FlashSAC: Fast and Stable Off-Policy Reinforcement Learning for High-Dimensional Robot Control
Abstract: Reinforcement learning (RL) is a core approach for robot control when expert demonstrations are unavailable. On-policy methods such as Proximal Policy Optimization (PPO) are widely used for their stability, but their reliance on narrowly distributed on-policy data limits accurate policy evaluation in high-dimensional state and action spaces. Off-policy methods can overcome this limitation by learning from a broader state-action distribution, yet suffer from slow convergence and instability, as fitting a value function over diverse data requires many gradient updates, causing critic errors to accumulate through bootstrapping. We present FlashSAC, a fast and stable off-policy RL algorithm built on Soft Actor-Critic. Motivated by scaling laws observed in supervised learning, FlashSAC sharply reduces gradient updates while compensating with larger models and higher data throughput. To maintain stability at increased scale, FlashSAC explicitly bounds weight, feature, and gradient norms, curbing critic error accumulation. Across over 60 tasks in 10 simulators, FlashSAC consistently outperforms PPO and strong off-policy baselines in both final performance and training efficiency, with the largest gains on high-dimensional tasks such as dexterous manipulation. In sim-to-real humanoid locomotion, FlashSAC reduces training time from hours to minutes, demonstrating the promise of off-policy RL for sim-to-real transfer.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces FlashSAC, a new way to train robots using reinforcement learning (RL) that is both fast and stable, especially for hard tasks like making humanoid robots walk or teaching robot hands to manipulate objects. It’s built on a popular RL method called Soft Actor-Critic (SAC) and is designed to learn well even when the robot’s world has many moving parts (high-dimensional state and action spaces).
What questions did the researchers ask?
The researchers focused on three simple questions:
- How can we make off-policy RL (which reuses past experience) train faster without becoming unstable?
- Can we make off-policy RL work better than popular on-policy methods (like PPO) on complex, high-dimensional robot tasks?
- Will this approach also work in the real world, not just in simulation (sim-to-real transfer)?
How did they try to solve it?
They combined a few big ideas so the robot can learn quickly and safely:
- Learn from more kinds of experiences (off-policy)
- Think of on-policy as learning only from today’s homework. Off-policy also studies your old notes. This gives broader and richer practice, which matters when tasks are complicated.
- Bigger brain, fewer updates, more data
- Instead of making tiny learning steps all the time, FlashSAC makes fewer but more meaningful steps using larger neural networks and larger batches of data. This is like carrying more books in a bigger backpack so you need fewer trips.
- Keep learning stable with “speed limits”
- In RL, the robot has a “critic” that judges how good actions are. If the critic’s mistakes feed into its next guesses, errors can snowball.
- FlashSAC puts “speed limits” on learning by keeping key values (weights, features, and gradients) within healthy ranges. This reduces wild swings and keeps the critic from getting confused.
Here are the main pieces, explained in everyday terms:
- Massive parallel practice
- They run 1,024 simulations at once to collect lots of varied experiences quickly.
- Big replay buffer
- A replay buffer is a memory bank. FlashSAC’s is very large (up to 10 million steps), so it doesn’t forget rare but important situations.
- Larger models and larger batches, but fewer updates
- Bigger networks (about 2.5 million parameters) and big batch sizes (2,048) get more from each learning step, so they can do fewer steps overall and still learn faster.
- Stabilizers to prevent error snowballs
- Smarter network blocks and normalization layers keep signals well-scaled.
- A “distributional critic” predicts a range of possible outcomes, not just one number, making learning smoother and less sensitive to noise.
- Weight normalization keeps the network from growing unstable values.
- Special handling of batches ensures the critic’s targets and predictions are compared fairly.
- Better exploration without tricky tuning
- A simple rule makes the robot explore at a consistent level, no matter how many action dimensions it has.
- “Noise repetition” repeats a small bit of randomness for a few steps, creating purposeful, stick-with-it exploration instead of jittery, useless wiggles.
What did they find, and why is it important?
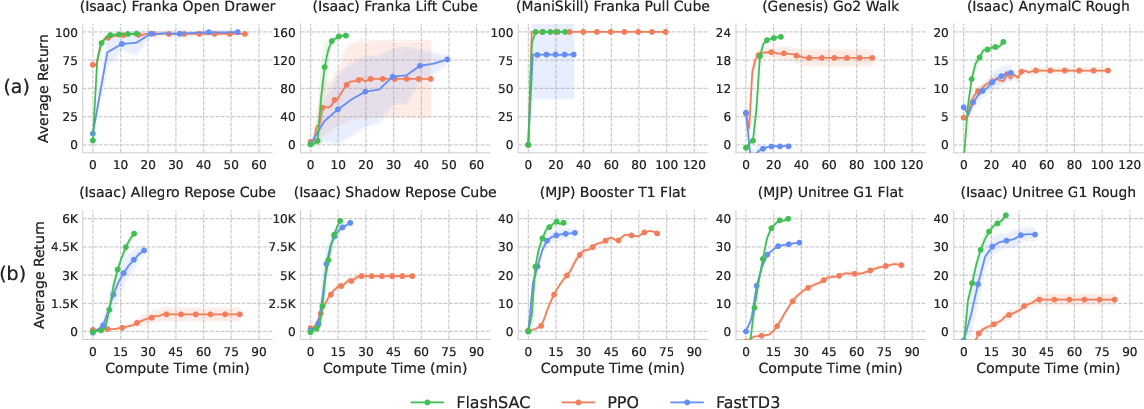
Across more than 60 tasks in 10 simulators:
- FlashSAC consistently beat PPO (a popular on-policy method) and strong off-policy baselines.
- The biggest wins were on hard, high-dimensional tasks like dexterous manipulation and humanoid locomotion.
- It trained faster in real time (wall-clock), not just in number of steps.
Real-world highlight (sim-to-real):
- On a Unitree G1 humanoid robot, FlashSAC learned walking in minutes instead of hours with PPO.
- On rough terrain (like stairs), FlashSAC reached success in about 4 hours versus nearly 20 hours for PPO.
Why this matters:
- High-dimensional robot tasks are the future (humanoids, dexterous hands, vision-based control). On-policy methods struggle here because they throw away old data and need tons of fresh experience.
- FlashSAC shows off-policy RL can be both stable and fast, making these complex tasks much more practical.
What does this mean for the future?
- Faster learning: Robots can be trained in less time, saving compute and money.
- Tougher tasks: More complex skills (humanoids walking, hands manipulating, vision-based control) become more reachable.
- Better sim-to-real: More robust transfer from simulation to physical robots means safer, quicker real-world deployment.
- More flexible data: Off-policy methods can mix demonstrations and self-play, and can benefit from slower, more realistic simulators.
In short, FlashSAC suggests a promising path: reuse more experience, scale up the model and data, and keep learning stable with smart constraints. That combination can push robot learning to be both quicker and more reliable in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes the paper’s unresolved issues and concrete avenues for future research:
- Lack of theoretical guarantees: no formal analysis connecting the proposed norm constraints (weight/feature/gradient bounds, BN, RMSNorm, distributional targets) to contraction properties of the bootstrapped Bellman operator, finite-sample error bounds, or convergence rates under large-batch, low-UTD regimes.
- Sensitivity of reward scaling and distributional support: no study of bias/variance induced by adaptive reward scaling, choice of , number of atoms, or their interaction with changing reward scales across tasks.
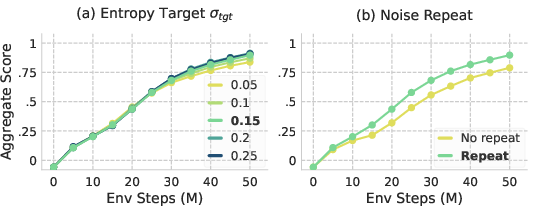
- Exploration design details under-specified: the Zeta distribution for Noise Repetition lacks an explicit exponent and cutoff; sensitivity to its parameters and control frequency is unreported, and safety impacts on real robots are unexplored.
- Unified entropy target generality: the fixed scheme is validated only for diagonal Gaussian policies; applicability to non-Gaussian policies, constrained actions, or torque-limited actuators is untested.
- Actor-side stability: constraints primarily target the critic; whether bounding policy update magnitudes (e.g., KL/trust-region penalties, adaptive step-size control) further improves stability with large batches and low UTD remains unknown.
- BatchNorm under nonstationarity: although BN is central, its behavior with small-batch, single-environment settings, policy-induced distribution drift, and evaluation-time running-stat mismatch is not systematically assessed; alternatives (GroupNorm, GhostNorm, LayerNorm with large batches) are not compared.
- Distributed/cross-device practicality: Cross-Batch Value Prediction assumes shared normalization statistics; feasibility, bandwidth cost, and correctness in distributed multi-GPU settings are unaddressed.
- Hyperparameter scaling law: the paper motivates “larger models + larger batches + fewer updates,” but does not provide a prescriptive mapping from simulator throughput and task dimensionality to batch size, UTD, learning rate, and target-update rate .
- Optimizer choice at scale: no comparison between optimizers/regularizers tailored to large-batch training (e.g., LARS, LAMB, AdamW with decoupled weight decay, adaptive gradient clipping) or analyses of stability regions for step size vs. batch size.
- Replay buffer design: 10M-transition buffers are memory-heavy; there is no evaluation of prioritized replay, reservoir/age-based sampling, recency-biased sampling, or adaptive buffer sizing to mitigate staleness and preserve long-tail experiences without slowing learning.
- Vision memory footprint: the cost of storing high-resolution observations in large replay buffers (compression, feature replay, or encoder-side caching) and its impact on throughput and performance is left unexplored.
- Vision-based generalization: results are limited to DMControl; no evaluation on real-robot RGB-D streams, cluttered manipulation, high-resolution inputs, or camera viewpoint/domain shifts, nor the effect of augmentations (e.g., DrQ/RAD) when combined with FlashSAC’s stabilizers.
- Sparse/long-horizon tasks: the method is not tested on sparse-reward or long-horizon credit-assignment benchmarks; the efficacy of Noise Repetition and entropy tuning in those settings is unclear.
- Multi-step targets and bootstrapping: beyond the 3-step returns used in vision, there is no systematic study of -step targets with the distributional critic under large batches and their stability/performance trade-offs.
- Partial observability and memory: no results with recurrent policies or belief-state estimation; applicability of the proposed stabilizers to recurrent critics/actors remains unknown.
- Continual and multi-task learning: the method is not evaluated for multi-embodiment or multi-task training; interference, normalization drift, replay curation across tasks, and whether a single entropy target scales to mixed action spaces are open.
- Offline/batch RL and demonstrations: compatibility with static datasets, mixture of demonstrations with self-collected data, and robustness to dataset shift (behavior policy mismatch) are not studied.
- Safety and constraints: no integration with control barrier functions, torque/velocity constraint handling, risk-sensitive objectives, or explicit use of the distributional critic for risk-aware control in safety-critical deployments.
- Real-time deployment constraints: inference latency, control frequency limits, CPU-only/onboard compute viability, quantization effects, and latency-induced degradation are not quantified for the 2.5M-parameter policies.
- Robustness and OOD stress-testing: generalization to disturbances (pushes, sensor dropouts), latency/jitter, partial observations, and extreme domain randomization ranges is largely unreported beyond the single G1 case.
- Sim-to-real breadth: sim-to-real is demonstrated on one platform (Unitree G1) and one class of behavior (blind locomotion); transfer to other morphologies (hands, grippers, manipulators), perception-based policies, and other terrains/tasks is untested.
- Domain randomization ablations: the contribution of each randomization factor to transfer success is not quantified; principled methods to select ranges and curricula remain open.
- Sample efficiency vs. compute: while wall-clock gains are emphasized, a unified comparison of sample efficiency (normalized by environment steps) across all benchmarks and sensitivity to UTD is incomplete.
- Failure mode analysis: when/why FastTD3 or PPO fail vs. FlashSAC is qualitatively asserted but not dissected with diagnostics (e.g., TD-error explosion, value overestimation, gradient norm blow-ups), limiting mechanistic understanding.
- Calibration of distributional values: the quality/calibration of predicted return distributions (e.g., CDF reliability, quantile accuracy) and potential for risk-sensitive control is not evaluated.
- Action saturation and exploration: potential conflicts between a fixed entropy target and action bounds/actuator limits (e.g., saturation, wear) in real robots are not analyzed.
- Extensibility to deformable/soft-body domains: applicability to contact-rich, deformable, or fluid dynamics with limited throughput (where model-based rollouts might help) is untested; hybrid model-based/model-free integration is an open direction.
- Reproducibility across hardware: stated results rely on a high-end GPU and 1024 parallel envs; performance on modest hardware, with fewer environments, or different simulator versions is not characterized.
Practical Applications
Immediate Applications
The following applications can be pursued with today’s tools and hardware, using the paper’s methods and findings largely as-is.
- Robotics (Industry): Rapid sim-to-real locomotion for humanoids and quadrupeds
- Use case: Train blind locomotion controllers (e.g., for Unitree G1) in minutes-to-hours instead of days; deploy for warehouse logistics, inspection, or security patrolling on flat and moderately rough terrain.
- Tools/products/workflows:
- FlashSAC-based training pipeline with 1024+ parallel envs, 10M replay buffer, large-batch/few-update schedule, and the stabilization stack (BN + RMSNorm + distributional critic + weight normalization + cross-batch targets).
- “Sim-to-real accelerator” workflow combining domain randomization, implicit system-ID, and terrain curricula.
- Assumptions/dependencies: High-throughput simulators (e.g., IsaacLab, Genesis, ManiSkill), robust reward functions, carefully tuned domain randomization, access to GPU(s) with sufficient memory for large batches and buffers, safe deployment practices.
- Robotics (Industry): Dexterous manipulation for assembly, reorientation, and bin picking
- Use case: Train Allegro/Shadow-hand style policies for in-hand reorientation, precise insertion, and non-prehensile regrasping where diverse replay experiences stabilize learning.
- Tools/products/workflows:
- Plug-and-play FlashSAC critic/actor into existing SAC stacks; reuse Noise Repetition for temporally coherent exploration and the unified entropy target for easier scaling across new hands/arms.
- Assumptions/dependencies: High-fidelity contact simulation, reward signals that reflect task success, and sufficient data diversity preserved by a large replay buffer.
- Robotics (R&D/Academia): Drop-in stabilization modules for off-policy RL
- Use case: Improve stability of existing off-policy baselines (SAC, TD3, etc.) on high-dimensional tasks without major re-engineering.
- Tools/products/workflows:
- “NormSafe Critic” module (weight normalization, RMSNorm, pre-activation BatchNorm, distributional Q with adaptive reward scaling).
- Cross-batch value prediction utility to align normalization stats for Q and targets.
- Assumptions/dependencies: Access to implementation-level control over normalization layers and forward passes; ability to adjust replay sampling and batch assembly.
- Software (ML Infrastructure): Wall-clock–efficient RL training configurations
- Use case: Cut training time in cloud/on-prem clusters by adopting few-update/large-batch regimes while increasing network capacity (≈2.5M params).
- Tools/products/workflows:
- JIT-compiled PyTorch training, mixed precision, high-throughput data loaders, replay servers scaled to ≥10M transitions, monitoring for critic norms and condition number proxies.
- Assumptions/dependencies: Sufficient GPU memory and I/O; simulator parallelism; robust logging to detect critic drift.
- Robotics (SMEs/Startups): Unified exploration without per-robot tuning
- Use case: Scale policies from 6-DoF arms to 29-DoF humanoids using the entropy target derived from a fixed action std (σ_tgt), avoiding task-by-task entropy tuning.
- Tools/products/workflows:
- “Unified Entropy Target” utility in RL codebases; default σ_tgt ≈ 0.15.
- Assumptions/dependencies: Gaussian policy heads with diagonal covariance; consistent reward scaling.
- Education/Academia: Course labs and benchmarks for high-dimensional RL
- Use case: Teach stable off-policy RL in large action/state spaces via replicable FlashSAC labs on IsaacLab/ManiSkill/DMC.
- Tools/products/workflows:
- Released code templates; preconfigured tasks with ablations (buffer size, batch size, UTD ratio) to illustrate scaling laws and stability.
- Assumptions/dependencies: Access to a single modern GPU for small-scale labs; smaller parallelism (reduce env count, batch) still demonstrates qualitative trends.
- Energy/Operations: Reduced compute and energy costs for robot policy training
- Use case: Lower energy footprints by converging with fewer optimizer steps and better throughput; maintain or improve asymptotic performance.
- Tools/products/workflows:
- Job schedulers that favor larger batches with fewer updates; energy telemetry for RL experiments.
- Assumptions/dependencies: Simulator parallelization, stable replay diversity; careful batch/UTD tuning.
- Healthcare (Research Labs): Faster prototyping of gait/exoskeleton controllers in simulation
- Use case: Iterate quickly on locomotion assistance policies (in sim) using FlashSAC’s stability and speed before patient-in-the-loop testing.
- Tools/products/workflows:
- Domain-randomized musculoskeletal or device simulators; replay buffers that retain rare failure modes.
- Assumptions/dependencies: High-fidelity biomechanics models; strict safety validation before human trials.
- Policy/Governance: Practical guidance and metrics for safe, efficient RL training
- Use case: Encourage practices that bound critic/gradient/feature norms and track replay diversity to reduce deployment risk in safety-critical robots.
- Tools/products/workflows:
- RL training checklists: stability controls applied; wall-clock and energy budgets; domain-randomization coverage reports.
- Assumptions/dependencies: Organizational buy-in; access to sim logs and reproducible training artifacts.
Long-Term Applications
These applications require additional research, scaling, integration, or standardization before becoming broadly feasible.
- Robotics (Consumer/Service): Generalist home robots trained via scalable off-policy RL
- Vision: Train multi-skill manipulators and humanoids (cleaning, tidying, cooking prep) using large replay buffers, diverse curricula, and multi-modal inputs.
- Tools/products/workflows:
- FlashSAC-style critic stabilization combined with vision/tactile encoders and large-scale simulation suites (digital twins of homes).
- Assumptions/dependencies: Rich perception models, reliable reward/feedback design, scalable domain randomization bridging home diversity; robust safety frameworks.
- Robotics + Foundation Models: Multi-modal policies combining FlashSAC with VLMs
- Vision: Pair norm-constrained critics with pre-trained vision-language encoders for instruction-following manipulation and mobile manipulation.
- Tools/products/workflows:
- Hybrid pipelines layering representation learning (e.g., MR.Q-style objectives) on top of FlashSAC; dataset aggregation from mixed demonstrations and self-experience.
- Assumptions/dependencies: Stable joint optimization with large encoders; sample- and compute-efficient integration.
- Digital Twins (Industry 4.0): Process and factory control via stable off-policy RL
- Vision: Replace hand-tuned controllers with policies trained in realistic digital twins (assembly lines, logistics systems) and transferred to production.
- Tools/products/workflows:
- “RL-in-the-loop” twin platforms: replay retention for rare events, norm-bounded critics to resist drift, and few-update/large-batch schedules for throughput.
- Assumptions/dependencies: High-fidelity twin models; rigorous safety constraints; interpretable policy behavior; compliance with industrial standards.
- Continuous Learning on Robot Fleets: On-device/offline off-policy updates
- Vision: Robots collect diverse experience during deployment; aggregated replay fuels periodic stable updates and fleet-wide improvements.
- Tools/products/workflows:
- Federated replay servers; schedule-driven updates using FlashSAC stability stack; anomaly/out-of-distribution detection using feature-norm monitors.
- Assumptions/dependencies: Data governance, privacy, bandwidth; robust validation before rollout; incremental deployment tooling.
- Autonomous Vehicles and Drones: Stable off-policy fine-tuning from logged data
- Vision: Use replay-heavy, norm-constrained critics to learn motion/control improvements from diverse logs, before safe on-road/on-flight validation.
- Tools/products/workflows:
- Offline-to-online RL workflows; conservative policy improvement with distributional critics for uncertainty awareness.
- Assumptions/dependencies: High-quality logs, comprehensive scenario coverage, regulatory approval, safety monitors.
- Healthcare/Assistive Devices: Personalized prosthetic/exoskeleton controllers
- Vision: Personalized policies adapted from rich replay of individual gait/EMG data, with norm constraints reducing instability during adaptation.
- Tools/products/workflows:
- Simulation-to-patient pipelines; reward shaping from clinician-defined goals; conservative on-device updates.
- Assumptions/dependencies: Accurate patient-specific simulators; strict clinical safety protocols; real-time compute constraints.
- Energy/Utilities: Process optimization with safe RL controllers
- Vision: Apply stabilized off-policy RL to energy plant setpoints, HVAC systems, or microgrid control, leveraging replay logs and digital twins.
- Tools/products/workflows:
- Norm-bounded critics to limit value overestimation; distributional Q-values for risk-aware optimization.
- Assumptions/dependencies: High-fidelity dynamics models; fail-safe overrides; regulatory compliance.
- Standards and Certification: Sim-to-real RL testing protocols
- Vision: Codify requirements (e.g., bounded norms, replay coverage metrics, energy budgets, domain-randomization disclosures) into certification processes for commercial robots.
- Tools/products/workflows:
- Auditable training reports; standardized benchmarks for high-dimensional control stability.
- Assumptions/dependencies: Industry consensus; third-party auditors; tooling to reproduce training runs.
- Education/Workforce Development: Practitioner-ready RL curricula
- Vision: Courses and certifications emphasizing stable off-policy RL in high-dimensional domains, with hands-on modules using FlashSAC-like stacks.
- Tools/products/workflows:
- Benchmark suites, assignment scaffolds, and visualization tools for condition numbers, norm tracking, and replay coverage.
- Assumptions/dependencies: Access to teaching compute; open, well-documented reference implementations.
Notes on Cross-Cutting Dependencies and Assumptions
- Simulation and Data
- Reliable, high-throughput simulators (GPU/CPU) and parallelization are pivotal to reap FlashSAC’s throughput benefits.
- Large, diverse replay buffers (≈10M) are needed to prevent catastrophic forgetting and capture long-tail events.
- Effective domain randomization and curricula are key for sim-to-real success.
- Compute and Implementation
- GPUs with sufficient memory for large batches; mixed precision and JIT can materially impact wall-clock efficiency.
- Stability stack requires careful implementation of BN (pre-activation), RMSNorm, weight normalization, cross-batch target computation, and distributional critics with adaptive reward scaling.
- Safety and Governance
- Sim-to-real deployments must include safety monitors, staged rollouts, and fallback controllers.
- For regulated domains (healthcare, energy, AVs), formal validation and compliance frameworks are necessary before deployment.
- Generalization
- While demonstrated on continuous-control robotics, the stability and scaling principles (few updates + large batches + norm constraints + distributional critics) may transfer to other high-dimensional off-policy settings, but require task-specific validation.
Glossary
- Action repeat: Executing each chosen action for multiple consecutive environment steps to reduce control frequency and training cost. "All methods are trained for 1M environment steps with an action repeat of 2."
- Action-value function: A function estimating expected return from a state–action pair, often denoted Q(s,a), used by critics in actor–critic methods. "maintaining two action-value functions and ."
- Adaptive reward scaling: Dynamically scaling rewards/returns to keep targets within a fixed support and stabilize training. "Distributional Critic with Adaptive Reward Scaling"
- Asymmetric actor–critic: A training setup where the critic receives privileged information unavailable to the actor at test time, improving learning stability. "an asymmetric actorâcritic formulation"
- Batch normalization: Normalizing activations using batch statistics to stabilize and accelerate training. "We apply batch normalization before each nonlinearity to keep activations well-scaled."
- Bootstrapped Bellman objective: A value-learning target where current estimates depend on next-state value estimates, enabling temporal-difference learning. "minimizing a bootstrapped Bellman objective,"
- Bootstrapping: Estimating targets using the model’s own predictions at future states, which can propagate and amplify errors. "causing critic errors to accumulate through bootstrapping."
- Clipped double Q-learning: Using two Q-functions and taking their minimum to reduce overestimation bias in target values. "SAC commonly employs clipped double Q-learning"
- Condition number (loss landscape): A measure of how ill-conditioned the optimization problem is; lower values generally imply more stable, faster convergence. "yielding a smoother loss landscape with a lower effective condition number"
- Cross-Batch Value Prediction: A technique to compute predictions and targets under shared normalization statistics by concatenating current and next-state batches. "Cross-Batch Value Prediction"
- Dead ReLUs: Neurons stuck at zero output due to unfavorable activation scaling, degrading gradient flow during training. "e.g., dead ReLUs"
- Distribution shift: A change between the training data distribution and the data encountered during learning or deployment, which can amplify errors. "limit error amplification under distribution shift and repeated bootstrapping,"
- Distributional critic: A value function that predicts a distribution over returns (not just the mean), typically improving stability and expressiveness. "Distributional Critic with Adaptive Reward Scaling"
- Domain randomization: Randomizing simulation parameters during training to improve robustness and transfer to real-world variations. "we apply large-scale domain randomization"
- Entropy regularization: Adding an entropy term to the objective to encourage exploration and prevent premature convergence. "Beyond maximizing expected return, SAC incorporates an entropy regularization term"
- Exponential moving average: A smoothing update for target networks where parameters are updated by blending old and new values. "which are updated via exponential moving average:"
- Extrapolation errors: Value over/under-estimation at poorly supported state–action pairs, often exacerbated off-policy. "approximation and extrapolation errors"
- Frame stacking: Providing multiple recent frames as input to capture temporal information without a recurrent model. "frame stacking of the three most recent frames"
- Game-inspired curriculum: Gradually increasing task difficulty based on performance, analogous to levels in games. "using a game-inspired curriculum"
- Importance sampling: A technique to correct for distribution mismatch between behavior and target policies by reweighting samples. "While importance sampling can, in principle, correct for policy mismatch"
- Implicit system identification: Inferring latent system parameters (e.g., dynamics) during training to adapt control policies. "implicit system identification via a context estimator"
- Inverted bottleneck: An architectural block that expands features to higher dimension before contracting, aiding expressiveness and gradient flow. "via an inverted bottleneck"
- Inverted residual block: A residual architecture that uses the inverted bottleneck pattern, improving stability and capacity. "The backbone stacks inverted residual blocks"
- JIT compilation: Just-in-time compiling model code to reduce Python overhead and improve runtime performance. "with both training and inference JIT-compiled to minimize Python overhead."
- Layer normalization: Normalizing activations across feature dimensions; contrasted with batch norm for its different statistical properties. "We choose batch normalization over layer normalization"
- Markov Decision Process (MDP): A formal framework for sequential decision making defined by states, actions, transition dynamics, rewards, and discounting. "We model robotic control as a discounted Markov Decision Process (MDP)"
- Maximum-entropy RL: An RL paradigm that augments reward with entropy to promote exploration and robustness. "Maximum-entropy RL with automatic temperature tuning encourages sustained exploration"
- Mixed-precision training: Using lower-precision arithmetic (e.g., FP16) to speed up training and reduce memory without harming convergence. "We use mixed-precision throughout training"
- Noise Repetition: Holding a sampled action-noise vector constant for multiple steps to induce temporal correlation for exploration. "We propose Noise Repetition, a lightweight alternative"
- Ornstein--Uhlenbeck noise: A temporally correlated noise process used to generate smooth exploratory actions. "Ornstein--Uhlenbeck noise"
- Pink noise: A temporally correlated noise with power inversely proportional to frequency, used for exploration. "with pink noise and Ornstein--Uhlenbeck noise being widely used."
- Projected Bellman target: A target distribution obtained by projecting bootstrapped returns onto a fixed support for distributional RL. "trained via cross-entropy loss against the projected Bellman target"
- Proximal Policy Optimization (PPO): A popular on-policy policy-gradient algorithm that stabilizes updates via clipping and surrogate objectives. "On-policy methods such as Proximal Policy Optimization (PPO) are widely used"
- Replay buffer: A memory of past transitions used to break temporal correlations and enable off-policy learning. "storing transitions in a replay buffer and reusing them across updates"
- RMSNorm: Root-mean-square normalization that scales activations by their RMS, helping to bound feature norms. "we apply RMSNorm to bound per-sample feature norms"
- Sim-to-real: Transferring policies trained in simulation to real-world hardware. "demonstrating the promise of off-policy RL for sim-to-real transfer."
- Soft Actor-Critic (SAC): An off-policy actor–critic algorithm that maximizes entropy alongside return for stable, efficient learning. "Soft Actor Critic (SAC)"
- Target entropy: A desired policy entropy level used to automatically tune the temperature in maximum-entropy RL. "requires specifying a target entropy."
- Target networks: Slowly updated copies of value networks used to stabilize bootstrapped targets. "using slowly updated target networks"
- Target update rate: The smoothing coefficient controlling how quickly target networks track the online networks. "where is the target update rate."
- Updates-to-data ratio: The number of gradient updates performed per unit of newly collected experience. "The updates-to-data ratio is set to 2/1024"
- Weight normalization: Constraining or reparameterizing weights to control their norms and stabilize optimization. "Weight Normalization"
- Zeta distribution: A heavy-tailed discrete distribution used here to sample action-noise repetition lengths. "drawn from a Zeta distribution with probability mass function "
Collections
Sign up for free to add this paper to one or more collections.

