM, Sync-C, Sync-D, and camera trajectory (rotation/translation) metrics. Particularly, translation error is minimized, highlighting effective camera trajectory planning and execution. DPO and the dynamic window strategy yield notable metric improvements; for example, FVD drops by more than 6% when using the dynamic window strategy.
User Studies: Participants consistently rate YingVideo-MV videos as top-performing for camera motion smoothness (4.3/5), lip-sync (4.5/5), motion naturalness, and overall video quality (4.4/5), outperforming prior systems. Human evaluations confirm model capacity for generating semantically and cinematically coherent audiovisual content.
Generality and Diversity: The system produces visually rich, artistically varied music videos, demonstrating generalization across camera moves and musical styles.

Figure 5: Additional video generation examples under diverse camera and performance settings, showing generalization and stylistic control.
Limitations and Future Perspectives
Current limitations include inadequate handling of non-human or highly morphologically divergent subjects. The architecture remains tailored for human avatars and faces challenges synthesizing fantastical or non-biological forms. Additionally, modeling complex multi-character interactions is not yet addressed. Future work may involve auxiliary reference-aware modules for improved semantic adaptation, and compositional modeling to support multi-agent interaction with synchronized audiovisual coordination.
Conclusion
YingVideo-MV sets a new reference point for automated music-driven video synthesis by advancing shot-level global planning, multi-modal integration, and temporally consistent long-video generation. Its combination of explicit camera trajectory modeling and human-aligned preference optimization enables seamless, expressive, and artistically controllable music video production. Continued development in expanding subject diversity, interaction modeling, and semantic adaptation could further generalize its impact for AI-driven audiovisual content creation.
Reference: "YingVideo-MV: Music-Driven Multi-Stage Video Generation" (2512.02492)
