The Representational Geometry of Number
Abstract: A central question in cognitive science is whether conceptual representations converge onto a shared manifold to support generalization, or diverge into orthogonal subspaces to minimize task interference. While prior work has discovered evidence for both, a mechanistic account of how these properties coexist and transform across tasks remains elusive. We propose that representational sharing lies not in the concepts themselves, but in the geometric relations between them. Using number concepts as a testbed and LLMs as high-dimensional computational substrates, we show that number representations preserve a stable relational structure across tasks. Task-specific representations are embedded in distinct subspaces, with low-level features like magnitude and parity encoded along separable linear directions. Crucially, we find that these subspaces are largely transformable into one another via linear mappings, indicating that representations share relational structure despite being located in distinct subspaces. Together, these results provide a mechanistic lens of how LLMs balance the shared structure of number representation with functional flexibility. It suggests that understanding arises when task-specific transformations are applied to a shared underlying relational structure of conceptual representations.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question about how ideas are stored inside AI LLMs: do different tasks share the same “mental map” of a concept, or do they split into separate spaces to avoid getting in each other’s way? The authors focus on numbers (like 1–9) as a clear test case. They show that, inside LLMs, numbers keep a stable pattern of relationships (like a mental number line), even when the model is doing different tasks. Each task lives in its own “subspace,” but these subspaces can be connected by simple, straight-line transformations. In short, the models balance shared structure with task-specific flexibility.
Key Questions
The paper explores three easy-to-grasp questions:
- Do AI models keep a consistent “shape” for how numbers relate to each other, across different tasks?
- Do different tasks (like comparing numbers or doing arithmetic) use separate spaces to prevent confusion?
- Can the model switch between tasks by applying simple transformations to the same underlying number structure?
How Did They Study It?
The authors used several well-known LLMs (BERT, GPT-2, Qwen2.5, and Qwen2.5-Math) and looked at their internal representations of numbers during different kinds of sentences. Think of a representation as a coordinate for a number inside the model’s “brain”—like a dot on a very high-dimensional map.
They tested numbers in short sentences that prompted different skills:
- Quantity (how many apples?)
- Comparison (greater/smaller)
- Arithmetic (addition/multiplication)
- Properties (odd/even, prime/composite)
- Order (successor/predecessor: what comes before or after a number)
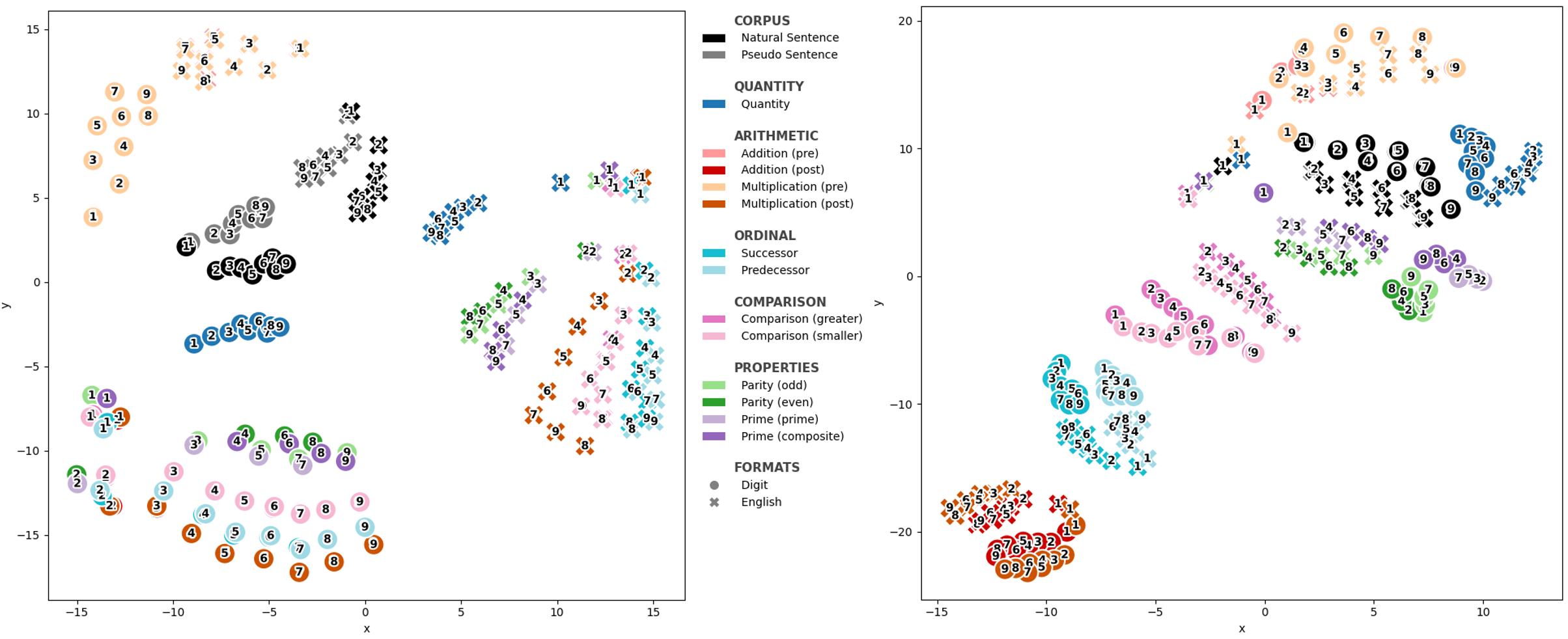
They checked both formats: digits (“3”) and words (“three”), and also used natural sentences from Wikipedia.
To understand the “shape” of the number space, they used tools that you can think of as map-making or map-matching:
- t-SNE: like making a 2D map that shows how close or far representations are.
- Cosine similarity: a measure of similarity based on angles; here used as a proxy for how easily a model “sees” two numbers as close or far (similar to reaction time in human studies).
- Procrustes analysis: like rotating, shifting, and scaling one map to line up with another to see how similar their shapes are.
- PCA (Principal Component Analysis): finds the main directions that explain most of the variation—like picking the most important axes in a room.
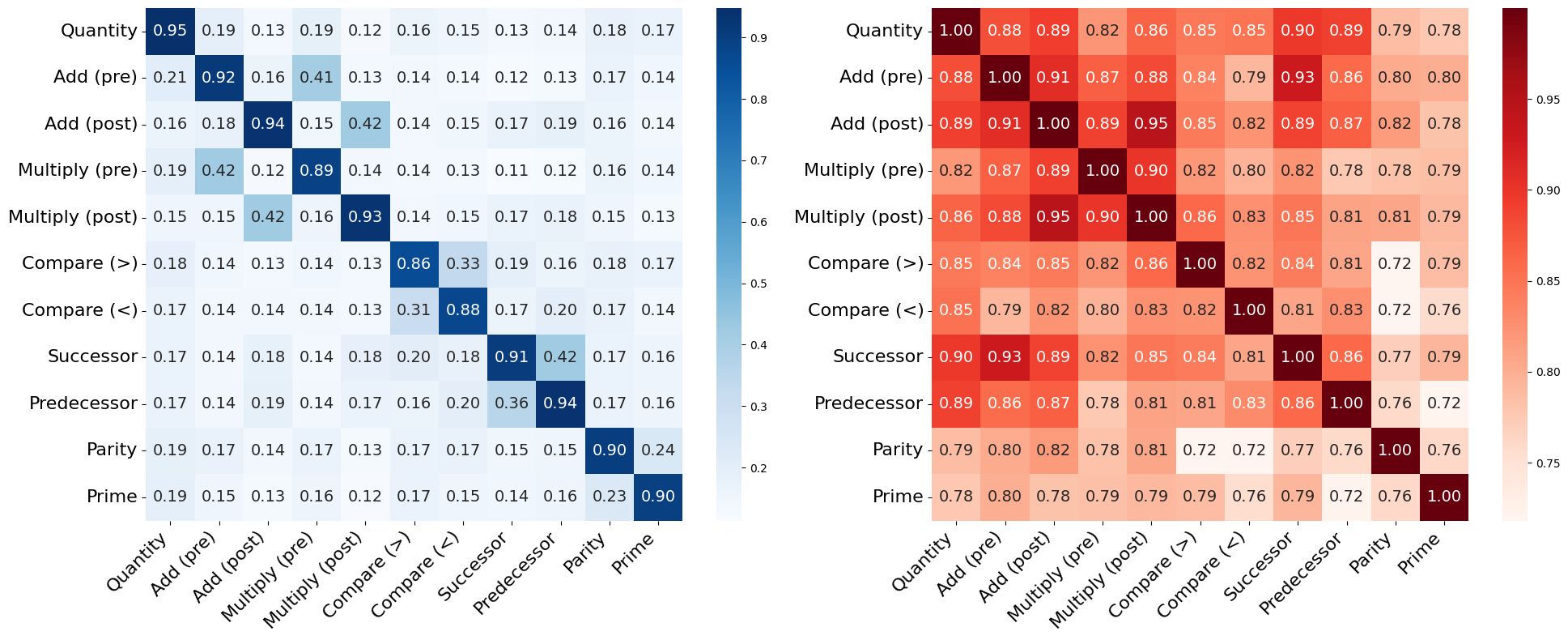
- Subspace overlap: checks how much the “room” used by one task overlaps with another task’s room.
- SVCCA: tests whether you can linearly transform one set of axes into another and still get high correlation—like seeing if two different coordinate systems are describing the same structure.
They also checked classic human number effects:
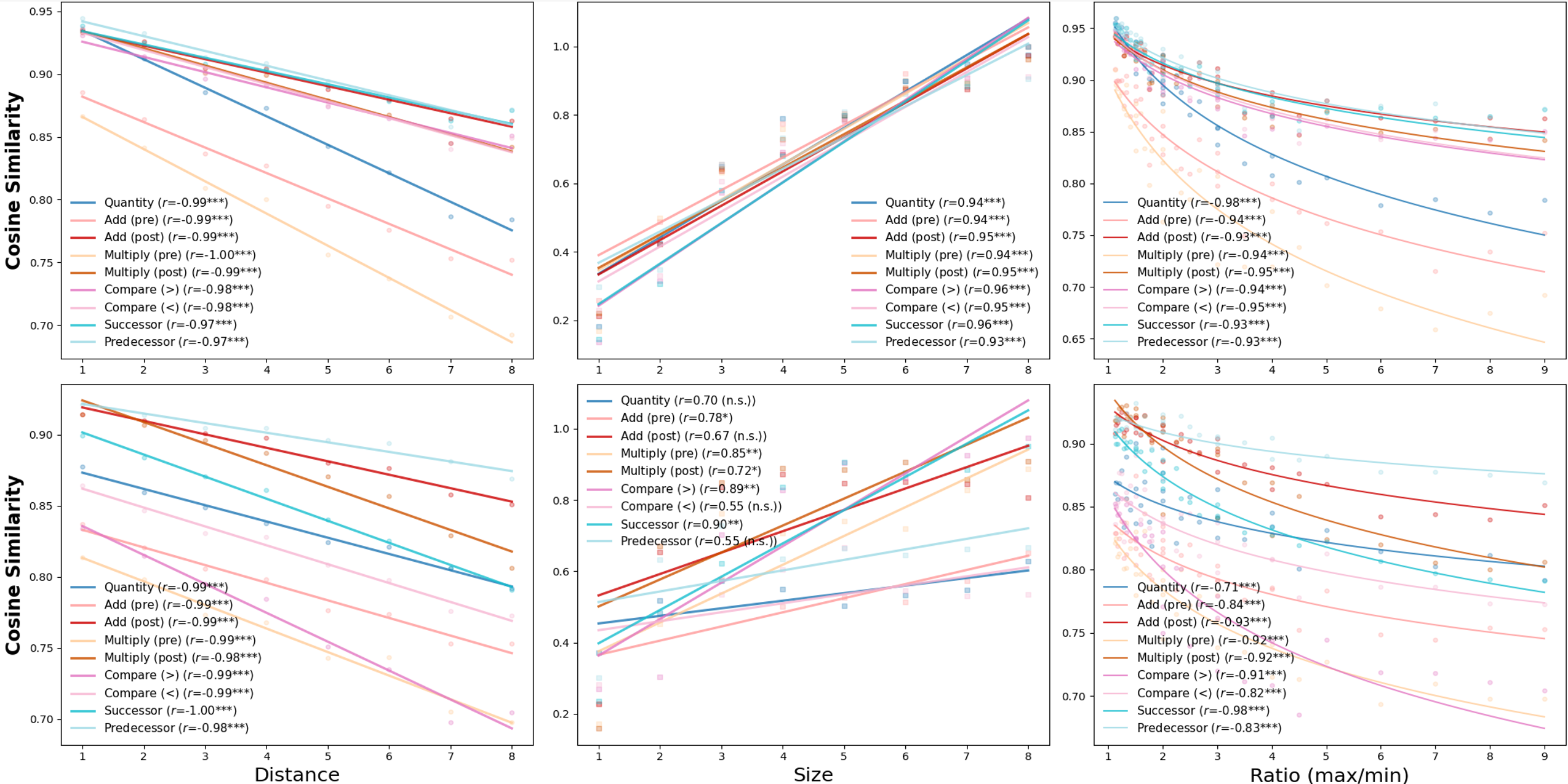
- Distance effect: it’s easier to tell apart numbers that are farther apart (1 vs 9) than closer ones (1 vs 2).
- Size effect: for the same gap, smaller numbers are easier to compare than bigger ones (1 vs 2 faster than 8 vs 9).
- Ratio effect: comparisons get easier when the ratio between numbers grows (e.g., 2 vs 8 is easier than 6 vs 8).
Main Findings and Why They Matter
Here are the key discoveries, explained simply:
- Shared “mental number line”: Across tasks and models, numbers line up in a consistent order, and the classic distance and ratio effects appear. This means the model keeps a stable sense of “how far apart” numbers are, much like humans do.
- Tasks use different subspaces: Even though the underlying number relationships are similar, each task sits in its own representational “room” inside the model. This separation helps avoid interference—like keeping your math notes separate from your history notes so they don’t get mixed up.
- Simple transformations connect tasks: These different task rooms can be related by mostly linear transformations (rotate, stretch, combine axes). That means the model can switch tasks by applying straightforward changes to the same shared structure, rather than relearning everything.
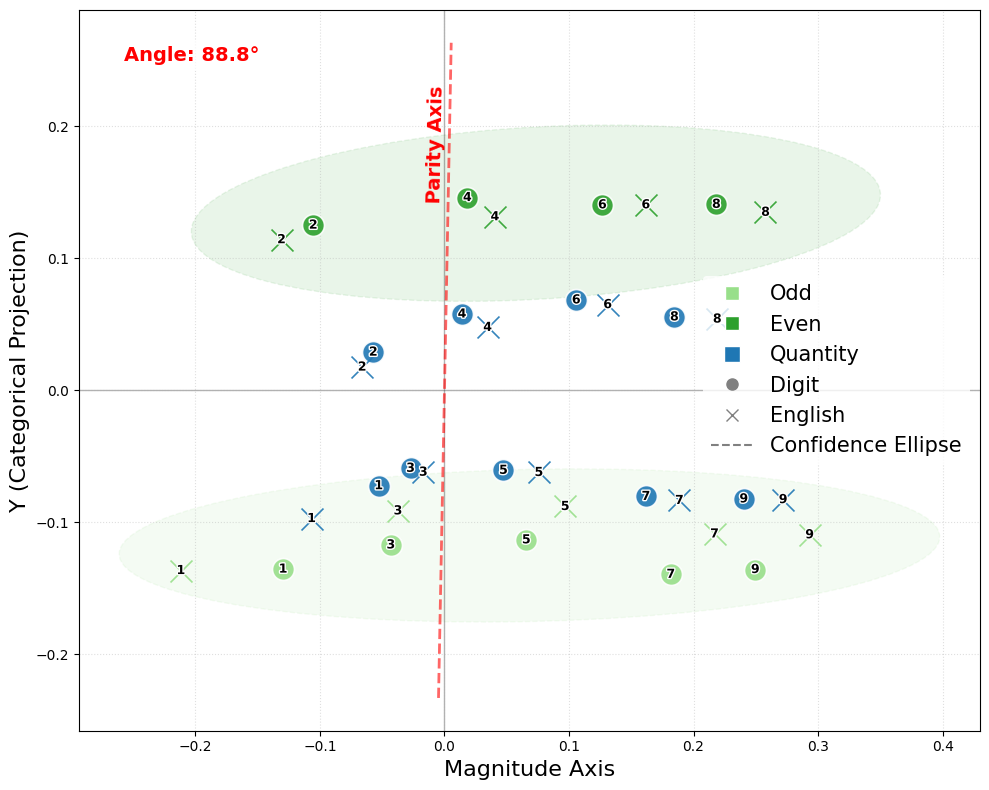
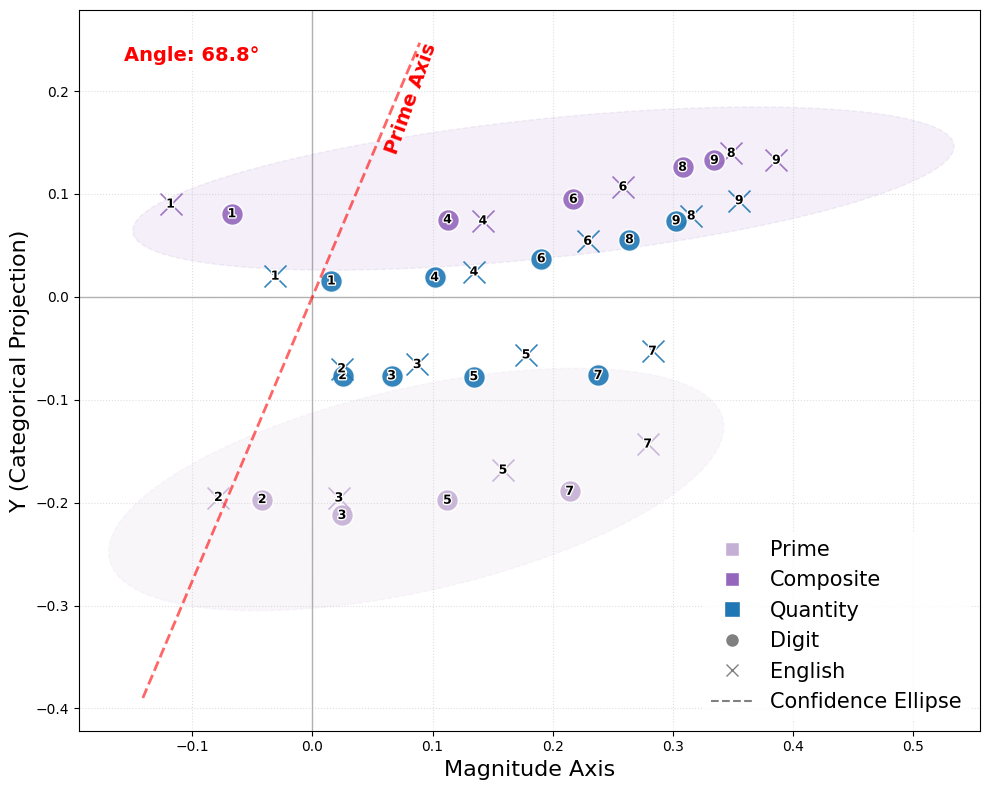
- Features are encoded along clean directions:
- Magnitude (how big a number is) and parity (odd vs even) are almost at right angles (orthogonal)—like north-south vs east-west. That makes parity a clean, independent feature from size.
- Primality (prime vs composite) isn’t perfectly independent from magnitude; its direction tilts toward size, which makes sense because larger numbers are more often composite.
- Formats are distinct but parallel: Digits (“3”) and words (“three”) live in different regions, but they keep similar relational patterns—like two maps of the same city drawn in different styles but preserving the same street layout.
- More specialized models show finer separation: The math-focused model (Qwen2.5-Math) separates tasks more clearly and embeds logical distinctions more sharply (for example, addition and multiplication clusters are more cleanly split).
Why it matters:
- It shows how models can generalize (by sharing a core structure) while also avoiding confusion (by separating tasks).
- It provides a mechanical explanation for “understanding” as applying task-specific transformations to a common relational scaffold.
Implications and Impact
- Better AI design: Knowing that models keep a shared relational geometry but use separate task spaces can guide training strategies. We can build models that switch tasks quickly and safely by encouraging linear, transformer-like mappings between subspaces.
- Bridges to human cognition: The findings match human-like number effects and suggest that stable relational structures may be a learned adaptation to complex environments. This might help explain why some people struggle with numerical tasks (e.g., dyscalculia): their systems may not form or connect these stable geometries as well.
- Beyond numbers: The same idea—shared relational geometry plus task-specific transformations—could apply to other concepts (like colors, shapes, or social roles). It hints that “concepts as vectors” is not just a metaphor but a useful way to think about meaning inside brains and machines.
In short, the paper argues that understanding comes from applying the right transformation to a shared, well-organized relational map. Numbers are a clear example of how AI models balance common structure with flexible task use—and this balance may be a general principle of intelligent systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s current scope.
- Limited numeric range: analyses focus almost exclusively on 1–9 (with inconsistent use of 0), leaving unknown whether results hold for larger magnitudes, multi-digit numbers, negatives, fractions, decimals, scientific notation, and ordinal/canonical forms beyond nine.
- Edge-case semantics: special cases (e.g., 0’s parity, 1’s non-primality) are not systematically tested, risking confounds in “parity” and “primality” conclusions.
- Format coverage: only Arabic digits and English words are considered; no assessment of Roman numerals, abbreviations (e.g., “No. 3”), spelled-out multiword numerals (e.g., “twenty-one”), or morphological variants (“third”) and how these map across subspaces.
- Cross-linguistic generality: all experiments are in English; it is unknown whether the reported geometry and cross-task transformability hold for other languages with different numeral systems and morphology.
- Small, hand-crafted prompt set: only five sentences per task may under-sample contextual variability; robustness to paraphrase, syntactic alternation, discourse context, and adversarial phrasing is not established.
- Limited ecological evaluation: the “Real Sentence” corpus is small (450 sentences) and Wikipedia-only; results may not generalize to broader domains (news, fiction, math textbooks, social media) or multi-sentence contexts.
- Tokenization confounds: effects of subword segmentation for number words, multi-token numerals, and token-boundary choices (first vs. last subtoken) are not analyzed; stability of findings under alternate tokenization remains unknown.
- Frequency and co-occurrence biases: differences in token frequency and collocations (“odd,” “even,” “prime”) may drive structure; no controls (e.g., frequency-matched corpora, downsampling) are applied.
- Model diversity and scaling: only four base (pretrained) transformer LLMs are tested; effects of instruction tuning/RLHF, architecture variants (e.g., Mamba, RNNs), parameter scaling, and pretraining data size/composition are not explored.
- Random seed variability: stability of the representational geometry across multiple training seeds or checkpoints is untested.
- Layerwise dynamics: analyses emphasize a single layer (~75% depth) with qualitative claims about other layers; no systematic, time-resolved trajectory across layers or generation steps (for autoregressive models) is provided.
- Behavior-grounded validation: cosine similarity is used as a proxy for reaction time, but no direct fit to human RT/accuracy or neuroimaging RSA is conducted to validate the mapping quantitatively.
- MNL compression characterization: while distance/ratio/size effects are reported, the paper does not explicitly test logarithmic vs. linear scaling of magnitude (e.g., model comparison for ), leaving the MNL compression claim under-specified.
- Statistical power and uncertainty: many analyses rely on very small sample sizes (nine numbers) and report averages without confidence intervals/bootstraps; variance across prompts/sentences/runs is largely absent.
- t-SNE dependence: global organization is supported by t-SNE visualizations, which can be parameter-sensitive; no complementary manifold or separability metrics (UMAP, Isomap, silhouette scores) are reported.
- Procrustes baselines and inference: Procrustes alignment uses a label-permutation baseline only; sensitivity to normalization, isotropic/anisotropic noise, affine (non-rigid) distortions, and confidence intervals via bootstrapping are not reported.
- Subspace Overlap/SVCCA choices: results depend on the number of PCs (95% variance threshold); no sensitivity analysis to , alternative similarity metrics (CKA), or cross-validated stability is provided.
- Linear transformability claims: high SVCCA is suggestive but no explicit linear mappings are learned/evaluated for out-of-sample generalization (e.g., train on subset of numbers/tasks, test on held-out numbers/tasks).
- Nonlinear structure quantification: the paper hypothesizes emerging nonlinearity for complex properties (e.g., primality) but does not quantify it (e.g., kernel CCA, nonlinear manifold alignment, CKA) or test whether nonlinear maps improve alignment.
- Causal and functional tests: there are no interventions (e.g., activation steering along “parity”/“magnitude” directions, representation editing) to demonstrate causal effects on model outputs or to probe interference in behavior.
- Task interference is inferred, not measured: no experiments test catastrophic interference/transfer (e.g., fine-tune on one task and evaluate forgetting or cross-task generalization) to link subspace separation to functional interference mitigation.
- Linear decodability: the presence of distinct axes (e.g., parity) is inferred geometrically, but no linear probes are trained to quantify decodability and compare across tasks/layers/models.
- Cross-format mapping: digit–word subspaces are “parallel” but not operationally connected; whether a learned linear map transfers across unseen numerals/forms or improves format-invariant behavior is untested.
- Generality beyond number: the relational-geometry hypothesis is argued to “extend beyond numbers,” but no tests on other conceptual domains (e.g., color, kinship, taxonomy, geography) are conducted.
- Training-data attribution: differences between Qwen2.5 and Qwen2.5-Math are observed but not causally attributed; controlled ablations on math-corpus size/content are needed to link training distribution to representational geometry.
- Robustness across prompts and noise: stability to input noise, paraphrase, context length, and distractors is not assessed; how perturbations deform subspaces or mappings remains unknown.
- Representation anisotropy and normalization: cosine similarity and L2 normalization are used, but anisotropy, whitening, or alternative distance metrics are not explored, which may affect geometric conclusions.
- Sparseness and density claims: sparseness is reported for formats but not across tasks/layers; its relation to linear decodability and subspace separation is not analyzed.
- Mechanistic attribution within architecture: it is unknown which layers/heads or pathways carry magnitude vs. property axes; attention-head/MLP attribution (e.g., path patching) is not performed.
- Compositional arithmetic: only single-digit arithmetic contexts are probed; multi-digit operations, carry/borrow, and multi-step reasoning (chain-of-thought) are not examined for geometric stability and transformability.
- Ordinal vs. comparison asymmetries: observed asymmetries (e.g., successor vs. predecessor effects) are described but not explained; no hypothesis tests or ablations link them to training data or architectural bias.
- Token boundary ambiguity: for multi-token numbers/words, it is unclear which token’s embedding should anchor the “number representation”; this choice is not stress-tested for stability.
- Reproducibility details: hyperparameters for t-SNE/PCA/SVCCA, number of PCs retained, and exact layer indices are not fully specified for replicability or sensitivity checks.
These gaps point to concrete follow-ups: expand numeric and linguistic coverage; test robustness and scaling; perform layerwise/dynamic and causal analyses; learn and evaluate explicit inter-task/format mappings (linear and nonlinear); ground representational effects in human/behavioral data; and validate interference claims with controlled transfer/finetuning experiments.
Practical Applications
Immediate Applications
Below are applications that can be deployed with existing models, data, and tooling, leveraging the paper’s analyses (Procrustes, Subspace Overlap, SVCCA), findings (shared relational structure, task-specific subspaces, linear transformability), and task design.
- Bold numeracy interpretability and audit toolkit — software/AI
- Tool/product/workflow: A lightweight library and dashboard that extracts internal number embeddings (e.g., for 1–9 and beyond) and reports Procrustes disparity, Subspace Overlap, and SVCCA across tasks (quantity, comparison, arithmetic, ordinal, properties). Integrate into evaluation pipelines and model cards to quantify “numeracy geometry health.”
- Assumptions/dependencies: Access to model activations or hidden states; results generalize beyond 1–9; stable across layers and tokenization schemes.
- Linear probes and drift monitors for magnitude, parity, and related number properties — software/AI
- Tool/product/workflow: Train linear probes for magnitude and parity/primality axes; set acceptance thresholds for orthogonality and linear separability; continuous monitoring during fine-tuning to detect numeracy regressions; regression tests for digits vs. words alignment.
- Assumptions/dependencies: Linear probes remain predictive for larger number ranges; parity/primality separability holds in production domains.
- Activation steering and task adapters (“task toggles”) — software/AI
- Tool/product/workflow: Learn linear mappings between task subspaces (e.g., comparison ↔ ordinal ↔ arithmetic) to reduce interference and improve reliability; package as adapters or activation hooks that steer the model to the desired task subspace at inference time.
- Assumptions/dependencies: Linear transformations do not introduce harmful side effects; requires internal access to hidden states; may need task-specific calibration.
- Prompting and data curation guidelines for numeracy subspaces — software/AI; education
- Tool/product/workflow: Style guides that use task-activating phrases (“greater than,” “successor,” pre-/post-equal arithmetic prompts) to reliably elicit the right task subspace. Dataset curation that balances formats (digits/words) and tasks to maintain shared relational structure and minimize interference.
- Assumptions/dependencies: Task-sensitive phrasing reliably activates subspaces across models and languages; prompt patterns transfer to downstream applications.
- Numeracy benchmark with geometric criteria — academia; industry evaluation
- Tool/product/workflow: A public benchmark suite that scores models on (i) distance/size/ratio effects, (ii) Procrustes alignment across tasks and formats, (iii) subspace overlap and SVCCA for interference vs. transformability. Use for model selection and regression tests after domain fine-tuning.
- Assumptions/dependencies: Agreement on metrics and thresholds; reproducibility across seeds/layers; community adoption.
- EdTech diagnostics in LLM-powered tutors — education
- Tool/product/workflow: Assessment items that elicit distance/size/ratio effects to estimate a learner’s “mental number line” structure; analytics to detect confusion between magnitude and parity/primality; personalized feedback based on which “axes” (features) appear entangled.
- Assumptions/dependencies: Behavioral alignment between human learners and model-derived geometry; ethical and privacy-safe data collection.
- Cognitive neuroscience analysis pipeline — academia/healthcare research
- Tool/product/workflow: Use representational similarity, Procrustes, and SVCCA to compare human neural data (fMRI/MEG/EEG) with LLM-derived number geometries; evaluate hypotheses about shared vs. distinct subspaces for magnitude, parity, and arithmetic operations.
- Assumptions/dependencies: Access to well-controlled neuroimaging datasets; appropriate alignment methods and statistical controls.
- Spreadsheet/BI numeracy checks — software/finance/operations
- Tool/product/workflow: Assistants that flag inconsistencies in tables and reports using ordinal/magnitude/ratio checks (e.g., mislabeled “top 3,” incorrect ordering, ratio claims not supported by values), and parity/primality tagging for QA in math-heavy documents.
- Assumptions/dependencies: Robust extraction and grounding of numbers from unstructured text; domain adaptation to avoid false positives.
Long-Term Applications
These applications will benefit from further research to scale beyond 1–9, extend to more tasks and modalities, validate in humans, and formalize training/standards.
- Geometry-aware training objectives and architectures — software/AI
- Tool/product/workflow: New loss terms that (i) encourage orthogonal task subspaces to reduce interference and (ii) enforce linear equivariance between related tasks; architectures with explicit “task heads” plus linear bridges. Expected to improve reliability in numerical reasoning and beyond (e.g., date/time, units).
- Assumptions/dependencies: Scaling to large vocabularies and broader number ranges; no degradation in general capabilities.
- Clinical screening and remediation for dyscalculia — healthcare/education
- Tool/product/workflow: Behavioral batteries inspired by geometric markers (distance/size/ratio effects; separability of magnitude vs. parity) to detect atypical number geometry; targeted interventions that train specific mappings (e.g., ordinal ↔ comparison).
- Assumptions/dependencies: Rigorous clinical validation and longitudinal studies; ethical, privacy-compliant deployment; interdisciplinary collaboration.
- Certification standards for LLM numeracy — policy/industry standards
- Tool/product/workflow: Procurement and risk frameworks that require reporting Procrustes disparity, subspace overlap, and cross-format alignment for numeracy; standard test suites with pass/fail thresholds to certify models for domains where numeric reliability is critical (finance, healthcare, public communication).
- Assumptions/dependencies: Community consensus on metrics; clear links between scores and downstream error rates.
- Cross-lingual numeracy alignment and translation — software/NLP
- Tool/product/workflow: Use Procrustes/CCA to align number manifolds across languages and scripts (e.g., English, Chinese, Arabic), improving numerical translation accuracy and reducing format-induced errors in multilingual systems.
- Assumptions/dependencies: High-quality cross-lingual corpora; tokenization that preserves numeric structure; validation across diverse languages.
- Geometry-preserving knowledge distillation and edge numeracy — software/AI hardware
- Tool/product/workflow: Distillation procedures that match teacher–student representational geometry (Procrustes/SVCCA targets) to retain numeracy robustness in small, on-device models (e.g., calculators, IoT, mobile assistants).
- Assumptions/dependencies: Efficient objectives and training recipes; compute budgets; compatibility with quantization/pruning.
- Multimodal numeracy and robotics planning — robotics/vision+language
- Tool/product/workflow: Extend number geometry to visual counting and set cardinality detection; build planners that keep counting/magnitude in a dedicated subspace to prevent interference with language grounding, enabling robust “count-then-act” behaviors.
- Assumptions/dependencies: Multimodal datasets linking symbols to visual numerosities; reliable alignment across modalities.
- Automated verification of numerical claims — media/finance/policy analytics
- Tool/product/workflow: Content verification that checks relational consistency (ordering, ratios, magnitudes) in reports, dashboards, and news; flag suspicious claims for human review.
- Assumptions/dependencies: Accurate information extraction and grounding; calibrated thresholds to reduce false positives; domain-specific adaptation.
- Agent/tool routing via subspace gating — software/AI orchestration
- Tool/product/workflow: Middleware that inspects activations to detect which numeracy subspace is active and routes to the appropriate external tool (calculator, comparator, table parser), or applies a learned linear map before tool use for consistency.
- Assumptions/dependencies: Access to internal activations; latency and privacy constraints; robust subspace detectors.
- Safety via interference-aware multi-task design — software/AI safety
- Tool/product/workflow: Model and training designs that minimize cross-task leakage by constraining orthogonal subspaces, reducing unexpected couplings (e.g., arithmetic interfering with date parsing or unit conversion).
- Assumptions/dependencies: Demonstrated link between subspace interference and real-world failures; standardized tests to quantify safety gains.
- Geometry-informed math curricula and tutoring — education
- Tool/product/workflow: Curriculum sequencing that first stabilizes magnitude (mental number line), then introduces orthogonal properties (parity/primality), leveraging distance/ratio effects for practice spacing and item difficulty. Adaptive tutoring systems use representational signals to personalize paths.
- Assumptions/dependencies: Classroom trials and learning science validation; equity and accessibility considerations; teacher training and support.
Each application leverages the central insight of the paper: representations of numbers in LLMs maintain a stable relational geometry across tasks and formats while residing in task-specific subspaces that are largely connected via linear transformations. This enables practical tooling for interpretability, reliability, training, and education—immediately for auditing and diagnostics, and longer term for new training paradigms, clinical applications, and standards.
Glossary
- Approximate Number System: An evolutionarily ancient cognitive system that represents and estimates numerical magnitudes approximately. "Human numerical cognition is understood as comprising two systems: the Approximate Number System, an evolutionarily ancient system to estimate magnitudes, and the Symbolic System, which enables exact calculation and rule-based manipulation through culturally acquired symbols \citep{cantlon2012math, ansari2016number}."
- Canonical Correlation Analysis: A statistical method that finds pairs of linear projections of two datasets that are maximally correlated. "Canonical Correlation Analysis \citep{morcos2018insights} then identifies pairs of projection vectors that maximize the Pearson correlation:$\rho_i = \max_{\mathbf{w}_{A,i}, \mathbf{w}_{B,i} \frac{\text{Cov}(\mathbf{w}_{A,i}^\top \mathbf{PC}_{A}, \mathbf{w}_{B,i}^\top \mathbf{PC}_{B})}{\sqrt{\text{Var}(\mathbf{w}_{A,i}^\top \mathbf{PC}_{A}) \cdot \text{Var}(\mathbf{w}_{B,i}^\top \mathbf{PC}_{B})}$"
- Canonical correlation coefficient: The correlation value obtained from CCA for each pair of canonical variates, indicating maximal correlation under linear projections. "Each is a canonical correlation coefficient, representing the maximum correlation between linear combinations of the two sets of components that remain orthogonal to all previously identified pairs."
- Conceptual space theory: A framework positing that concepts can be represented as regions in a geometric (metric) space structured by meaningful dimensions. "This provides support for \citet{gardenfors2004conceptual}’s conceptual space theory, yet goes beyond the idea of concepts as regions in a structured metric space as relations in vector space \citep{piantadosi2024concepts}."
- Distance Effect: A behavioral phenomenon where comparing two numbers is faster when their numerical distance is larger. "The Distance Effect is that the time to compare which of two numbers is greater increases with numerical distance between them (e.g., 1 vs. 9 is compared faster than 1 vs. 2) \citep{moyer1967time}."
- Dyscalculia: A learning difficulty characterized by impaired numerical processing and arithmetic skills. "This may help explain why individuals with dyscalculia—whose intraparietal sulcus (IPS) often shows reduced gray matter volume or atypical connectivity \citep{butterworth2011dyscalculia}—struggle with higher-order number representations."
- Intraparietal sulcus (IPS): A brain region in the parietal cortex implicated in numerical cognition and quantity processing. "whose intraparietal sulcus (IPS) often shows reduced gray matter volume or atypical connectivity \citep{butterworth2011dyscalculia}"
- Kernel density estimation (KDE): A nonparametric method to estimate the probability density function of data, yielding smooth distribution visualizations. "We project raw embeddings (instead of mean) of numbers from both the corpus and handcrafted task sentences using PCA and visualize their concentration with kernel density estimation \citep{rosenblatt1956remarks}."
- Linear decodability: The property that information can be recovered from representations using linear classifiers or regressors. "enable task flexibility through linear decodability, while constraining abstract categories to low-dimensional structures for generalization."
- Linear Representation Hypothesis: The proposition that many semantic concepts correspond to linear directions in a model’s latent space. "our account unifies them under a common relational perspective and has the potential to extend beyond number concepts. These findings also bear on a foundational question in neural systems and representation: if the same behavior or structure can arise from multiple implementations \citep{hu2025function}, what constrains representational convergence? One answer is the interplay between system capacity and environmental complexity. In small systems, representational redundancy often impedes the emergence of a stable geometry. However, as systems face increasingly complex learning environments—much like the human brain—they are pressured to converge to a more structured coding scheme. This suggests that knowledge representation is not necessarily innate \citep{spelke2007core}, but is a learned structural adaptation to the demands of the data." (context includes "the linear representation hypothesis \citep{park2024linear}")
- Linear transformation equivariance: The property that representational structure is preserved under linear transformations between task subspaces. "While the model uses distinct subspaces to minimize task interference, it balances the shared structure and efficient task-switching primarily through linear transformation equivariance."
- Mental Number Line (MNL): An internal, typically ordered spatial representation of numerical magnitude. "Numbers are uniquely suited as they are well-defined for various tasks and their representations, such as the Mental Number Line (MNL), are supported by a rich psychophysical literature \citep{dehaene2001precis}."
- Platonic hypothesis: The claim that models converge to shared, ideal representations of reality irrespective of architecture or modality. "suggesting that semantic identity does not fully converge—a finding contrary to the Platonic hypothesis \citep{huh2024position}."
- Procrustes Analysis: A method to align two sets of points via translation, rotation, and scaling to assess structural similarity. "We also apply Procrustes Analysis \citep{gower1975generalized} to estimate the degree to which the geometric relations between numbers are shared."
- Procrustes disparity: The residual distortion after optimal rigid alignment in Procrustes Analysis, measuring mismatch between structures. "The resulting , referred to as the Procrustes disparity, quantifies the residual geometric distortion."
- Ratio Effect: A behavioral phenomenon where number comparison gets easier as the ratio between numbers increases. "Finally, the Ratio Effect is that comparison time decreases as the ratio between the numbers increases \citep{halberda2008individual}."
- Representation sparseness: A measure of how distributed or concentrated activity is across representational dimensions. "We quantified this using representation sparseness \citep{rolls1995sparseness}, which measures how neural activity is distributed across the available dimensions."
- Representational geometry: The study of the geometric structure of representations and how it supports behavior and generalization. "Representational geometry has emerged as a quantitative framework to investigate how the structure of representations supports intelligent behavior."
- Rotational dynamics: Time-evolving changes in neural population activity characterized by rotations in latent space. "\citet{libby2021rotational} showed that neural circuits reformat sensory inputs via rotational dynamics into orthogonal memory subspaces over time."
- Shattering dimensionality: The capacity of a representational system to linearly separate many configurations, supporting task flexibility. "\citet{bernardi2020geometry} argues that neural representations adopt geometries that support high shattering dimensionality to enable task flexibility through linear decodability, while constraining abstract categories to low-dimensional structures for generalization."
- Singular Vector Canonical Correlation Analysis (SVCCA): A technique combining PCA and CCA to compare representational subspaces across models or tasks. "To quantify the functional equivalence between two representations under linear transformations, we employed Singular Vector Canonical Correlation Analysis (SVCCA; \citealp{raghu2017svcca})."
- Structural isomorphism: A correspondence between structures where relational patterns are preserved across spaces. "A smaller indicates a higher degree of structural isomorphism between the two latent spaces."
- Subspace Overlap Analysis: A method that measures how much variance in one task’s representations is explained by the principal components of another task. "To assess whether one task spans the same subspace as others, we apply asymmetric Subspace Overlap Analysis."
- Task-disentangled subspace perspective: The view that networks organize different tasks into separate subspaces to reduce interference. "our account unifies them under a common relational perspective and has the potential to extend beyond number concepts. These findings also bear on a foundational question in neural systems and representation: if the same behavior or structure can arise from multiple implementations \citep{hu2025function}, what constrains representational convergence? One answer is the interplay between system capacity and environmental complexity." (context includes "the task-disentangled subspace perspective \citep{yang2019task}")
- Task interference: Degradation in performance when multiple tasks share overlapping representations. "A central tension in this area is the trade-off between generalization and task interference."
- t-SNE: A nonlinear dimensionality reduction technique for visualizing high-dimensional data in low-dimensional space. "To visualize the global organization of embeddings among tasks, we projected them into a 2D space using t-SNE \citep{hinton2002stochastic}."
- Triple-Code Model: A theory proposing three distinct numerical representation formats—Arabic digits, verbal words, and analog magnitude—each with different neural substrates. "The highly influential Triple-Code Model proposes that numerical information is represented in three distinct formats — Arabic (i.e., digits), verbal (i.e., words), and analog magnitude (i.e., MNL) — each associated with a different neural substrate \citep{dehaene2001precis}."
Collections
Sign up for free to add this paper to one or more collections.