Does Understanding Inform Generation in Unified Multimodal Models? From Analysis to Path Forward
Abstract: Recent years have witnessed significant progress in Unified Multimodal Models, yet a fundamental question remains: Does understanding truly inform generation? To investigate this, we introduce UniSandbox, a decoupled evaluation framework paired with controlled, synthetic datasets to avoid data leakage and enable detailed analysis. Our findings reveal a significant understanding-generation gap, which is mainly reflected in two key dimensions: reasoning generation and knowledge transfer. Specifically, for reasoning generation tasks, we observe that explicit Chain-of-Thought (CoT) in the understanding module effectively bridges the gap, and further demonstrate that a self-training approach can successfully internalize this ability, enabling implicit reasoning during generation. Additionally, for knowledge transfer tasks, we find that CoT assists the generative process by helping retrieve newly learned knowledge, and also discover that query-based architectures inherently exhibit latent CoT-like properties that affect this transfer. UniSandbox provides preliminary insights for designing future unified architectures and training strategies that truly bridge the gap between understanding and generation. Code and data are available at https://github.com/PKU-YuanGroup/UniSandBox
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question about advanced AI models that can both “understand” and “create”: does what the model understands actually help it make better images? The authors build a careful testing setup and show that many models struggle to use their thinking and knowledge when generating pictures. They also suggest ways to fix this.
What questions did the researchers ask?
They focus on two simple ideas:
- Can the model use reasoning (like doing math or following rules) to guide the pictures it makes?
- Can the model use new facts it learns (knowledge) to create the right images later?
In other words: if an AI can figure out an answer in text, can it turn that answer into the right image?
How did they study it?
The UniSandbox “safe playground”
The authors created a controlled “sandbox” called UniSandbox. Think of it like a clean, cheat-proof testing ground:
- They used synthetic (made-up) data so the model couldn’t just memorize old examples from the internet.
- They separated “understanding” (thinking) from “generation” (drawing) so they could see where things go wrong.
Reasoning tasks
They tested reasoning with two types of challenges:
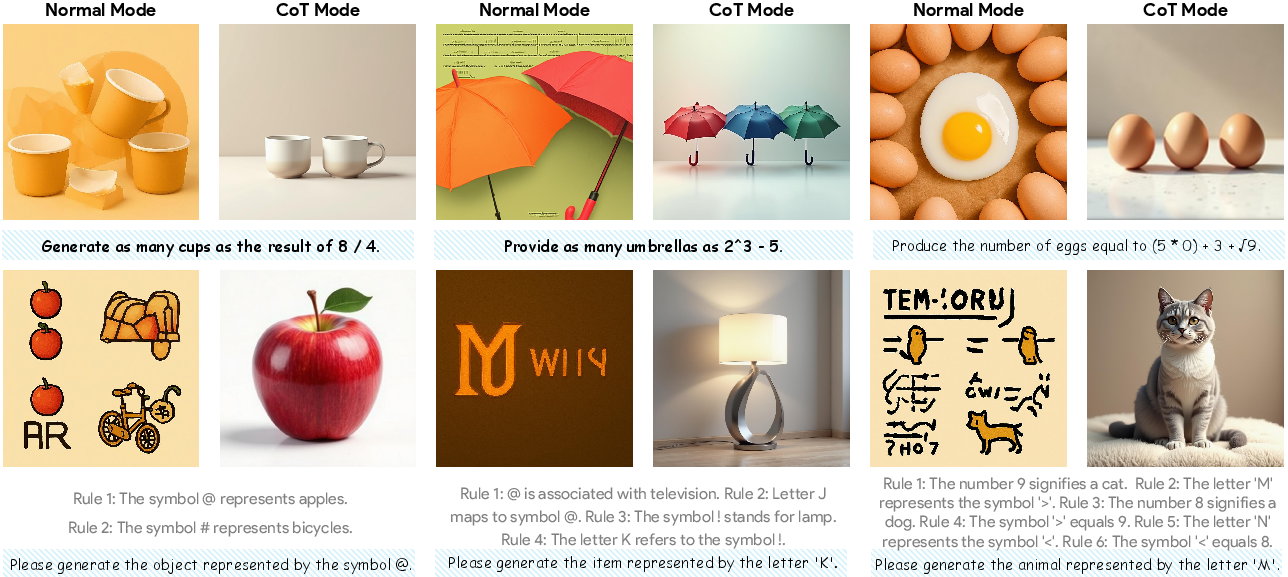
- Mathematical Operations: The AI has to do small math first, then generate the right number of objects. Example: “Draw as many erasers as 3 - 2.” The model should compute 3 - 2 = 1, then draw one eraser.
- Symbolic Mapping: The AI follows a chain of rules to find the right object. Example: “A → 1, 1 → cat.” The model should figure out A means cat, then draw a cat.
These tasks force the AI to think before drawing, not just match a word to a picture.
Knowledge transfer tasks
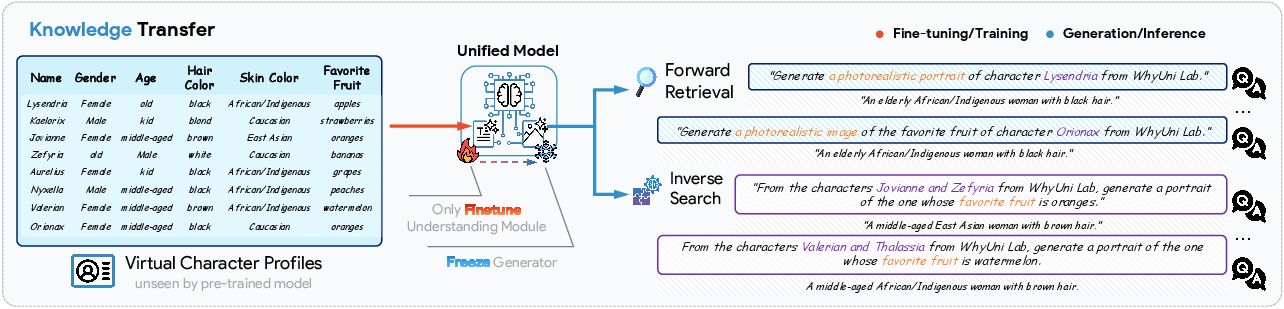
They taught the model brand‑new facts about fictional characters (like names and favorite things), then checked if it can use those facts when creating images:
- Forward Retrieval (Key → Value): From a name (key), generate the right attribute (value), like the favorite fruit.
- Inverse Search (Value → Key): From the attributes (value), generate the right character (key).
This tests whether the model can recall newly learned information when generating pictures.
How they graded the results
To avoid judging by eye, they used a two-step check with another AI:
- The AI writes a caption describing the generated image.
- Another AI compares that caption to the correct answer to see if it matches.
For mapping tasks, the model had to get both parts of a pair right to score a point—this reduces lucky guesses.
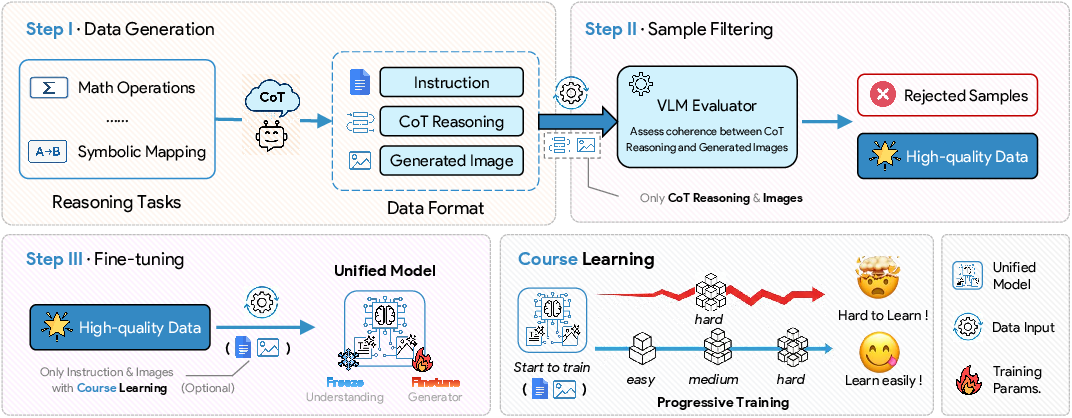
Teaching the model to “think inside”
They tried a simple training method called STARS (Self-Training with Rejection Sampling):
- Use Chain-of-Thought (CoT)—like “showing your work”—to generate correct examples.
- Keep only high-quality examples (filter out wrong ones).
- Fine‑tune the model on these examples without the visible “thinking steps,” hoping it learns to reason internally.
They also used Curriculum Learning (learning easy tasks first, then harder ones) for tricky rule-following problems to prevent the model from “cheating” by always drawing the same thing.
What did they find?
Here are the main results and why they matter:
- There’s a big gap between understanding and generation: Many models can “understand” text but fail to use that understanding when making images, especially for reasoning tasks. Without visible step‑by‑step thinking (CoT), open-source models scored near zero.
- Chain-of-Thought is a powerful bridge: When the model writes out its reasoning first (CoT), its image generation gets much better—scores jump from almost nothing to around half correct. This shows that “thinking out loud” helps the model turn understanding into correct images.
- Self-training can internalize reasoning: Using STARS, the model improved even without visible CoT. It learned to do some reasoning quietly and still generate the right images, and it generalized across different difficulty levels—showing real learning, not memorization.
- Knowledge transfer is hard: When taught new facts, most models struggled to use them for image generation. CoT helped a lot in “forward retrieval” (name → attribute), but “inverse search” (attribute → name) stayed weak—similar to a known “reversal curse” in LLMs.
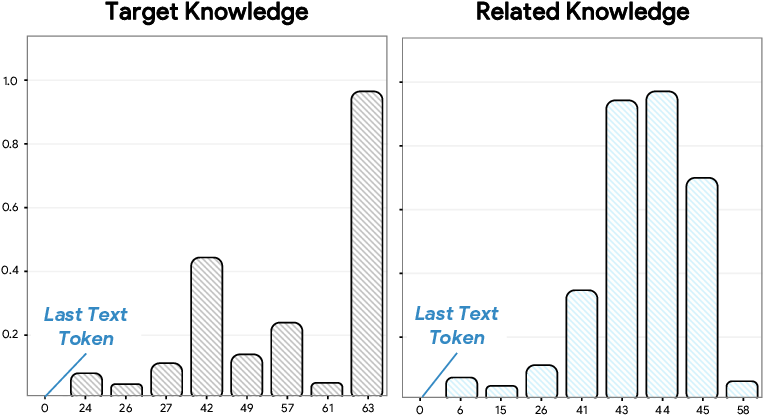
- Query-based models may do “silent CoT”: Architectures that use special “queries” to pull out information seem to naturally retrieve and chain relevant facts over steps, a bit like hidden Chain-of-Thought. These models performed better than some others on knowledge transfer.
Why it matters
If an AI can’t use its understanding to guide what it creates, it will fail at more complex instructions. Real-world prompts often require thinking first (like planning scenes, following rules, or using facts). This paper shows that today’s unified models aren’t fully “unified” in practice—their reading brain and drawing brain don’t talk well enough.
Implications and potential impact
- Training strategies: Adding Chain-of-Thought and using self-training (like STARS) and curriculum learning can make models better at reasoning‑guided generation.
- Model design: Query-based architectures might naturally support “silent reasoning.” Future models could build on this to better connect understanding and generation.
- Better benchmarks: UniSandbox gives a clean, fair way to test whether understanding really helps generation—useful for researchers and developers to measure genuine progress.
Overall, this work highlights a crucial weakness in current AI and offers practical steps to make “understanding informs generation” a reality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of the key gaps the paper leaves unresolved. Each point is framed to be directly actionable for future research.
- External validity: The framework relies entirely on synthetic, leak-proof tasks; it remains unclear whether the observed understanding–generation gap and CoT effects transfer to real-world, open-domain prompts and datasets with naturally occurring ambiguities, distractions, and compositional complexity.
- Judge reliability: The two-stage evaluation uses an MLLM to caption images and another MLLM to compare captions with ground truth; the paper does not quantify caption hallucination rates, inter-judge agreement across different MLLMs, or the sensitivity of results to judge choice and prompts.
- Metric granularity: Binary scoring for many tasks (including pair-wise success in symbolic mapping) may mask partial successes and nuanced errors; no calibrated, fine-grained metrics (e.g., per-attribute accuracy, reasoning step correctness, confidence-weighted measures) are provided.
- Human evaluation: No human-in-the-loop assessment to validate MLLM-based judgments, particularly for subtle reasoning, numerosity, or attribute correctness; the absence of human audits limits trust in the reported scores.
- Data leakage verification: While the paper claims leak-proof synthetic data, it does not provide formal checks (e.g., approximate matching against pretraining corpora, perplexity-based overlap tests, or canary-based audits) to empirically validate the no-leak assumption.
- Realism and task diversity: Reasoning tasks cap numerosity at less than seven and symbolic chains at length three; open questions remain about performance on longer chains, higher numerosity, occlusion, cluttered scenes, multi-step spatial reasoning, or mixed symbolic and mathematical reasoning.
- Knowledge injection scope: The knowledge transfer experiments use simple virtual character profiles with a small set of attributes; the generality of results for richer, relational, temporal, counterfactual, or multi-entity knowledge (e.g., “A’s friend B prefers X when Y holds”) is unknown.
- Catastrophic forgetting: The paper injects new knowledge into the understanding module, but does not measure retention of original knowledge, interference effects, or stability–plasticity trade-offs in both understanding and generation after fine-tuning.
- Inverse retrieval (“reversal curse”) mitigation: The paper observes poor Value→Key performance but does not test interventions (e.g., symmetric training objectives, bidirectional contrastive losses, retrieval-augmented planners, or cross-attention constraints) to overcome this limitation.
- Architecture causality: The claim that query-based architectures exhibit a latent CoT-like capability is based on correlational probability visualizations; rigorous causal tests (ablation of query count/position, intervention on attention flows, controlled feature removal) are missing.
- Cross-architecture generalization of STARS: STARS (self-training with rejection sampling) is only demonstrated on BAGEL; it is unknown whether the method works (or how to adapt it) for AR-only, shallow fusion (AR+Diffusion), and other unified multimodal models.
- Self-verification bias: STARS uses the model’s own understanding module as the verifier for filtering; the extent of confirmation bias, error compounding, and overfitting to its own judgments is not assessed against external verifiers or cross-model filters.
- Training stability and CL schedules: Curriculum learning (CL) was necessary for symbolic mapping, but the paper does not explore CL schedule design (e.g., pacing, mixing ratios, adaptive difficulty), sensitivity to hyperparameters, or robustness across datasets and seeds.
- Degradation under high difficulty: Direct training on higher-level symbolic datasets degrades performance (including CoT-mode performance); the underlying causes (e.g., loss landscape, shortcut learning, instability) remain uncharacterized and unmitigated.
- Scaling laws: There is no analysis of how STARS improvements scale with data volume, model size, number of training steps, or CoT trace complexity; researchers lack guidance on cost–benefit and convergence behavior.
- CoT mechanism tracing: The study shows CoT helps, but provides no mechanistic analysis (e.g., representational trajectory tracking, reasoning step localization, causal mediation) to explain how CoT signals are transformed into effective generative guidance.
- Alternative bridges beyond CoT: The paper does not evaluate other understanding-to-generation bridges (planner modules, program-of-thought, memory retrieval, structured constraints, latent alignment losses, or RL feedback) that could replace or complement CoT.
- Prompting and “think mode” standardization: The CoT prompting protocol (“think mode”) and rewriting strategy are not standardized or stress-tested; effects of prompt phrasing, reasoning formats, or external reasoning agents remain unexplored.
- Statistical significance: Results are reported over relatively small prompt sets (e.g., 300 math prompts, 600 mapping prompts) without confidence intervals, variance analysis, or statistical testing; replicability across random seeds and prompt variants is not shown.
- Quality–accuracy trade-offs: The paper focuses on semantic correctness but does not analyze whether reasoning activation (CoT, STARS) affects image fidelity, realism, or aesthetic quality; joint metrics and Pareto trade-offs remain unquantified.
- Robustness and adversariality: Performance under adversarial prompts, linguistic perturbations, visual distractors, or instruction noise (e.g., typos, synonyms, negations) is not assessed.
- Knowledge retrieval pathways: For knowledge transfer, the pathways by which understanding-derived facts condition the generator (e.g., feature bottlenecks, cross-attention) are unmeasured; targeted architectural probes and interventions could clarify bottlenecks.
- Task generalization: STARS shows cross-difficulty generalization in math but mixed results in mapping; it is unclear if the distilled implicit reasoning transfers to unseen reasoning families (logic puzzles, algebraic word problems, spatial planning).
- Closed-source comparability: The best closed-source model (nano-banana) exhibits CoT-like behavior, but proprietary preprocessing or orchestration may be responsible; without controlled replication, attributing gains to architecture vs. prompting vs. training is speculative.
- Efficiency and latency: CoT and multi-stage evaluation introduce overhead; the paper does not quantify inference latency, training cost, or throughput implications of CoT/STARS/CL pipelines.
- Multimodal breadth: The framework targets text-to-image only; whether the conclusions hold for other generative modalities (video, audio, 3D, multi-image) or cross-modal generation (e.g., image-to-image guided by text reasoning) is unknown.
- Safety and bias: Injected knowledge and reasoning pipelines may propagate or amplify biases; the paper does not audit demographic fairness, attribute misclassification biases, or safety concerns arising from reasoning-guided generation.
- Release completeness: Some critical details (judge prompts, knowledge injection protocol specifics, CoT formats, curriculum schedules) are referenced in appendices but not systematically summarized; reproducibility across labs may be hindered without standardized recipe and seed control.
- Data generation bias: Task instances are generated by GPT-4o; potential biases in task distributions, linguistic styles, and symbol choices introduced by a single generator are not analyzed or mitigated (e.g., using multiple generators or templated combinatorics).
- Capacity-controlled comparisons: Model comparisons do not control for parameter count, pretraining data volume, or generator backbone quality; confounding factors may obscure true architectural effects on understanding-to-generation transfer.
These gaps point to concrete next steps: diversify tasks and modalities, calibrate and validate evaluators, design causal architecture studies, broaden STARS across models, optimize curriculum learning, and develop alternative bridges between understanding and generation beyond CoT.
Practical Applications
Immediate Applications
Below are applications that can be deployed now by leveraging the paper’s frameworks (UniSandbox), training strategies (CoT activation, STARS, curriculum learning), evaluation protocol (caption+semantic judge), and architectural insights (query-based latent CoT).
- UniSandbox-based pre-deployment evaluation for multimodal products (software/ML, media/advertising)
- Use leak-proof synthetic tasks to audit whether a unified multimodal model (UMM) can correctly translate understanding into generation under reasoning and knowledge-transfer demands.
- Potential tools/products: “UniSandbox-as-a-Service” for model vendors; CI/CD gates for T2I/UMM releases.
- Assumptions/dependencies: Access to MLLMs for captioning/judging; synthetic data generation; compute; evaluation bias management; reproducible seeds.
- Reason-then-generate middleware via explicit CoT prompt rewriting (software, media/design, e-commerce, education)
- Preprocess user prompts with an LLM to compute the required logic/knowledge (e.g., 3–2=1, “Mother’s Day flower”→“carnation”), then pass the resolved instruction to the generator.
- Potential workflows: Creative production pipelines; product image configuration; visual math/logic problems.
- Assumptions/dependencies: Reliable CoT LLM; prompt hygiene to avoid hallucination; fallback verification step; domain-specific lexicons.
- CoT-activated knowledge retrieval for brand/style and product catalogs (retail/e-commerce, marketing)
- Inject newly acquired structured knowledge (e.g., brand guidelines, SKU attributes) into the understanding module; use CoT to retrieve relevant attributes and guide generation.
- Potential tools: Lightweight adapters or fine-tunes for brand knowledge; “catalog-to-visual” generators.
- Assumptions/dependencies: Controlled knowledge injection pipelines; data freshness; judge-based attribute validation; licensing constraints for closed-source models.
- Two-stage acceptance testing and guardrails for generative outputs (policy/compliance, finance reporting, enterprise content ops)
- Apply the paper’s caption+semantic comparison protocol to automatically accept/reject images based on rule compliance (e.g., quantities, colors, attributes).
- Potential products: “CoT Guardrail Evaluator” for content moderation; compliance dashboards.
- Assumptions/dependencies: MLLM judge robustness; domain-specific semantic rules; audit trails; bias auditing.
- STARS self-training to internalize reasoning for task-specific deployments (software vendors, ML ops)
- Fine-tune UMMs with CoT-generated and self-verified samples to reduce dependence on explicit CoT at inference for math/logic tasks.
- Potential products: “STARS Fine-Tuning Kit” with data generation, rejection sampling, and training scripts.
- Assumptions/dependencies: Sufficient compute and high-quality CoT outputs; reliable self-verification; careful scope (task-specific generalization, avoid overfitting).
- Curriculum learning schedulers for complex reasoning tasks (academia/research labs, training platform providers)
- Integrate progressive curricula (e.g., Math/Mapping levels) to prevent shortcut learning and preserve/enhance CoT capabilities.
- Potential tools: Training pipeline plugins that schedule datasets by difficulty.
- Assumptions/dependencies: Good curriculum design; monitoring for performance drift; data balance.
- Architecture selection guidance: prefer query-based conditioning for knowledge transfer-sensitive use cases (model engineering, platform teams)
- Adopt query-based shallow-fusion designs where knowledge retrieval matters, leveraging latent CoT-like behavior observed in queries.
- Potential tools: Architectural templates; inference-time query configuration.
- Assumptions/dependencies: Access to model internals; ability to add/optimize query sets; careful evaluation for task fit.
- Query visualization/diagnostics to audit retrieval behavior (ML ops, research)
- Use the paper’s approach to decode hidden states and inspect how queries retrieve target knowledge and intermediate attributes over time.
- Potential tools: “QueryScope” visualization dashboard.
- Assumptions/dependencies: Hooks into model internals; privacy-safe logging; interpretability training.
- Education content generation with verified reasoning (education technology, publishers)
- Produce math/logic learning visuals using reason-then-generate pipelines and guardrail evaluation to ensure correctness of quantities and mappings.
- Potential products: AI lesson content generators; interactive problem visualizers.
- Assumptions/dependencies: Alignment with curricula; stringent correctness validation; teacher-in-the-loop workflows.
Long-Term Applications
Below are applications that require further research, scaling, architectural development, or policy standardization, building on the UniSandbox insights and the understanding–generation gap.
- New unified architectures with built-in reasoning-to-generation bridges (software/model vendors, robotics)
- Design deep-fusion or hybrid systems where understanding signals (reasoning traces, knowledge retrieval) are reliably translated into generation conditions without explicit CoT.
- Potential products: “Reasoning-native” UMMs; transformer-diffusion hybrids with structured reasoning heads.
- Assumptions/dependencies: Robust handling of multi-step logic; benchmarks; stability under distribution shifts.
- Robust inverse knowledge retrieval (Value→Key) to overcome the reversal curse (knowledge management, search, e-commerce)
- Enable models to identify entities from attribute sets as reliably as forward retrieval, supporting attribute-based search and personalization.
- Potential workflows: “Describe-it→Find-it→Generate-it” engines; attribute-first product discovery.
- Assumptions/dependencies: Architectural and training advances; structured knowledge stores; careful evaluation.
- Standardized benchmarks and procurement policies for understanding–generation synergy (policy/regulators, enterprise governance)
- Formalize UniSandbox-like tests in RFPs and compliance suites for sectors where correctness matters (finance reporting visuals, healthcare education materials, public information).
- Potential artifacts: Sector-specific test suites; certification pathways.
- Assumptions/dependencies: Stakeholder consensus; auditing infrastructure; liability frameworks.
- Continual knowledge injection with reliable generative replay (retail/e-commerce, catalog ops, marketing)
- Build pipelines that ingest frequent catalog updates and immediately influence image generation, preserving attribute accuracy and brand consistency.
- Potential products: “Live Catalog→Visual” generators; dynamic brand compliance checks.
- Assumptions/dependencies: Safe continual learning; drift detection; scalable verification.
- Patient-specific educational visuals from computed care instructions (healthcare, patient education)
- Produce personalized visuals (e.g., rehabilitation steps, device usage illustrations) where reasoning computes individual parameters before generation.
- Potential workflows: EMR-integrated education tools with reason→generate pipelines and strict guardrails.
- Assumptions/dependencies: High accuracy, privacy compliance (HIPAA/GDPR), clinical review, bias/fairness controls; avoid diagnostic/therapeutic claims without approval.
- Simulation scene generation from logical constraints for planning (robotics, autonomous systems, digital twins)
- Translate situational rules and constraints into synthetic environments that match computed parameters for testing and training.
- Potential products: Constraint→Scene generators; risk-aware simulation suites.
- Assumptions/dependencies: Domain logic integration; safety validation; scalable scene composition.
- Explainable finance visualization pipelines (finance, analytics)
- Ensure charts/infographics reflect computed metrics derived via verified reasoning steps (explicit or internalized), with audit logs of the reasoning path.
- Potential tools: Reason-explained reporting engines; compliance dashboards.
- Assumptions/dependencies: Data integrity; audit trails; regulator acceptance; performance at scale.
- Energy/urban planning visuals derived from model outputs (energy, public infrastructure)
- Generate maps and schematics that reflect outputs of planning models (load forecasts, zoning constraints) after explicit computation, with guardrail verification.
- Potential workflows: Policy briefings; stakeholder communications; scenario testing.
- Assumptions/dependencies: Domain model integration; public transparency standards; multi-stakeholder review.
- Personalized tutoring agents with multi-step visual reasoning (education)
- Agents that solve problems with internal reasoning (possibly implicit after STARS-like training) and produce step-wise visual explanations tailored to learner progress.
- Potential products: “Reason-and-visualize” tutors; curriculum-aligned adaptive learning systems.
- Assumptions/dependencies: Longitudinal evaluation; pedagogical alignment; robust correctness checks; equity and accessibility.
- Autonomous creative assistants that compute rules from briefs (media/design)
- Agents that parse constraints (brand rules, legal requirements, logical specifications) and reliably produce compliant visuals, minimizing human corrections.
- Potential workflows: Brief→Constraints→Verified Visuals; collaborative co-pilots for designers.
- Assumptions/dependencies: Strong constraint parsing; legal/compliance integration; human oversight; performance under complex briefs.
Glossary
- Ablation study: An experimental procedure where components or settings are systematically removed or varied to assess their impact on performance. "We also conducted an ablation study on rejection sampling in \autoref{app:abl}."
- AR + Diffusion (deep fusion) models: Unified models that tightly integrate autoregressive language components with diffusion-based image generation within a single transformer. "AR + Diffusion (deep fusion) models, like BAGEL~\citep{deng2025emerging}, which unify understanding and generation within a deeply integrated transformer framework."
- AR + Diffusion (shallow fusion) models: Models that combine an autoregressive component with a diffusion generator via a lightweight connection, often passing extracted features as conditions. "AR + Diffusion (shallow fusion) models, which use an AR model to extract features."
- Autoregressive (AR) models: Generative models that produce outputs token-by-token, each conditioned on previously generated tokens. "Autoregressive (AR) models, such as Janus-Pro-7B~\citep{januspro2025};"
- Bag-of-words: A simplified representation treating text as an unordered set of words, ignoring structure or reasoning. "their generation process degenerates into a shallow pixel-to-word mapping, essentially more like a ``bag-of-words''~\citep{yuksekgonul2022and}."
- Chain-of-Thought (CoT): A prompting or modeling technique that makes intermediate reasoning steps explicit to guide task completion. "explicit Chain-of-Thought (CoT) in the understanding module effectively bridges the gap,"
- Curriculum Learning: A training strategy that presents tasks in increasing order of difficulty to improve learning and generalization. "Inspired by this observation, we adopted a Curriculum Learning~\citep{bengio2009curriculum} strategy that mimics human learning by exposing the model to progressively more complex knowledge."
- Data contamination: Unintended overlap or leakage between training and evaluation datasets that biases assessment. "To prevent ``data contamination'' caused by the overlap between the current model pre-training dataset and the evaluation dataset,"
- Data leakage: The presence of evaluation content within training data (or vice versa), leading to artificially inflated performance. "a decoupled evaluation framework paired with controlled, synthetic datasets to avoid data leakage"
- Decoupled evaluation framework: An assessment setup that separates components (e.g., understanding and generation) to attribute performance more precisely. "we introduce UniSandbox, a decoupled evaluation framework paired with controlled, synthetic datasets to avoid data leakage and enable detailed analysis."
- Deeply integrated transformer framework: A design where understanding and generation are unified within a single transformer architecture for tighter coupling. "which unify understanding and generation within a deeply integrated transformer framework."
- Forward Retrieval: A knowledge-use task where the model generates a value (e.g., attribute) given a key (e.g., name). "Forward Retrieval (Key Value)"
- Hidden state: Internal model representation (e.g., from a transformer) used as conditioning for subsequent generation. "which utilizes the last hidden state as generation condition"
- Inherent Self-Verification Capability: A model’s ability to assess the semantic consistency of its own outputs relative to inputs using its understanding component. "Inherent Self-Verification Capability: The unified model's powerful visual understanding endows it with an inherent capability to evaluate its own generative output."
- Inverse Search: A task requiring the model to infer the key (e.g., character identity) from given attributes or values. "Inverse Search (Value Key)"
- Knowledge injection: The process of introducing new, controlled information into a model’s understanding module via fine-tuning. "we inject new knowledge into the model's understanding module"
- Knowledge transfer: The ability of a model to use knowledge stored in its understanding component to guide its generative component. "for knowledge transfer tasks, we find that CoT assists the generative process"
- Latent CoT-like capability: An implicit, chain-of-thought-like behavior emerging within an architecture (e.g., query-based) without explicit reasoning prompts. "query-based architectures, which use an extra set of queries for information extraction as the condition for generation, exhibit a latent CoT-like capability."
- Leak-proof data: Synthetic evaluation data constructed to avoid overlap with pretraining corpora, preventing leakage. "we introduce UniSandbox, a decoupled framework with synthetic, leak-proof data."
- Multimodal LLMs (MLLMs): LLMs that can process and reason over multiple modalities (e.g., text and images) for evaluation or generation. "To avoid the judge biases associated with using Multimodal LLMs (MLLMs) as direct visual judges~\citep{chen2025multi},"
- Out-of-distribution synthetic data: Artificially generated datasets intentionally distinct from training distributions to ensure robust evaluation. "completely out-of-distribution synthetic data to provide an ideal ``sandbox environment''."
- Paired prompts: Matched prompt pairs designed to reduce guessing by requiring consistent reasoning across variants. "we employ paired prompts, where each pair is based on the same set of rules but asks for a different result."
- Query-based architectures: Models that use learned query vectors to extract conditional information for generation. "query-based architectures, which use an extra set of queries for information extraction as the condition for generation"
- Rejection sampling: A filtering method that retains only samples meeting a criterion (e.g., consistency), discarding others. "curating 5,000 high-quality samples generated via CoT and filtered with rejection sampling."
- Reversal curse: A phenomenon where models can retrieve values from keys but fail at the inverse mapping. "This finding aligns with the ``reversal curse" observed in LLMs ~\citep{berglund2023reversal},"
- Semantic comparison: Evaluating alignment by comparing generated captions with ground-truth answers in text space. "we employ MLLM to perform a semantic comparison between the generated caption and the ground-truth answer"
- Semantic consistency: The degree to which generated outputs faithfully match the meaning of the input instructions. "assess the semantic consistency between a generated image and a textual instruction."
- Self-training: A paradigm where a model generates pseudo-labels or training samples and uses them to improve itself. "a self-training approach can successfully internalize this ability, enabling implicit reasoning during generation."
- STARS (Self-Training with Rejection Sampling): A self-training framework that distills CoT-generated samples and filters them via rejection sampling to teach implicit reasoning. "we envision a preliminary framework named \textcolor{topicblueS}elf-\textcolor{topicblueT}r\textcolor{topicbluea}ining with \textcolor{topicblueR}ejection \textcolor{topicblueS}ampling (STARS)."
- Symbolic mapping: Tasks requiring reasoning over arbitrary symbol-to-object rules through multi-step mapping chains. "The symbolic mapping tasks are designed to evaluate a model's ability to follow novel, arbitrary rules by reasoning through mapping chains of varying lengths."
- Think mode: A generation mode where the model explicitly produces reasoning steps (CoT) before the final output. "Normal and CoT represent generation without/with think mode (Chain-of-Thought mode), respectively."
- Two-stage evaluation protocol: An assessment procedure that first captions outputs and then evaluates caption-gt alignment, avoiding direct visual judging biases. "we implemented a two-stage evaluation protocol."
- Unified Multimodal Models (UMMs): Single models that combine understanding and generation across modalities (e.g., vision and language). "Recent years have witnessed significant progress in Unified Multimodal Models,"
- UniSandbox: A controlled, decoupled evaluation framework with synthetic data to study understanding’s impact on generation. "we introduce UniSandbox, a decoupled framework with synthetic, leak-proof data."
- Understanding-generation gap: The discrepancy where a model’s understanding does not effectively inform or guide its generation. "Our findings reveal a significant understanding-generation gap,"
- Understanding-to-generation transfer: The process of leveraging understanding results (e.g., reasoning, knowledge) to condition and drive generation. "a failure in the
understanding-to-generation" transfer (i.e., theunderstanding" module knows the answer, but the ``generation" module cannot utilize it)."
Collections
Sign up for free to add this paper to one or more collections.