DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Abstract: The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DreaMontage, an AI system that can create long, single-shot videos (like the “one-shot” scenes you see in movies) by smoothly connecting different images and short video clips that a user provides. The goal is to turn a set of “key moments” placed at specific times into one continuous, cinematic video with natural motion and transitions.
What questions did the researchers ask?
The researchers wanted to know:
- How can we make one continuous video that follows user instructions while smoothly moving through several images or clips placed at different times?
- How can we avoid awkward jumps, flickering, and weird character movements when shifting between these key moments?
- How can we generate long videos efficiently, without needing huge amounts of computer memory?
How did they do it?
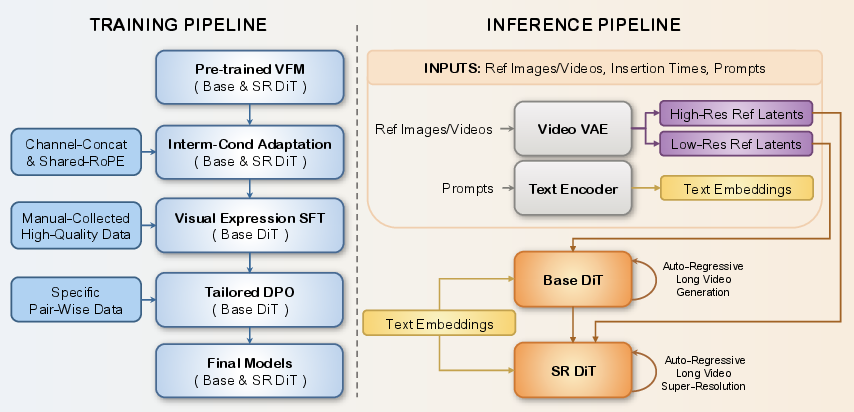
To explain the approach, think of building a movie scene the way you might build a story: you place important “anchor points” (key images or clips) on a timeline, and the AI fills in the parts in between so everything flows naturally. DreaMontage uses a few core ideas and tools:
The building blocks: VAE and DiT
- A VAE (Variational Autoencoder) is like a “zip tool” for videos: it compresses frames into a smaller, hidden form (called “latents”) and later unzips them back to full images.
- A Diffusion Transformer (DiT) is like a careful painter: it starts with noise and gradually improves the image step-by-step, guided by text and visual hints.
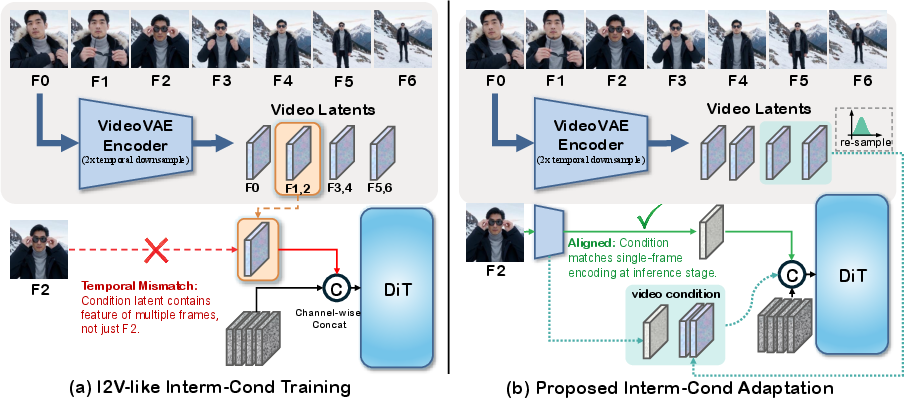
1) Intermediate conditioning (adding anchors anywhere)
- Problem: Most models only use the first and/or last frame as anchors; adding frames in the middle often breaks the flow.
- Solution: DreaMontage lets you insert any image or clip at any time. It “stitches” these anchors into the video by:
- Channel-wise concatenation: It combines the “anchor” latents with the noisy latents so the model knows where to match details.
- Adaptive Tuning: Think of this as targeted practice. The team filtered and trained on videos with strong motion and variety, so the model learns to smoothly connect different anchors.
- Shared-RoPE for super-resolution: When making the video high-resolution, frames sometimes flicker. Shared-RoPE is like giving matching sticky notes to the anchor frame and the frames it guides, so the model knows precisely which parts should align over time.
2) Making motion and style more cinematic
- Visual Expression SFT (Supervised Fine-Tuning): The model “studies” handpicked examples of camera moves (like dolly-in or FPV), visual effects (like lighting and transformations), sports actions, spatial tricks, and tricky transitions. This helps it follow instructions better and make motion look intentional and exciting.
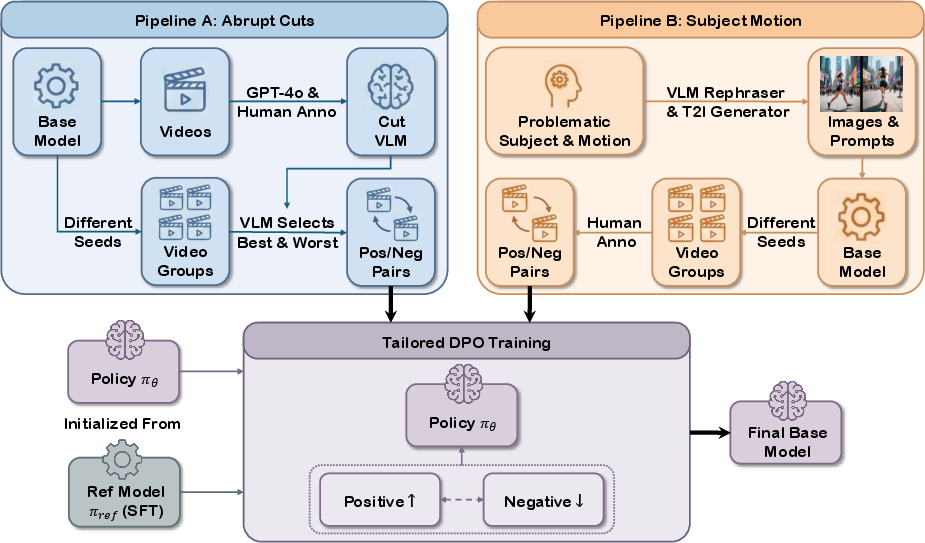
- Tailored DPO (Direct Preference Optimization): Imagine teaching by example pairs: “this is good,” “this is bad.” The team collected pairs of videos showing:
- Smooth transitions vs. abrupt cuts
- Natural movement vs. weird, physically impossible motion
- The model learns to prefer smooth, realistic results without needing a complicated scoring formula.
3) Making long videos efficiently
- Segment-wise Auto-Regressive (SAR) generation: Creating a very long video all at once is heavy. SAR is like writing a long story one chapter at a time while remembering how the last chapter ended. The model generates the video in segments, and each new segment is guided by the end of the previous one. This keeps the whole video consistent while saving memory.
What did they find, and why is it important?
The system can:
- Seamlessly connect multiple image and video anchors placed at exact times to create one continuous, “one-shot” video.
- Reduce flickering, sudden cuts, and odd character motion.
- Efficiently produce longer videos while staying visually consistent.
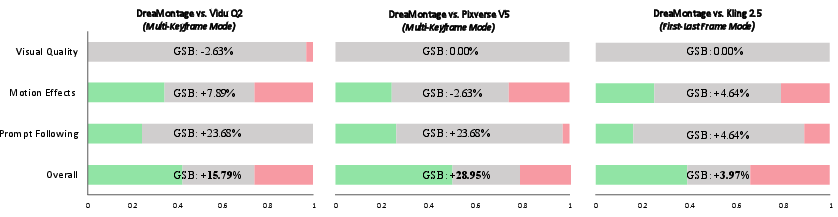
In tests and comparisons:
- Against multi-keyframe models (like Vidu Q2 and Pixverse V5), DreaMontage was preferred more often overall, especially for following complex prompts and keeping the story coherent.
- Against a strong first-last frame model (Kling 2.5), DreaMontage matched visual quality and did better on motion and instruction following.
- Ablation studies (tests of each trick):
- SFT boosted motion quality noticeably.
- DPO reduced abrupt cuts and improved natural movement.
- Shared-RoPE strongly reduced flickering problems in high-resolution outputs.
These results matter because smooth, controlled transitions are the difference between a video that feels like a professional movie and one that feels stitched together.
Why could this matter in real life?
DreaMontage can make creative work faster, cheaper, and more flexible:
- Filmmakers and editors: Turn a storyboard with key frames into a flowing “one-shot” scene. Try bold transitions and camera effects without expensive sets or reshoots.
- YouTubers and content creators: Build long, coherent videos from mixed media—images, short clips, and text descriptions—without harsh cuts.
- Game studios and advertisers: Animate static posters into dynamic scenes, then transition into real footage, keeping brand style intact.
- Education and pre-visualization: Quickly test scene ideas and camera moves to plan shoots or explain visual storytelling concepts.
In short, DreaMontage helps transform a set of scattered visual moments into one continuous, cinematic experience—and does it in a way that’s smooth, expressive, and scalable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, with concrete directions for future work:
- Quantitative evaluation gap: No standardized objective metrics (e.g., FVD, KVD, LPIPS, temporal flicker/consistency metrics, optical-flow stability, identity consistency) are reported; only internal GSB human preferences are used without confidence intervals or statistical significance tests.
- Benchmarking reproducibility: Comparisons rely on internal test sets and commercial baselines; no public benchmark, code, or model weights are released, limiting external verification and apples-to-apples evaluation across resolutions, durations, and prompts.
- Human evaluation protocol details: Number of raters, inter-rater reliability, annotation guidelines, and sample counts per comparison are not provided, making the reported GSB results hard to interpret scientifically.
- Computational efficiency claims: Memory/latency improvements from Segment-wise Auto-Regressive (SAR) are not quantified (e.g., GPU memory footprints, inference time per minute of video, throughput), nor compared to single-pass baselines.
- Error accumulation in SAR: The paper does not assess how auto-regressive segment stitching affects drift, identity preservation, motion continuity, or visual degradation over very long horizons (e.g., >5–10 segments).
- SAR design specification: The temporal operator τ(·), overlap size, fusion strategy, window lengths, and boundary conditions are not specified or ablated; sensitivity to these hyperparameters remains unknown.
- Upper bound on condition count: Scalability with many intermediate conditions (e.g., 10–50 keyframes/clips) is not studied; performance/compute trade-offs as condition density increases are unclear.
- Robustness to condition placement: No analysis of how performance varies with temporal spacing, clustering of conditions, or misaligned timestamps; robustness to slight timing errors in anchors is untested.
- Multi-modal control omissions: Audio is not considered for continuity or beat-synchronous transitions; integrating audio conditions or sound-aware motion remains unexplored.
- VAE causality limitation: The causal, temporally downsampled 3D VAE still introduces imprecise alignment for intermediate frames; alternative encoders (e.g., non-causal, variable stride, conditioned temporal encoders) are not investigated.
- Intermediate-video conditioning approximation: Re-encoding only the first frame and resampling subsequent frames from the latent distribution is an approximation; its bias and failure cases are not measured or compared to more principled segment encoding strategies.
- Shared-RoPE mechanism scope: Shared-RoPE is applied only in SR and only to the first frame of video conditions; its theoretical justification, scaling behavior, and applicability to the base DiT are not analyzed, and ablations beyond GSB are missing.
- Flicker and color shift metrics: The paper claims reduction of SR artifacts but does not report quantitative flicker/color consistency metrics or per-scene breakdowns.
- DPO for diffusion/DiT likelihoods: The paper uses a DPO-style objective without detailing how log-likelihoods are computed for diffusion Transformers on video latents; implementation specifics, estimator variance, and training stability are unclear.
- Preference pair scale and quality: Only ~1k pairs per task are used; distribution coverage, annotator agreement, and generalization of DPO improvements across domains (e.g., animals, vehicles, sports) are not reported.
- Abrupt cut discriminator validity: The trained VLM’s accuracy, calibration, and cross-domain generalization for cut detection are not measured; risk of bias transferring to the generator via DPO is unaddressed.
- Trade-offs from DPO: Potential over-regularization (e.g., oversmoothing transitions, reduced diversity, slower motion) is not assessed; diversity-preservation metrics or qualitative counterexamples are absent.
- Instruction following mechanics: The “rephrased prompts” module used at inference is not described; its impact on controllability and adherence is not isolated via ablation.
- Identity and attribute consistency: No quantitative tracking of subject identity, appearance attributes, or camera intrinsics across long sequences; failure cases with occlusion, extreme scale changes, or lighting shifts are not cataloged.
- Physical plausibility metrics: Claims of improved subject motion rationality lack physics-aware evaluation (e.g., contact consistency, foot sliding metrics, kinematic plausibility scores) or comparisons to motion priors.
- 3D scene geometry: Handling of strong parallax, camera rotations, or multi-plane scenes is not evaluated; no 3D-consistency metrics (e.g., epipolar/geometric coherence) are reported.
- Domain coverage and bias: Data filtering (CLIP similarity, Q-Align aesthetics, optical flow, RTMPose) likely biases toward high-aesthetic, high-motion, human-centric content; generalization to low-motion, low-light, non-human, or technical footage is unknown.
- Data transparency: Details of the 300k filtered corpus and the ~1k SFT dataset (sources, licenses, distribution, annotations) are insufficient for replication; structured action-wise annotations are not released.
- Resolution and aspect ratio support: The model targets 720p/1080p SR, but comparative evaluations do not control for resolution/aspect ratio; robustness to varied ARs, frame rates, and compression artifacts is not tested.
- Maximum duration support: Long-form claims span up to 60 seconds in tests; limits (e.g., minutes-scale generation) and degradation behavior are not characterized.
- Mixed-condition edge cases: Conflicts between image and video conditions (e.g., contradictory styles/physics) are not systematically studied; mechanisms to prioritize or reconcile competing conditions are unspecified.
- Failure mode taxonomy: The paper lacks a catalog of typical failures (e.g., hallucinated cuts, temporal jitter, identity drift, motion implausibility) and their frequencies, hindering focused future mitigation.
- Safety and misuse: No discussion of content safety, deepfake risks, identity cloning, or brand/IP misuse; absence of guardrails or detection mechanisms for ethically sensitive scenarios.
- Environmental footprint: Training/inference energy costs, hardware requirements, and carbon impact are unreported, limiting assessment of sustainability for long-form generation.
- Licensing and deployment constraints: Use of Seedance 1.0 and other internal components raises questions on licensing, model availability, and reproducibility for the community.
These gaps suggest targeted follow-ups: publish reproducible benchmarks and metrics suites; quantify SAR compute and stability; formalize and ablate conditioning mechanisms (VAE, Shared-RoPE, DPO likelihoods); measure identity/physics consistency; expand domain coverage; and document safety, data, and evaluation protocols.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods and findings, with sector links, potential tools/workflows, and feasibility notes.
- AI-assisted one-shot trailer and montage creation (media/entertainment, advertising)
- What: Turn mixed assets (keyframes, concept art, short clips) into cohesive one-shot trailers and social ads with seamless transitions and controlled temporal anchors.
- Tools/Workflows: “Storyboard-to-OneShot” timeline editor with arbitrary frame anchors; NLE plugins (Premiere/Resolve) that pass selected frames/clips into DreaMontage; auto prompt rephraser; export at 720p/1080p via SR model.
- Assumptions/Dependencies: Access to GPU inference; rights to source assets; robust text prompts; SR model configured with Shared-RoPE; acceptable latencies for creative iteration.
- Pre-visualization (previz) for film, TV, and virtual production (media/entertainment)
- What: Rapidly simulate camera paths, blocking, and stylistic transitions by placing key visual anchors along the timeline; reduce on-set tests and set-building costs.
- Tools/Workflows: Timeline-conditioned previz tool; camera-move presets (FPV, dolly, crane) curated in SFT; SAR for long shots without memory overflow.
- Assumptions/Dependencies: Domain prompts and reference frames; integration with production asset libraries; supervisors validate physical plausibility; compute budget.
- Hybrid-condition cutscene generation for games (software/gaming)
- What: Generate narrative cutscenes from a mix of posters, character sheets, and gameplay snippets while maintaining style and character identity.
- Tools/Workflows: Engine-side API to call DreaMontage for in-between generation; “Character Identity Lock” presets and DPO motion rationalizer.
- Assumptions/Dependencies: Legal use of assets; engine integration (Unity/Unreal) via Python/REST; quality control for motion; storage for latent segments.
- Marketing content automation from static brand assets (advertising/marketing)
- What: Animate product posters into dynamic sequences that smoothly transition to usage clips and UGC snippets.
- Tools/Workflows: Brand stylebook-conditioned prompts; batch pipeline to generate variants; QC using the VLM-based cut-severity discriminator.
- Assumptions/Dependencies: Brand safety review; governance for claims; watermarking/provenance; consistent color management in SR.
- Social media montage and memory films for consumers (daily life/creator economy)
- What: Turn photo albums and short clips into coherent one-shot vacation/wedding highlight reels with user-placed anchors (e.g., “first kiss”, “venue”, “dance”).
- Tools/Workflows: Mobile/desktop app with timeline anchoring; lightweight SAR for segment extension; default transitions tuned via SFT/DPO.
- Assumptions/Dependencies: Cloud inference or high-end local GPUs; content ownership; simple UI for temporal control; safe default prompts.
- Long-form vlog and documentary-style auto-extension (media/creator economy)
- What: Autoregressively extend videos with consistent style and subjects using SAR, maintaining continuity without drift.
- Tools/Workflows: “Keep-extending” toggle that conditions on tail latents; seed/identity persistence; continuity scoring.
- Assumptions/Dependencies: Storage for long latents; runtime management to avoid style drift; periodic human checks for factuality when used documentary-like.
- Video continuity enhancement and cut smoothing for stitched content (post-production/software)
- What: Improve temporal coherence when concatenating clips (e.g., highlight reels), removing abrupt cuts and flicker via Tailored DPO and SR Shared-RoPE.
- Tools/Workflows: “Continuity Fixer” pass on rough edits; VLM cut-score gating; SR with sequence-wise conditioning to reduce flicker/color drift.
- Assumptions/Dependencies: Access to intermediate renders; prompt customization for transitional semantics; compute overhead for SR passes.
- Synthetic long-sequence dataset generation for CV research (academia)
- What: Produce controllable, long, coherent video sequences to study temporal consistency, motion rationality, and transition quality.
- Tools/Workflows: Arbitrary-condition protocol to synthesize benchmarks; export ground-truth anchors; use VLM cut-severity scores for labels.
- Assumptions/Dependencies: Disclosure that data are synthetic; domain-specific style prompts; calibration of evaluation metrics beyond GSB.
- HCI research on timeline-guided generative interfaces (academia/HCI)
- What: Study user interaction patterns with arbitrary-frame conditioning, prompt rephrasing, and temporal anchoring to improve creative tooling.
- Tools/Workflows: Controlled experiments with timeline UIs; logging of anchor placement and revisions; usability measures tied to output coherence.
- Assumptions/Dependencies: Access to prototype UI; participant studies; IRB compliance for user experiments.
- Content QA/QC services using learned discriminators (media, platforms, moderation)
- What: Repurpose the trained VLM abrupt-cut detector for automated quality checks of generated or edited content; flag hard cuts/flicker before publish.
- Tools/Workflows: Batch scoring service; thresholds for platform acceptance; dashboards for production teams.
- Assumptions/Dependencies: Model generalization to diverse content; false-positive management; integration with existing asset pipelines.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or systems integration before practicality.
- Real-time, in-engine generative cutscenes and interactive storytelling (gaming/software)
- What: On-the-fly one-shot scene synthesis responding to player actions with arbitrary anchors injected at runtime.
- Tools/Workflows: Low-latency inference on GPUs; streaming SR; tight engine integration; caching of latents for SAR stepping.
- Assumptions/Dependencies: Significant optimization for latency; robust identity/style locking; safety rails to avoid uncanny motion; hardware acceleration.
- Feature-length “one-shot” films and live broadcast augmentation (media/broadcast)
- What: Full-length coherent generation with dynamic anchors (crowd cues, director inputs) and on-air adjustments.
- Tools/Workflows: Operator consoles for anchor insertion; multi-GPU distributed SAR; live QC overlays (cut/motion scores).
- Assumptions/Dependencies: High compute scale; rigorous editorial oversight; watermarking/provenance; compliance with broadcast standards.
- Domain-specialized educational content generation with factual control (education)
- What: Generate long, coherent lecture demos or science visualizations with anchored concept frames and physically plausible motion.
- Tools/Workflows: Domain prompt libraries; fact-check modules; audio narration synchronization; teacher-in-the-loop editing.
- Assumptions/Dependencies: Strong factual grounding; model fine-tuning per subject; accessibility compliance; integration with LMS.
- Robotics and autonomous systems simulation with long, coherent visual sequences (robotics)
- What: Create controllable visual scenarios (e.g., navigation, manipulation) with temporal anchors for training and evaluation.
- Tools/Workflows: Scenario composer mapping task events to anchors; interfaces to reinforcement learning pipelines; labels for state transitions.
- Assumptions/Dependencies: Domain realism and physics fidelity beyond current entertainment-focused training; alignment with sensor models; sim-to-real transfer validation.
- Digital twin storytelling and operations visualization (industrial/enterprise)
- What: Long-form narrative overlays for digital twins (facility tours, maintenance procedures) guided by anchors (stations, events).
- Tools/Workflows: Integration with twin data; anchor auto-generation from logs; SAR for procedural steps; multilingual variants.
- Assumptions/Dependencies: Security/governance for enterprise data; domain calibration; multi-lingual text/image conditions; audit trails.
- Automated multi-market ad localization with style and identity preservation (advertising/marketing, finance/retail)
- What: Scale campaigns by generating localized one-shot ads from template anchors (product shots, local footage), preserving brand identity.
- Tools/Workflows: Localization prompts; brand safety and legal review; batch SAR pipelines; A/B testing hooks.
- Assumptions/Dependencies: Jurisdiction-specific compliance; cultural adaptation datasets; scalable compute; brand approvals.
- Provenance, watermarking, and policy tooling for generative video (policy, platforms, regulators)
- What: Standardized provenance tags embedded at segment boundaries; platform-side detectors for generated transitions and motion plausibility.
- Tools/Workflows: Policy SDK integrating cut/motion scoring; cryptographic watermarks; disclosure badges for generative content.
- Assumptions/Dependencies: Industry standards adoption; regulator-platform collaboration; robustness against removal attacks; user privacy considerations.
- Multimodal orchestration: synchronized audio, dialogue, and camera control (media/software)
- What: Joint generation of voiceover, sound effects, and camera trajectories aligned to anchored visual beats.
- Tools/Workflows: Multimodal timeline; audio TTS/music models aligned to anchors; camera-path planners; unified consistency scoring.
- Assumptions/Dependencies: Cross-model alignment; beat-level temporal accuracy; IP licensing for audio; expanded DPO for audio-visual coherence.
- Edge and mobile deployment for consumer apps (daily life/creator economy)
- What: On-device montage generation with shorter segments and efficient SR for casual creation.
- Tools/Workflows: Distilled models; quantization/pruning; progressive SAR rendering; offline packs for style domains.
- Assumptions/Dependencies: Significant model compression; battery and thermal constraints; simplified UI; limited resolution/length.
- Academic benchmarks and metrics for temporal coherence and narrative quality (academia)
- What: Standardized long-video benchmarks with anchor metadata; quantitative metrics beyond GSB for motion rationality and cut smoothness.
- Tools/Workflows: Public datasets with condition timelines; open-source evaluators (cut-severity, motion plausibility); challenge tracks.
- Assumptions/Dependencies: Community consensus on metrics; licensing for shared assets; reproducible pipelines; cross-model comparability.
Glossary
- Adaptive Tuning: A lightweight fine-tuning strategy on filtered base data to enable robust arbitrary-frame control. "By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities."
- Channel-wise concatenation: A conditioning method that concatenates condition latents with noise latents along the channel dimension. "we follow the channel-wise concatenation mode used in the typical image-to-video task"
- CLIP: A contrastive vision-LLM used here to compute feature similarity between frames for data filtering. "The cosine similarity is calcuated between the CLIP~\cite{radford2021learning} features of the first and last frame for each video"
- Cross-attention: An attention mechanism that injects text features into the video diffusion model. "which is subsequently integrated into the DiT backbone via cross-attention."
- Differentiable Prompt Optimization (DPO): A preference-based optimization method guiding the generator using contrastive pairs to reduce artifacts. "we construct specific pairwise datasets and apply Differentiable Prompt Optimization (DPO)~\cite{rafailov2023direct,xiao2024cal,wallace2024diffusion}."
- Diffusion Transformer (DiT): A transformer-based backbone for diffusion models used for video generation. "a Variational Autoencoder (VAE)~\cite{kingma2013auto} and a Diffusion Transformer (DiT)~\cite{peebles2023scalable}."
- Dual-stream and single-stream DiT blocks: Architectural blocks that inject semantic tokens via parallel or unified streams in a DiT. "which are then injected through a combination of dual-stream and single-stream DiT blocks."
- Good/Same/Bad (GSB) protocol: A human evaluation scheme comparing two videos pairwise across several dimensions. "we employ the Good/Same/Bad (GSB) protocol for human evaluation."
- Image-to-video (I2V): The task of generating videos conditioned on images (and text) with controllable motion. "In the I2V task, different foundation models adopt distinct mechanisms for injecting conditioning."
- In-context control: Conditioning approach that injects image semantics as context tokens for generation. "Hunyuan Video further introduces in-context control for image conditions."
- Interm-Cond (Intermediate conditioning): The setting where frames or clips are used as intermediate conditions at arbitrary timestamps. "In case of Interm-Cond, we frequently observe flickering and cross-frame color shifts."
- Latent distribution: The probability distribution over latent variables from which latent frames can be re-sampled. "the subsequent frames are re-sampled from the latent distribution."
- Latent space: The compact representation space produced by the VAE where videos are modeled and manipulated. "compressing images and videos into a compact latent space."
- Optical flow predictor: A model estimating motion between frames, used here to quantify motion strength for data filtering. "a 2D optical flow predictor is applied to estimate the videoâs motion strength."
- Q-Align: A visual scoring model used to assess aesthetic quality for data curation. "We use Q-Align~\cite{wu2023q} to assess aesthetic scores"
- Rotary Position Embedding (RoPE): A positional encoding method enabling relative position awareness in transformers. "the value of Rotary Position Embedding (RoPE)~\cite{su2024roformer} being set the same as those at the corresponding position."
- RTMPose: A human pose estimation model used for filtering high-quality, human-centric videos. "Additionally, the RTMPose~\cite{jiang2023rtmpose} is utilized to filter out high-quality human-centric videos with clear pose structure."
- Segment-wise Auto-Regressive (SAR): A long-video generation strategy that produces segments sequentially with boundary conditioning. "we design a Segment-wise Auto-Regressive (SAR) inference strategy"
- Sequence-wise conditioning: Conditioning by appending condition latents to the token sequence (not just channels) for the SR model. "an extra sequence-wise conditioning is applied."
- Shared-RoPE: A super-resolution strategy that shares RoPE values between condition tokens and their guided positions to reduce flicker. "we propose Shared-RoPE: for each reference image, besides the channel-wise conditioning, an extra sequence-wise conditioning is applied."
- Super-resolution (SR) DiT: The DiT model that upsamples low-resolution video latents to higher resolution. "a super-resolution (SR) DiT model enhances the primary latents to the desired higher resolution (720p/1080p)."
- Supervised Fine-Tuning (SFT): Fine-tuning on curated, labeled data to improve instruction following and motion expressiveness. "We then leverage Supervised Fine-Tuning (SFT) for visual expression."
- Temporal down-sampling: Reducing the temporal resolution (frame rate) in encoding, often for efficiency or causality. "a causal mechanism with temporal down-sampling."
- Temporal operator τ(·): An operator extracting boundary latents (e.g., tail latents) from previous segments for conditioning. "extracted via a temporal operator "
- Timestep-based conditioning control: A method assigning different diffusion timesteps to noise and condition tokens to distinguish roles. "employ timestep-based conditioning control, where the noise tokens and conditioning tokens are assigned different timesteps"
- Variational Autoencoder (VAE): A generative model that encodes videos into a latent space and decodes them back to pixels. "a Variational Autoencoder (VAE)~\cite{kingma2013auto}"
- VideoVAE: A 3D VAE specialized for videos, used to encode/decode video latents. "a 3D Video Variational Autoencoder (VideoVAE) compressing images and videos into a compact latent space."
- Vision-LLM (VLM): A model jointly processing images/videos and text; here used for scene detection and cut quality. "a VLM-based scene detection model is adopted to exclude multi-shot videos."
Collections
Sign up for free to add this paper to one or more collections.

