- The paper presents transcoder adapters that approximate the differences in MLP computations induced by reasoning fine-tuning through sparse corrections.
- The methodology leverages KL divergence, NMSE, and L1 sparsity to ensure faithful reconstruction of internal states and outputs across transformer layers.
- Empirical results demonstrate that the adapters recover up to 90% of fine-tuning accuracy while allowing controlled modifications of reasoning behaviors such as hesitation.
Transcoder Adapters for Reasoning-Model Diffing: A Technical Analysis
Introduction
Reasoning models have become integral to LLMs, yet the internal ramifications of reasoning-specific fine-tuning remain only partially understood. "Transcoder Adapters for Reasoning-Model Diffing" (2602.20904) systematically addresses this gap by introducing transcoder adapters, a class of sparse, interpretable modules that directly approximate the changes in MLP (feedforward) computation induced by fine-tuning. The study focuses both on validating these adapters in terms of faithfulness and interpretability and leveraging them to dissect the mechanistic effects of reasoning fine-tuning, with a detailed focus on model behaviors like hesitation.
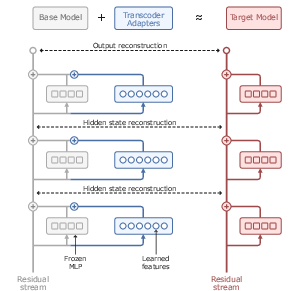
Figure 1: Transcoder adapters architecturally model the sparse difference in MLP computation between base and fine-tuned models, reconstructing both internal states and outputs.
Methodological Advances: Transcoder Adapters
The paper extends recent developments in sparse dictionary learning and SAE-derivatives by proposing adapters that are trained to reconstruct the difference in MLP computation between a base model and its fine-tuned counterpart. Specifically, at every transformer layer ℓ, a transcoder adapter runs in parallel to the MLP, receiving the same input and outputting a sparse correction. Only the adapters are trained, while all other parameters are frozen, with objectives enforcing output and internal state reconstruction (via KL and NMSE losses), as well as sparsity (L1 penalization). The adapters are evaluated between Qwen2.5-Math-7B and DeepSeek-R1-Distill-Qwen-7B.
This delta-focused architecture sharply contrasts with methods that attempt to reconstruct the entire MLP computation, enabling significantly sparser and more interpretable feature sets. Importantly, each learned feature is intrinsically tied to a change resulting from reasoning model fine-tuning, decoupling base model computation from fine-tuning effects.
Empirical Evaluation
Faithfulness to Model Behavior and Internals
Transcoder adapters achieve high fidelity both in output predictions and the reconstruction of target model activations. Even at extreme sparsity (L0 as low as 0.1–10, meaning only a handful of features are active per token/layer), adapters closely approach the performance of an MLP fine-tuning upper bound.
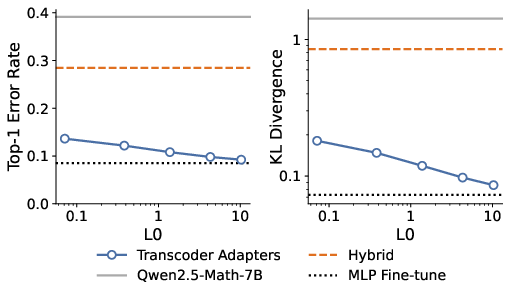
Figure 2: Transcoder adapters achieve low top-1 error and KL divergence with high sparsity, outperforming full-parameter baselines.
Internal state faithfulness is confirmed via NMSE and replacement layer KL studies: error is not compounded through the stack, and adapters act locally rather than accumulating compounding mismatches.
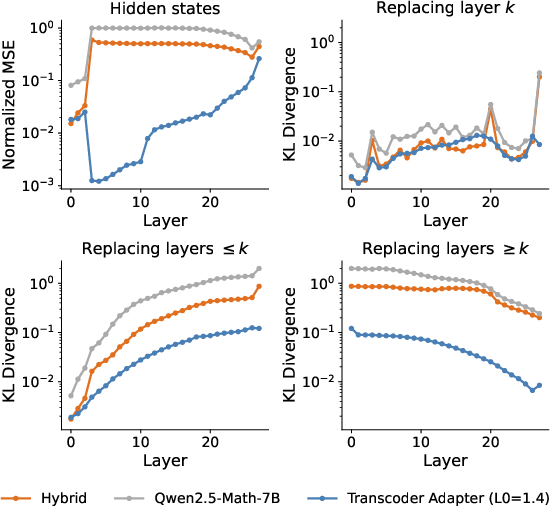
Figure 3: Adapters reconstruct internal states with low NMSE; KL divergence plateaus with full replacement, indicating errors do not cascade.
Adapters are evaluated on a suite of reasoning and academic benchmarks. They precisely match fine-tuned model response lengths (a known behavioral signature of reasoning models) and recover 50–90% of the accuracy boost achieved by fine-tuning. The residual gap saturates the corresponding MLP fine-tuning “skyline,” indicating that limits are likely due to data or non-MLP parameter changes, not adapter expressivity.
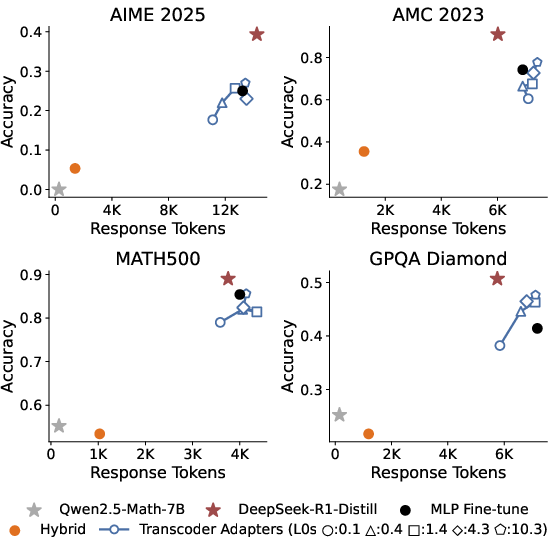
Figure 4: Adapters recover most accuracy and response length improvements of reasoning fine-tuning, matching the MLP fine-tune baseline—hybrid models limited by attention/embedding non-MLP parameters.
Interpretability and Feature Classification
Feature Structure and Interpretation
Automated and LLM-based evaluations demonstrate that transcoder adapter features are substantially more interpretable than baseline MLP neurons. Max-activating feature detection accuracy exceeds 0.82, indicating clear semantic roles for highly activating directions.
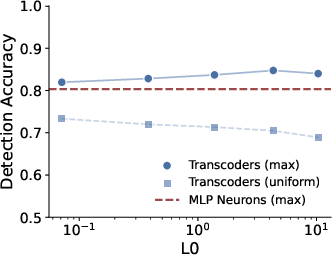
Figure 5: Automated interpretability—adapters outperform MLP neurons on max-activation-based detection tasks.
Manual and LLM-based classification reveals that only ~8% of features are linked to reasoning-specific behavior (e.g., tokens like “wait”, backtracking, self-correction), while the majority encode domain-specific (math/science/code) or general linguistic content. This result quantitatively argues that reasoning fine-tuning predominantly amplifies domain breadth rather than inducing large-scale mechanistic overhaul.
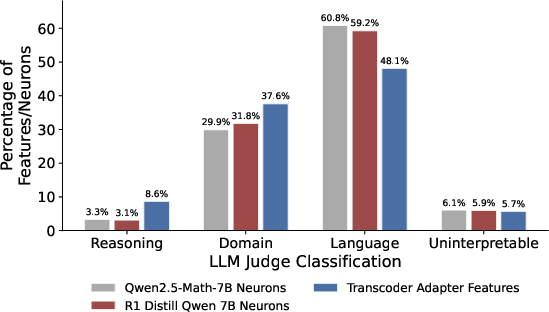
Figure 6: More transcoder adapter features are reasoning-specific or domain-specific relative to base/fine-tuned model neurons.
Mechanistic Analysis of Reasoning Behaviors
Case Study: Hesitation and Response Length
A detailed study using attribution graphs isolates the computation leading to hesitation tokens (e.g., "Wait"), a hallmark of reasoning model reasoning traces. Hesitation output and template features comprise only ~2.4% of adapter features but are both necessary and sufficient for producing hesitation, as shown by targeted ablation and addition.
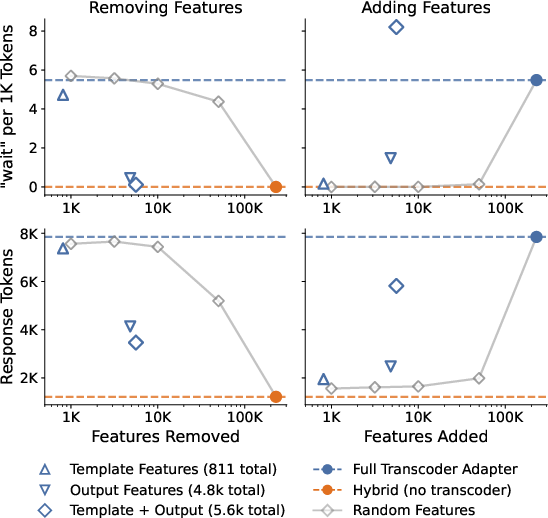
Figure 7: Removing hesitation features significantly reduces “Wait” frequency and shortens responses; adding them reproducibly induces hesitation.
Suppression of these features in both the adapter and the underlying fine-tuned network reduces response verbosity without uniformly harming accuracy, suggesting that fine-tuning modularizes reasoning-specific behaviors in a compact, interpretable way.
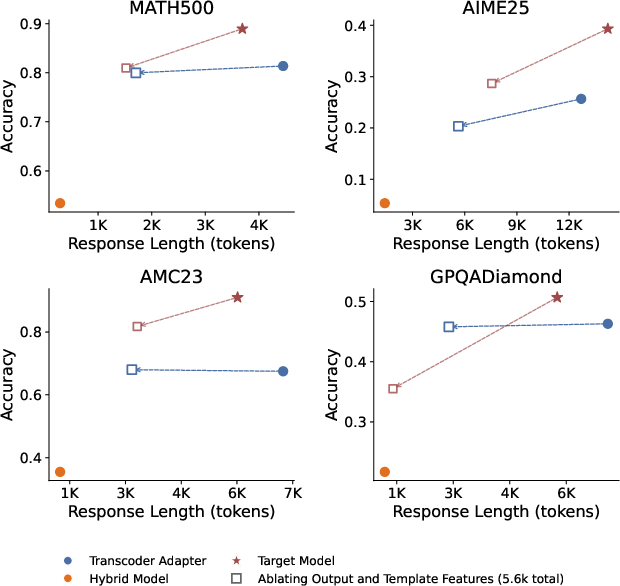
Figure 8: Suppressing hesitation features substantially decreases response length while accuracy remains stable in three of four benchmarks.
Implications and Future Directions
Practical Impact: Transcoder adapters offer an operationally efficient and interpretable method to localize and study the effects of fine-tuning in LLMs. They enable precise behavioral editing (e.g., modifying reasoning verbosity without damaging accuracy) and foster analysis-driven model steering.
Generalization and Theoretical Insights: The finding that only a minority of fine-tuning-induced features are genuinely reasoning-centric suggests that most reasoning training reinforces or imports domain knowledge into model representations, not fundamentally novel mechanistic routines. This aligns with recent studies identifying the plasticity of latent representations and minimal parameter interventions that can elicit reasoning behaviors ["Rank-1 LoRAs Encode Interpretable Reasoning Signals" (Ward et al., 10 Nov 2025), "Who Reasons in the LLMs?" (Shao et al., 27 May 2025)].
Open Challenges: Adapter coverage is limited to MLP-modifiable computation. Non-MLP changes (notably attention) are not decomposed; recent sparse/low-rank attention analysis (He et al., 29 Apr 2025) is a promising direction. Robust cross-model and cross-training-stage application remains to be charted, as do potential roles in detecting or correcting misalignment and unanticipated behaviors.
Conclusion
Transcoder adapters constitute a powerful, interpretable methodology for dissecting the effects of fine-tuning in LLMs, particularly for reasoning tasks. The approach is distinguished by its sparsity, high faithfulness, and ability to directly map behavioral phenomena to tractable feature edits. These adapters reveal that the majority of fine-tuning impact lies outside of core reasoning circuits, emphasizing the primacy of domain knowledge acquisition. As such, transcoder adapters broaden the interpretability toolkit for LLM research, enabling targeted, mechanistic interventions and setting the stage for future generalization to non-MLP and cross-model interventions.