- The paper demonstrates that transformer representations follow log-compressive geometry but lack scalar variability, as variability decreases with increasing numerical magnitude.
- The study employs hidden-state vector analysis across multiple models and layers, using corpus frequency and instruction-tuning controls to rigorously assess noise patterns.
- The findings imply that without explicit resource constraints, distributional learning in transformers fails to reproduce human-like constant coefficient noise scaling.
Introduction
This work, "Same Geometry, Opposite Noise: Transformer Magnitude Representations Lack Scalar Variability" (2604.04469), interrogates the extent to which large transformer LLMs replicate both geometric and noise properties attributed to biological magnitude representation. While prior work demonstrates that both biological and artificial systems encode numerical magnitudes with log-compressive geometry—yielding behavior consistent with Weber's Law—the present study examines whether LLM representations also exhibit scalar variability, i.e., the proportional scaling of representational noise with magnitude that characterizes biological systems.
Scalar variability manifests as a constant coefficient of variation (CV), suggesting that noise increases linearly with mean magnitude, a phenomenon widely observed in neural responses and psychophysics. The efficient coding hypothesis predicts the joint emergence of log-compressive geometry and scalar variability from power-law-distributed stimuli under a fixed noise budget. However, transformers lack explicit metabolic constraints or noise budgets; therefore, this research addresses whether distributional learning alone suffices for the emergence of scalar noise patterns.
Experimental Design
The investigation analyzes hidden-state vectors for 26 numerical magnitudes (ranging from 1 to 1000) across 5 distinct carrier sentences in three transformer models: Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.3, and Llama-3-8B-Base. For each magnitude and model-layer combination (layers 16–31, covering the peak-geometry regime identified in prior work), representational variability is quantified as the mean Euclidean distance from sentence-wise centroids. Two controls are used: sentence-identity correction and projection onto the principal component (PC1) aligned with the magnitude axis. The scaling exponent α is determined by regressing log(variability) on log(magnitude); scalar variability predicts α≈1.
Hypotheses explicitly preregistered involved the sign and value of α, its deviation from unity, and its variation across layers.
Results
Representative Variability Patterns
Contrary to the central prediction of scalar variability, the scaling exponent α was negative in all cases: representational variability decreases with magnitude along both the full-dimensional space and the magnitude-relevant subspace. No instance across 48 model–layer–measure combinations yielded a positive α. Quantitatively, mean α for the raw Euclidean measure ranged from −0.031 (Llama-Base) to −0.046 (Llama-Instruct), corresponding to a 10–15% reduction in dispersion across the magnitude range.
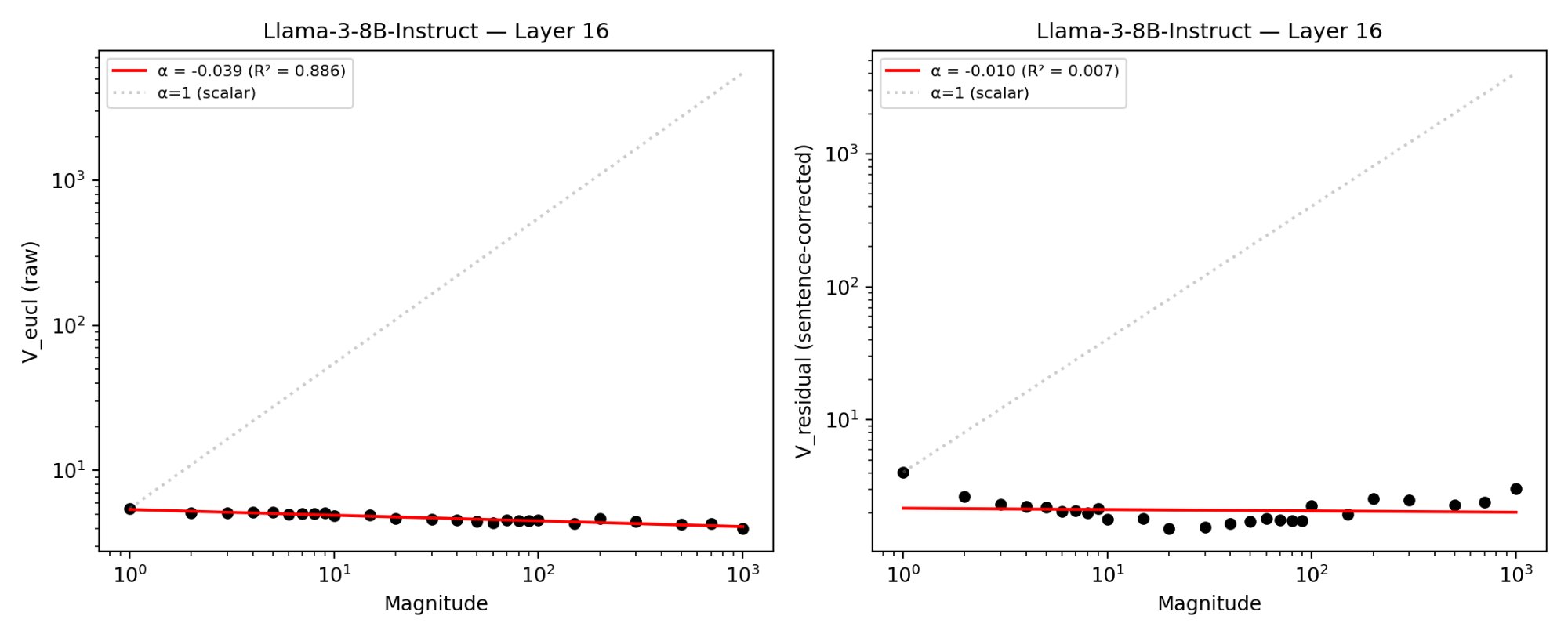
Figure 1: Representational variability as a function of numerical magnitude (log--log axes) at layer 16 of Llama-3-8B-Instruct for both raw and sentence-corrected measures; lines indicate OLS regression and scalar (log0) prediction.
No layer in any model approached the scalar prediction (log1). The anti-scalar pattern persisted across all control analyses and was stable through network depth: layerwise log2 did not systematically vary.
Corpus Frequency Effects
Variability reduction with increasing magnitude closely tracked corpus frequency: small numbers, which appear more often and in diverse contexts during training, exhibited higher representational dispersion. Conversely, large numbers, with sparse contextual diversity, showed compressed representations. The Spearman correlation between corpus frequency and dispersion reached log3 across all models and layers.
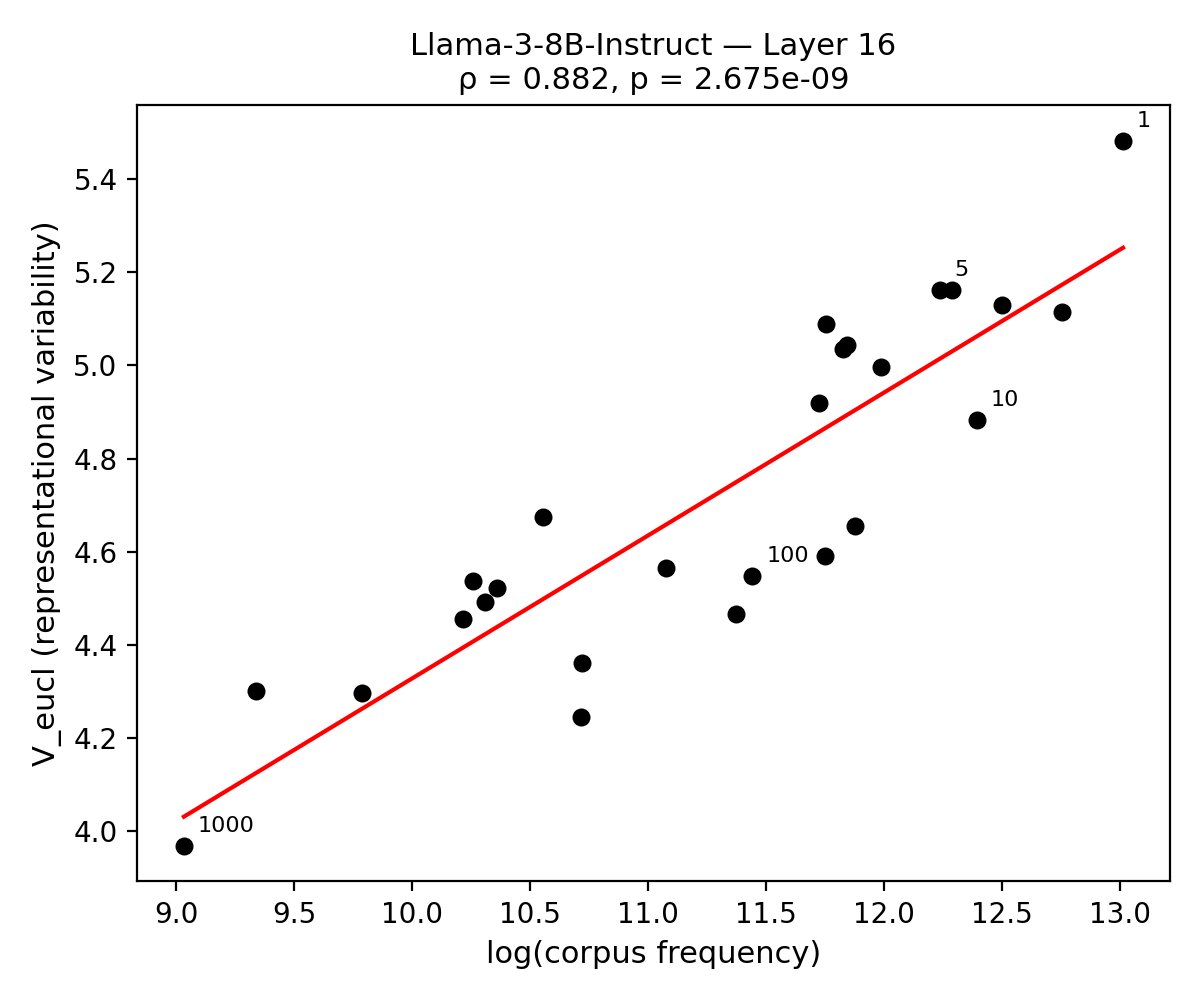
Figure 2: Corpus frequency robustly predicts representational variability across tested magnitudes—high-frequency (typically smaller) numbers are more dispersed.
Subspace and Instruction Tuning Effects
Dimensionality-specific analysis revealed that the anti-scalar effect is most pronounced along the magnitude-relevant (PC1) axis; the decrease in variability is stronger here than in orthogonal subspaces (on-axis mean log4 around log5 vs. off-axis around log6).
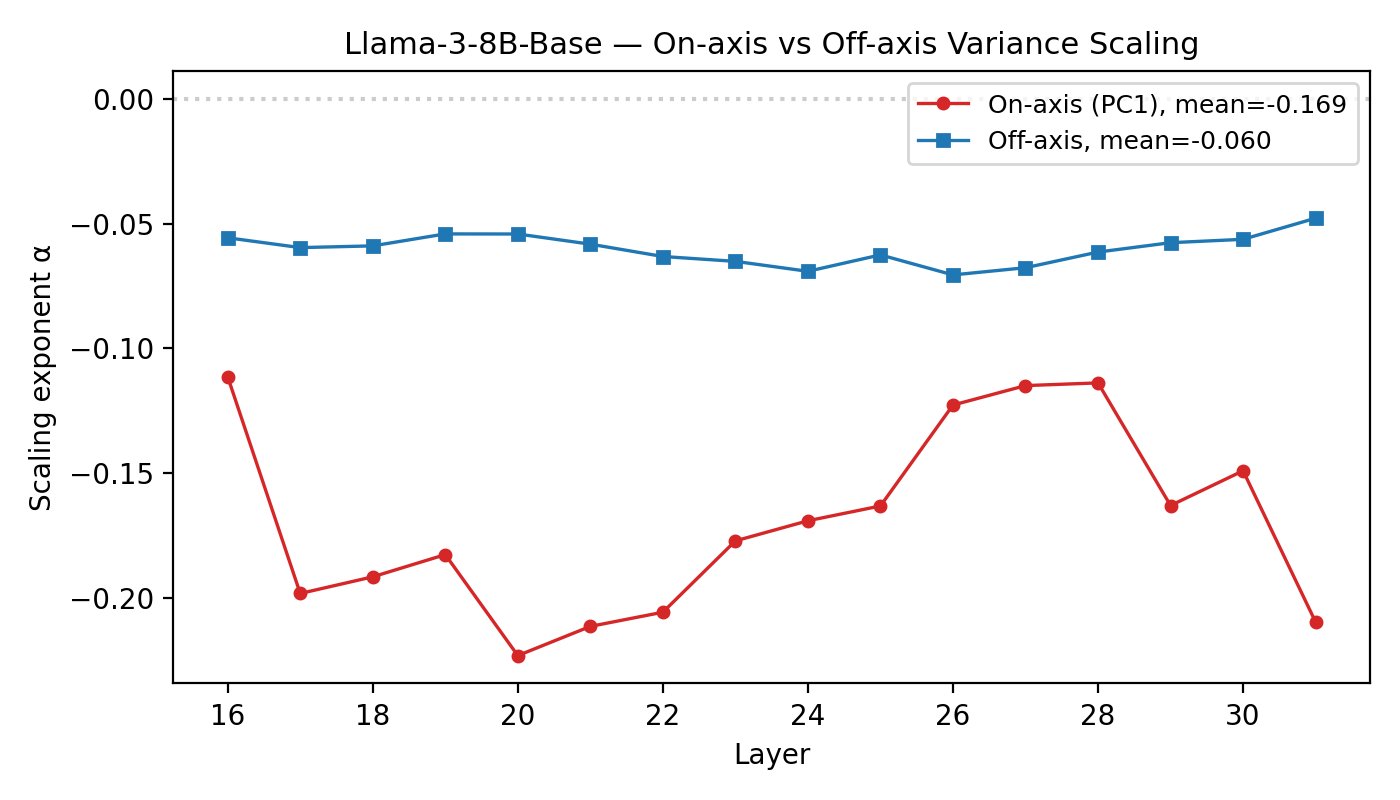
Figure 3: The anti-scalar scaling exponent is substantially more negative along the magnitude (on-axis) direction compared to orthogonal components.
Furthermore, instruction tuning exacerbates the anti-scalar pattern: Llama-Instruct layers exhibit more negative log7 values than base, indicating that supervised fine-tuning suppresses representational variability among rare, large-magnitude numbers.
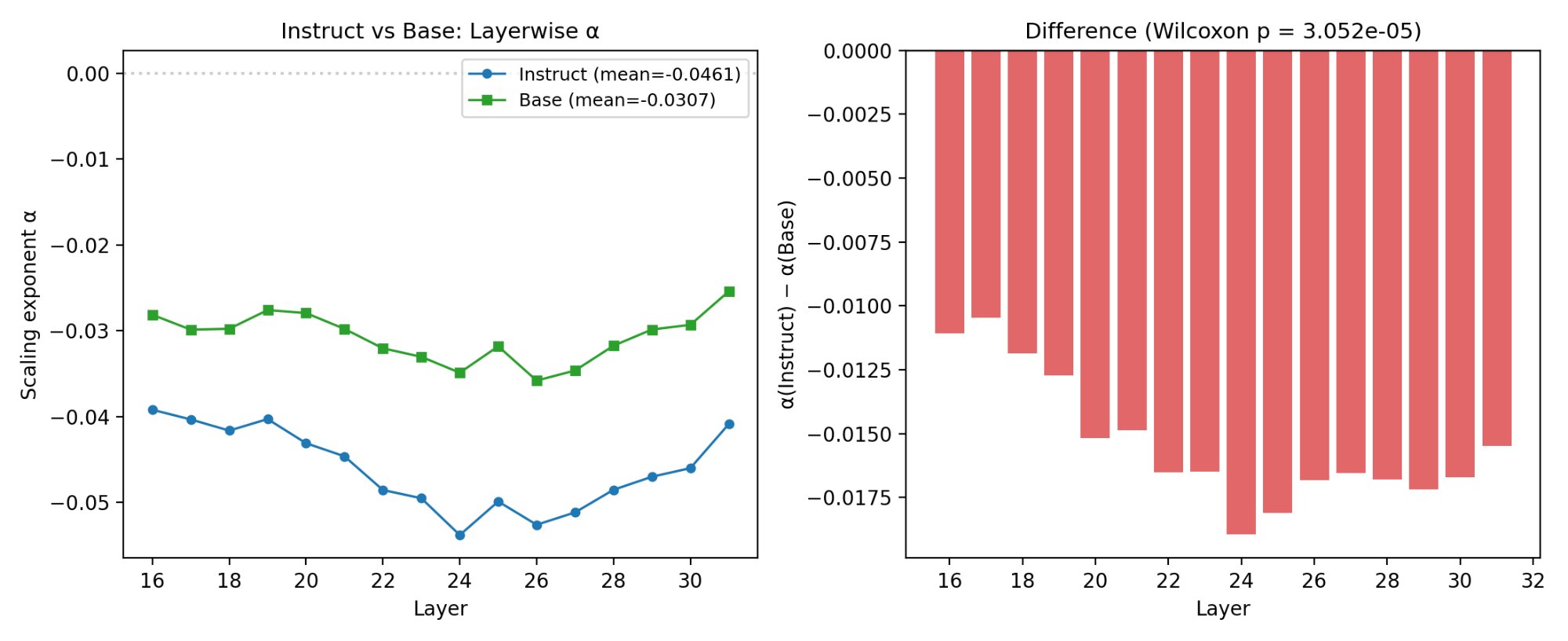
Figure 4: Instruction-tuned models show consistently stronger anti-scalar scaling (log8 at all layers) than their untuned counterparts.
Layerwise profiles for log9 reinforce the ubiquity of the anti-scalar phenomenon across all models, layers, and variability metrics.
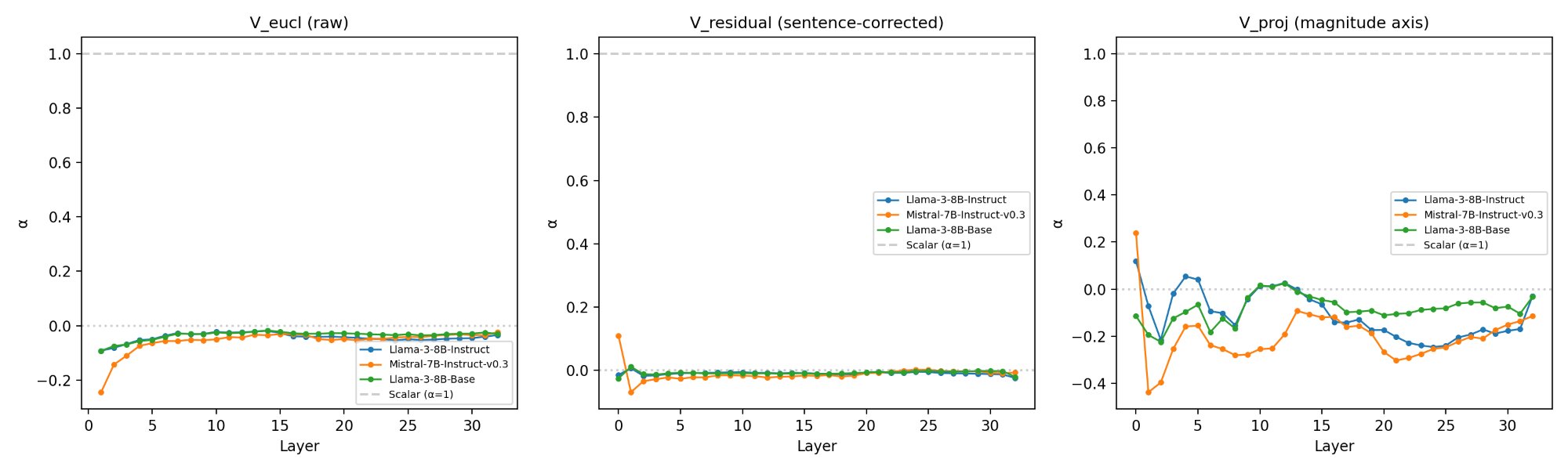
Figure 5: Anti-scalar scaling (log0) dominates across all layers, models, and measures, refuting the scalar variability hypothesis for transformer LLMs.
Theoretical and Practical Implications
These findings establish a dissociation between mean representation geometry and noise structure within transformer LLMs. While distributional learning over power-law-distributed stimuli suffices to produce log-compressive magnitude geometry, it does not yield scalar variability in the absence of explicit resource constraints. This empirically substantiates the two-component formulation of the efficient coding hypothesis: distributional statistics set the geometry, but a fixed capacity/noise budget is necessary for proportional noise scaling.
The corpus frequency dependence has important implications for modeling LLM representations: representational noise tracks contextual diversity rather than numerical magnitude per se. This is interpreted as a signature of the training data regime rather than an emergent property of magnitude representation akin to biological cognition.
Practically, this divergence raises questions for the use of LLMs in modeling or simulating human psychophysics or decision-making under uncertainty. Without scalar variability, transformers lack a key property underlying human-like estimation, accumulation, and decision noise patterns. The amplification of this effect by instruction tuning suggests that fine-tuning on supervised instructions may further entrench distribution-driven, rather than capacity-driven, representational phenomena.
Speculation for Future Research
The results motivate extensions to other numerical domains (fractions, negatives), larger-scale models, and different architectures (e.g., RNNs, diffusion models) to test the generality of these dissociations. Introducing explicit noise constraints or regularization promoting constant-CV noise signatures could be investigated as interventions. Better proxies for stochastic variability (e.g., through dropout sampling or at pre-activation stages) may further clarify the structure of internal noise.
Additionally, these findings dovetail with open questions in interpretability: do other token concepts showing heavy-tailed frequency distributions exhibit similar anti-scalar noise, or is this unique to numerical magnitude? How does representational dispersion relate to in-context generalization and extrapolation capabilities for rare versus common concepts?
Conclusion
Transformer LLMs reproduce log-compressive magnitude geometry but invert the hallmark noise structure of biological systems, exhibiting anti-scalar rather than scalar variability. This reveals that distributional learning alone cannot capture the constant-CV noise pattern; efficient coding's noise predictions presuppose capacity constraints absent from current architectures. The mechanistic divergence underscores important limitations for LLMs as models of psychophysical and cognitive phenomena and suggests new directions for architecture design and learning objectives aiming to bridge this gap.

