- The paper introduces 16 measurable reasoning features spanning multilingual alignment, step quality, and flow dynamics to quantify trace effectiveness.
- Regression analysis and sparse autoencoder models reveal varying feature impacts across languages, highlighting both adaptive selection benefits and cross-lingual conflicts.
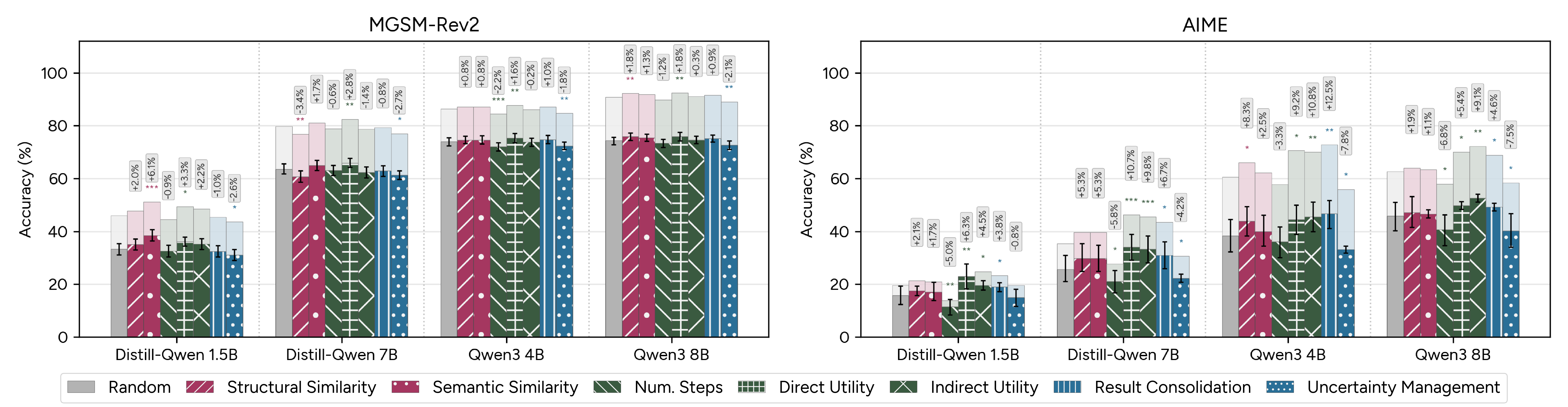
- Test-time trace selection based on features like direct utility and self-checking yields significant accuracy gains, especially on challenging benchmarks.
Disentangling Multilingual Reasoning: Feature-Based Analysis and Adaptive Trace Evaluation
Introduction
This paper, "What Makes Good Multilingual Reasoning? Disentangling Reasoning Traces with Measurable Features" (2604.04720), systematically interrogates the assumptions underlying multilingual reasoning performance in Large Reasoning Models (LRMs). The authors challenge the prevalent paradigm of directly projecting reasoning practices from English to other languages, particularly the notion that English-derived reasoning features universally underpin effective reasoning across linguistic boundaries. Instead, they introduce a comprehensive framework that identifies, quantifies, and exploits measurable features within reasoning traces to dissect and optimize multilingual reasoning, moving beyond final answer correctness toward a nuanced, trace-level analysis.
Methodology
Feature Definition and Categorization
The core of the study is the definition of 16 measurable reasoning features that span three axes: multilingual alignment, reasoning step quality, and reasoning flow dynamics. These features encompass structural and semantic alignment to English traces, translation quality (COMET-QE), step count, logical validity (NLI-based), direct and indirect utility, V-Information, and cognitively-relevant tags (e.g., self-checking, plan generation, uncertainty management), all annotated and quantified for each language and trace.
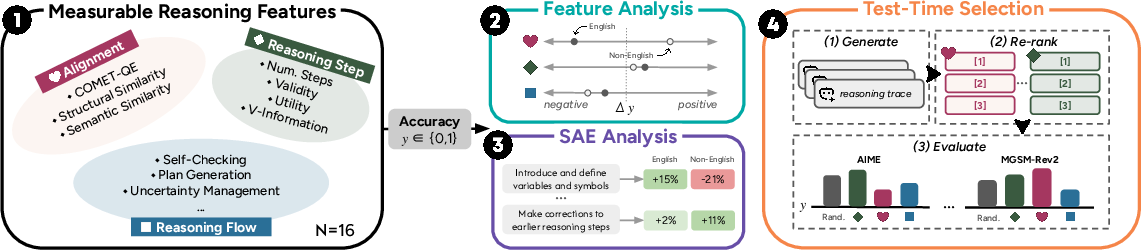
Figure 1: Overview of the method, showing the complete suite of reasoning features and their association analyses via regression, SAEs, and test-time selection policies.
Statistical Analysis and Regression Modeling
For each feature, a univariate logistic regression is employed per language to model the association between normalized feature values and final answer correctness. The discrete change in predicted accuracy across ±1 standard deviation of each feature (ΔAcc) provides a robust effect size, enabling direct comparison across features and languages.
Sparse Autoencoder Discovery
To extend beyond the hand-designed feature set, sparse autoencoders (SAEs) are trained on multilingual reasoning traces. Latent neurons with high accuracy correlation are identified, interpreted via GPT-4o, and benchmarked against the established features. This approach offers a pathway to capture fine-grained and emergent reasoning behaviors beyond the scope of manual annotation.
Test-Time Trace Selection
Each feature is operationalized as an inference-time trace selection policy. For each query, 32 candidate reasoning traces are generated and ranked by feature value, enabling empirical evaluation of each policy's impact on pass@1 accuracy relative to random and English-similarity-based selection strategies.
Experimental Design
The evaluation leverages MGSM-Rev2 (middle-school math, human-translations) and AIME (high-school math, machine-translations) benchmarks across ten languages (Bengali, German, Spanish, French, Russian, Swahili, Telugu, Thai, Chinese, English) and four open-weight LRMs (Distill-Qwen 1.5b/7b, Qwen-3 4b/8b), encompassing diverse resource levels, typologies, and scripts.
Results
Regression Analysis of Feature Effects
Distinct patterns emerge from feature analysis:
- Multilingual Alignment Features: COMET-QE, structural similarity, and semantic similarity to English all positively correlate with accuracy, but effect sizes vary substantially across languages and can reverse.
- Reasoning Step Features: Validity, direct/indirect utility, and V-Information generally exhibit positive associations, though magnitude depends on task difficulty and language context.
- Reasoning Flow Features: Cognitive tags related to computation, result consolidation, and self-checking consistently predict accuracy, but features like uncertainty management display negative or inconsistent associations, often diverging between English and non-English traces.
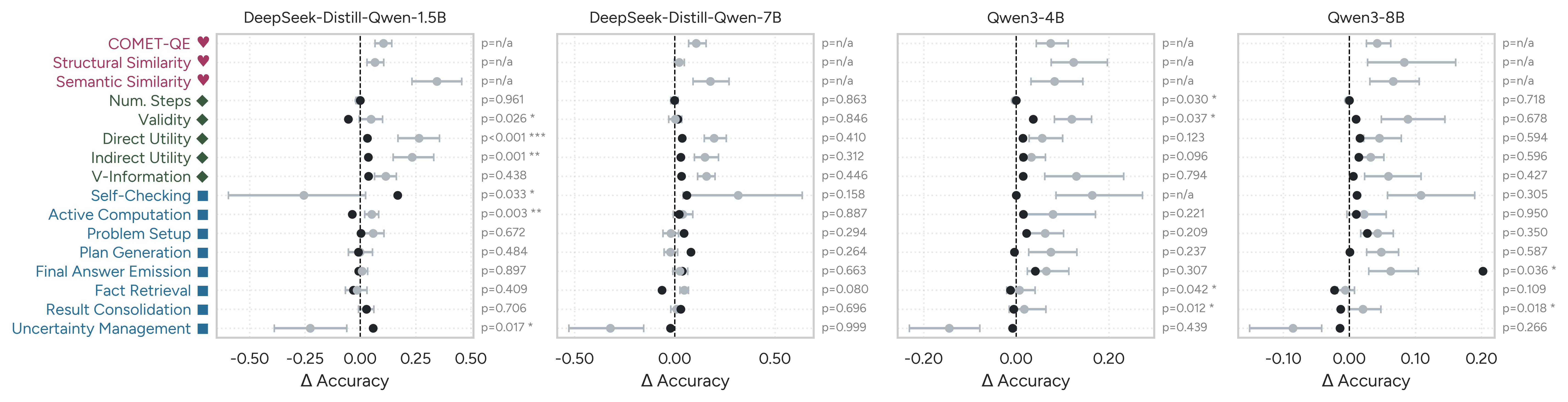
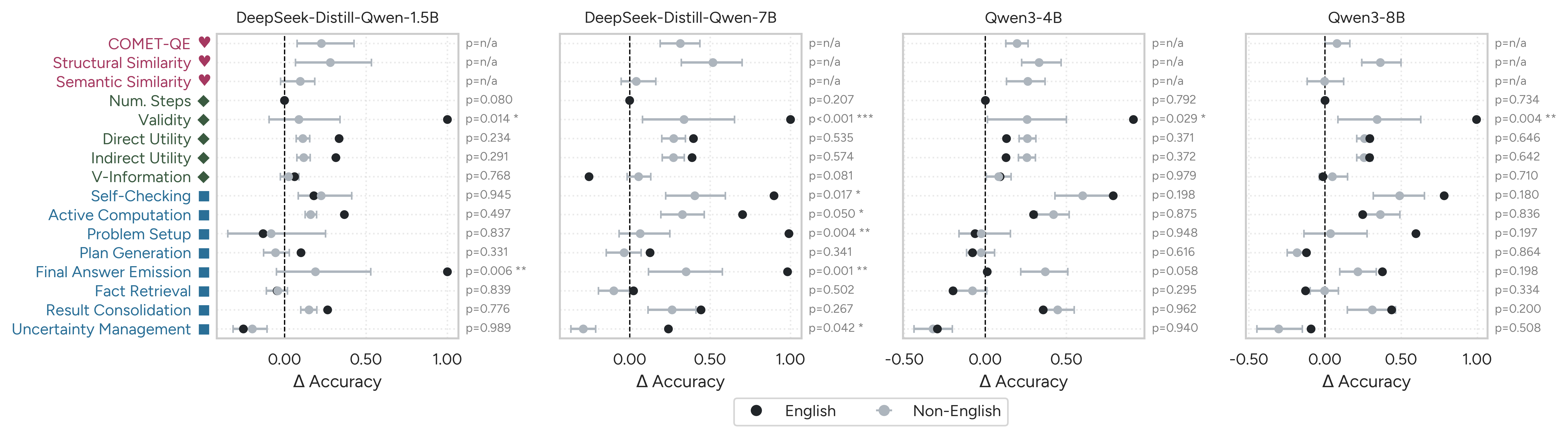
Figure 2: Comparative feature analysis results for English and non-English traces, highlighting cross-lingual variability in feature effect sizes.
Per-language decomposition reveals stronger conflicts: e.g., self-checking boosts ΔAcc in English but penalizes accuracy in Swahili and Telugu, and final answer emission steps are advantageous in English but detrimental for some languages on AIME.
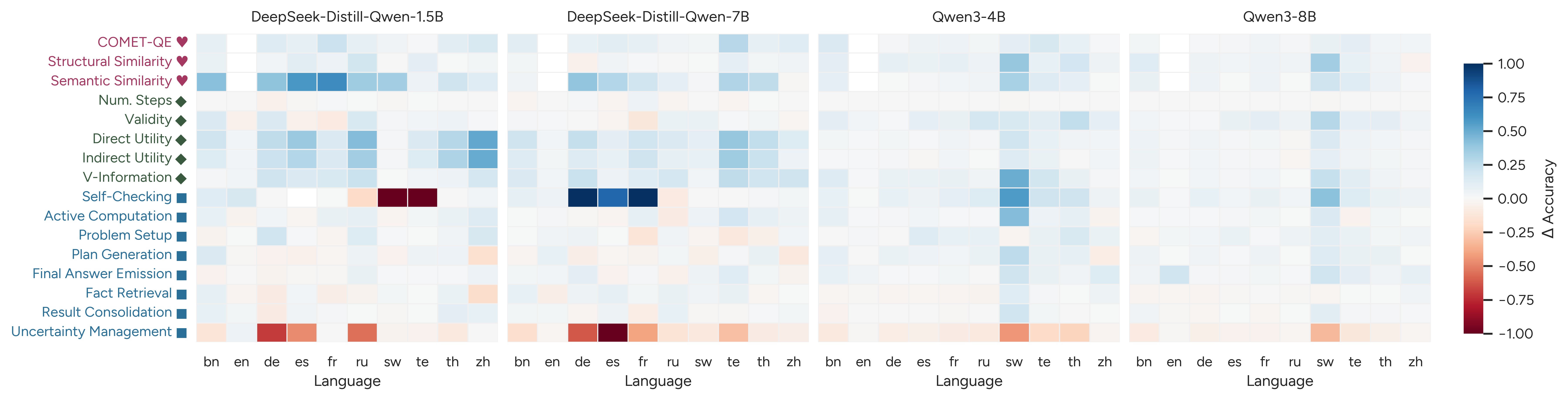
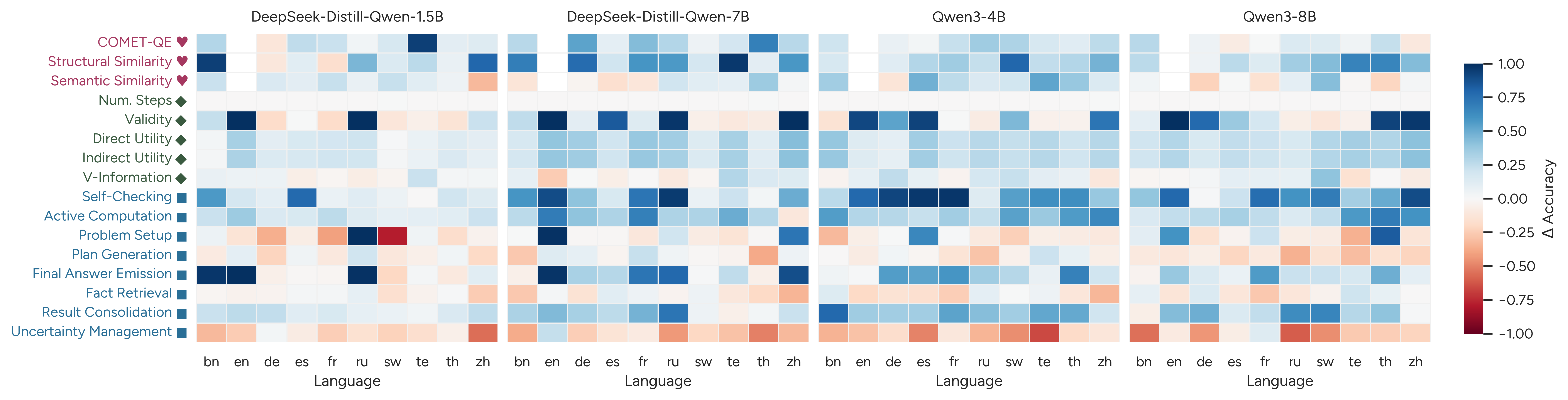
Figure 3: Per-language feature analysis results, exposing language-specific divergences in feature-accuracy relationships.
SAE Concept Discovery
SAEs not only corroborate feature-defined behaviors—e.g., preferred deduction structures or penalty for language-mixing—but also uncover latent concepts, such as ordinal breakdowns in Chinese traces or translation-error discussion behaviors in Bengali, that strongly associate with accuracy differentials.
Trace Selection and Policy Evaluation
The utility of features as selection policies is benchmarked:
Implications and Discussion
The analysis directly challenges the universality of English-centric reward and trace alignment objectives. The findings advocate for adaptive, language-aware benchmark and reward designs, emphasizing:
- The crucial role of per-language translation quality (COMET-QE) in benchmark construction.
- The transferability of reasoning step quality metrics (especially utility) across languages, supporting their adoption in language-agnostic evaluation and reward models.
- The inadequacy of semantic similarity to English as a sole reward objective; step and flow features often yield stronger accuracy improvements.
- The necessity for flexible reward and selection strategies that accommodate cross-lingual conflicts in feature effect sizes, leveraging adaptive reasoning and trace selection mechanisms.
Limitations
The study is constrained to mathematical benchmarks, four LRMs, and relies on GPT-4o for step annotation and dependency labeling. While human verification shows substantial agreement, future work should explore broader domains, additional architectures, and more extensive human/Machine annotation validation.
Conclusion
This paper delivers a systematic, feature-driven investigation into the dynamics of multilingual reasoning in LRMs, exposing cross-lingual variability and conflict in the effectiveness of reasoning features. English-centric reasoning paradigms are empirically challenged, and alternative reward signals—grounded in step utility and reasoning flow—are shown to offer stronger, language-adaptive performance improvements. The implications span benchmark design, evaluation methodology, and RL reward modeling, opening paths for more nuanced, robust, and generalizable multilingual reasoning capabilities in AI systems.