Learning Sim-to-Real Humanoid Locomotion in 15 Minutes
Abstract: Massively parallel simulation has reduced reinforcement learning (RL) training time for robots from days to minutes. However, achieving fast and reliable sim-to-real RL for humanoid control remains difficult due to the challenges introduced by factors such as high dimensionality and domain randomization. In this work, we introduce a simple and practical recipe based on off-policy RL algorithms, i.e., FastSAC and FastTD3, that enables rapid training of humanoid locomotion policies in just 15 minutes with a single RTX 4090 GPU. Our simple recipe stabilizes off-policy RL algorithms at massive scale with thousands of parallel environments through carefully tuned design choices and minimalist reward functions. We demonstrate rapid end-to-end learning of humanoid locomotion controllers on Unitree G1 and Booster T1 robots under strong domain randomization, e.g., randomized dynamics, rough terrain, and push perturbations, as well as fast training of whole-body human-motion tracking policies. We provide videos and open-source implementation at: https://younggyo.me/fastsac-humanoid.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Learning Sim-to-Real Humanoid Locomotion in 15 Minutes”
What is this paper about?
This paper shows a fast and simple way to teach human-shaped robots (humanoids) to walk and move in the real world after learning in simulation. The big claim: they can train a walking controller in about 15 minutes on a single gaming GPU (an NVIDIA RTX 4090) and then run it on real robots.
What questions did the researchers ask?
- Can we train humanoid robots to walk and balance quickly (in minutes, not hours) using lots of simulated practice?
- Can we keep the training method simple and still make it strong enough to work on real robots, even on rough ground and when pushed?
- Can this approach handle not just walking, but “whole-body” motions like dancing or lifting?
How did they do it?
Think of training a robot like practicing in a very fast, very realistic video game before trying it in real life.
- Massively parallel simulation: They run thousands of copies of the robot at the same time in a simulator. This is like having a giant training gym with many practice fields running in parallel, so the robot learns much faster.
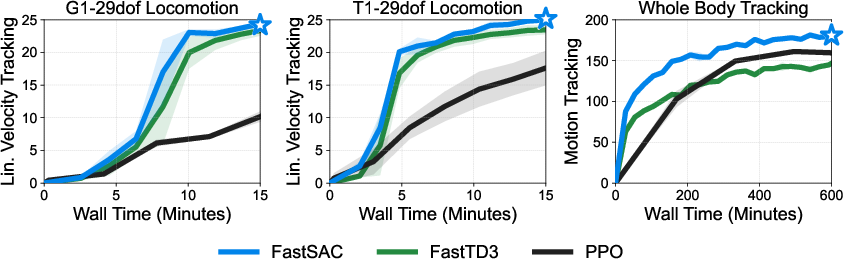
- Off-policy reinforcement learning (RL): They use two algorithms called FastSAC and FastTD3. “Off-policy” means they collect practice experiences and reuse them many times, like studying from a big notebook of past drills instead of throwing old notes away. That makes learning quicker and more efficient than many older methods (like PPO), especially when simulation is slow.
- Domain randomization: During practice, they constantly change things—like robot weight, friction, delays, ground roughness, and random pushes—so the robot doesn’t overfit to a perfect world. It’s like practicing soccer in sun, rain, and wind, on grass and turf, so you’re ready for real games.
- Simple rewards (the “rules” the robot tries to maximize): Instead of 20+ complicated scoring rules, they use fewer than 10 clear ones. For walking, the main ideas are:
- Move at the target speed and turning rate.
- Don’t fall; keep the body upright.
- Lift and place feet sensibly; avoid weird leg crossings.
- Keep joints in safe ranges and make smooth movements.
- This “minimalist” scoring system makes training more stable and easier to tune.
- Practical stabilizing tricks:
- Joint-aware action limits: They make sure the robot never asks a joint to move beyond its safe angle—like respecting how far your knee can bend.
- Normalization: They keep the numbers going into the neural network well-behaved, which helps steady learning.
- Balanced exploration: They carefully control how “curious” or “noisy” the robot’s actions are, so it explores enough without going wild.
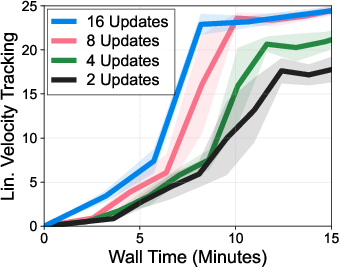
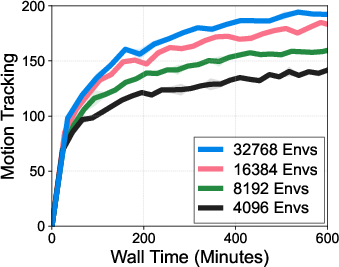
- Big batches and many updates: With thousands of simulations running, they train the neural networks using large chunks of data and more frequent updates to speed up learning.
What did they find, and why is it important?
Here are the key results:
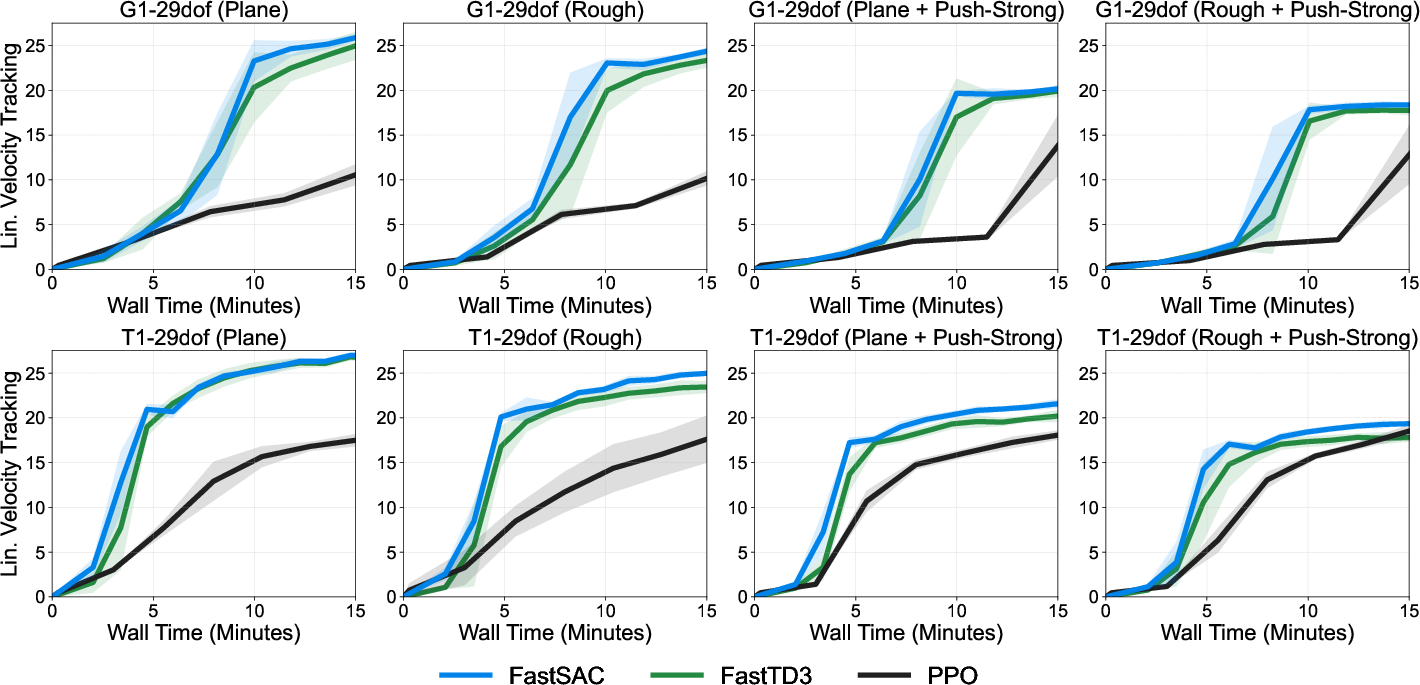
- Trains in about 15 minutes: On a single RTX 4090 GPU, their method teaches humanoids to walk and follow speed commands very quickly.
- Works on real humanoid robots: They tested on Unitree G1 and Booster T1 robots in the real world, not just in simulation.
- Robust to tough conditions: The trained robots can handle rough terrain and repeated push disturbances (pushes every 1–3 seconds in the hardest setting), and still stay balanced and follow commands.
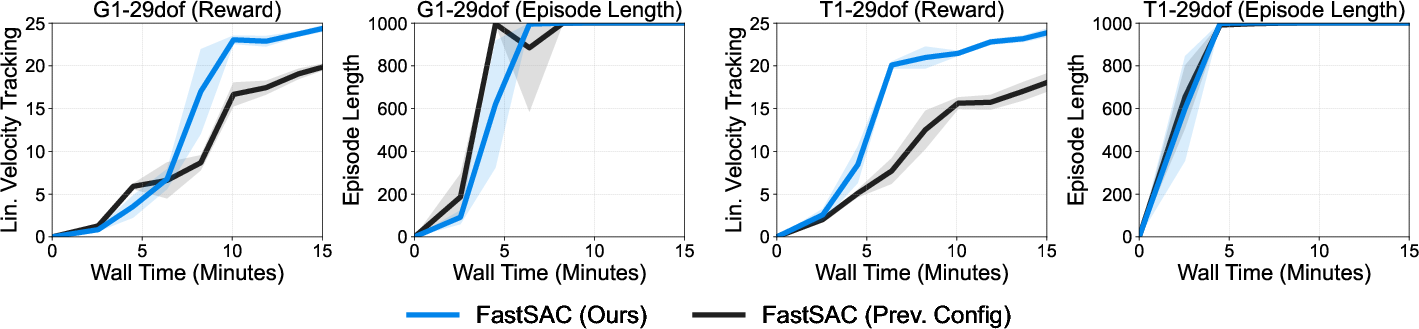
- Faster and often stronger than a popular baseline (PPO): In wall-clock time, their off-policy methods reach good performance much faster.
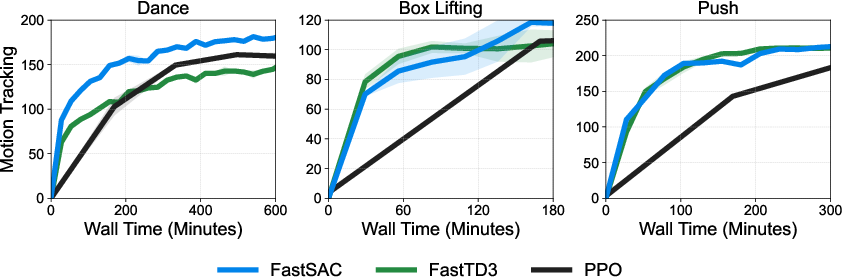
- Whole-body motion tracking: With more GPUs (4× L40s) and lots of parallel simulations, they also learned complex full-body motions (like dancing or box-lifting) faster than PPO. They showed successful transfer of these motions to a real robot.
Why this matters: Training robots in minutes instead of hours makes it much easier to iterate—try something, test it on the real robot, fix issues, and try again—until it works reliably in the real world.
What’s the bigger impact?
- Faster development cycles: Engineers and researchers can improve robot skills quickly, making real-world deployment more practical.
- Less fiddly engineering: A short, simple “recipe” with minimal reward rules means fewer delicate settings to tune and fewer ways for training to break.
- Stronger sim-to-real transfer: By practicing in many varied conditions, robots are more likely to stay stable in the real world.
- A foundation to build on: The authors open-sourced their implementation, so others can adopt and extend it. Future improvements in off-policy RL could make training even faster and more reliable.
In short, the paper provides a practical, fast, and simple recipe for teaching humanoid robots to move well in the real world—turning long, complex training into something you can do on a single PC in the time it takes to eat lunch.
Knowledge Gaps
Below is a single, focused list of unresolved knowledge gaps, limitations, and open questions left by the paper. Each point is concrete to guide follow-up research.
- Generalization beyond Unitree G1 and Booster T1: Does the recipe transfer without re-tuning to other humanoids with different morphology, actuation (e.g., series elastic), gearing, or sensor suites?
- Control-interface dependence: The joint-limit-aware action bounds are tailored to position PD control; how do they extend to torque control, impedance control, or hybrid controllers, and what mappings are needed?
- Real-world quantitative evaluation: Provide metrics beyond videos and training curves, including success rates, tracking RMSE on hardware, fall frequency, foot slip rate, energy consumption, joint/actuator temperature, and battery usage under varied tasks.
- Long-horizon robustness: Assess stability and failure modes in hour-long deployments, including drift, overheating, and cumulative wear, not just 20-second episodes or a single 2-minute sequence.
- Terrain and environment diversity: Evaluate on stairs, slopes, compliant surfaces, obstacles, partial footholds, wet/low-friction surfaces, and outdoor conditions to understand limits of current domain randomization.
- Vision and perception integration: The policies are proprioceptive; quantify how adding exteroception (e.g., vision, depth, tactile) affects robustness and sim-to-real transfer, especially on rough/obstacle-rich terrain.
- Domain randomization design: Systematically ablate individual randomizations (mass, friction, CoM, PD gains, delays, pushes) and ranges to identify which are critical for transfer; develop adaptive DR schedules that respond to training progress.
- Reward sensitivity and ablation: Perform controlled ablations to measure each reward term’s contribution and sensitivity to weights; document the curriculum schedule and analyze its effects on exploration, convergence, and sim-to-real robustness.
- Symmetry augmentation side effects: Quantify potential trade-offs (e.g., impaired turning, asymmetric maneuvers) and define conditions under which symmetry augmentation should be reduced or disabled.
- Replay buffer strategy at massive scale: Specify buffer size, replacement policy, sampling strategy (e.g., prioritized vs uniform), data freshness, and effects of mixing experiences across diverse randomized domains; evaluate stratified sampling by domain parameters.
- Off-policy stability conditions: Provide theoretical or empirical analysis of when averaging double Q-values with layer normalization outperforms clipped double Q-learning, and whether the conclusion holds across tasks and architectures.
- Distributional critic trade-offs: Investigate lighter-weight distributional methods (e.g., categorical vs quantile variants, truncated support, smaller atoms) that maintain performance with large batches while controlling compute/memory costs.
- Exploration hyperparameters: Derive or validate principled target entropy settings (as functions of action dimension and task type) and noise schedules for TD3 that generalize across locomotion and whole-body tracking.
- Action-rate curriculum specification: Detail the schedule, triggers, and magnitude of the action-rate penalty ramp; quantify its impact on smoothness, energy usage, and transfer stability.
- Real-time deployment stack: Report control frequency, sensing delays, inference latency, on-board vs off-board compute, communication channel constraints, and their measured impacts on closed-loop performance.
- Scaling on multi-GPU vs single-GPU: For whole-body tracking, clarify data-parallel vs env-parallel strategies, communication overhead, and whether similar performance can be achieved on a single GPU with tuned hyperparameters.
- Sample efficiency and throughput: Report environment steps to success, environment FPS, gradient-update ratio, and data reuse statistics to disentangle wall-clock speed from true sample efficiency.
- Policy robustness to sensor imperfections: Systematically test tolerance to joint encoder bias, latency spikes, dropped packets, IMU drift, and contact sensing errors beyond the limited joint-position bias randomization.
- Guidelines for action bounds: Provide diagnostic criteria and decision rules for switching between joint-limit-aware and unbounded action spaces to avoid torque underutilization without destabilizing training.
- Cross-task generalization: Evaluate how a learned locomotion policy performs on unseen command profiles (high-speed running, rapid yaw changes), task transitions (stand-to-walk, walk-to-run), and mixed objectives (locomotion plus manipulation).
- Whole-body tracking generalization: Test to truly novel motions not included in training, multi-contact sequences (e.g., kneeling, rolling), and dynamic object interactions with varying object mass, shape, and friction.
- Safety and failure mitigation: Define and test safety constraints (torque/velocity limits, impact thresholds), fault detection, recovery strategies, and “graceful degradation” behaviors during extreme perturbations or hardware anomalies.
- Reproducibility and variance: Report number of seeds, variance across runs, and statistical significance for all comparisons; assess sensitivity to initialization, network size, and normalization choices.
- Auto-tuning and meta-optimization: Explore automated hyperparameter tuning (e.g., population-based training, Bayesian optimization) to reduce reliance on “carefully tuned” settings and to improve portability across robots and tasks.
- Simulator fidelity and identification: Quantify the impact of contact model choice, friction/contact parameters, and compliance; integrate offline/online system identification and compare against pure DR for closing the sim-to-real gap.
- Online adaptation post-deployment: Investigate residual learning, policy adaptation, or model-based corrections on hardware to compensate for unmodeled dynamics, rather than relying solely on zero-shot DR transfer.
Glossary
- Action delay: A sim-to-real robustness technique that injects latency between policy output and actuation during training. "We apply various domain randomization techniques to further robustify sim-to-real deployment: push perturbations, action delay, PD-gain randomization, mass randomization, friction randomization, and center of mass randomization (only for G1)."
- Action-rate curriculum: A schedule that gradually increases the penalty on changes in actions to encourage smoother control as training progresses. "with randomized dynamics, rough terrain, push perturbations, and an automatic action-rate curriculum, all end-to-end in 15 minutes on a single RTX 4090 GPU."
- Adam optimizer: A stochastic gradient optimization method that adapts learning rates using first and second moment estimates. "We train FastSAC and FastTD3 using Adam optimizer \citep{kingma2014adam} with a learning rate of $0.0003$."
- Alive reward: A per-step reward that incentivizes the agent to avoid falling or entering invalid states. "A per-step alive reward that encourages remaining in valid, non-fallen states."
- C51: A distributional reinforcement learning algorithm that models the return distribution with a fixed set of atoms. "Following prior work \citep{li2023parallel,seo2025fasttd3}, we also use a distributional critic, i.e., C51 \citep{bellemare2017distributional}."
- Center of mass randomization: Varying the robot’s center of mass in simulation to improve transfer robustness. "center of mass randomization (only for G1)."
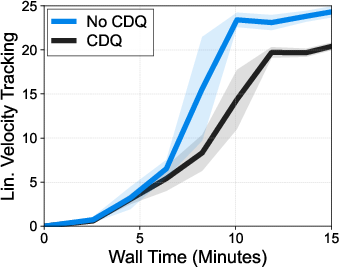
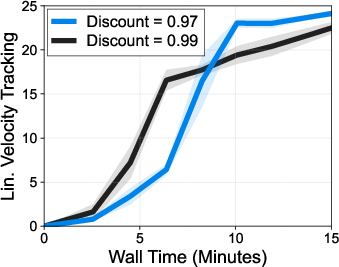
- Clipped double Q-learning (CDQ): A value estimation technique that uses the minimum of twin critics to reduce overestimation bias. "We find that using the average of Q-values improves FastSAC and FastTD3 performance over using Clipped double Q-learning (CDQ; \citealt{fujimoto2018addressing}) that uses the minimum (see \cref{fig:fig1})."
- DeepMimic-style termination conditions: A set of termination rules from the DeepMimic framework that end episodes when motion tracking diverges too far from reference. "together with DeepMimic-style termination conditions \citep{peng2018deepmimic}."
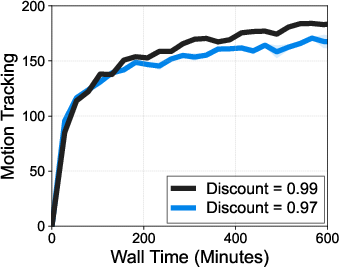
- Discount factor γ: A parameter that weights future rewards relative to immediate rewards in RL. "We investigate the effect of (d) discount factor on a Unitree G1 locomotion task with rough terrain."
- Distributional critic: A critic that models the distribution of returns rather than only the expected value. "Following prior work \citep{li2023parallel,seo2025fasttd3}, we also use a distributional critic, i.e., C51 \citep{bellemare2017distributional}."
- Domain randomization: Randomly varying simulation parameters (e.g., dynamics, friction) to bridge the sim-to-real gap. "with strong domain randomization including randomized dynamics, rough terrain, and push perturbations."
- FastSAC: A large-scale, efficient variant of Soft Actor-Critic tailored for massively parallel simulation. "we introduce a simple and practical recipe based on off-policy RL algorithms, i.e., FastSAC and FastTD3, that enables rapid training of humanoid locomotion policies in just 15 minutes"
- FastTD3: A large-scale, efficient variant of TD3 designed for stability and throughput with many parallel environments. "At the core of this recipe are FastSAC and FastTD3 \citep{seo2025fasttd3}, efficient variants of popular off-policy RL algorithms"
- Foot-height tracking term: A reward component that guides swing leg motion by tracking desired foot elevation. "A simple foot-height tracking term \citep{zakka2025mujoco,phase_rewards} to guide swing motion."
- Joint-limit-aware action bounds: Per-joint action limits derived from hardware joint limits to stabilize Tanh policies and training. "Joint-limit-aware action bounds"
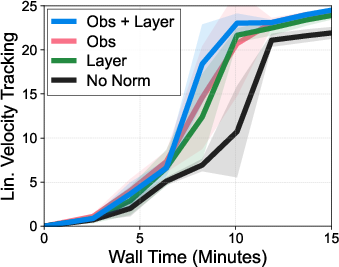
- Layer normalization: A normalization technique applied across features in a layer to stabilize and accelerate training. "we find that layer normalization \citep{ba2016layer} is helpful in stabilizing the performance in high-dimensional tasks (see \cref{fig:fig3})."
- Maximum entropy learning: An exploration strategy that augments the reward with policy entropy to encourage diverse behavior. "FastSAC, which learns how to explore environments from data with its maximum entropy learning scheme"
- Mixed noise schedule: An exploration scheme (for TD3) that samples action noise standard deviations from a range each step or episode. "we use mixed noise schedule that randomly samples Gaussian noise standard deviation from the range ."
- Observation normalization: Scaling or standardizing input observations to improve training stability. "we find that observation normalization is helpful for training."
- Off-policy reinforcement learning (off-policy RL): RL methods that learn from data collected by a behavior policy different from the current policy. "Our recipe is based on off-policy RL algorithms tuned for large-scale training with massively parallel simulation"
- On-policy reinforcement learning (on-policy RL): RL methods that learn primarily from data collected by the current policy. "off-policy RL algorithms, i.e., Soft Actor-Critic and TD3, ... faster than on-policy RL algorithms such as PPO"
- PD controller: A proportional-derivative controller mapping errors to torques for joint control. "when using PD controllers."
- PD-gain randomization: Randomizing controller gains to improve transfer robustness. "PD-gain randomization"
- Proximal Policy Optimization (PPO): A widely used on-policy RL algorithm using clipped policy updates for stability. "such as PPO \citep{schulman2017proximal} that has been a standard algorithm for sim-to-real RL"
- Push perturbations: External forces applied to the robot during training to enhance robustness. "push perturbations"
- Reparameterization trick: A technique to enable low-variance gradient estimates through stochastic nodes by reparameterizing sampling. "Update actor with reparameterization trick:"
- Replay buffer: A memory that stores transitions for sampling during training in off-policy RL. "entropy temperature , replay buffer "
- Rough terrain: Non-flat ground surfaces used in training to improve locomotion robustness. "rough terrain"
- Sim-to-real: Transferring policies trained in simulation to real robot hardware. "fast and reliable sim-to-real RL for humanoid control"
- Soft Actor-Critic (SAC): An off-policy, maximum-entropy actor-critic algorithm for continuous control. "Soft Actor-Critic \citep{haarnoja2018learning}"
- Symmetry augmentation: A data augmentation technique that leverages left-right symmetry to encourage symmetric behaviors. "We also use symmetry augmentation \citep{mittal2024symmetry} to encourage symmetric walking pattern"
- Target critics: Slowly updated copies of critic networks used to compute stable bootstrapped targets. "Initialize target critics $Q_{\phi^{target}_{1}, Q_{\phi^{target}_{2}$ with and "
- Target entropy: A hyperparameter specifying the desired policy entropy level in SAC’s entropy auto-tuning. "For the target entropy, we find that using $0.0$ (for locomotion tasks) or (for whole-body tracking tasks) works best in practice."
- Tanh policy: An action parameterization using a Tanh squashing function to enforce bounded outputs. "setting proper action bounds for its Tanh policy."
- TD3: Twin Delayed Deep Deterministic Policy Gradient, an off-policy algorithm using twin critics and delayed policy updates. "TD3 \citep{fujimoto2018addressing}"
- Temperature α: The entropy coefficient in SAC that balances reward maximization and entropy (exploration). "large initial value of the temperature "
- Velocity tracking: A locomotion objective where the robot tracks commanded linear and angular velocities. "Locomotion (velocity tracking) results."
- Weight decay: L2-style parameter regularization applied in optimization to reduce overfitting. "we find that weight decay $0.1$, which \citet{seo2025fasttd3} uses, is a too strong regularization for high-dimensional control tasks and thus we use weight decay of $0.001$."
- Whole-body tracking (WBT): Policy learning to track full-body human motions across all joints. "Effect of (WBT)"
Practical Applications
Immediate Applications
The following applications leverage the paper’s recipe (FastSAC/FastTD3, minimalist rewards, domain randomization, joint-limit-aware actions, large-batch off-policy training) and the open-source Holosoma implementation to deliver value today.
- Robotics (industrial R&D) — rapid sim-to-real iteration for humanoid locomotion
- Actionable use: Train and update full-body locomotion controllers for Unitree G1/Booster T1 (or similar humanoids) in ~15 minutes on a single RTX 4090, then deploy on hardware for immediate testing.
- Sectors: robotics, manufacturing, logistics
- Tools/workflows: Holosoma repo, FastSAC/FastTD3 configs, symmetry augmentation, action-rate curriculum, domain randomization sweeps; “train→deploy→evaluate→retrain” loop multiple times per day
- Dependencies/assumptions: Accurate robot models and PD control interfaces; GPU-based parallel simulation; safety procedures for on-hardware testing; domain randomization adequately covers real-world variability
- Robotics (field deployment) — robust gait under disturbances and terrain variability
- Actionable use: Deploy controllers trained with push perturbations and rough-terrain randomization to improve resilience in warehouses, campuses, and event venues (e.g., human interaction, mild collisions, uneven flooring).
- Sectors: security patrol, facility operations, live events
- Tools/workflows: Minimalist velocity-tracking rewards; push-strong training regimes; joint-limit-aware action bounds
- Dependencies/assumptions: Mechanical robustness; conservative safety limits and geofencing; monitoring for out-of-distribution conditions
- Entertainment and creative industries — whole-body motion tracking for choreography
- Actionable use: Train humanoids to perform dance sequences and scripted motions tracked from human actors for shows, installations, and promotional events.
- Sectors: entertainment, advertising, live performance
- Tools/workflows: FastSAC whole-body tracking with BeyondMimic-style rewards; curated motion datasets; training on 4× L40s GPUs for longer sequences
- Dependencies/assumptions: Reliable motion capture or high-quality reference datasets; rehearsals with safety checks; venue-specific compliance
- Academic research and education — reproducible baselines and faster experimentation
- Actionable use: Use the open-source recipe for replicable humanoid RL experiments, comparative algorithm studies, and course labs demonstrating sim-to-real in one session.
- Sectors: academia, education
- Tools/workflows: Holosoma; standardized reward suite; layer normalization; distributional critic (C51); large-batch off-policy training
- Dependencies/assumptions: Access to GPU simulators and a single high-end GPU; consistent curriculum settings; reproducible environment seeds
- Robotics DevOps — CI/CD for robot controllers
- Actionable use: Integrate “policy CI” into robotics stacks: automatic regression tests in simulation (terrain, pushes, friction ranges), nightly hyperparameter sweeps, and gated on-hardware rollouts.
- Sectors: software for robotics, MLOps
- Tools/workflows: Automated domain-randomization test suites; telemetry dashboards; checkpoint selection from stars in learning curves
- Dependencies/assumptions: Robust sim orchestration; on-robot logging; OTA update mechanisms; roll-back plans
- Safety and compliance engineering — rapid stress testing pre-deployment
- Actionable use: Run standardized perturbation and randomization batteries to generate safety evidence (failure rates, recovery metrics) before deployment.
- Sectors: safety engineering, risk management
- Tools/workflows: Push perturbation protocols; friction/mass/CoM randomization matrices; episode-termination and upright penalties
- Dependencies/assumptions: Agreement on test coverage; mapping from sim stressors to real-world risk scenarios; independent validation
- Hobbyist and maker communities — accessible gait training for affordable humanoids
- Actionable use: Quickly train walking/standing controllers for consumer-accessible humanoids for demos, meetups, and research clubs.
- Sectors: consumer robotics communities
- Tools/workflows: Single-GPU training; minimalist reward configurations; curated terrain packs
- Dependencies/assumptions: Budget hardware; safety constraints; limited task complexity
Long-Term Applications
These applications build on the paper’s methods but require further scaling, validation, integration, or regulatory work.
- Warehousing and logistics — adaptive humanoid fleets with frequent policy refresh
- Use case: Daily retraining to adapt gaits to shifting layouts, loads, footwear, or floor conditions; fleet-wide OTA rollout after sim-validation.
- Sectors: logistics, e-commerce fulfillment
- Potential products/workflows: “Policy Update-as-a-Service,” cloud training farms, facility-specific domain randomization libraries, fleet telemetry-driven retraining triggers
- Dependencies/assumptions: Fleet management platforms; robust OTA governance; continuous sim environments mirroring live facilities; strong safety assurance
- Construction, mining, and energy — locomotion in harsh, evolving terrains
- Use case: Train controllers robust to debris, slopes, mud, or low-friction surfaces with conservative safety envelopes.
- Sectors: construction, mining, energy
- Potential products/workflows: Ruggedized humanoids; terrain-specific randomization packs; on-site rapid retraining kits
- Dependencies/assumptions: Hardware survivability; extreme-condition simulation; comprehensive risk controls
- Healthcare — assistive and rehabilitation humanoids with motion imitation
- Use case: Therapists guide robots via tracked motion to demonstrate exercises; humanoids assist with mobility tasks in controlled environments.
- Sectors: healthcare, rehabilitation
- Potential products/workflows: Clinical-grade motion tracking; safety layers around contact; standardized exercise libraries
- Dependencies/assumptions: Regulatory approvals, clinical trials, high-fidelity sensing, stringent safety and reliability guarantees
- Education and public services — classroom assistants and interactive learning
- Use case: Robots mimic teacher movements (PE, dance, theater), adapting behaviors with on-site retraining to local conditions.
- Sectors: education, municipal services
- Potential products/workflows: Curriculum-tuned reward presets; privacy-compliant motion capture; school-specific deployment SOPs
- Dependencies/assumptions: Ethics and privacy safeguards; supervision; procurement and maintenance capacities
- Disaster response and search-and-rescue — mobility in rubble and constrained spaces
- Use case: Rapidly adapted gaits for unstable environments and push-recovery under uncertainty.
- Sectors: emergency response
- Potential products/workflows: Incident-specific sim scenarios; resiliency stress tests; remote teleoperation with motion tracking failsafes
- Dependencies/assumptions: Ruggedized platforms; reliable comms; risk-informed deployment protocols
- Commercial software and hardware bundles — SDKs for fast sim-to-real RL
- Use case: Offer a turnkey training stack combining Holosoma-like software, GPU simulation acceleration, and robot-specific adapters.
- Sectors: robotics software, platform providers
- Potential products/workflows: “Reward-lite” library, joint-limit-aware action adapters, domain randomization presets per robot model
- Dependencies/assumptions: Licensing, cross-platform compatibility, vendor integration support
- Standards and policy — certification for sim-to-real RL controllers
- Use case: Formalize stress-test categories (push frequency/strength, friction/mass ranges), reporting protocols (energy/time footprints), and retraining governance.
- Sectors: regulation, industry consortia
- Potential products/workflows: Certification toolkits; audit logs of randomization coverage and sim-to-real deltas
- Dependencies/assumptions: Multi-stakeholder consensus; independent labs; enforcement mechanisms
- Sustainability — greener RL practices through reduced training energy
- Use case: Track and optimize power and carbon budgets for frequent retraining; compare off-policy vs on-policy energy profiles.
- Sectors: sustainability, ESG
- Potential products/workflows: Carbon dashboards; energy-aware hyperparameter tuning; institutional reporting
- Dependencies/assumptions: Standardized measurement methods; data transparency; organizational incentives
- Finance and business operations — improved robotics ROI and risk modeling
- Use case: Quantify faster iteration benefits (time-to-market, update agility), factor into CAPEX/OPEX planning and insurance underwriting.
- Sectors: finance, operations
- Potential products/workflows: Financial models incorporating rapid iteration cycles; risk profiles tied to domain randomization coverage
- Dependencies/assumptions: Demonstrated reliability at scale; standardized safety metrics
- Cross-robot generalization — extending to exoskeletons, prosthetics, high-DoF manipulators
- Use case: Apply joint-limit-aware bounds and minimal rewards to other high-dimensional platforms for safe, efficient control learning.
- Sectors: medical devices, industrial manipulators, defense
- Potential products/workflows: Device-specific adapters; contact-rich simulation libraries; exploration-safe entropy tuning
- Dependencies/assumptions: Validated transfer for different contact dynamics and sensing; task-specific safety guards
- Advanced human–robot interaction — robust contact and compliance
- Use case: Train policies that tolerate external pushes and human contact, enabling safe co-working and collaborative tasks.
- Sectors: manufacturing, services
- Potential products/workflows: HRI stress suites; compliance-aware reward terms; monitoring and intervention policies
- Dependencies/assumptions: Reliable tactile/force sensing; strong safety interlocks; user training and oversight
Collections
Sign up for free to add this paper to one or more collections.

