- The paper introduces CLEAR, a method that bridges generative and reasoning processes in UMMs to mitigate the impact of image degradation.
- It employs a three-stage approach—behavioral initialization, latent representation bridging, and joint RL-based optimization—to enhance robustness and visual fidelity.
- Empirical results show significant gains on MMD-Bench benchmarks, including a 5.11 point absolute improvement on severely degraded images.
CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
Motivation and Problem Statement
Image degradation caused by factors such as blur, noise, compression, and illumination artifacts represents a significant, ubiquitous barrier in real-world deployment of unified multimodal models (UMMs). Empirical evidence shows that both commercial and open-source UMMs sustain marked drops in reasoning accuracy when inputs undergo these degradations, regardless of architectural sophistication or parameter scale; the generative pathways within these models do not autonomously contribute to robustness.
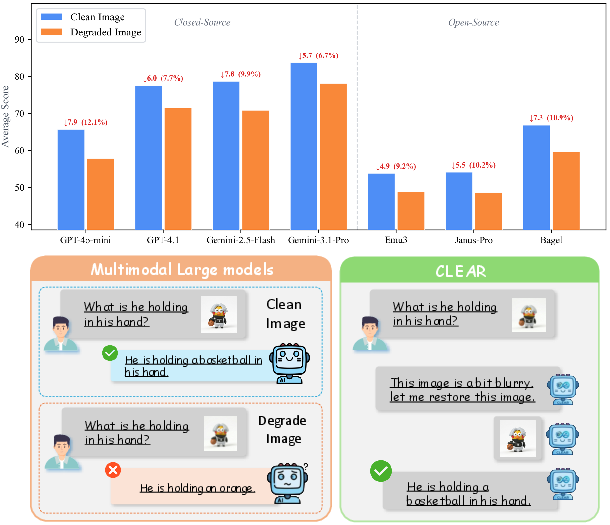
Figure 1: Top: All commercial and open-source multimodal models suffer substantial performance degradation on corrupted MMD-Bench images. Bottom: On a representative degraded image, CLEAR demonstrates a notable robustness advantage over prior approaches.
While UMMs are architecturally poised to address this challenge, housing both an understanding pipeline (typically powered by a vision encoder) and a generative pipeline (e.g., VAE or quantized latent transformer), their training protocols and computation graphs enforce a strong functional disconnect: generative and understanding capacities coexist without direct mutual benefit. Standard pipelines enforce a "decode-reencode" detour that severs differentiability between generation and reasoning, thereby precluding joint answer-level optimization. Consequently, UMMs do not learn to strategically invoke generation to mitigate information loss due to input degradation.
CLEAR Framework: Functional Bridging of Generation and Reasoning
CLEAR (Comprehension via Latent Enhancement and Adaptive Reasoning) introduces a systematic methodology to bridge this disconnect. It comprises three sequential stages: Behavioral Initialization, Structural Bridging, and Joint Optimization via Reinforcement Learning.
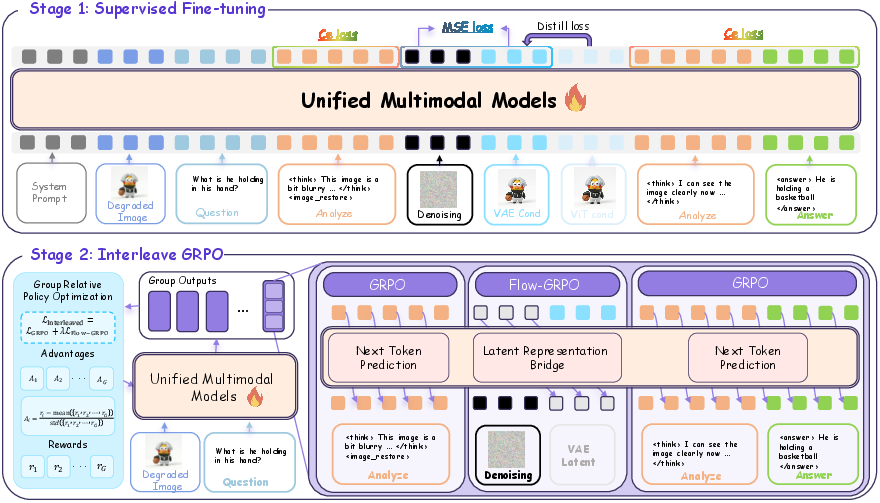
Figure 2: CLEAR employs two-stage training: supervised fine-tuning (top) teaches the generate-then-answer pattern; Interleaved GRPO (bottom) jointly optimizes text and image tokens with rewards derived from answer correctness, utilizing the Latent Representation Bridge as a differentiable conduit.
Behavioral Initialization via Supervised Fine-tuning
CLEAR utilizes a degradation-aware dataset constructed by applying 16 real-world corruption types at multi-level severity to instruction-tuning data. Trajectories are assigned to either a direct-answer route or a generate-then-answer route depending on whether the base model can answer correctly under degradation. This fine-tuning phase teaches the model not only when to invoke generation, but also induces explicit interleaving of generation and reasoning actions in the output sequence, forming the basis for subsequent joint optimization. Ground-truth-guided reasoning traces (with explicit tool-invocation markup) are generated using large LMs (e.g., GPT-4.1), and the LLM backbone alone is updated under a composite objective combining next-token prediction and auxiliary losses for latent visual representation alignment.
Latent Representation Bridge: Eliminating the Decode-Reencode Bottleneck
CLEAR introduces a novel architectural connection: the Latent Representation Bridge. Generated visual latents from the VAE are directly concatenated into the reasoning context, bypassing the prior requirement to decode to pixel space and re-encode via a frozen vision encoder.
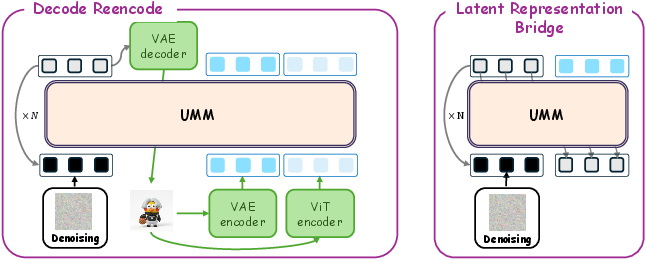
Figure 3: Left: The standard decode-reencode pathway blocks gradients between generation and reasoning. Right: The Latent Representation Bridge enables direct integration of VAE latents, supporting differentiability and efficient optimization.
This structural innovation yields two critical effects: (i) it provides both degraded ViT features and generated VAE latents (with access to low-level structure) as complementary context for the LLM, and (ii) it allows answer-level supervision to backpropagate directly into the generation pathway, enabling end-to-end differentiable optimization with respect to final task success.
Interleaved GRPO: Joint RL-based Optimization
In the third phase, CLEAR adopts Interleaved Group Relative Policy Optimization (GRPO), integrating both GRPO (for text) and Flow-GRPO (for continuous denoising steps) within unified, interleaved trajectories. For each input, multiple full-generation-and-reasoning trajectories are sampled; the reward is based primarily on answer correctness (as assessed by LLM-as-judge), with additional terms for output structure validity and generation decision appropriateness.
Interleaved GRPO samples a random denoising step for credit assignment, efficiently supporting optimization of both text and visual outputs within a shared computation graph. The consequence is a learning dynamic in which the model refines its visual generation strictly in service of improved reasoning performance, rather than mere pixel-level fidelity.
Empirical Results: Robustness, Efficiency, and Visual Quality
Evaluation proceeds on MMD-Bench (six benchmarks × 16 corruptions × 3 severities) and R-Bench-Dis, enabling both aggregate and per-corruption analysis. All comparisons are conducted with scale- and training-matched open baselines (e.g., Bagel, Janus-Pro, Emu3).
Key findings:
- CLEAR-RL (full pipeline) attains the highest open-source robustness: a 5.11 absolute point / 8.5% relative gain over the Bagel-7B backbone on hard MMD-Bench; a 2.02-point margin over Bagel augmented with external state-of-the-art restoration.
- The average clean-to-hard performance drop contracts by 24% compared to baseline, directly demonstrating increased robustness rather than mere overall performance gain.
- Per-corruption analysis indicates that the model's gain is largest for core degradations (motion/lens blur, noise, low illumination), whereas foreign overlays (e.g., graffiti) remain hardest to recover, consistent with expectations regarding generative prior capacity.
- The model acquires input-adaptive generation policies: at low corruption, it skips unnecessary generation, yielding base-level inference cost; at high corruption, it concentrates computation on difficult instances for maximal robustness benefit.
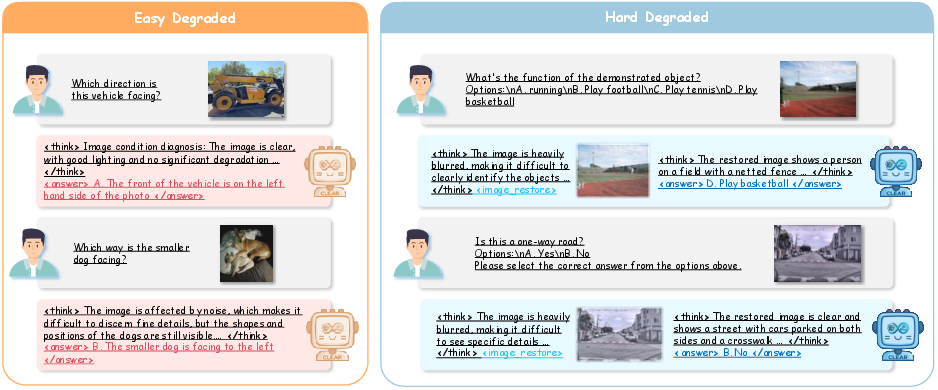
Figure 4: CLEAR performs direct answering on mildly degraded images (left), and triggers generative restoration only when severe degradation impairs necessary cues (right).
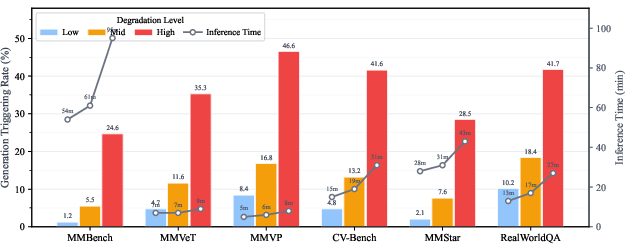
Figure 5: The model dynamically adjusts the generation trigger rate with corruption severity, incurring extra inference cost only when benefit is expected.
Critically, RL-trained models—optimized strictly on answer-correctness—yield intermediate visual states with consistently higher perceptual quality (BRISQUE, NIQE, MUSIQ) than those optimized using pixel-level MSE, despite receiving no explicit perceptual supervision. Task-driven optimization and visual clarity are thus empirically aligned, and reconstruction losses can actively suppress the retrieval of sharp detail.
Theoretical and Practical Implications
The CLEAR framework advances the theory and practice of multimodal model design in multiple ways:
- It demonstrates that potential synergies between generation and understanding in UMMs can only be realized if both behavioral and architectural bottlenecks are eliminated, requiring alteration of both data and computation graph.
- The Latent Representation Bridge constitutes a general structural innovation, permitting unified models to support fully differentiable, interleaved multi-modal reasoning in settings beyond image degradation.
- The finding that task-driven RL yields visual representations with superior perceptual metrics challenges the standard intuition that explicit pixel supervision is necessary for visual generation, with implications for model design in restoration, enhancement, and beyond.
- From a deployment perspective, CLEAR enables robustness improvements on naturally occurring degradations with moderate, predictable computational overhead, as the triggering of generative steps is tightly coupled with anticipated downstream utility.
Conclusion
CLEAR provides a methodologically rigorous and practically effective solution to the problem of degradation-induced performance collapse in unified multimodal models. Through explicit training curricula, architectural modification, and joint RL-based optimization, it establishes an actionable functional connection between generative and reasoning capacities. The resulting models are robust across diverse corruption types, preserve clean-image performance, and dynamically allocate generative resources as needed, closing the behavioral and structural loop that prior UMMs leave open. Future directions include extending the paradigm to finer-grained region-conditional generation, continuous degradation assessment, and modeling of non-additive or adversarial noise distributions.

Figure 6: Visualization of the 16 corruption types at three severity levels exemplifies the diversity and severity of degradations addressed in MMD-Bench and CLEAR analysis.

Figure 7: Additional qualitative results demonstrate the breadth of CLEAR’s robust reasoning across degradation types and benchmarks.

