CutClaw: Agentic Hours-Long Video Editing via Music Synchronization
Abstract: Editing the video content with audio alignment forms a digital human-made art in current social media. However, the time-consuming and repetitive nature of manual video editing has long been a challenge for filmmakers and professional content creators alike. In this paper, we introduce CutClaw, an autonomous multi-agent framework designed to edit hours-long raw footage into meaningful short videos that leverages the capabilities of multiple Multimodal LLMs~(MLLMs) as an agent system. It produces videos with synchronized music, followed by instructions, and a visually appealing appearance. In detail, our approach begins by employing a hierarchical multimodal decomposition that captures both fine-grained details and global structures across visual and audio footage. Then, to ensure narrative consistency, a Playwriter Agent orchestrates the whole storytelling flow and structures the long-term narrative, anchoring visual scenes to musical shifts. Finally, to construct a short edited video, Editor and Reviewer Agents collaboratively optimize the final cut via selecting fine-grained visual content based on rigorous aesthetic and semantic criteria. We conduct detailed experiments to demonstrate that CutClaw significantly outperforms state-of-the-art baselines in generating high-quality, rhythm-aligned videos. The code is available at: https://github.com/GVCLab/CutClaw.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
CutClaw: A simple explanation
What this paper is about
The paper introduces CutClaw, an AI system that takes hours of raw video (like a full movie or long vlog) and turns it into a short, great-looking video that:
- follows the user’s instructions (for example, “focus on the main hero” or “tell a love story”),
- stays in perfect rhythm with a chosen music track,
- and looks polished and professional.
Think of CutClaw as a smart team of helpers that edit a long, messy video into a short, exciting clip that fits the beat of the music.
What questions the researchers wanted to answer
In simple terms, they wanted to solve three big problems:
- How can an AI handle very long videos without forgetting details?
- How can it tell a clear story that follows the user’s instructions, while still staying true to what’s actually in the footage?
- How can it line up the visuals with the music exactly, so cuts and actions hit on the beat?
How the system works (in everyday language)
The system works like a film crew with three roles, moving from big-picture planning to fine details.
First, it prepares the raw materials:
- Breaking the video into pieces: It detects “shots” (parts between camera cuts) and groups similar shots into “scenes.” It also labels what’s happening: who’s there, where they are, what the mood is.
- Understanding the music: It finds the song’s important moments—beats, changes in melody, and sections like verse and chorus. Imagine placing flagpoles on the music timeline where the energy shifts or the rhythm hits.
Then, the “crew” goes to work:
- Playwriter (the planner): This agent plans the story. It matches scenes from the video to sections of the music, making sure no scene is used twice and that the total video length exactly fits the music. It writes a “shot plan” for each part of the music, saying:
- how long the clip should be (based on the music),
- which scene to pull from,
- and what kind of moment to show (for example, “close-up on the main character looking worried”).
- Editor (the cutter): This agent looks inside the chosen scene and finds the precise start and end times for each clip so it:
- looks good (no blurry or awkward frames),
- actually shows the right person,
- and matches the exact duration needed to hit the beat.
- If it can’t find a good match, it smartly looks at nearby scenes with similar content.
- Reviewer (the quality checker): This agent double-checks every clip to make sure:
- the right character is clearly visible,
- the timing is perfect and clips don’t overlap,
- the quality is high (no dark, shaky, or broken shots).
- If something fails, it sends the Editor back to try another option.
A helpful analogy: Imagine you’re making a highlight reel for a song. The Playwriter decides the story flow and where each scene should go based on the music’s sections. The Editor picks the exact moments that look best and fit the beat. The Reviewer ensures everything matches the plan and looks professional. Together, they turn a giant puzzle into a clean, rhythmic mini-movie.
What they found and why it matters
The team tested CutClaw on long movies and vlogs paired with different music styles. They compared it to other popular automatic editing methods. CutClaw did best in three key areas:
- Visual quality: The edited videos looked more professional and pleasing.
- Instruction following: It stuck to what the user asked (like focusing on a specific character or telling a certain story).
- Audio–visual harmony: The cuts matched the music’s rhythm and structure much more precisely.
In a user study, people preferred CutClaw’s results about half the time across all categories—roughly twice as often as the next-best method. This shows that the system doesn’t just do well on paper; viewers actually like the results.
Why this matters: Good editing is hard and time-consuming. An AI that can understand both the story and the music—and put them together beautifully—can save creators a lot of work while raising the quality of short videos for social media, film previews, and more.
What this could lead to next
- Practical impact: CutClaw could help YouTubers, filmmakers, and marketers quickly create catchy, beat-perfect edits from hours of footage.
- Future upgrades: The authors note two main improvements they want:
- Adding special effects or stylish transitions automatically (for extra “wow”).
- Making the system faster, since processing hours of video can take time.
In short, CutClaw shows how AI “agents” can work together like a real editing team—planning, cutting, and checking—to turn long, messy footage into short, music-synced videos that look and feel human-edited.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Dataset scale and diversity: The benchmark comprises only 10 source pairs (~24 hours) and two instruction types (character-centric, narrative-centric). It remains unknown how the system performs on broader domains (sports, documentaries, live events, short-form UGC, multi-camera concerts), different languages, and various cinematographic styles.
- Benchmark availability and licensing: It is unclear whether the curated long-form footage and music tracks can be released (copyright), which limits reproducibility and external validation.
- Generalization to complex musical structures: The audio parser’s reliability on tracks with variable tempo, rubato, polyrhythms, swing, irregular meters (5/4, 7/8), weak/transient beat salience, anacrusis, or live recordings is not evaluated.
- Audio-visual affect alignment beyond beats: The method emphasizes beat/keypoint sync but does not quantify or evaluate affective congruence (mood, tension, energy) between music and visuals. How to measure and optimize emotion/energy alignment remains open.
- Precision under low frame-rate analysis: Preprocessing downsampling to 2 FPS raises questions about whether fine-grained cut timing can be accurately located and rendered at sub-frame precision. The paper does not clarify if final rendering uses original frame-rate timestamps nor report timing error introduced by downsampling.
- Reliability of music structure segmentation: Musical unit detection relies on an MLLM and hand-tuned weights (). There is no evaluation of segmentation accuracy against music-structure annotations nor sensitivity analysis to these weights.
- Objective weights and sensitivity: The joint objective uses /weight hyperparameters (, thresholds , neighborhood size ) without reporting how they were set, tuned, or how sensitive performance is to them.
- Lack of formal optimality or convergence guarantees: The hierarchical, heuristic search has no analysis of approximation quality, complexity, or convergence; the number of backtracks and failure cases per shot plan is unreported.
- Disjoint scene allocation constraint: Forbidding reuse of scenes may hinder good storytelling (e.g., call-backs, motif reuse, B-roll cutaways). The trade-off between non-overlap and narrative quality is not explored.
- Missing film grammar constraints: The Reviewer does not check continuity rules (180-degree rule, match-on-action, eye-line match), pacing logic, or transition smoothness; only hard cuts are considered. How to model and evaluate cinematic grammar remains open.
- Transitions and effects: No support for cross-dissolves, L/J-cuts (audio-lead/lag), slow motion, speed ramps, color grading, captions, or on-beat effects that are central to professional edits. Integration points and quality metrics for these are not specified.
- Audio mixing and dialog handling: There is no treatment of mixing levels, ducking, or balancing original audio with background music—especially critical for dialog-heavy footage. How to jointly optimize picture cuts and audio mixing is unaddressed.
- Identity tracking under weak/no speech: “Identity injection” relies on dialogue-derived names; the approach for VLOGs or multi-unknown subjects without reliable ASR or subtitles is unclear. The system does not describe face/voice ID or re-ID modules or evaluate identity robustness.
- Reviewer reliability and failure modes: Protagonist presence and aesthetics are judged by MLLMs/VLMs, which can hallucinate. There is no calibration or inter-model agreement study, nor a breakdown of false acceptance/rejection rates.
- AV harmony metric validity: AV sync is scored via downbeats/pitch onsets with a fixed threshold (e.g., 0.1 s). There is no psychophysical validation, user-level just noticeable difference assessment, or comparison to human editor ground truth cut points.
- Human study methodology details: The expertise of raters, randomization, statistical significance tests, and inter-rater reliability are not reported, leaving uncertainty about robustness of subjective conclusions.
- Baseline coverage and fairness: There is no comparison to music-synchronized editing systems or commercial rhythm-aware template editors beyond general frameworks (UVCOM, Time-R1, NarratoAI). Adaptations for long-form baselines may be suboptimal; stronger musical baselines are needed.
- Robustness to shot-detection errors: Performance sensitivity to PySceneDetect failure cases (fast cuts, whip pans, heavy motion blur, non-cut transitions) is not reported; no fallback strategy if shot boundaries are misdetected.
- Long-duration scalability: While “hours-long” is claimed, evaluation caps at ~3 hours. Memory/latency scaling, throughput, and cost (API calls across multiple MLLMs) under much longer inputs are not quantified.
- Latency and resource profiling: The pipeline’s end-to-end runtime, GPU/CPU usage, model invocation counts, and cost per minute of footage are not provided; no profiling of time spent per agent/module.
- Domain and language robustness: There is no evaluation on non-English speech, code-switching, or noisy ASR; nor on culturally diverse content with different pacing conventions and editing norms.
- Interactive/iterative editing: The system is fully automated; support for human-in-the-loop revision, constraint editing, or interactive re-planning (e.g., “tighten the first chorus,” “more B-roll of cityscapes”) is not explored.
- Learning-based planning vs. rule-based: The framework does not learn the planning weights or editing policies from data. Whether RL/imitation learning from professional timelines could improve Playwriter/Editor decisions is open.
- Error analysis: The paper lacks a categorized breakdown of common failure modes (mis-synced beats, identity drift, abrupt pacing, narrative incoherence) and their prevalence.
- Multi-agent orchestration analytics: There is no quantitative study of how often the Reviewer rejects clips, how many backtracking iterations occur, or how planning/regeneration cascades impact latency and quality.
- Handling sparse/weak material: When allocated scenes lack enough on-spec content of duration , the fallback “semantic neighborhood” expansion may conflict with music anchors or narrative constraints. The frequency and impact of such conflicts are not analyzed.
- Cut granularity vs. musical phrasing: Shot durations are constrained to segment durations. Many professional edits cut within bars or use syncopation. How to support flexible, learned cut timing that respects phrasing but allows off-beat cuts is unknown.
- Reproducibility with proprietary models: The system depends on proprietary APIs (Gemini3-Pro, MiniMax-M2.1) and large Qwen models; replicability with open models, model version drift, and sensitivity to prompt phrasing are not addressed.
- Safety, bias, and legal concerns: Bias in protagonist detection (gender/skin tone), handling of explicit content, and legal issues around editing copyrighted films/music are unaddressed; no filtering or governance mechanisms are described.
- Ground-truth references: There is no comparison to professional editor timelines for the same source material, which limits claims about human-likeness beyond user preference votes.
- Uncertainty estimation and confidence: The agents do not produce confidence scores or uncertainty estimates to guide re-planning or human review; how to expose and leverage uncertainty remains open.
- Extensibility to non-musical guidance: The framework is tailored to music-driven edits; generalization to sound-design-driven edits (foley, ambient, SFX) or to multi-track music (stems) is unexplored.
- Cross-modal representation learning: The system relies on captioning plus heuristic alignment rather than learned joint embeddings of music and video for retrieval; whether learned AV embeddings would improve alignment is an open question.
- Comprehensive ablations: Only Editor/Reviewer/Audio-context ablations are reported. Ablations on Playwriter strategies, scene allocation policies, neighborhood expansion, and music keypoint types/weights are missing.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, based on the paper’s methods (hierarchical multimodal deconstruction, Playwriter–Editor–Reviewer agents, beat/keypoint audio parsing) and the released code.
- Media/Entertainment — Auto-cut social videos from long footage
- Use case: Turn hours of film dailies, VLOGs, travel videos, or behind-the-scenes footage into 20–60s music-synchronized shorts (e.g., teasers, reels, TikTok/Shorts).
- Tools/products/workflows: “CutClaw Assistant” plugin for Adobe Premiere Pro/DaVinci Resolve; a SaaS/API that ingests long clips + a music track + prompt and outputs a ready-to-post short with beat-aligned cuts; exports EDL/XML for finishing in NLEs.
- Assumptions/dependencies: Music licensing; adequate compute (GPU) for MLLMs/VLMs; reasonable shot detection/ASR quality on the source domain; best performance with structured, beat-driven music.
- Advertising/Marketing — Rapid promo generation at scale
- Use case: Produce multiple music-synced ad variants (15/30/60s) from campaign footage that follow brand prompts (e.g., “focus on product close-ups,” “show smiling customers”).
- Tools/products/workflows: Batch-processing service integrated with MAM/brand asset libraries; A/B testing variants with different music sections; automatic EDLs for color/VFX finishing.
- Assumptions/dependencies: Robust identity/brand logo detection; brand-safety checks via the Reviewer; music clearance; consistent style guidance in prompts.
- Sports/Esports — Highlight reels from full matches
- Use case: Extract hype reels synchronized to music from hours-long match recordings (player-focused, key moments), for social channels or broadcast interstitials.
- Tools/products/workflows: Post-match highlight generator; editor-in-the-loop UI to pin player identities; AVID/Premiere XML export.
- Assumptions/dependencies: Domain adaptation for sports visuals; optional event detectors improve precision; latency acceptable for post-game, not live.
- Newsrooms/Broadcast — B-roll montages and segment packaging
- Use case: Build quick music-synced B-roll montages that follow editorial constraints (e.g., focus on specific locations/subjects) from newsroom archives.
- Tools/products/workflows: Integration with newsroom MAM; scripted prompts per segment; Reviewer gate enforces identity/topic focus and duration fidelity.
- Assumptions/dependencies: Strict editorial standards require human review; privacy/compliance checks for bystanders; music rights for broadcast.
- Wedding/Event Videography — Client-ready highlights
- Use case: Convert multi-hour raw recordings into emotive, music-aligned highlight films (e.g., “focus on couple + family reactions”).
- Tools/products/workflows: Studio pipeline that auto-generates cuts for client selection; adjustments via instruction prompts; delivery-ready with simple transitions.
- Assumptions/dependencies: Face/identity detection robustness across lighting and occlusions; licensed music or client-provided tracks.
- Music Industry — Teasers/visualizers aligned to song structure
- Use case: Quickly produce lyric-free visual teasers or social cuts structured by verse/chorus and major downbeats for new releases.
- Tools/products/workflows: Label-driven batch creation; “structure-aware” cutplans; integration with label asset libraries.
- Assumptions/dependencies: Works best with clear section structure (e.g., pop/rock/OST); creative sign-off still needed.
- Corporate Communications — Internal/external sizzle reels
- Use case: Auto-create music-synced highlight reels from town halls, product launches, or trade show footage focusing on executives/products.
- Tools/products/workflows: Private-cloud service with audit logs; identity constraints (e.g., “show CEO, product demo shots”); export for finishing.
- Assumptions/dependencies: On-premise or secure-cloud deployment for sensitive footage; governance for automated edits.
- Education — Course promos and lecture intros/outros
- Use case: Generate short music-synced promo cuts from lecture capture, lab demos, or campus events.
- Tools/products/workflows: LMS integration; shot detection + identity prompts (e.g., instructor presence); auto-captioning for accessibility.
- Assumptions/dependencies: Mixed classroom audio may reduce ASR quality; ensure accessibility compliance (captions/alt-text).
- Archive/MAM — Structured scene/identity indexing
- Use case: Use the video deconstruction outputs (shots/scenes, character-aware summaries) to enrich metadata for faster retrieval and downstream editing.
- Tools/products/workflows: Metadata export (JSON/CSV) into MAM; search by scene semantics/identities; prebuilt “candidate pools” for editors.
- Assumptions/dependencies: Accuracy of scene aggregation and identity grounding; scalable storage for metadata.
- Research/Academia — Benchmarking and dataset bootstrapping
- Use case: Generate beat-aligned video–audio pairs and agent traces to study multimodal alignment, long-context planning, and human-like pacing.
- Tools/products/workflows: Reproducible pipelines; public code to replicate evaluations; use as a baseline for VTG/highlight detection research.
- Assumptions/dependencies: Licensing for source footage/audio; domain coverage to avoid bias; compute availability.
- Compliance/Brand Safety — Automated validity gate
- Use case: Leverage the Reviewer’s multi-criteria checks to enforce identity focus, non-overlap, duration fidelity, and minimum quality thresholds before publishing.
- Tools/products/workflows: Pre-publish gate integrated with CMS; logs of pass/fail with reasons; configurable thresholds per channel.
- Assumptions/dependencies: Reviewer thresholds tuned to content type; human escalation for edge cases.
Long-Term Applications
These applications require further research, scaling, latency improvements, or productization beyond the current system’s capabilities and limitations (noted in the paper: high inference latency; lack of advanced VFX; opportunities to integrate generative models).
- Live/Real-Time Editing — In-event highlights for sports, concerts
- Use case: Generate beat-synced highlights as events unfold (near-real-time social clips, stadium boards).
- Tools/products/workflows: Low-latency audio keypoint detection; streaming shot detection; incremental agent plans; edge compute.
- Assumptions/dependencies: Significant latency reduction; robust live audio separation; multi-cam synchronization; reliable low-compute MLLMs.
- Fully Autonomous Post-Production — Beyond cutting (VFX, transitions, color)
- Use case: Deliver nearly finished cuts with beat-aligned transitions, stylized overlays, and color passes.
- Tools/products/workflows: Integration with generative video (e.g., Sora, Kling) for B-roll/FX; learned transition libraries triggered on downbeats; AI color styles.
- Assumptions/dependencies: High-quality generative models, style controllability, and safety; editorial approval loops.
- Personalized Co-Creative Editors — Interactive agent collaboration
- Use case: Editors “steer” the Playwriter via high-level notes; system regenerates cut plans and alternatives on the fly.
- Tools/products/workflows: UX for rapid prompt iteration; explainable agent traces; suggestion ranking with human-in-the-loop.
- Assumptions/dependencies: Efficient re-planning; better controllability and determinism; versioning of agent outputs.
- Multimodal Anchoring Beyond Music — Speech- or event-driven summaries
- Use case: Apply the same hierarchical agent workflow with non-musical anchors (e.g., lecture speech beats, game event whistles, sensor cues).
- Tools/products/workflows: Replace beat detectors with speech turn/keyword detectors, event detectors; hybrid anchors (music + speech).
- Assumptions/dependencies: Strong ASR and diarization in noisy domains; event detection pipelines; evaluation metrics adjustment.
- Healthcare — Procedure/therapy video summarization
- Use case: Summarize surgical/endoscopy or therapy sessions aligned to procedural stages or device audio cues (not music).
- Tools/products/workflows: Procedural phase detectors as “anchors”; strict privacy filters; de-identification checks in Reviewer.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); clinician-in-the-loop validation; domain-specific models and ontologies.
- VR/AR and 360° Content Editing — Spatial audio-visual alignment
- Use case: Produce music-synced edits for immersive media considering gaze, spatial cues, and head-locked audio events.
- Tools/products/workflows: 360° shot boundary detection; spatial audio keypoint parsing; spherical aesthetic scoring.
- Assumptions/dependencies: New feature extractors for panoramic video; user comfort constraints; specialized viewers.
- Scaled Creative Optimization — Mass-variant ad generation
- Use case: Produce thousands of targeted variants with different music sections, pacing, and focal identities for micro-audiences.
- Tools/products/workflows: Programmatic generation with campaign metadata; automatic performance feedback loops; brand rules as constraints.
- Assumptions/dependencies: Data pipelines for performance signals; robust guardrails; scalable compute and storage.
- Policy/Governance — Standards for AI-edited content transparency
- Use case: Establish disclosure formats, audit trails, and provenance for automated edits in advertising and news.
- Tools/products/workflows: Cryptographic provenance (e.g., C2PA); standardized Reviewer logs; compliance dashboards.
- Assumptions/dependencies: Industry consensus; alignment with legal frameworks; interoperable metadata standards.
- Intelligent Media Search/Recommendation — Segment-level retrieval and pacing-aware ranking
- Use case: Use scene/character/music-structure metadata to power fine-grained search and recommend clips with desired pacing/emotion.
- Tools/products/workflows: Indexes built from CutClaw’s deconstruction; rhythm/emotion tags; API for creative teams and platforms.
- Assumptions/dependencies: High-quality embeddings; cross-domain generalization; privacy-aware indexing.
- Robotics/On-Device Cameras — Autonomous capture-to-edit
- Use case: Drones/action cams that auto-produce music-synced highlight reels from multi-hour recordings.
- Tools/products/workflows: On-device lightweight agents; offline batch refinement; sensor fusion for “event anchors.”
- Assumptions/dependencies: Efficient models for edge devices; stabilization and quality checks in the Reviewer; safe flight/capture policies.
Notes on Cross-Cutting Dependencies
- Model stack: Performance relies on MLLMs/VLMs (e.g., Gemini, Qwen, MiniMax) and audio keypoint detection; domain shift may degrade accuracy.
- Compute and latency: Hours-long parsing is compute-intensive; real-time and large-scale use cases require optimized or distilled models.
- Rights and safety: Music and footage licensing; privacy for identifiable individuals; brand safety; regulatory compliance (sector-dependent).
- Integration: Best value realized when exporting timelines (EDL/XML) to NLEs and connecting to MAM/CMS for metadata and governance.
- Prompting and QA: Clear instructions significantly affect outcomes; human oversight remains important for high-stakes or broadcast uses.
Glossary
- Agentic: Pertaining to autonomous, decision-making agents coordinating tasks. "a diverse benchmark specifically designed for agentic video editing tasks."
- Audio-Anchor Alignment: Aligning visual edits to explicit audio anchors (e.g., beats, sections) to ensure synchronization. "pairing a Hierarchical Decomposition strategy for long-context processing with Audio-Anchor Alignment for precise multi-modal synchronization."
- Audio-driven video editing: Editing where music/audio structure guides the selection and timing of visual cuts. "Audio-driven video editing represents the most transformative stage of storytelling, fusing sight and sound into organic harmony."
- Audio-Visual Harmony (AV Harmony): A metric or quality describing how well video cuts align with musical cues. "AV Harmony is quantified via detecting the minimum temporal offset between audio onsets~(downbeats, pitch) and video scenes, strictly rewarding alignments within a perceptual threshold (e.g., )."
- Audio-visual synchronization: Temporal alignment between visuals and audio, especially cuts with beats. "lacking audio-visual synchronization and semantic awareness, they yield repetitive outputs devoid of narrative progression."
- Automatic Speech Recognition (ASR): Technology that converts spoken audio into text transcripts. "Whisper-v3-turbo \cite{whisper} for Automatic Speech Recognition (ASR) to extract subtitles."
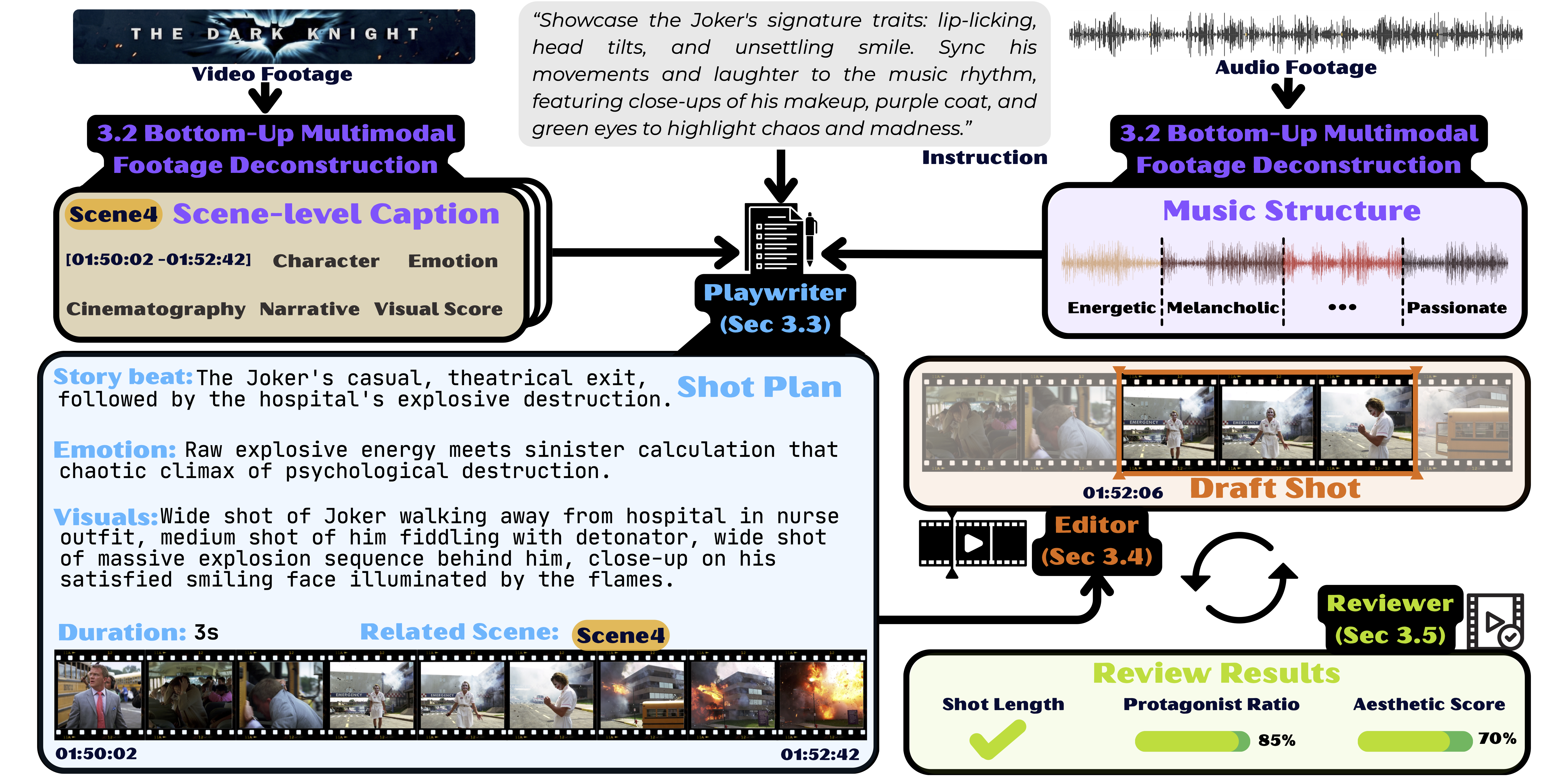
- Bottom-Up Multimodal Footage Deconstruction: Discretizing continuous video and audio into semantic units (shots/scenes, musical sections) for tractable planning. "a Bottom-Up Multimodal Footage Deconstruction module abstracts both raw video and audio into structured semantic units of visual scenes and musical sections"
- Character-Aware Grounding: Conditioning analysis and descriptions on specific character identities to maintain narrative consistency. "Character-Aware Grounding."
- Context window length: The maximum input length an LLM/MLLM can process at once. "physically surpasses the context window length of current MLLMs~(Multimodal LLMs)"
- Disjoint Resource Allocation (Non-Overlap): A constraint ensuring each source scene is used at most once across musical units. "Disjoint Resource Allocation (Non-Overlap): To prevent temporal redundancy, the Playwriter strictly partitions the scene ."
- Downbeats: Strong beat at the start of a musical bar used as rhythmic anchors. "We identify three types of candidates: (i) Downbeats $\mathcal{K}_{\mathrm{db}$ (bar-level accents);"
- Energy minimization problem: Formulating editing as minimizing an energy function that encodes desired alignments. "formulated editing as an energy minimization problem to align shots with themed cues."
- Fine-Grained Cross-Modal Alignment: Precise synchronization between modalities (audio/visual) at sub-shot temporal scales. "Fine-Grained Cross-Modal Alignment. Achieving organic visual-audio harmony demands fine-grained temporal grounding"
- Fine-Grained Shot Trimming: Selecting exact sub-intervals within shots to meet duration and quality constraints. "Action 2: Fine-Grained Shot Trimming."
- Hierarchical Decomposition: A coarse-to-fine structuring of data/tasks to reduce search complexity. "pairing a Hierarchical Decomposition strategy for long-context processing"
- Highlight Detection: Automatically identifying salient or exciting video moments. "Highlight Detection has evolved from using visual saliency scores~\cite{sun2014ranking, xu2021cross, xiong2019less} to incorporating textual prompts"
- Human-Likeness: Subjective measure of how closely automated edits resemble professional human editing. "Human-Likeness, which benchmarks the naturalness of the model's editing pacing and logic against professional human editors."
- Identity injection: Incorporating inferred character identities into model prompts to stabilize references. "we implement a identity injection."
- Keypoint-Aligned Shot Planning: Planning shots to match durations and boundaries of detected audio keypoints. "Keypoint-Aligned Shot Planning"
- Moment retrieval: Locating specific temporal segments in video that match a query. "UVCOM \cite{uvcom} and {Time-R1} \cite{timer1} represent state-of-the-art approaches in moment retrieval and temporal grounding, respectively."
- Multi-Criteria Validity Gate: A filtering stage that accepts/rejects clips based on multiple constraints (identity, timing, quality). "Reviewer: Multi-Criteria Validity Gate"
- Multi-agent framework: A system where multiple specialized agents collaborate to solve a complex task. "an autonomous multi-agent framework designed to edit hours-long raw footage into meaningful short videos"
- Multimodal alignment: Ensuring consistent, coherent coordination among audio, video, and text modalities. "holistic multimodal alignment required to satisfy the dual constraint of global storytelling and fine-grained visual-audio harmony."
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities (e.g., text, image, audio, video). "leverages the capabilities of multiple Multimodal LLMs~(MLLMs) as an agent system."
- Non-linear editing: Non-destructive video editing allowing arbitrary ordering and reordering of clips. "to non-linear editing in EditDuet~\cite{editduet}"
- Peak de-duplication: Removing redundant detected peaks in a signal to yield robust keypoints. "apply temporal filtering (e.g., peak de-duplication) to obtain robust boundaries"
- Protagonist Presence Ratio: The proportion of frames within a clip where the main character is prominently visible. "By computing a Protagonist Presence Ratio via hierarchical MLLM~\cite{Qwen3-VL} sampling, we filter out false positives"
- ReAct: An agent paradigm that interleaves reasoning and acting to iteratively solve tasks. "We instantiate the Editor as a ReAct~\cite{yao2022react} agent"
- Rejection sampling: Iteratively rejecting candidate clips that fail checks until a valid one is found. "this module audits every candidate clip proposed by the Editor through a rigorous rejection sampling mechanism."
- Rhythmic Alignment: Aligning visual edits with the rhythm/beat structure of the music. "To maximize Rhythmic Alignment ($\mathcal{Q}_{\mathrm{sync}$), we convert the continuous music waveform into a discrete grid of potential cut points."
- Semantic Alignment: Matching selected visual content to the semantics of the user’s instruction. "$\mathcal{Q}_{\mathrm{cond}$~(Semantic Alignment) measures the fidelity of selected content to the instructions ;"
- Semantic Neighborhood Retrieval: Expanding the search to semantically adjacent scenes when primary candidates are insufficient. "Action 1: Semantic Neighborhood Retrieval."
- Shot boundary detection: Automatically detecting cuts/transitions between shots in video. "Shot boundary detection is performed using PySceneDetect~\cite{pyscenedetect}."
- Structural Audio Parsing: Segmenting music into hierarchical units (sections, beats) and extracting salient keypoints. "Structural Audio Parsing"
- Structural Scene Allocation: Assigning scenes to specific music sections under disjointness and duration constraints. "Structural Scene Allocation"
- Temporal filtering: Processing signals over time to refine detections (e.g., smoothing, deduplication). "apply temporal filtering (e.g., peak de-duplication)"
- Timeline optimization: Optimizing an edit’s sequence of clips over time under multiple objectives/constraints. "making direct timeline optimization computationally intractable."
- Video Temporal Grounding (VTG): Localizing video segments that correspond to a natural-language query. "Video Temporal Grounding(VTG) and Highlight Detection serve as fundamental prerequisites for editing"
- Vision-LLM (VLM): Models that jointly interpret visual content and text for analysis or retrieval tasks. "the Editor employs a VLM-driven analysis tool to perform dense temporal grounding"
- Visual saliency scores: Quantitative measures of how attention-grabbing or important visual content is. "Highlight Detection has evolved from using visual saliency scores~\cite{sun2014ranking, xu2021cross, xiong2019less}"
Collections
Sign up for free to add this paper to one or more collections.

