- The paper demonstrates that LRMs reasoning in English yield higher final-answer accuracy but introduce significant translation-induced errors for low-resource languages.
- The study systematically evaluates multilingual performance using MGSM and GPQA Diamond benchmarks with controlled reasoning language prompts.
- The paper highlights differing cognitive behaviors in reasoning traces, underscoring the need for tailored model designs and richer native-language datasets.
The Reasoning Lingua Franca: A Double-Edged Sword for Multilingual AI
Introduction
This paper presents a systematic evaluation of Large Reasoning Models (LRMs) in multilingual settings, focusing on the language of reasoning traces and its impact on both answer accuracy and cognitive behaviors. The central hypothesis is that LRMs, when presented with non-English questions, tend to default to reasoning in English, which may yield higher accuracy but risks losing linguistic and cultural nuances. The study leverages two benchmarks—MGSM and GPQA Diamond—across a diverse set of languages and open-weight models, quantifying the trade-offs between reasoning in English and the question’s native language.
Experimental Design and Methodology
The evaluation framework is built on explicit control of the reasoning language via system prompts and prefix tokens, ensuring that models reason either in English or the question’s language. The MGSM dataset covers mathematical reasoning in 13 languages, while GPQA Diamond targets expert-level scientific questions in English, Danish, and five Indic languages. Models are sampled with T=0.6, p=0.95, k=20, and each configuration is run four times to report mean and standard deviation. Reasoning traces are extracted and analyzed for cognitive attributes using gpt-4o-mini as an automated judge.
Final Answer Accuracy: English vs. Native Language Reasoning
Empirical results demonstrate that reasoning in English consistently yields higher final-answer accuracy, especially as task complexity increases and for high-resource languages. The performance gap widens for low-resource languages, indicating that the models’ internal knowledge and reasoning capabilities are more effectively leveraged in English.
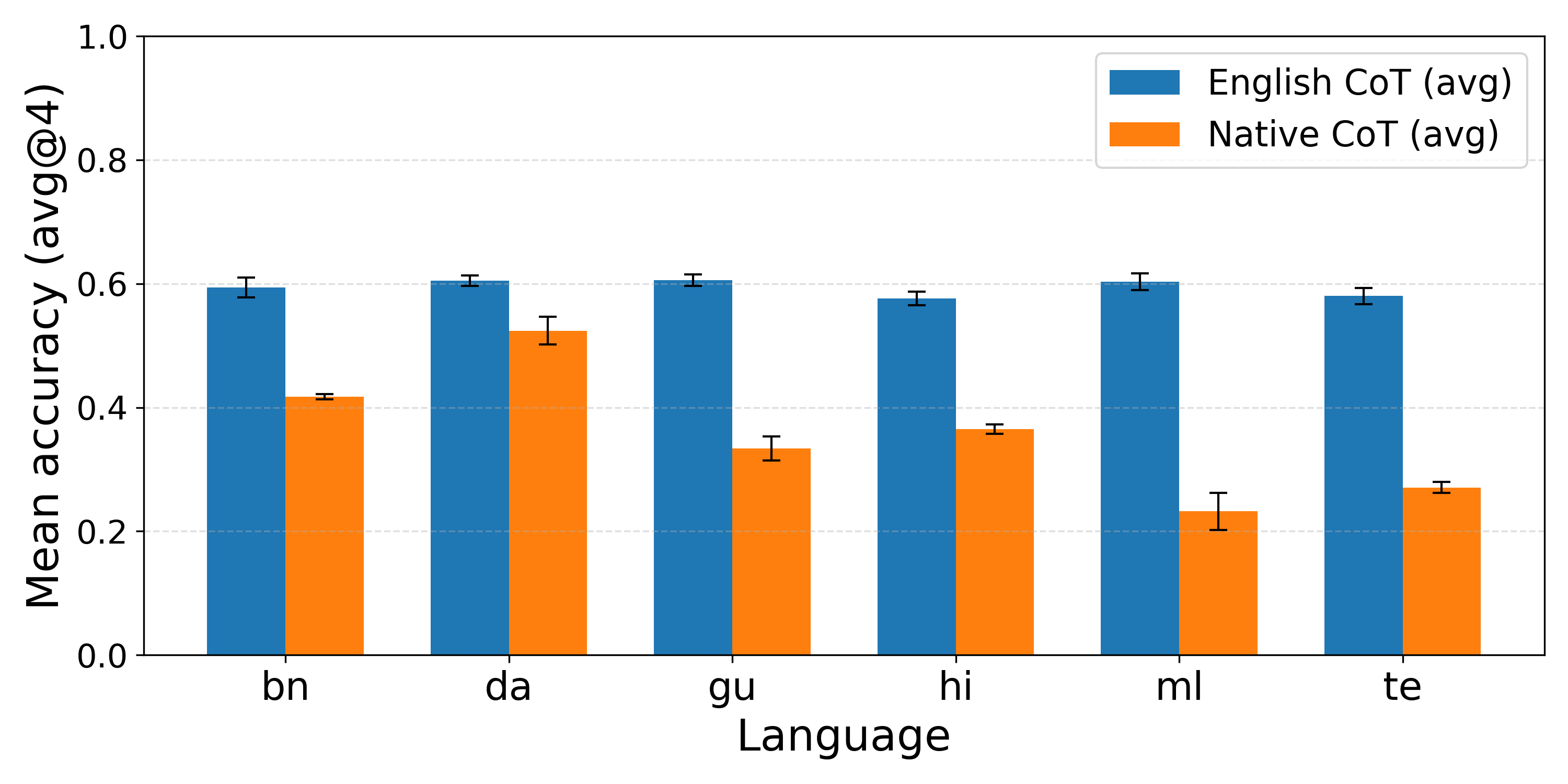
Figure 2: MGSM final answer accuracy when reasoning in the question’s language across models and languages.
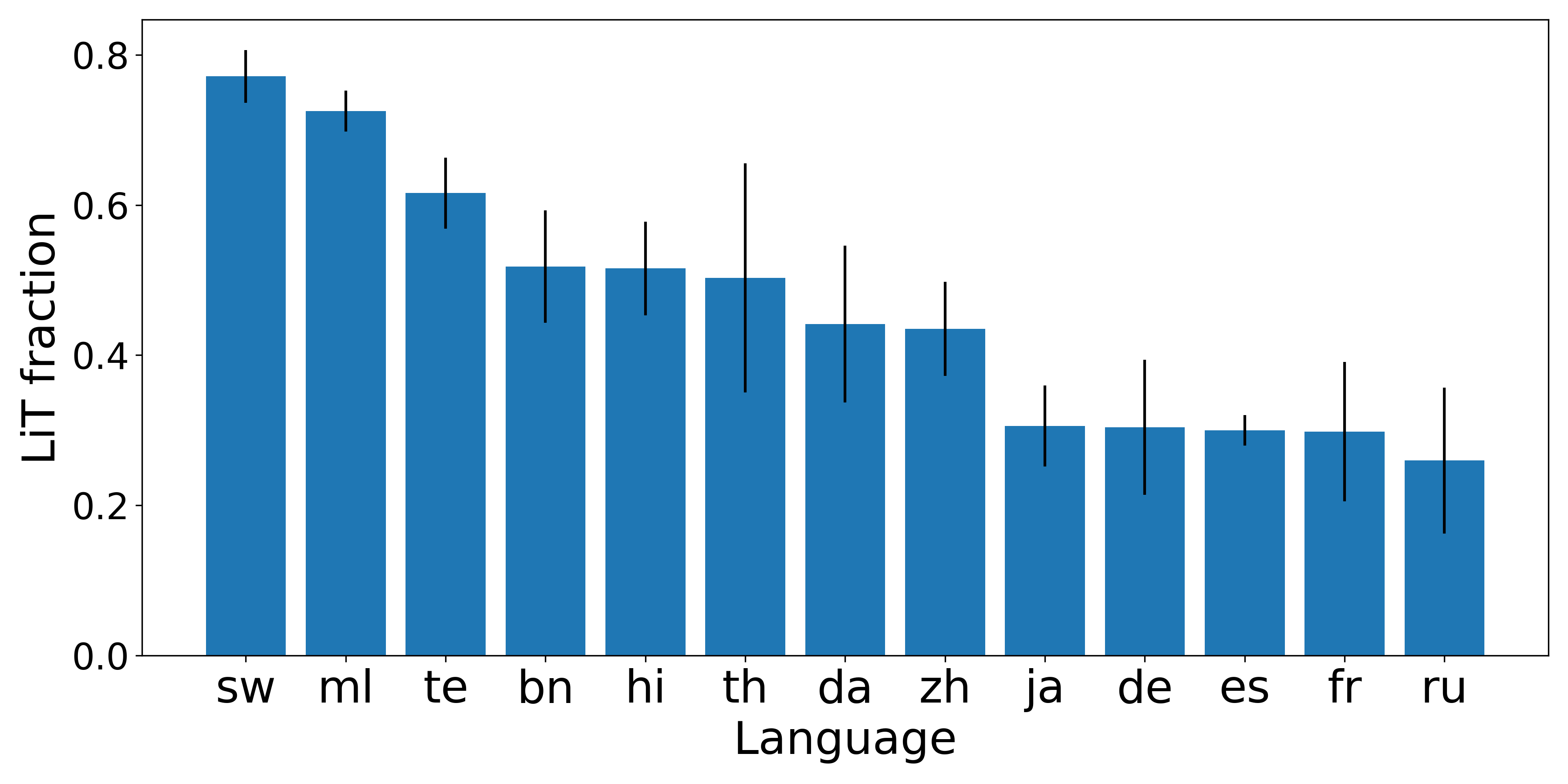
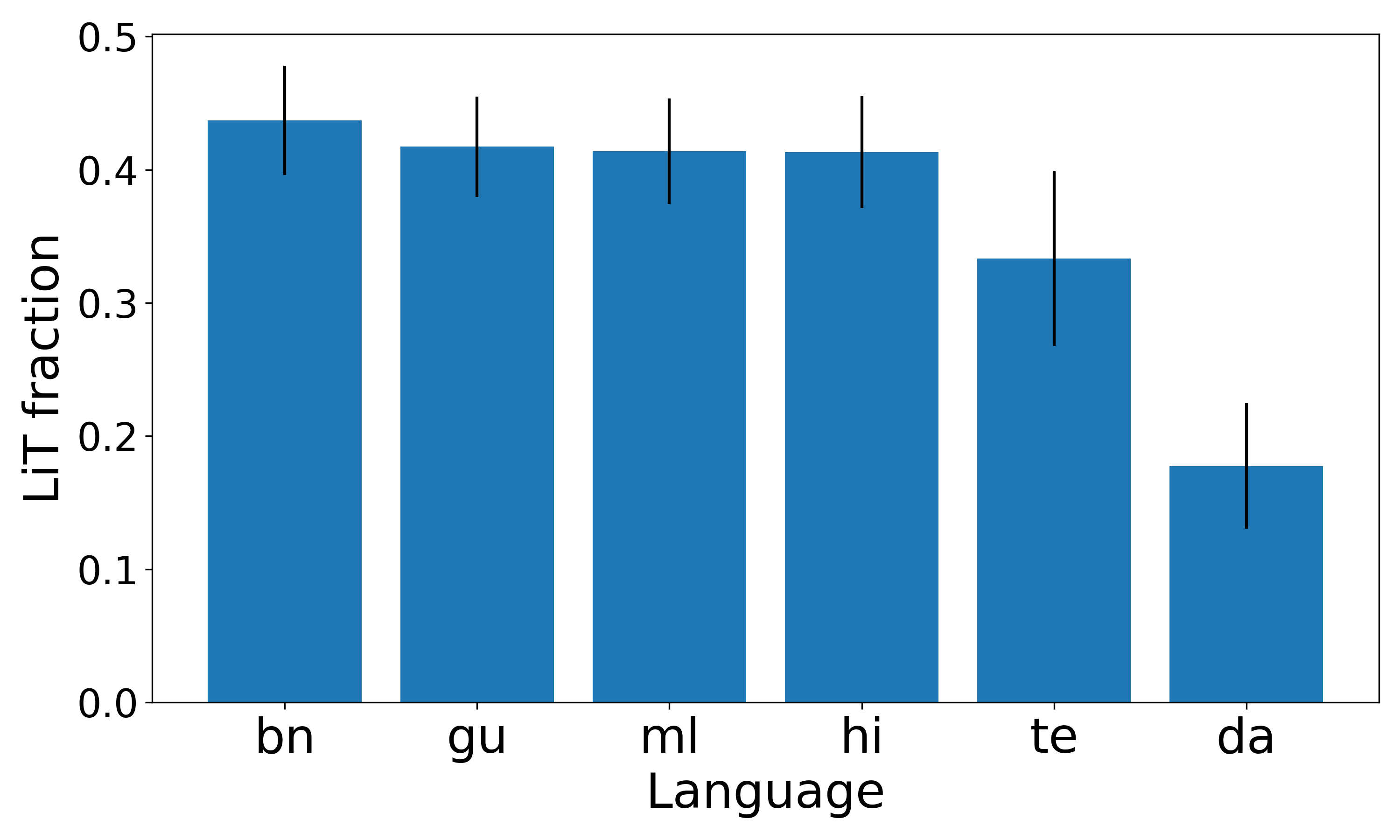
Figure 1: MGSM final answer accuracy heatmap, highlighting the decline in performance for low-resource languages.
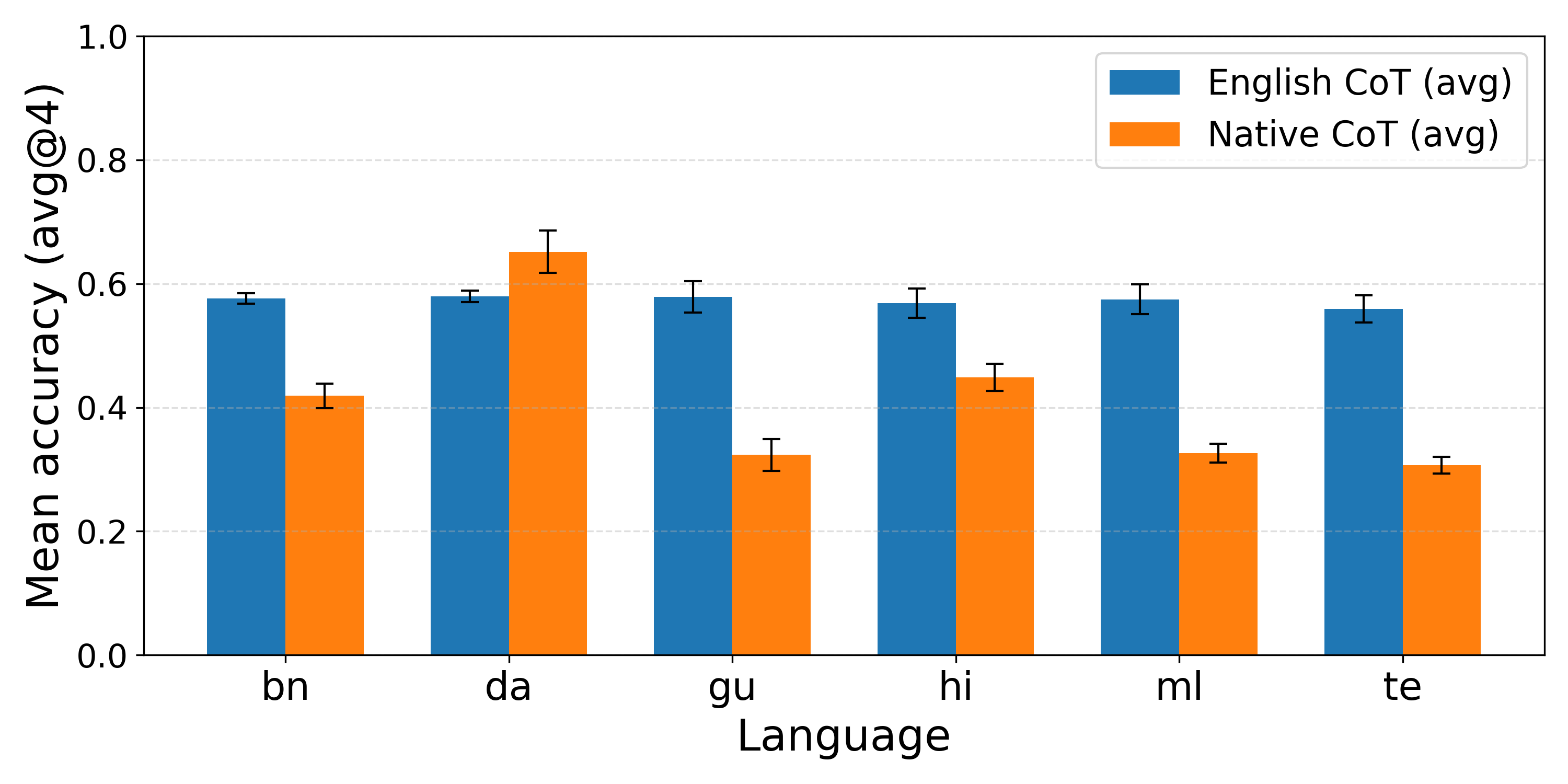
Figure 5: MGSM final answer accuracy for additional models, reinforcing the English advantage.
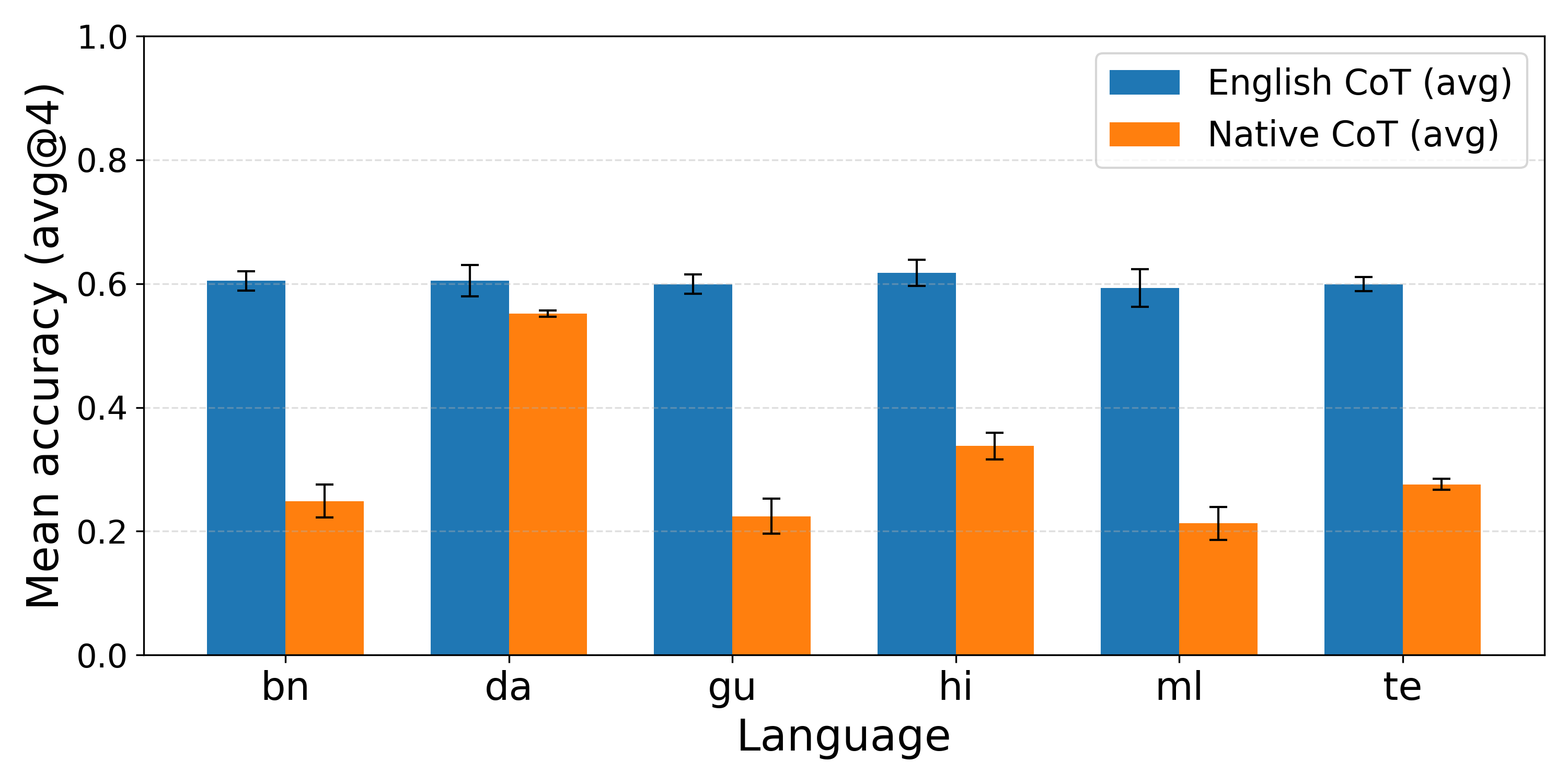
Figure 7: MGSM final answer accuracy for DeepSeek-R1-Distill-Llama-70B, showing similar trends.
For the GPQA Diamond task, which requires advanced domain knowledge, the contrast is even more pronounced. Danish, a high-resource language, exhibits a smaller gap, but all low-resource languages show substantial deficits when reasoning is forced in the question’s language.
Cognitive Behaviors in Reasoning Traces
Beyond answer accuracy, the study quantifies the presence of cognitive behaviors—subgoal setting, verification, backtracking, and backward chaining—in reasoning traces. These behaviors are more prevalent in English reasoning, correlating with higher accuracy. Notably, subgoal setting and verification are somewhat more frequent in native-language traces, but backtracking and backward chaining are significantly reduced.
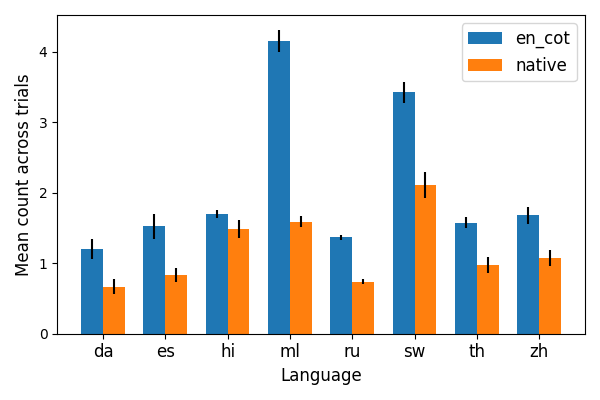
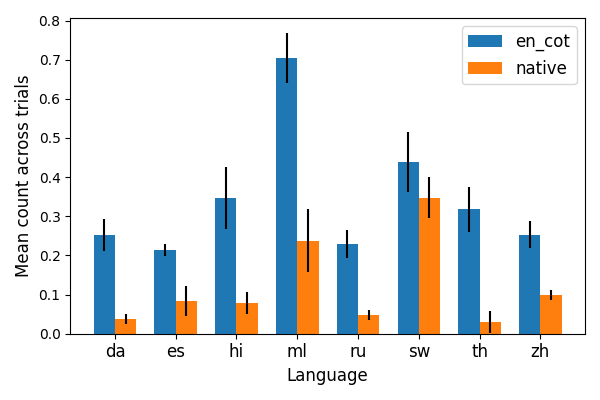
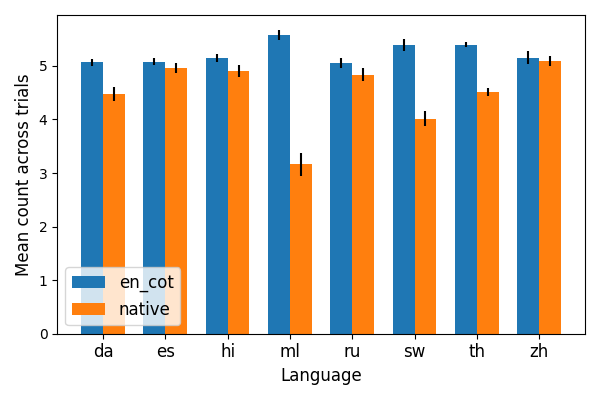
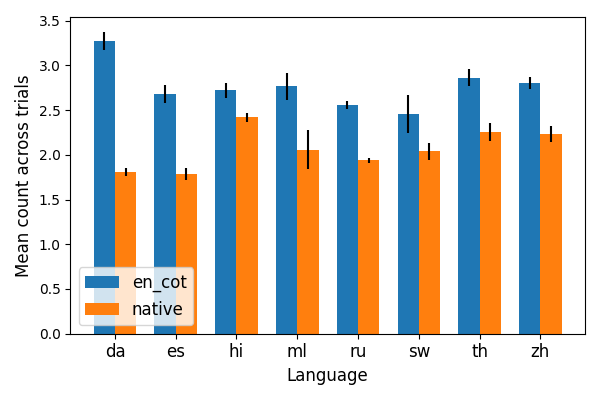
Figure 3: Frequency of backtracking in reasoning traces, with English traces showing higher prevalence.
The "Lost in Translation" Phenomenon
A critical failure mode is identified: translation-induced errors when reasoning in English. The “Lost in Translation” effect is quantified by measuring the fraction of incorrect answers attributable to mistranslation. This fraction is highest in low-resource languages (up to 0.77 for MGSM), indicating that direct native-language reasoning can outperform English reasoning in scenarios where translation distorts key information.

Figure 9: Example of "Lost in Translation"—English reasoning trace contains a critical error due to mistranslation, while the native Hindi trace is correct.
Implications and Future Directions
The findings have several practical and theoretical implications:
- Model Design: Current LRMs are optimized for English-centric reasoning, which is insufficient for robust multilingual performance. There is a need for architectures and training objectives that preserve language-specific reasoning patterns.
- Dataset Construction: High-quality, diverse datasets in low-resource languages are essential to mitigate the translation bottleneck and improve native-language reasoning.
- Evaluation Protocols: Benchmarking must move beyond answer accuracy to include cognitive behaviors and error analysis, especially for translation-induced failures.
- Deployment: For real-world applications in multilingual contexts, reliance on English reasoning may compromise interpretability and correctness, particularly in domains where cultural or linguistic nuances are critical.
Conclusion
This study provides a rigorous empirical diagnosis of the limitations of English-centric reasoning in LRMs. While reasoning in English generally yields higher accuracy and richer cognitive behaviors, it introduces a systemic vulnerability to translation errors, especially in low-resource languages. Achieving reliable native-language reasoning will require targeted research in model training, dataset curation, and evaluation methodologies. The baselines and analyses established here offer a foundation for future work in advancing multilingual AI reasoning capabilities.

